
【关于 概率图模型】 那些的你不知道的事
作者:杨夕
论文链接:https://arxiv.org/pdf/1810.04805.pdf
本文链接:https://github.com/km1994/nlp_paper_study
个人介绍:大佬们好,我叫杨夕,该项目主要是本人在研读顶会论文和复现经典论文过程中,所见、所思、所想、所闻,可能存在一些理解错误,希望大佬们多多指正。
【注:手机阅读可能图片打不开!!!】
目录
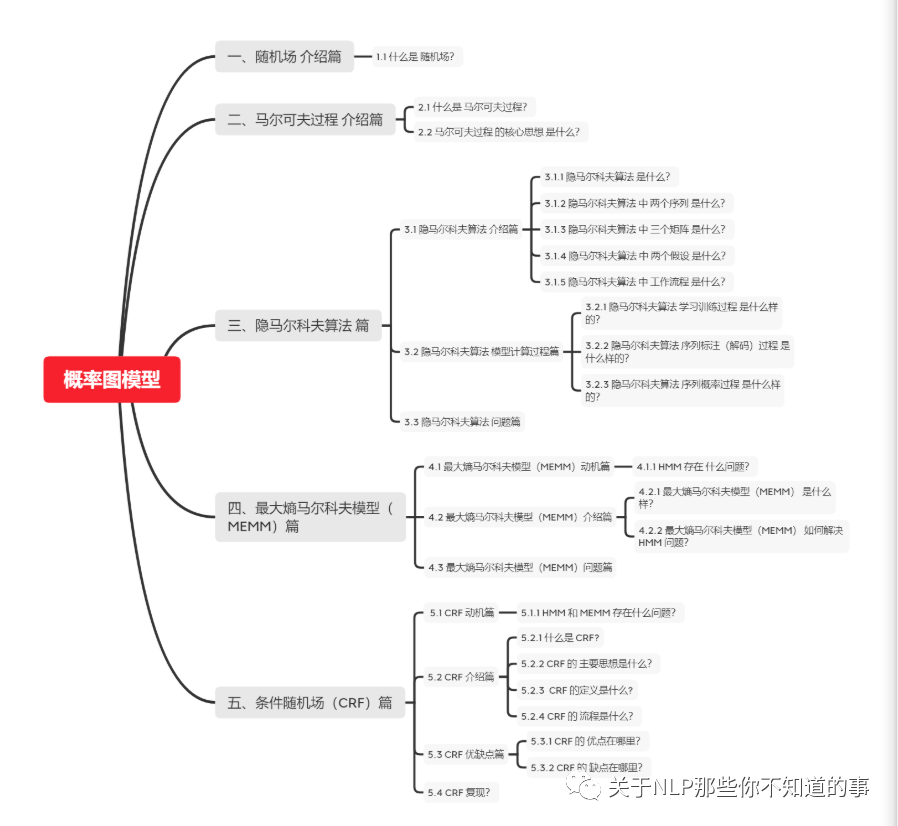
一、基础信息 介绍篇
1.1 什么是概率图模型?
概率图模型(Probabilistic Graphical Model, PGM),简称图模型(Graphical Model,GM),是指一种用图结构来描述多元随机变量之间条件独立性的概率模型(注意条件独立性),从而给研究高维空间的概率模型带来了很大的便捷性。
1.2 什么是 随机场?
每个位置按照某种分布随机赋予一个值 所构成 的 整体。
二、马尔可夫过程 介绍篇
2.1 什么是 马尔可夫过程?

2.2 马尔可夫过程 的核心思想 是什么?
对于 马尔可夫过程 的 思想,用一句话去概括:当前时刻状态 仅与上一时刻状态相关,与其他时刻不相关。
可以从 马尔可夫过程 图 去理解,由于 每个状态间 是以 有向直线连接,也就是 当前时刻状态 仅与上一时刻状态相关。
三、隐马尔科夫算法 篇
3.1 隐马尔科夫算法 介绍篇
3.1.1 隐马尔科夫算法 是什么?

3.1.2 隐马尔科夫算法 中 两个序列 是什么?

3.1.3 隐马尔科夫算法 中 三个矩阵 是什么?

3.1.4 隐马尔科夫算法 中 两个假设 是什么?

3.1.5 隐马尔科夫算法 中 工作流程 是什么?

3.2 隐马尔科夫算法 模型计算过程篇
3.2.1 隐马尔科夫算法 学习训练过程 是什么样的?
思想
找出数据的分布情况,也就是模型参数的确定;
常用方法
极大似然估计:该算法在训练数据是会 将 观测状态序列 和 隐状态序列 ;
Baum-Welch(前向后向):该算法在训练数据是只会 将 观测状态序列 ;
3.2.2 隐马尔科夫算法 序列标注(解码)过程 是什么样的?
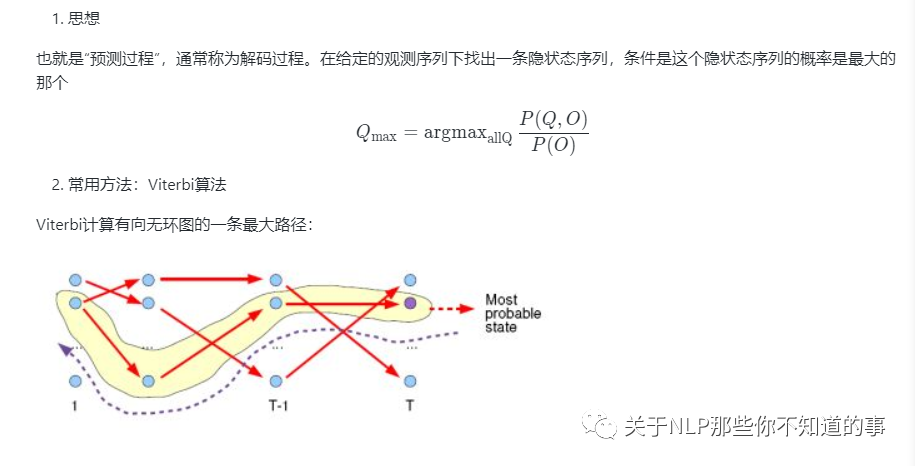
3.2.3 隐马尔科夫算法 序列概率过程 是什么样的?

3.3 隐马尔科夫算法 问题篇
在序列标注问题中,隐状态(标注)不仅和单个观测状态相关,还和观察序列的长度、上下文等信息相关。例如词性标注问题中,一个词被标注为动词还是名词,不仅与它本身以及它前一个词的标注有关,还依赖于上下文中的其他词。
四、最大熵马尔科夫模型(MEMM)篇
4.1 最大熵马尔科夫模型(MEMM)动机篇
4.1.1 HMM 存在 什么问题?

4.2 最大熵马尔科夫模型(MEMM)介绍篇
4.2.1 最大熵马尔科夫模型(MEMM) 是什么样?
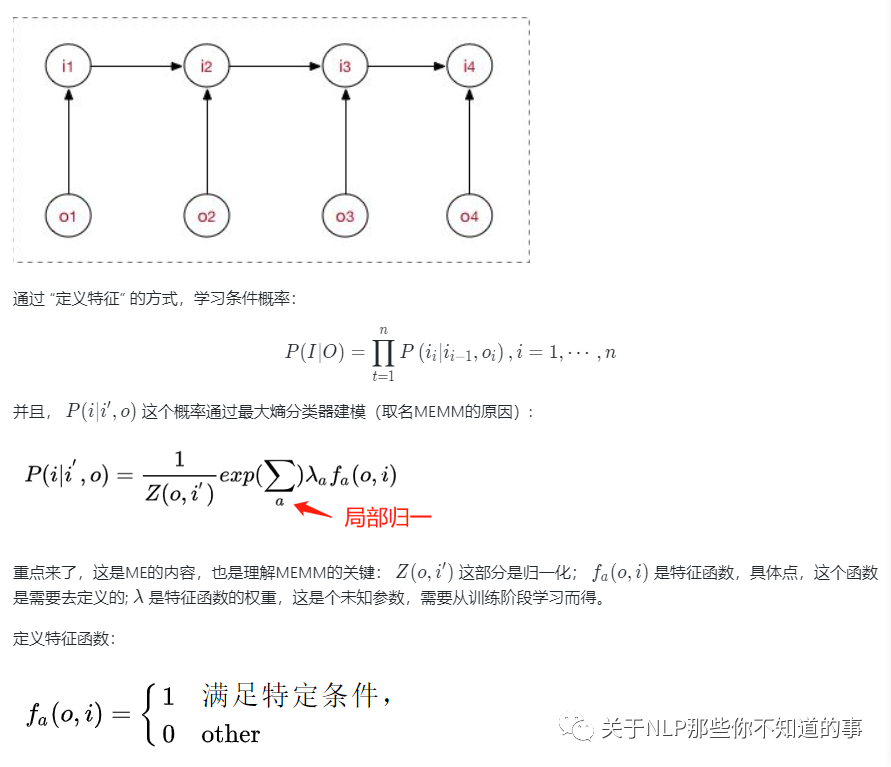

4.2.2 最大熵马尔科夫模型(MEMM) 如何解决 HMM 问题?

4.3 最大熵马尔科夫模型(MEMM)问题篇


五、条件随机场(CRF)篇
5.1 CRF 动机篇
5.1.1 HMM 和 MEMM 存在什么问题?
HMM :状态的转移过程中当前状态只与前一状态相关问题
MEMM :标注偏置 问题
解决方法:统计全局概率,在做归一化时考虑数据在全局的分布
5.2 CRF 介绍篇
5.2.1 什么是 CRF?
设X与Y是随机变量,P(Y|X)是给定条件X的条件下Y的条件概率分布,若随机变量Y构成一个由无向图G=(V,E)表示的马尔科夫随机场。则称条件概率分布P(X|Y)为条件随机场。
5.2.2 CRF 的 主要思想是什么?
统计全局概率,在做归一化时,考虑了数据在全局的分布。
5.2.3 CRF 的定义是什么?

5.2.4 CRF 的 流程是什么?
选择特征模板:抽取文本中的字符组合 or 具有其他特殊意义的标记组成特征,作为当前 token 在模板中的表示;
构建特征函数:通过一组函数来完成由特征向数值转换的过程,使特征与权重对应;
进行前向计算:每个状态特征函数(0-1二值特征函数)对应 L 维向量,最终状态特征函数权值的和即为该位置上激活了的状态特征函数对应的 L 维向量之和;
解码:利用 维特比算法 解码 出 最优标注序列
5.3 CRF 优缺点篇
5.3.1 CRF 的 优点在哪里?
为每个位置进行标注过程中可利用丰富的内部及上下文特征信息;
CRF模型在结合多种特征方面的存在优势;
避免了标记偏置问题;
CRF的性能更好,对特征的融合能力更强;
5.3.2 CRF 的 缺点在哪里?
训练模型的时间比ME更长,且获得的模型非常大。在一般的PC机上可能无法执行;
特征的选择和优化是影响结果的关键因素。特征选择问题的好与坏,直接决定了系统性能的高低
5.4 CRF 复现?
import numpy as np
class CRF(object):
'''实现条件随机场预测问题的维特比算法
'''
def __init__(self, V, VW, E, EW):
'''
:param V:是定义在节点上的特征函数,称为状态特征
:param VW:是V对应的权值
:param E:是定义在边上的特征函数,称为转移特征
:param EW:是E对应的权值
'''
self.V = V #点分布表
self.VW = VW #点权值表
self.E = E #边分布表
self.EW = EW #边权值表
self.D = [] #Delta表,最大非规范化概率的局部状态路径概率
self.P = [] #Psi表,当前状态和最优前导状态的索引表s
self.BP = [] #BestPath,最优路径
return
def Viterbi(self):
'''
条件随机场预测问题的维特比算法,此算法一定要结合CRF参数化形式对应的状态路径图来理解,更容易理解.
'''
self.D = np.full(shape=(np.shape(self.V)), fill_value=.0)
self.P = np.full(shape=(np.shape(self.V)), fill_value=.0)
for i in range(np.shape(self.V)[0]):
#初始化
if 0 == i:
self.D[i] = np.multiply(self.V[i], self.VW[i])
self.P[i] = np.array([0, 0])
print('self.V[%d]='%i, self.V[i], 'self.VW[%d]='%i, self.VW[i], 'self.D[%d]='%i, self.D[i])
print('self.P:', self.P)
pass
#递推求解布局最优状态路径
else:
for y in range(np.shape(self.V)[1]): #delta[i][y=1,2...]
for l in range(np.shape(self.V)[1]): #V[i-1][l=1,2...]
delta = 0.0
delta += self.D[i-1, l] #前导状态的最优状态路径的概率
delta += self.E[i-1][l,y]*self.EW[i-1][l,y] #前导状态到当前状体的转移概率
delta += self.V[i,y]*self.VW[i,y] #当前状态的概率
print('(x%d,y=%d)-->(x%d,y=%d):%.2f + %.2f + %.2f='%(i-1, l, i, y, \
self.D[i-1, l], \
self.E[i-1][l,y]*self.EW[i-1][l,y], \
self.V[i,y]*self.VW[i,y]), delta)
if 0 == l or delta > self.D[i, y]:
self.D[i, y] = delta
self.P[i, y] = l
print('self.D[x%d,y=%d]=%.2f\n'%(i, y, self.D[i,y]))
print('self.Delta:\n', self.D)
print('self.Psi:\n', self.P)
#返回,得到所有的最优前导状态
N = np.shape(self.V)[0]
self.BP = np.full(shape=(N,), fill_value=0.0)
t_range = -1 * np.array(sorted(-1*np.arange(N)))
for t in t_range:
if N-1 == t:#得到最优状态
self.BP[t] = np.argmax(self.D[-1])
else: #得到最优前导状态
self.BP[t] = self.P[t+1, int(self.BP[t+1])]
#最优状态路径表现在存储的是状态的下标,我们执行存储值+1转换成示例中的状态值
#也可以不用转换,只要你能理解,self.BP中存储的0是状态1就可以~~~~
self.BP += 1
print('最优状态路径为:', self.BP)
return self.BP
def CRF_manual():
S = np.array([[1,1], #X1:S(Y1=1), S(Y1=2)
[1,1], #X2:S(Y2=1), S(Y2=2)
[1,1]]) #X3:S(Y3=1), S(Y3=1)
SW = np.array([[1.0, 0.5], #X1:SW(Y1=1), SW(Y1=2)
[0.8, 0.5], #X2:SW(Y2=1), SW(Y2=2)
[0.8, 0.5]])#X3:SW(Y3=1), SW(Y3=1)
E = np.array([[[1, 1], #Edge:Y1=1--->(Y2=1, Y2=2)
[1, 0]], #Edge:Y1=2--->(Y2=1, Y2=2)
[[0, 1], #Edge:Y2=1--->(Y3=1, Y3=2)
[1, 1]]])#Edge:Y2=2--->(Y3=1, Y3=2)
EW= np.array([[[0.6, 1], #EdgeW:Y1=1--->(Y2=1, Y2=2)
[1, 0.0]], #EdgeW:Y1=2--->(Y2=1, Y2=2)
[[0.0, 1], #EdgeW:Y2=1--->(Y3=1, Y3=2)
[1, 0.2]]])#EdgeW:Y2=2--->(Y3=1, Y3=2)
crf = CRF(S, SW, E, EW)
ret = crf.Viterbi()
print('最优状态路径为:', ret)
return
if __name__=='__main__':
CRF_manual()
六、对比篇
6.1 CRF模型 和 HMM和MEMM模型 区别?
相同点:MEMM、HMM、CRF 都常用于 序列标注任务;
不同点:
与 HMM 的区别:CRF 能够解决 HMMM 因其输出独立性假设,导致其不能考虑上下文的特征,限制了特征的选择的问题;
与 MEMM 的区别:MEMM 虽然能够解决 HMM 的问题,但是 MEMM 由于在每一节点都要进行归一化,所以只能找到局部的最优值,同时也带来了标记偏见的问题,即凡是训练语料中未出现的情况全都忽略掉。
CRF :很好的解决了这一问题,他并不在每一个节点进行归一化,而是所有特征进行全局归一化,因此可以求得全局的最优值。
参考资料
条件随机场CRF
朴素贝叶斯(NB)、逻辑回归(LR)、隐马尔科夫模型(HMM)、条件随机场(CRF)
学习笔记:条件随机场(CRF)
如何轻松愉快地理解条件随机场(CRF)?
概率图模型体系:HMM、MEMM、CRF
CRF 视频介绍
