
CGroups 以及在 K8s 中的应用 - 内存

c
group
s(
control groups
,
控制组群
) 是 Linux 内核的一个功能,用来限制、控制与分离一个进程组的资源(如CPU、内存、磁盘输入输出等)。它是由 Google 的两位工程师进行开发的,自 2008 年 1 月正式发布的 Linux 内核 v2.6.24 开始提供此能力。
cgroup
s到目前为止,有两个大版本, 即 v1 和 v2 。
cgroups
可以限制、记录、隔离进程组所使用的物理资源(包括:
CPU
、
memory
、
IO
等),为容器实现虚拟化提供了基本保证,是构建
docker
、
containerd
、
ku
bernetes
等一系列容器服务的基石。
上一节中,我们对一些基本概念进行了介绍,本节我们针对
cgroups
对内存资源的限制进行简单的测试。
作者:董卫国,中国移动云能力中心软件研发工程师,专注于云原生领域。
cgroups
v1
版本测试
我们当前的测试环境为
centos 7.9
,内核为
5.4
版本,如下所示:

cgoups资源限制测试
创建一个名为
test
01
的
cgroups
组,并对内存进行资源限制,如下所示

现在我们对当前会话限制了
1
00
M
的内存,然后我们
在网上找到了
一个
c
函数
,
用来测试
内存
申请的效果
,如下所示
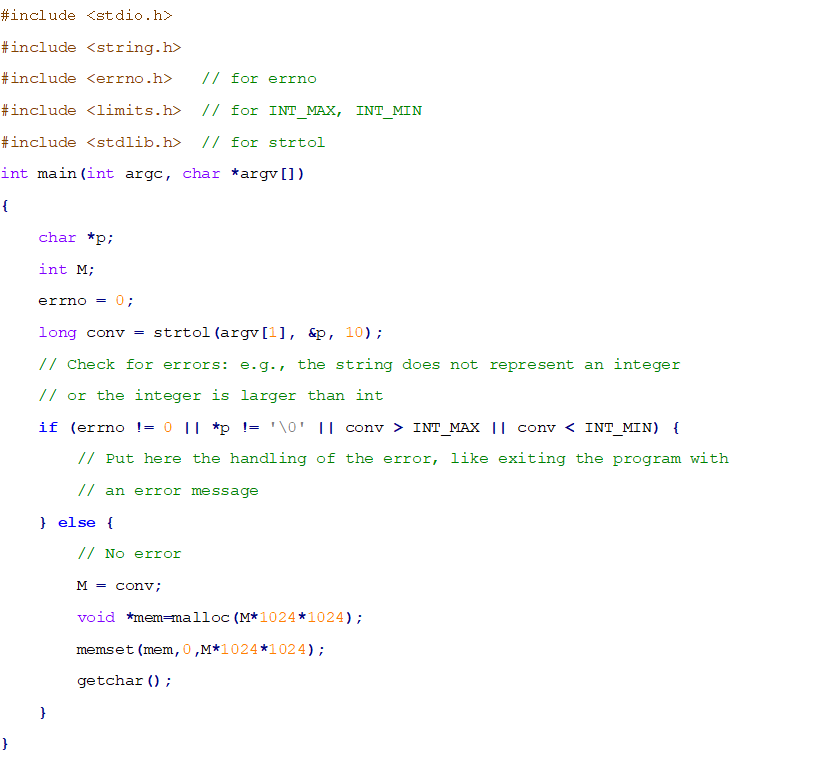
编译执行,测试如下:
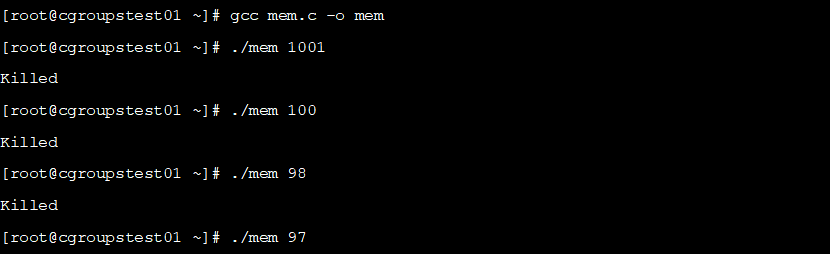
可以看到申请超过甚至接近
1
00
M
内存的时候,都容易
发生
OOM
,说明
cgroups
起到了限制内存使用的作用,查看
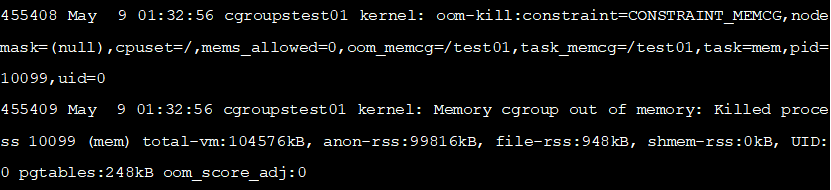
/var
/log/message
中可以看到对应的日志信息,如下所示:
我们申请了
1
00
M
内存,为什么只能用到不到
9
8
M
呢,我们查看内存统计值
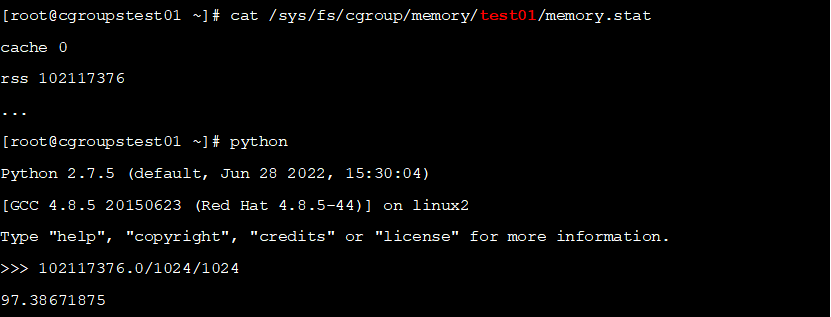
查看统计值发现 cache和rss仅使用了9
7
M
多一点,这基本符合我们的预期,但是剩下的内存去哪儿了?进一步查阅文献我们知道,还有一部分内存使用统计在
memory.kmem.usage_in_bytes(显示当前内核内存用量)
,而没有统计到
memory.stat
,查看结果,如下所示:
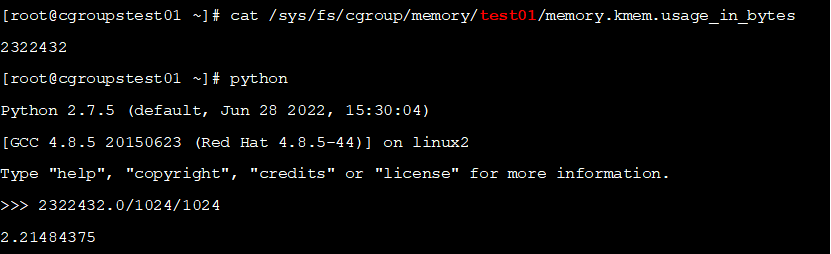
可以看到除了
9
7
M
程序运行使用的内存,还有
2M
内核多内核使用的内存,怪不得使用
9
8
M
内存时会触发
OOM
。这样一来,事情就基本符合我们的预期了。
K
u
bernets
中的资源限制
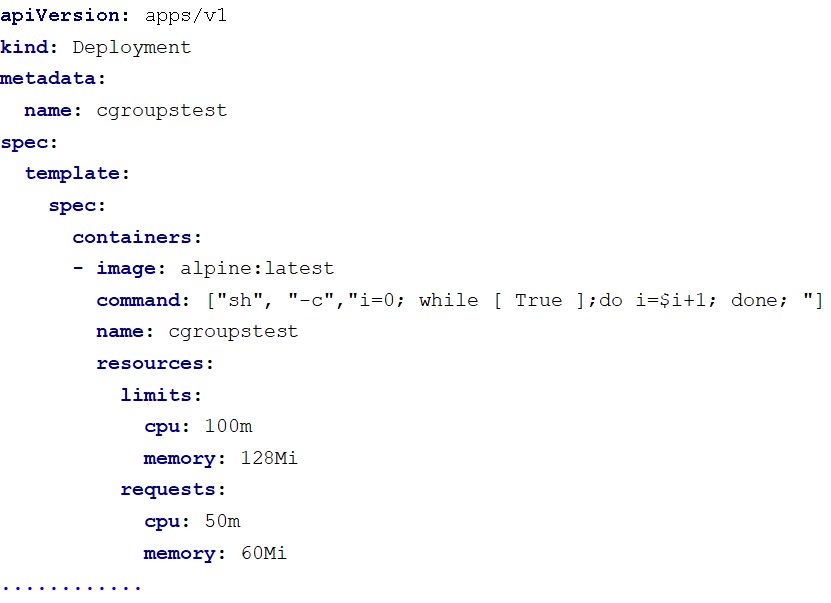
我们尝试
在
Kubernetes
中启动一个
deploy
ment
,
启动后登录到节点上查看
pod
的内存资源是如何被限制的
。
下面
的测试是使用
sealos
部署的
v1.25.9
版本的
Kubernetes
进行的。
P
od
变为
Running
状态后,登录到
Pod
所在节点执行如下
shell
命令查看容器
cgroupstest
的内存限制

容器的资源限制如下所示
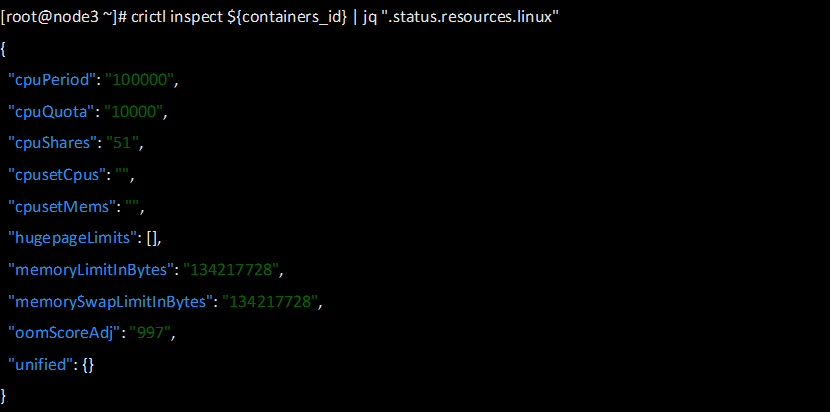
下面我们进一步查看限制效果,查看容器
cgroupstest
的内存限制

可以看到结果如下
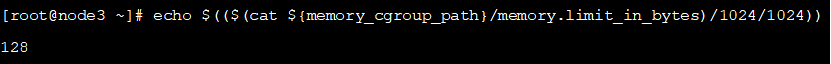
可以看到当前容器
cgroupstest
的内存限制为
1
28
M
。
cgroups
v
2
版本测试
简单
测试使用
c
groups v2
创建一个名为
test
01
的
cgroup
s
组,并对内存进行资源限制,如下所示
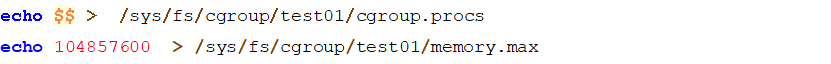
上面的
shell
命令,我们对这个
shell
限制了
1
00
M
的内存。
使用前面测试
v
1
版本的
cg
roups
时候引入
c
函数申请内存,编译执行,测试如下:
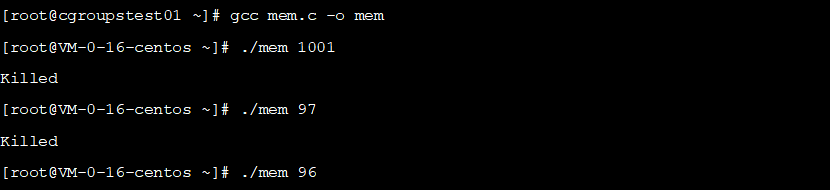
可以看到当前申请
9
7
M
内存时,就会触发
oom
,
cgroups
v2
版本可以通过查看
memory.current
文件统计当前的内存使用。
kubernetes中
基于
cgroups
v2
的
Me
mory Qos
K
ub
ernetes提供QoS(Quality of Service,服务质量)服务质量管理,基于每个 Pod 中容器的资源请求和限制为 Pod 设置 QoS 类
,并依赖
QoS 类来决定从遇到
节点压力
的 Node 中驱逐哪些 Pod。可选的 QoS 类有 Guaranteed、Burstable 和 BestEffort。 当一个 Node 耗尽资源时,Kubernetes 将首先驱逐在该 Node 上运行的 BestEffort Pod, 然后是 Burstable Pod,最后是 Guaranteed Pod。当这种驱逐是由于资源压力时, 只有超出资源请求的 Pod 才是被驱逐的候选对象。
下面对各级别分别进行相应说明:
Guaranteed
:pod中的所有容器都必须对cpu和memory同时设置limits,如果有一个容器要设置requests,那么所有容器都要设置,并设置参数同limits一致,那么这个pod的QoS就是Guaranteed级别。注:如果一个容器只指明limit而未设定request,则request的值等于limit值。
Burstable
: pod中只要有一个容器的requests和limits的设置不相同,该pod的QoS即为Burstable。
BestEffort
:如果对于全部的resources来说requests与limits均未设置,该pod的QoS即为BestEffort。
Memory QoS
是
Kubernetes
在新版本里基于
cgroup v2
实现的新特性,这个特性始于
1
.22
版本,至今仍属于
Alpha
版本。该特性本质上还是封装
cgroup v2
的能力,来提供更加弹性的内存管理。
cgroups v1 实现
了
CPU 和 Memory 隔离
,
CPU 属于可压缩资源,在节点 CPU 紧张时,任务只会
受到限制(
throttl
e
)
,不至于被 kill。但 Memory
属于
不可压缩资源,在节点内存不足时会触发 OOM
,导致容器重启,可是
这对部分 Burstable Pod 是不可接受的。而且某些内存消耗型 Pod 在创建和运行中会短时申请大量内存,导致节点内存瞬间飙升
,
节点内存紧张可能会导致内存高敏 Pod 在申请内存时
存在问题
,从而影响服务质量。cgroups v1 无法解决此类 Memory QoS 问题。但幸运的是,cgroups v2
的
memory controller 为我们提供了参数
减缓此问题
。
我们
回顾
下
cgroup v2
中内存
限制
的配置项,
cgroups
v2
一共有如下四种内存分配和保护实现(即
4
个可修改的文件):
Ø
memory.min
:内存的硬保护机制,这是当前
cgroups
必须保留的最小内存分配,在任何情况下都不会回收这块内存。如果满足不了
memory.min
的内存分配,系统会触发
OOM
。
Ø
memory.low
:是一种
BestEffort
的内存保护机制,是一种软保护实现,也即不能保证这块内存一定不被回收。当无法从其他未受保护的
cgroups
中回收内存时,会回收这块的内存。
Ø
memory.high
:内存使用的瓶颈限制,系统会尝试将
cgroups
内存使用率控制在此阈值之下,而并不是直接
OOM Kill
。这样的设计就非常适合一些
Memory Burst
的场景,可以像
CPU
一样做一定程度的资源压缩。
Ø
memory.max
:内存使用的最大限制,如果
cgroups
内存使用达到这个值,会触发
OOM
。
可以看到通过设置
memory.high
的值,我们可以环节一些特殊场景下的节点内存压力,
我们需要在kubelet中加入如下启动参数,才可以启用
Memory QoS
的机制:
--feature-gates=MemoryQoS=true
在这里多提一下,我们上面的测试中一直使用centos7升级内核和systemd的方式使其支持cgroups v2,但是这里开启此特性后,测试后pod无法启动,报错如下
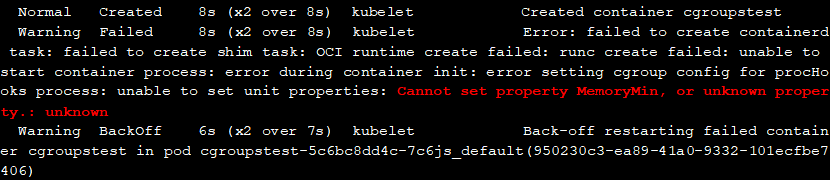
同样的
ku
bernets
和容器运行时版本,更换
ubuntu
22
和
rockylinux8
测试,都能正常启动服务进行测试,前面我们将
systemd
升级到了
2
34
版本,但还不够高,
docker
的官方文档中推荐使用
2
47
版本以上,也许
是
systemd
或者其他软件包版本的影响,笔者这里没有在
centos
7
上进一步的尝试,此处的测试使用
rockylinux8
(内核版本
4
.18
)。
我们启动一个
deploy
ment
,配置资源申请如下所示:

登录到
pod
所在节点查看该
pod
包含的容器内存限制如下所示:

可以看到,此处容器的内存最大值
memory.max
为
1
28
M
,即内存的
limit
值,最小值
memory.min
为
60
M
,即内存的
request
值。
me
mory
.
hgih
的计算公式如下:
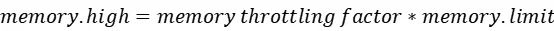
如
limit
没有设置,则按照如下公式得出
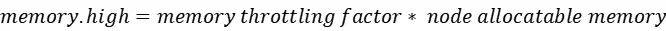
此时配置的
memory
.
high
为
102
M
,是内存
limit
的
0
.8
,符合预期。上面的
memory thrittling factor
值通过
kube
let config
中的
memoryThrottlingFactor
参数配置。
总结
本文对
cgroups
v1
和
v2
版本
对内存资源的限制
进行了介绍和基础功能的验证,并对其在
Kubernetes
中的使用进行了一些初步的调研。
对于
Kubernetes
中的
QoS
设计,本文也未能进一步的进行了解和学习,
Kubernetes
根据服务或者说
pod
的资源请求进行调度,使用
cgroups
进行
pod
占用资源的约束,根据
QoS
等级提供服务质量保障。在笔者的理解里,
Qo
S
是目标,
cgroups
只是其中的一种工具。
最后,由于笔者能力和时间所限,难免存在一些错漏,也缺乏对一些功能的源码级分析,对于不同系统和内核版本在不同硬件和参数配置下对不同资源类型的测试也存在不充分的地方,还请谅解。
参考
1)
一篇搞懂容器技术的基石: cgroup
,
https://zhuanlan.zhihu.com/p/434731896
2)
Linux cgroups
:深入理解
cgroups v1
版本
,
https://www.testerfans.com/archives/linux-cgroups-learn-more
3)
Linux CFS and task group
,
https://mechpen.github.io/posts/2020-04-27-cfs-group/index.html
4)
深入理解 Kubernetes 资源限制:CPU
,
https://icloudnative.io/posts/understanding-resource-limits-in-kubernetes-cpu-time/
5)
CFS Bandwidth Control
,
https://www.kernel.org/doc/html/v5.4/scheduler/sched-bwc.html?highlight=cpu%20cfs_quota_us
6)
Cgroup
详解
,
https://juejin.cn/post/6921299245685276686
7)
Cgroup
限制内存与节点的删除
,
https://chaochaogege.com/2019/09/11/6/
8)
容器内存分析
,
https://blog.csdn.net/u012986012/article/details/105291831
9)
控制组详解
,
https://blog.gmem.cc/cgroup-illustrated
10)
Cgroup V2 and writeback support
,
http://hustcat.github.io/cgroup-v2-and-writeback-support/
11)
Linux CGroup
基础
,
https://wudaijun.com/2018/10/linux-cgroup/
12)
详解
Cgroup V2
,
https://zorrozou.github.io/docs/%E8%AF%A6%E8%A7%A3Cgroup%20V2.html
13)
centos 7
升级
systemd
,
https://lqingcloud.cn/post/systemd-01/
14)
容器
-cgroup-blkio-cgroup
,
http://119.23.219.145/posts/%E5%AE%B9%E5%99%A8-cgroup-blkio-cgroup/
15)
打通
IO
栈:一次编译服务器性能优化实战
, https://mp.weixin.qq.com/s?__biz=Mzg2OTc0ODAzMw==&mid=2247502495&idx=1&sn=26950b22cba383b14052b441cd356516&source=41#wechat_redirect
16)
pod
资源限制和
QoS
探索
,
https://www.zerchin.xyz/2021/01/31/pod%E8%B5%84%E6%BA%90%E9%99%90%E5%88%B6%E5%92%8CQoS%E6%8E%A2%E7%B4%A2/
点击【阅读原文】到达
Kubernetes
网站。