
如何将pytorch检测模型通过docker部署到服务器

向AI转型的程序员都关注了这个号👇👇👇
人工智能大数据与深度学习 公众号:datayx
本文记录下如何使用docker部署pytorch文本检测模型到服务器,
。镜像文件也上传到docker hub了,可以一步步运行起来,不过需要先安装好docker。docker的安装可参考官方文档。https://docs.docker.com/docker-for-windows/install/
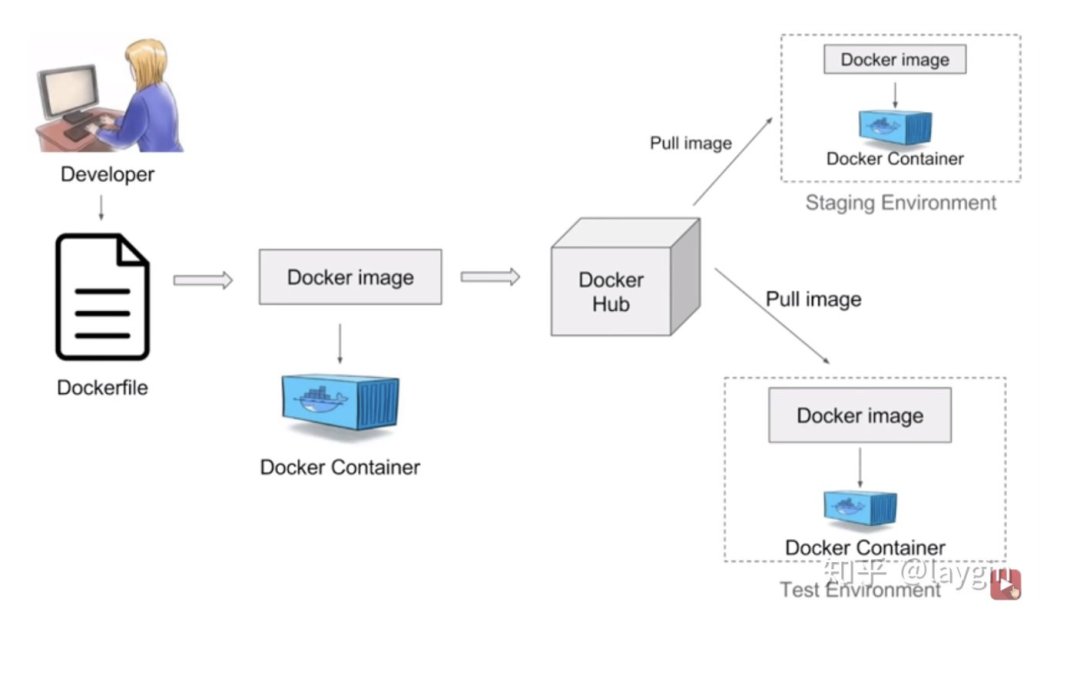
搭建服务端API
为了便于测试,可以先使用Flask搭建一个简易版本文本检测服务器,服务端创建接口部分代码如下:


其中主要的是detection函数,接收的图像为numpy array格式,通道为BGR;输出为检测的文本框,shape为(#boxes, 8),8代表四个点的横纵坐标,从左上角开始顺时针排序。
PAGE是一个简单的网页,创建表单。可在浏览器中进行验证,也可以通过脚本验证,后面详述。
创建镜像
需要先编写Dockerfile文件:
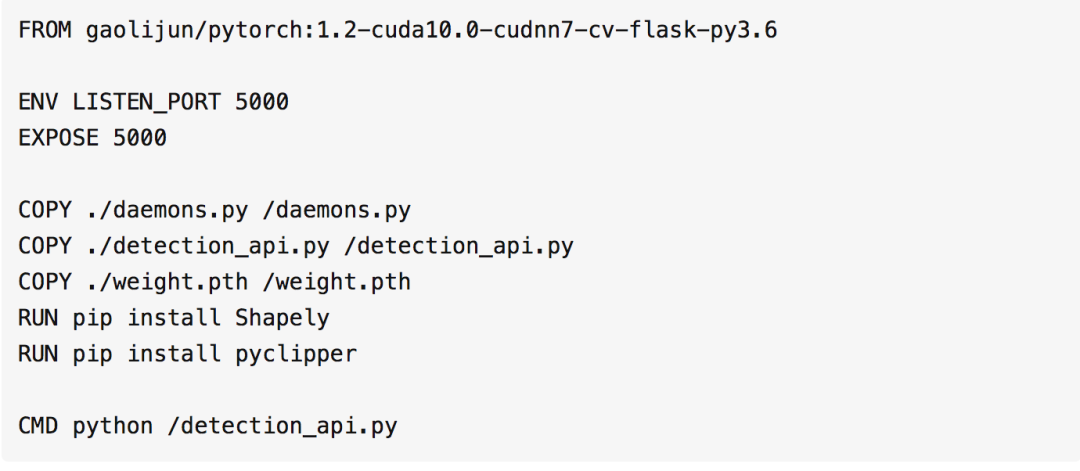
gaolijun/pytorch:1.2-cuda10.0-cudnn7-cv-flask-py3.6 是另一个自定义创建的镜像,安装的Python版本为3.6,pytorch版本为1.2,cuda版本为10.0;并且已经安装好了opencv和flask,以及其他一些常用库,比如numpy等等,该镜像做了许多精简,保证了搭建pytorch和flask服务所需的功能,文件并不很大。为了省事儿,直接在这上面搭建几层。
设置docker开放的端口为5000,后面可以在运行的主机上进行映射。
然后将需要的文本拷贝进去,其中detection_api提供上面的detection函数,可以看成黑盒子,输入是图像,输出为该图像上检测得到的所有文本框。
安装额外的依赖包:Shapely和pyclipper,这在 gaolijun/pytorch:1.2-cuda10.0-cudnn7-cv-flask-py3.6 中没有安装,so...
在容器中运行镜像的时候就运行检测api脚本。
写好了Dockerfile,在DockerFile所在目录运行:
docker build -t detector:v1.0 .
镜像名称为detector,给个标签:v1.0,便于跟踪管理。
拉取镜像
我已经将创建的镜像上传到docker hub了,可以拉取下来:
docker pull laygin/detector
然后查看下全部的镜像:

运行docker
docker run -p 3223:5000 -d --name detector detector:v1.0
-p: 主机端口到docker容器端口的映射。所以,只要愿意,主机上可以运行多个docker容器,指定不同的端口即可。
-d: docker容器在后台运行
--name: docker 容器名称
后面跟上创建的镜像,即在容器detector中运行的镜像detector:v1.0
或许需要
docker container ls来查看它或许还需要
docker stop detector来停止它或许也需要
docker rm detector来移除它,。。。。。如果没有停掉而想直接移除或许还不行,那就加上 --force/-f 强制操作吧
验证
文本检测服务已经运行起来了,要怎样才知道有没有运行成功呢?这里通过两种方式来验证一下。
1. 浏览器
提供了简易的web page,直接在浏览器中输入serverIP:3223/detector,其中serverIP为运行docker的服务器IP地址。
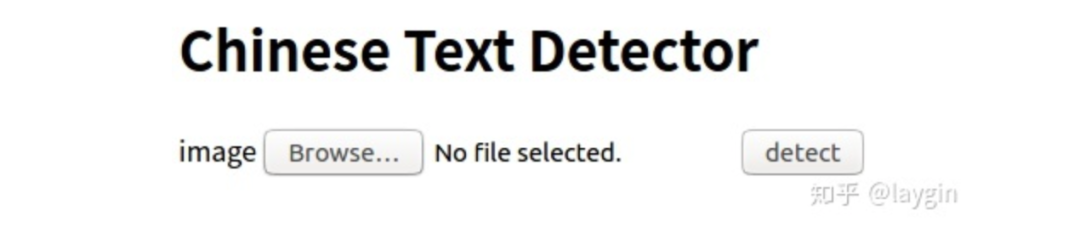
点击Browse选择图像,然后点击detect进行检测,得到如下结果:
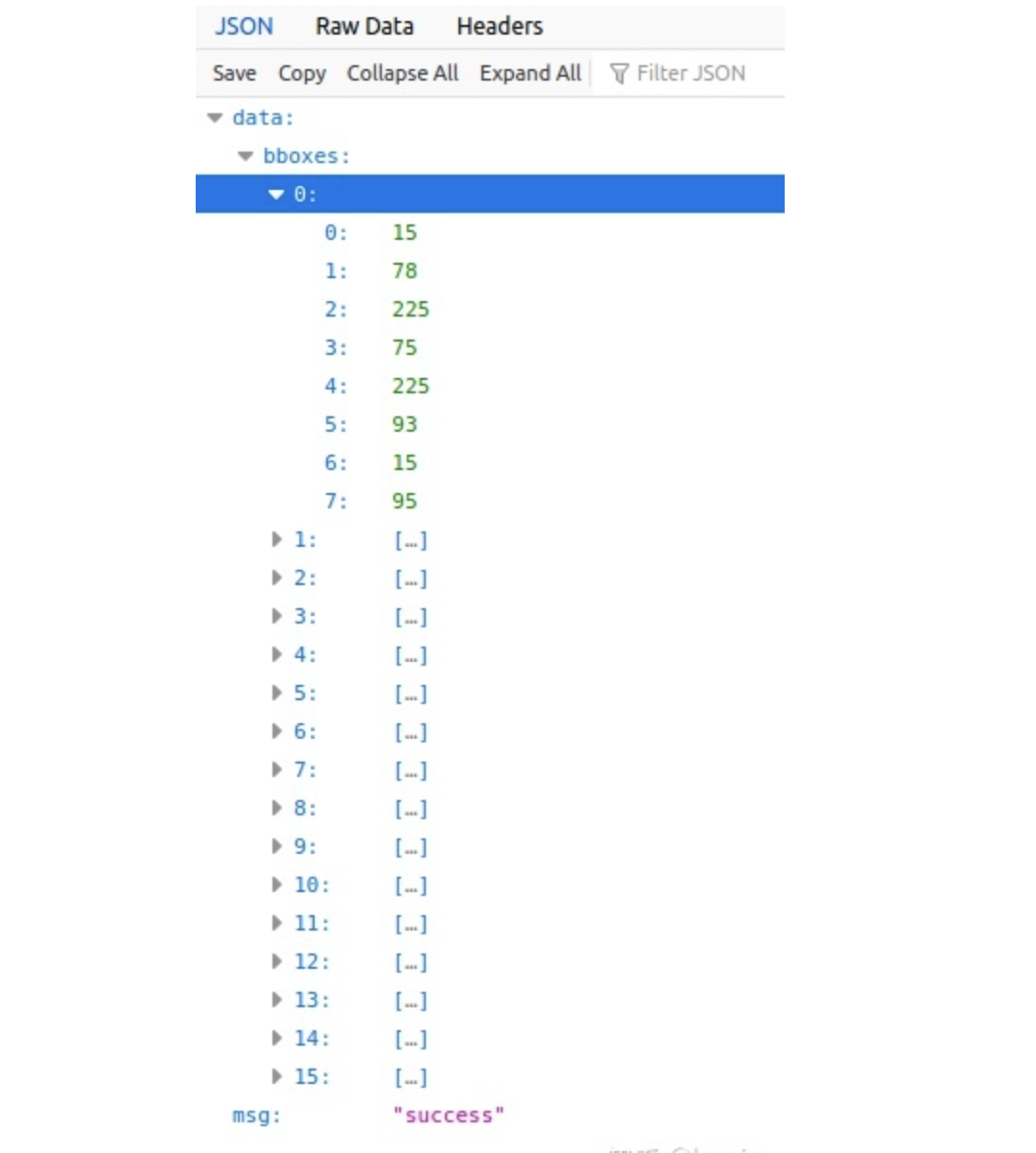
2. python脚本
通过脚本验证是最常用的方式了,这里写了一个简单的demo脚本


结果如图所示:

原文地址:https://zhuanlan.zhihu.com/p/159191983
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
机大数据技术与机器学习工程
搜索公众号添加: datanlp
长按图片,识别二维码