
你可能也会掉进这个简单的 String 的坑

图 by:石头@阿里巴巴飞天园区
关于作者:程序猿石头(ID: tangleithu),现任阿里巴巴技术专家,清华学渣,前大疆后端 Leader。
背景
石头同学是某大公司高级开发工程师,某日收到不少错误告警信息,于是便去开始排查。
跟踪日志发现是某个服务抛出的异常信息,奇怪的是这个服务上线也有一段时间了。之前很少看到类似的错误信息,最近偶尔多了起来。
后来才定位到是因为服务调用了某外部接口,发现对方对参数长度做了限制,如果输入参数超过 1000 bytes,就直接抛异常,代码类似如下:
/**
* @param status
* @param result, the size should less than 1000 bytes
* @throws Exception
*/
public XXResult(boolean status, String result) {
if (result != null && result.getBytes().length > 1000) {
throw new RuntimeException("result size more than 1000 bytes!");
}
......
}
心想,这还不简单,咱们的 result 也不是什么关键性的东西,你有限制,我直接 trim 一下不就行了?

解决方案
于是三下五除二,给搞了个 trim 方法,支持传不同参数按需 trim,代码如下:
/**
* 将给定的字符串 trim 到指定大小
* @param input
* @param trimTo 需要 trim 的字节长度
* @return trim 后的 String
*/
public static String trimAsByte(String input, int trimTo) {
if (Objects.isNull(input)) {
return null;
}
byte[] bytes = input.getBytes();
if (bytes.length > trimTo) {
byte [] subArray = Arrays.copyOfRange(bytes, 0, trimTo);
return new String(subArray);
}
return input;
}
再在需要调用外部服务的地方,先调用这个 trimAsByte 方法,一顿操作连忙上线,一切完美~

灾难现场
一切完美,石头哥也是这样认为的。然后幸福总是短暂的。
经过一段时间后(前面也提到,业务场景确实是偶发的),相同的错误仍然发生了。
简直不敢相信,都 trim 了为啥还会超出?你也帮忙想想,是哪里的问题?

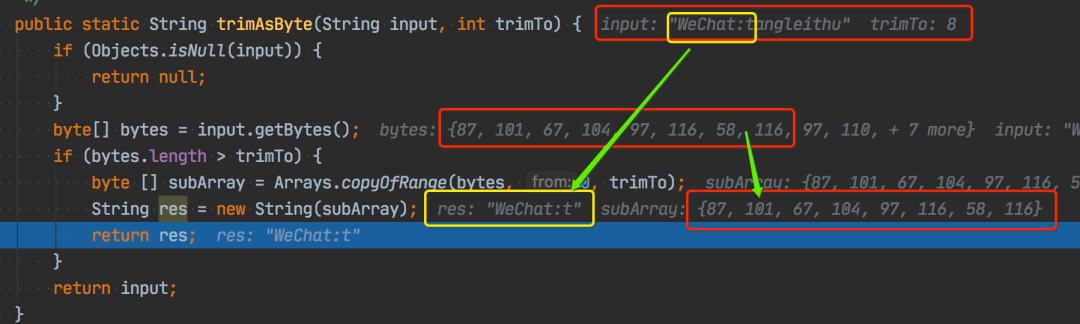
看看上面的例子(为了方便展示,简单修改文首代码了下),
trimAsByte("WeChat:tangleithu", 8)
输入字符串 WeChat:tangleithu 太长了,只 trim 到剩下 8 个字节,对应的字节数组是从 [87,101,67,104,97,116,58,116,97,110,103,108,101,105,116,104,117] 变为了 [87,101,67,104,97,116,58,116],字符串变成了 WeChat:t ,结果正确。
其实在写这个方法的时候还是太草率了,本应该很容易想到中文的情况的,我们来试试:
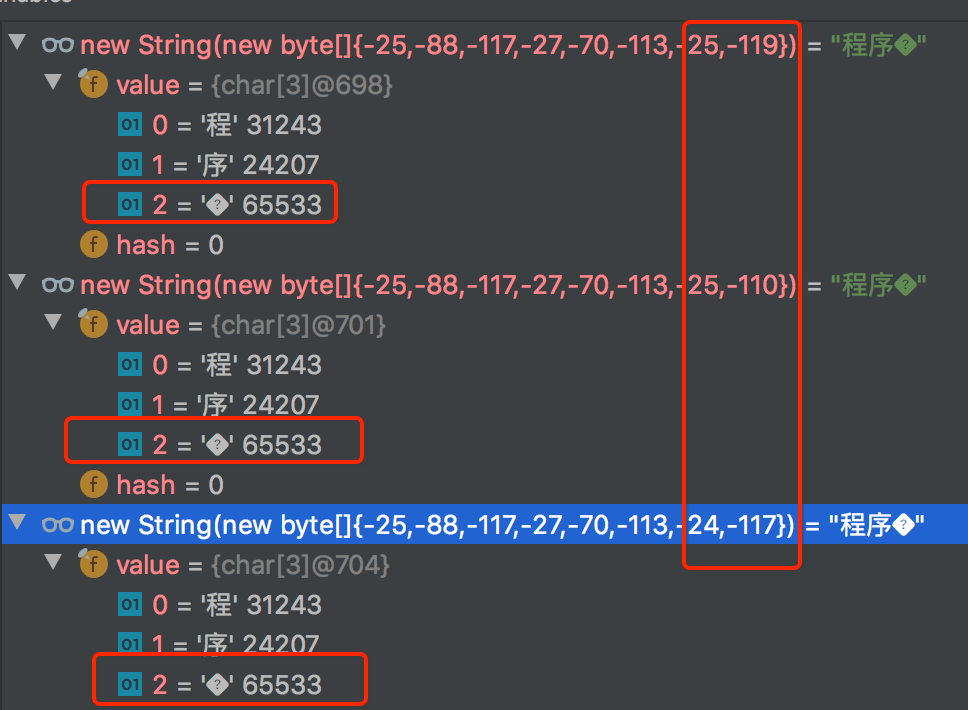
trimAsByte("程序猿石头", 8)
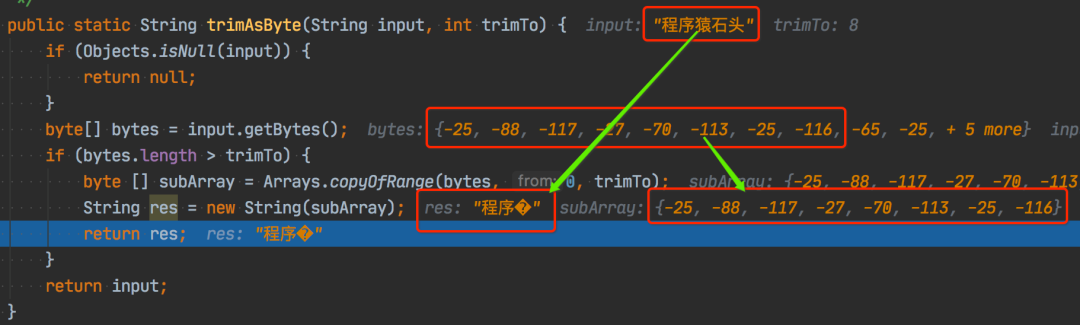
看上述截图,悲剧了,输入程序猿石头,3 个字节一个汉字,一共 15 个字节 [-25,-88,-117,-27,-70,-113,-25,-116,-65,-25,-97,-77,-27,-92,-76],trim 到 8 位,剩下前 8 位 [-25,-88,-117,-27,-70,-113,-25,-116] 也正确。再 new String,又变成3 个 “中文” 了,虽然第 3 个“中文”,咱也不认识,咱也不敢问到底读啥,总之再转换成字节数组,长度多了 1 个,变成 9 了。
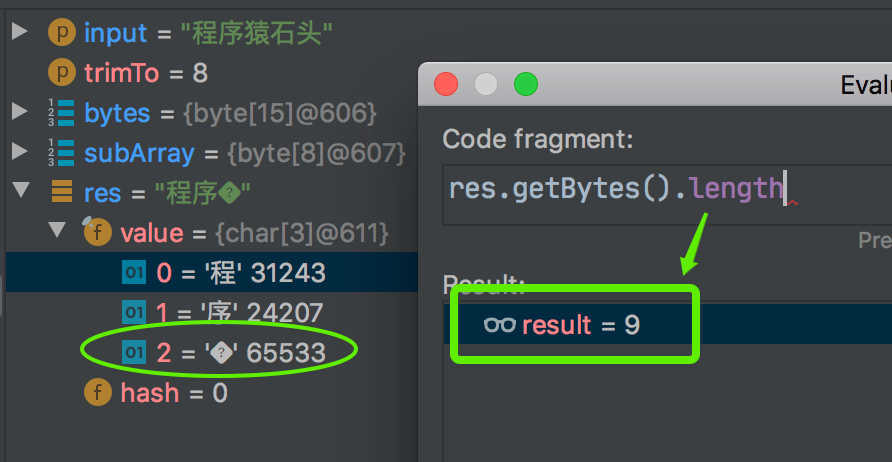
问题算是定位到了。
不禁要问,为什么?
来看看这个 String 的构造函数,看看上面注释才发现,其实我们忽略了一个很重要的概念,就是编码方式。
/**
* Constructs a new {@code String} by decoding the specified array of bytes
* using the platform's default charset. The length of the new {@code
* String} is a function of the charset, and hence may not be equal to the
* length of the byte array.
*
* The behavior of this constructor when the given bytes are not valid
* in the default charset is unspecified. The {@link
* java.nio.charset.CharsetDecoder} class should be used when more control
* over the decoding process is required.
*
* @param bytes
* The bytes to be decoded into characters
*
* @since JDK1.1
*/
public String(byte bytes[]) {
//this(bytes, 0, bytes.length);
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(bytes, offset, length);
}
当我们用默认的构造函数 new String 的时候,只是用了系统默认的编码(本文是“UTF-8”)去尝试解码,构造出字符串。
所以,当我们在用字节数组(字节流)来表达具体的语义的时候,一定要约定好以什么方式进行编码,本文不具体阐述编码问题了。下面用一个例子来解释上文的现象:
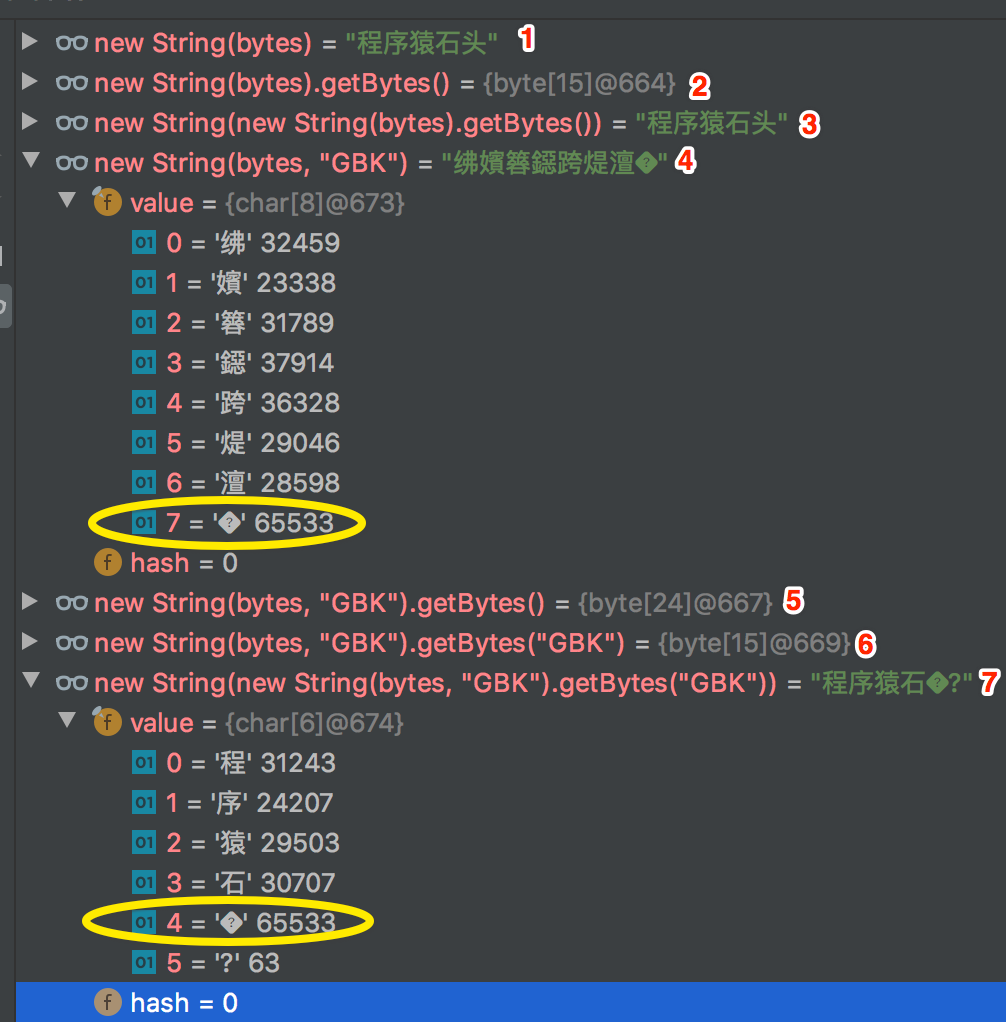
[-25,-88,-117,-27,-70,-113,-25,-116,-65,-25,-97,-77,-27,-92,-76] 仍然用这串字节数组来实验,这串字节数组,如果用 “UTF-8” 编码去解释,那么其想表达的语义就是中文“程序猿石头”,从上文标注的 1,2,3 中可以看出来,没有写即用了系统中的默认编码“UTF-8”。
假设按照 “GBK” 来解释(标注 4),就是表达的 “绋嬪簭鐚跨煶澶�”,注意看下其中的 � 是不是似曾相识;
注意标注 5,通过 GBK 解释构造字符串后,再通过默认的 “UTF-8” 获取字节数组,长度就变成 24 了,然后还通过 “GBK” 编码得到的字节数组长度为 15(标注 6),再试图构造字符串(标注 7),其中“程序猿石头”的“头”字,已经没了。说明这个转换过程中,其实信息已经被丢了。
上面的 � 其实是 UNICODE 编码方式中的一个特殊的字符,也就是 0xFFFD(65535),其实是一个占位符(REPLACEMENT CHARACTER),用来表达未知的、没办法表达的东东。上文中在进行编码转换过程中,出现了这个玩意,其实也就是没办法准确表达含义,会被替换成这个东西,因此信息也就丢失了。你可以试试前面的例子,比如把前 8 个字节中的最后一两个字节随便改改,都是一样的。
总结
总结一下,其实本来是一个很简单的问题,却经过几次修改才最终解决,说明对 “基础” 掌握得还是不够,一个重要的点是,在处理二进制数据的时候,一定要联想到 “编码” 方式。
另外,提醒我们,看似简单的问题,我们往往容易忽略。比如如果单纯看到文中提到的这个trim 方法,其实很容易写个单元测试就能尽早发现有问题;
题外话: 目前小哈正在个人博客(新搭建的网站,域名就是犬小哈的拼音) www.quanxiaoha.com 上更新《Go语言教程》,毕竟Go自带天然的并发优势,后端的同学还是要学一下的,这个教程系列小哈会一直更新下去,目前已经更新到 Go语言的基础语法了,欢迎小伙伴们访问哦~
END
有热门推荐?
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)
