
用apply()函数对DataFrame对象进行批量操作
说在前面

pandas的apply()函数可以自动遍历整个Series或者DataFrame对象, 对每一个元素运行指定的函数。具体参数说明如下:
DataFrame.apply(func, axis=0, raw=False, args=(), **kwds)
func表示要指定的函数,可以是内置函数或自定义函数,也可以是lambda表达式;axis规定了传入数据所在的轴向,默认为0,表示按列处理;1表示按行处理,即当axis=1时,会把一行数据以Series对象形式传入到func函数中,函数对Series对象进行相关处理后,返回一个结果;apply函数会自动遍历DataFrame对象的每一行或列,最后将所有结果组合成一个Series或DataFrame对象并返回。raw默认为 False,表示把每一行或列作为 Series 传入函数中。
例1. 处理所有的行或列。注意axis的值默认为0,表示按列处理。
df =pd.DataFrame(np.random.randint(-10, 10, (4,5)),columns=list('abcde'))# 求每列的最大值与最小值的差x =df.apply(lambda x:max(x)-min(x))# 求每行的最大值与最小值的差y =df.apply(lambda x:max(x)-min(x), axis=1)print(df)print(x)print(y)

df =pd.DataFrame(np.random.randint(-10, 10, (4,5)),columns=list('abcde'))# 求a、b两列自身值与平均值的差x = df.apply(lambda x : x-x.mean() if x.name in ['a', 'b'] else x)# 求第1行自身值与总和之比y = df.apply(lambda x : x/sum(x) if x.name==0 else x, axis=1)print(df)print(x)print(y)

df =pd.DataFrame(np.random.randint(-10, 10, (4,5)),columns=list('abcde'))def f(x):returnpd.Series([x.min(),x.max(),x.mean()],index=['min','max','mean'])d = df.apply(f)print(d)

df =pd.DataFrame(np.random.randint(-10, 10, (4,5)),columns=list('abcde'))def f(a, b, c):return a + b + cdf['sum'] = df.apply(lambda x:f(x['b'],x['c'],x['d']),axis=1)print(df)

df =pd.DataFrame(np.random.randint(-10, 10, (4,5)),columns=list('abcde'))def f(df, a, b, c):return df[a] + df[b] +df[c]df['sum'] = df.apply(f,axis=1,args=('b','c','d'))print(df)df['sum'] =df.apply(f,axis=1,a='b',b='c',c='d')print(df)

3. 课后拓展练习
计算体重指数。BMI指数(身体质量指数,又称体重指数,英文为Body Mass Index,简称BMI),是用体重(千克)除以身高(米)的平方得出的数字,是目前国际上常用的衡量人体胖瘦程度以及是否健康的一个标准。
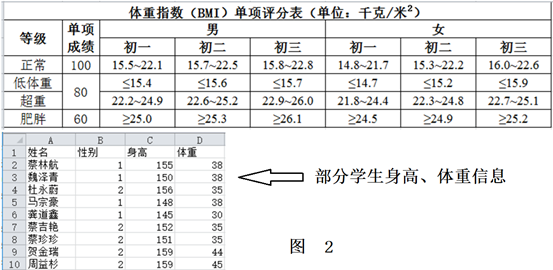
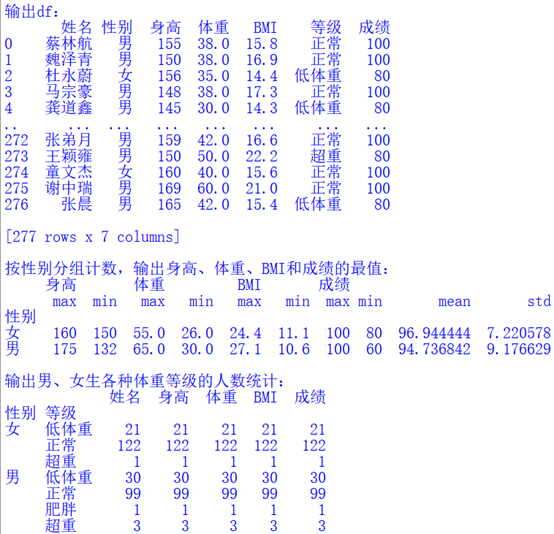
请编写程序读取“身高体重数据.csv”文件数据到DataFrame对象df中,并根据题目要求对df做进一步处理,最终输出df和其他统计数据如下图所示:
需要本文源代码和word文稿的,可以加入“Python算法之旅”知识星球参与讨论和下载文件,“Python算法之旅”知识星球汇集了数量众多的同好,更多有趣的话题在这里讨论,更多有用的资料在这里分享。
我们专注Python算法,感兴趣就一起来!
相关优秀文章:
评论