
聊一聊2020年实例分割领域的进展和未来展望
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
This article was original written by 林大佬, welcome re-post, first come with https://zhuanlan.zhihu.com/ai-man . but please keep this copyright info, thanks, any question could be asked via wechat: jintianandmerry
实例分割发展至今可谓是八仙过海各显神通,大家都在为打造一个精度足够高,速度足够快的方法不断地开拓着。从MaskRCNN这一开山鼻祖的方法到最新的SOLO,SOLOv2等,精度在不断刷新,速度在不断提高。然而对这一领域问题的定义并非是一成不变。Instance segmentation不同于Detection,围绕着这个问题可以展开非常多的方法去做它,甚至是把问题推翻,重新定义一遍instance segmentation然后再来想办法解决它。今天本文就围绕着从MaskRCNN这个开衫鼻祖开始,和大家聊一聊实例分割的发展脉络,以及它的未来发展方向。正在做实例分割方向调研准备在这上面发paper的同学可以深入看一看,顺便点个赞,实在无聊可以转发一波。
实例分割任务Review
实例分割是一个很具有挑战性的任务,我们用一张图来描述它:

从左到右,依次是目标检测任务,语义分割,实例分割任务。从图可以看出,实例分割不仅仅要求分割出物体的mask,识别出它的类别,还需要去区分同一类里面的不同instance。
自从2阶段的目标检测算法大行其道以来,FasterRCNN,各种RCNN的算法层出不穷。继而随着MaskRCNN算法的横空出世,让大家领略了原来目标检测还可以这样玩,许多基于RPN的实例分割算法也被相继提出。这一思想甚至一直影响到如今。比如PANet,MaskScoreRCNN (mask scoring MaskRCNN)等,这些其实都是MaskRCNN以及2 tage目标检测算法的思想延续而来。即通过RPN拿到box的proposal,再接着对这些Proposal进行mask的分割。不得不说,这些方法其实取得了非常大的成功,到目前位置,很多商业级别的算法都是基于MaskRCNN开发的。
但,MaskRCNN实在是太慢了。这就造成了这个算法被禁足在学术界,工业界完全不敢用,造成的latency是不可忍受的,可能就是因为10ms的误差,导致几百万美元的订单飞了。为此,包括学术界在内,大家都在苦思冥想,一直想开发一个足够快,同时精度上又能够和MaskRCNN比拼的实例分割算法。
事实上,除了速度慢以外,MaskRCNN还有一个缺点,既它产生的Mask,永远是从28x28的tiny mask reshape而来。因此,它产出的Mask实际上是很粗糙的。这是由于 它的mask分支的resolution被固定在一定的尺寸所导致的。因此,MaskRCNN对于一些大物体同时外边界有很复杂的场景下是不适用的。比如你拿去做大象的检测,大象计数,那么外边界可能就不准确了(什么人会专门检测大象?)
因而,基于这些缺点,一些人就想着去解决它。得益于这几年anchor-free方法的大力发展,大家都发现,基于anchor-free来做实例分割,好像是一个不错的idea,于是就有了很多基于CenterNet,FCOS等方法改进的实例分割算法,比如CenterMask,BlendMask,等等。下面这张图,来自于SOLOv2的paper,可以看看这些年实例分割算法的精度演化情况:

本篇文章不仅仅会概括实力分割发展的脉络,也会归纳一下,评判一下不同方法的优缺点。
事实上,本文开篇就提到了一个问题:实例分割这个领域和目标检测不一样, 你可以有无数种方法来定义实例分割. 为什么这么说呢?请继续看:
Mask的表征方式
许多学者其实已经意识到了这个问题,通过不同的途径来表征Mask,可以得到声东击西、曲线救国之功效,而mask的表征方式大家最熟悉,最直观的方式也就是binary的方法,也就是一个矩阵,里面放着0和1,有1的地方说明有物体,0的地方是背景。还有一些mask的表征方式就比较fancy了,比如把一个binary mask encode成一个固定维数的向量。
局部Mask和全局Mask
局部mask和全局mask的唯一区别在于,局部是拿到box之后,再做分割,从box里面crop出我们需要的mask,而全局mask是直接从图片上去拿到mask。
一图以蔽之:
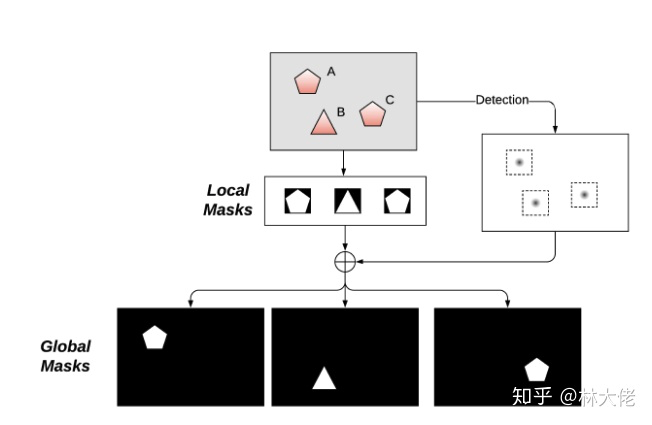
全局mask带来的优点就是,它很直观,其次它可以以原图的方式来分割出mask,这不会让小物体丢失全局信息,同时也可以让小物体更容易被看见。对于大物体来说,它看的也更加清晰,边界也应当会更加的清晰。
局部mask,就像是MaskRCNN等基于检测的方法所采用的那样,它的mask resize之后,最终会取决于实际物体的大小来决定这个物体的mask质量。它优点其实也很明显,它同样很简单,可以和任何目标检测算法结合起来,同时它应该速度相对来说更快,占用的显存毫无疑问会更小。
基于这种mask表征的方式,我们可以将所有的实力分割算法大致分为两个大类别:
基于局部mask的表征方法; 基于全局mask的表征方法。
局部mask的表征方法
首先我们聊一聊局部mask的表征方法,它从每一个Proposal出来的region提取mask。
通过边框回归表征的局部mask编码
bbox其实是一个很泛化的mask,它只有四个点,实际上只有两个坐标,如果我们把这四个点扩展为32个点会怎么样呢?

这就是ExtremeNet的思想,这篇论文也是CVPR2019. 它通过定位center point以及regression 八个边框点来构建mask。也就是我们传说中的八边形目标检测。这同时也不由得让我想起来最新的那篇PolyYolo:

这篇论文也是在yolo检测基础上,直接拓展了15个angle实现的。严格上来说,它和PolarMask更为相似,他们应该都可以归类到一类吧。不管怎么样,都还是局部Mask的思想为指导。
对PolyYolo比较感兴趣的朋友可以reference源代码:https://gitlab.com/irafm-ai/poly-yolo。我们最近也会重构一个基于tensorflow2.0的版本,尽请期待。

对于PolarMask,这篇CVPR2020的文章,其实也是蛮有意义的,等于说是把这个问题推翻了,重新定义了一遍,再来解决。在这里其实我很想跟大家分享这篇paper:https://arxiv.org/pdf/1908.04067.pdf ESESeg。

这篇论文来自于上海交大。文章采用了一个新颖的形状签名的方式,采用切比雪夫多项式来拟合每一个形状的内心半径,得到物体的mask。据说这个方法在VOC上超越了maskrcnn,以7倍的速度。
当然大家感兴趣也可以点进去看看paper。最后它也是没有超越我们框定的范畴,也是基于局部mask的方式,它可以和yolov3连接,也可以和其他任何SOTA的检测器链接,做成一个实例分割框架。
但,最后,就我个人而言:
虽然ESE-Seg生成的mask比那些基于若干个angle的方式要好,但still,看起来依旧很不对味,简单来说,没有那个味儿。。你懂吧?
通过4D的张量构建mask
继续来看一看基于局部mask的mask编码方式。通过4D的tensor来构建,典型的算法就是tensorMask了。4D,其实超越了我一个地球三维生物的维度想象上界,但我们可以剥开一个维度,看看它表征的是什么?

wh可以理解,vu可以看做是什么?像素点的坐标?不对,wh就已经包含了位置坐标信息了。应该是中心点在xy坐标处的mask,表示方式就是uv。这个方法要说巧妙吧,倒也满巧妙,毕竟何凯明出品,必出精品,但它的速度竟然比MaskRCNN还慢,有点杀第一百自损三千的赶脚。除此之外它需要更多的训练时间,是MaskRCNN训练时间的6倍。这简直无法忍受。
精巧的Mask编码方式
事实上,虽然都是局部mask编码方式,但是contour base和mask-based有着天然的缺点。比如这样:

你contour based就没有办法有效的表征里面的洞了。于是大家就在想,有没有办法可以让mask又高效同时又准确,还能表示这样的洞呢?
今年最近的论文MEInstance里面就提到了一个方法,将mask编码成一个统一的Matrix,它可以illustrate like this:

这个编码方式是很精妙的,完美的规避了端到端对齐的问题,什么事端到端对齐?一张图片里面的box数目,box大小都是不一样的,因此MaskRCNN这样的局部Mask的分割方式都会不可避免的引入RoIAlign这样的操作,导致了每一个batch都需要一个对齐的操作。MEInst这里做的工作就是一个标准化。不过令人遗憾的是,理想很丰满,但是现实却很骨感,虽然论文证明了这种表征方式可行,速度却没有和MaskRCNN高出多少,源自于这里面的编码和解码的操作比较耗时。
全局Mask表征方式
接着,我们来看一看思路完全不一样的实例分割方法。事实上,这个分支才是目前比较主流的,onestage的实例分割方法。全局Mask通过预测图片里面每一个可能存在的Mask,来构建整张图片的所有instance。
这些方法可以说是主流和先驱,他们可以简单的归结一下:
Yolact: yolact 是第一个做到realtime的实例分割算法,尽管它的精度不是很高 。yolact将整个任务拆分为了两个部分,一个部分是得到类似于FCN的语义分割结果,prototype,另外一个分支来拿到box,通过融合box和prototypes,得到mask和对应的box。实际上,这里面全局的Mask就被使用了,尽管你察觉不到。通过box来crop全局的mask淹没,其实大概率就可以找到对应的mask,然后再对这个mask进行一个学习,就可以回归出一个完整的Mask。
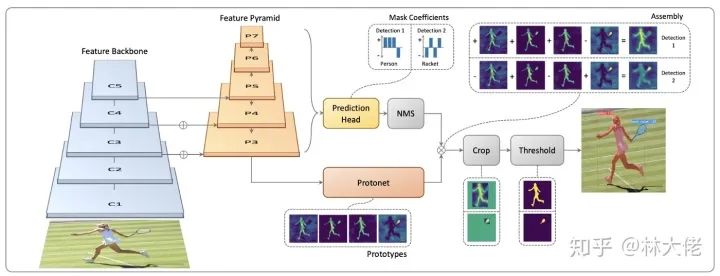
这里面还有一个十分值得注意的点,由于yolact里面采用了全局的Mask,并且最终生成的mask质量只取决于全图的分辨率,与mask的数目无关,这就使得yolact在计算mask的速度上,可以和mask的数目无关,它是一个常量。这也是Yolact速度比较快的原因之一;
InstanceFCN 和 FCIS: 这两个算法应该比MaskRCNN还老,可以说是实例分割的鼻祖的鼻祖了。这两个方法也使用了全局的Mask,只不过在FCIS里面,它是通过psroi来判断mask是否存在于某个position里面,它存在着ROI的操作,也是得这个方法比较复杂; BlendMask: 最新的BlendMask,个人认为,是一个比较精妙,精度很高,速度也做的很快的方法。你如果仔细思考BlendMask的做法,你会看到MaskRCNN的引子,但是也会看到Yolact的引子。因为它依赖于detector,同时也用到了全局的Mask。这篇paper,在它的Blender模块里面,使用了全局的Mask,同时通过FCOS检测到的position来融合局部的mask和对应位置的全局Mask,进而得到一个更加准确的Mask回归。结果也确实如此,BlendMask渲染出来的Mask边框更加完美。

ConsInst: 最后是ConsInst,个人认为,ConsInst应该是目前最有潜力的一个,它可以做到Realtime高速,同时保证高精度,最重要的是简单!CondInst更进一步,彻底的去掉了detector,完全完全的不需要检测器来辅助了。

仔细看ConsIns的架构,会发现,它的思路和SOLO有点像,直接输出原图中的全局Mask,只不过它的mask只负责输出mask,不负责输出类别,这一点和SOLO不同,与此同时,最终的mask排列顺序会和类别有一个匹配的过程,这样你才能知道哪一个mask是哪一个类别不是吗?最后,期待ConsInst开源...
总结一下,事实上,回过头去看,你会发现,BlendMask也好,CenterMask也罢,包括ConsInst,他们都是Yolact的扩展。为什么这么说呢?
BlendMask/CenterMask如同我们上面分析总结的那样,它需要一个检测器来辅助,得到全局Mask里面的局部mask信息,而全局的mask又辅助局部mask的优化和回归,从这个角度将,简直就是和Yolact一脉相承,说不定真的是收到了Yolact的启发也说不定; ConsInst直接输出全局的mask可能的位置,这个和Yolact何其的相似,只不过Yolact的作者发现好像我并没有办法把他们分开,而ConsInst的作者们做到了;
最后,我们再来讲一讲最新的SOLO和SOLOv2.
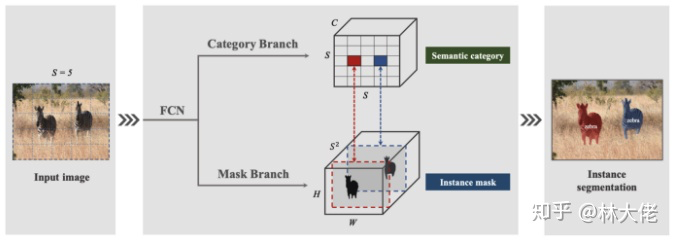
SOLO系列算法,给我的感觉就是两个字,牛逼。为什么呢?它仿佛就是在告诉你:
We did instance segmentation by stack convolutions without any bells and whistles.
通常在论文里面说这句话的人,我都是五体投地,跪拜大神的。为什么呢?就比方说有人用一个小学生都能看懂的方法推导出了泰勒展开,你能说不牛逼么。话说回来,SOLO这个系列的方法,确实简单,简单是简单,但是人家work啊,还有啥好说的呢?不服自己做实验去。
PS:不知道是我运气的原因,还是财力不够(没卡),我用4块GPU train SOLOv2,没有一个版本的work的。loss震荡剧烈,感兴趣的朋友也可以加入我们的社群,一起来讨论交流一下:
http://t.manaai.cnt.manaai.cn
言归正传,关于SOLO这个算法的解释,其实原作者有一个很详细的解释了:
如何看待SOLO: Segmenting Objects by Locations,是实例分割方向吗?
https://www.zhihu.com/question/360594484/answer/936591301
我这里结合本文的核心论述说一下,其实SOLOv2也可以归纳到全局Mask这个范畴,就如下图所示。它直接预测全局的Mask,同时通过Mask的构建方式来区分类别。

总结:
到目前为止,SOLOv2和ConsInst应该是真正的work,高速并且Box-Free的实例分割算法.
请注意,这里提出了一个新的名词,BoxFree, 就和anchofree一样,box就是实例mask的anchor,我们也可以去掉它。
干货
最后论文的干货如下:
通过更高维度的encoding来表征Mask是很棘手的问题,现在大多数的算法都把mask encoding在低纬度,比如20到200,事实上可能也是这个方法的瓶颈所在,不然大家都用更高的了; 手工制作的contour的方法,不是很好的办法,这类方法看起来没啥前途,事实上我的其他post也讲到过实例分割的用途,一个最大的用途就是在无人驾驶里面用,如果你的Mask不够准,我也就没啥用了; 局部Mask的方法大多数依赖于detector,我任务这样的方法过于复杂了,它也没有使得精度提高多少,反而使得部署过于困难,比如BlendMask需要全局的mask和location融合,还会引入类似于ROIAlign和ROIPooling的操作,在后处理阶段,实际使用上是很复杂的; 全局的Mask表征有时候比较昂贵,显存和速度都可能成为瓶颈,ConsInst这种方式其实应该速度会比SOLOV2慢一点,因为它的分支数更多; SOLOv2这个思路延续下去,或许会有更好的方法产生。 我不知道SOLOV2难以训练是开源代码存在的问题,还是算法本身就比较难以训练,这里面存在着一些问题值得探寻。
Reference
[1]. Patrick Langechuan Liu: Single Stage Instance Segmentation Review;
[2]. Mask Encoding for Single Shot Instance Segmentation