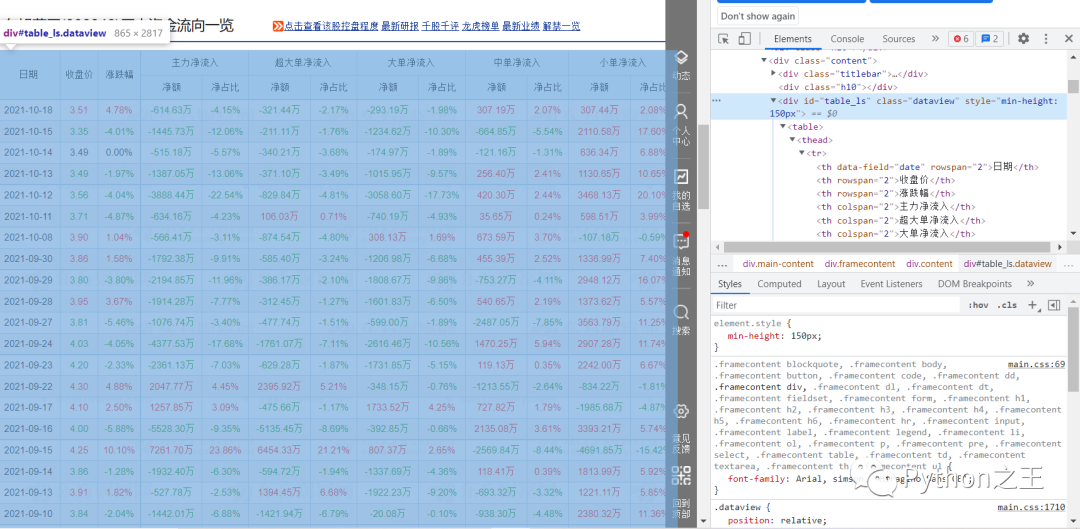
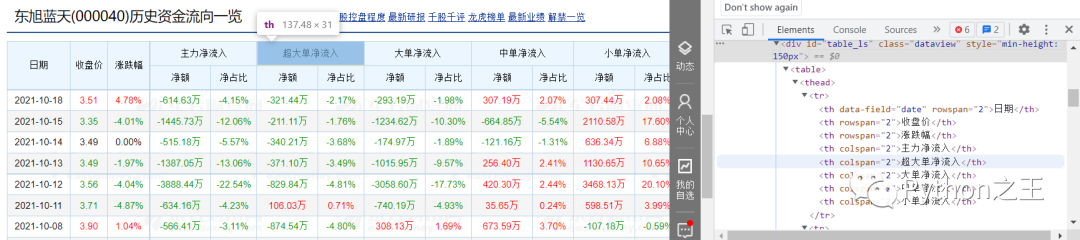
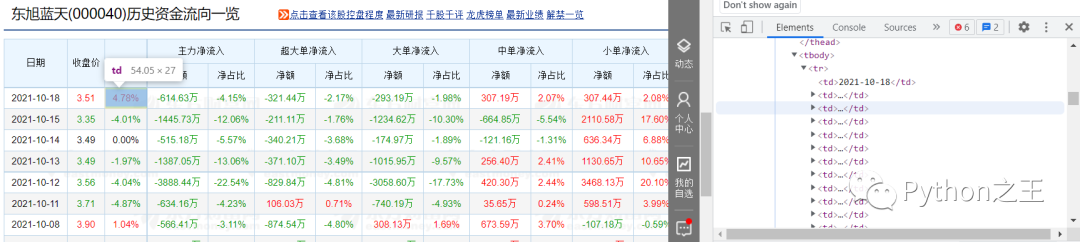
source = driver.page_source #获取页面源码 mytree = etree.HTML(source) #解析网页内容 tables = mytree.xpath('//div[@class="dataview"]/table') #定位表格 for i in range(len(tables)): #循环表格 onetable = [] trs = tables[i].xpath('.//tr') #取出所有tr标签 for tr in trs: ui = [] for td in tr: texts = td.xpath(".//text()") #取出所有td标签下的文本 mm = [] for text in texts: mm.append(text.strip("")) #去掉所有空格、换行符 ui.append(','.join(mm)) onetable.append(ui) #整张表格
with open('data.csv', 'a', newline='') as file: #将数据写入文件 csv_file = csv.writer(file) for i in onetable: csv_file.writerow(i) #按行写入