
从 Python 列表的特性来探究其底层实现机制

作者:ItRefer研发参考
列表(list)是 Python 中一个非常重要且常见的数据结构,它有很多易用的特性:可索引([index]),可切片([start, end, step]),能对其中的元素进行增(append、insert、extend)删(pop、remove)改操作。
如果你同时熟悉其他编程语言,比如 C++,你会觉得 Python 列表和 C++ STL 提供的 list 在操作上有些相似。
是的,它们都支持元素的增删改,在代码编写方面,C++ 的 list 不如 Python 列表开发效率高。C++ 中,你可能需要手动对 list 进行迭代,找到合适的元素或位置,然后执行操作。而 Python 中几乎所有操作都可以通过索引或切片来完成。
这样看来,二者底层实现机制应是有所区别的。事实正是如此。
C++ 的 list 是一个双向链表,链表中的节点是动态分配的,节点之间通过指针彼此相连。

这种结构的好处是,通过修改指针的指向,可以高效地在指定位置插入新的元素或删除指定的元素,而基本不影响其他节点。
其弊端就是无法随机访问 list 中的元素。在 list 中查找某个元素时需要从头开始遍历,时间复杂度为 O(n)。
那么,Python 是如何实现 list 数据结构的呢?
Python 3.9.2 FAQ 专门对 list 在 CPython 中的实现进行了简短的回答:
CPython's lists are really variable-length arrays, not Lisp-style linked lists. The implementation uses a contiguous array of references to other objects, and keeps a pointer to this array and the array's length in a list head structure
意思是说,CPython 中的 list 其实是一个变长数组,而非链表。变长数组中保存的是其他对象的引用。

使用这样一种数据结构的好处是,在 list 上执行索引操作所耗费的成本和 list 的尺寸或索引值的大小无关,即复杂度接近常量级。这是很显然的事情,因为这就是 C 或 C++ 中数组的下标访问。
FAQ 中还进一步介绍了该数据结构可能会产生的额外开销:
When items are appended or inserted, the array of references is resized. Some cleverness is applied to improve the performance of appending items repeatedly; when the array must be grown, some extra space is allocated so the next few times don't require an actual resize.
这个开销是在变长数组 resize 的时候产生的。当我们向 list 中插入或追加元素时,变长数组会根据需要来调整对象指针在数组中的位置,还会对数组大小进行扩充,以容纳更多的指针。
下面我们从代码层面来确认一下 Python 中 list 的实现方式。
在 Python 3.9.2 中,每个 list 对象都是一个 PyListObject 类的实例。
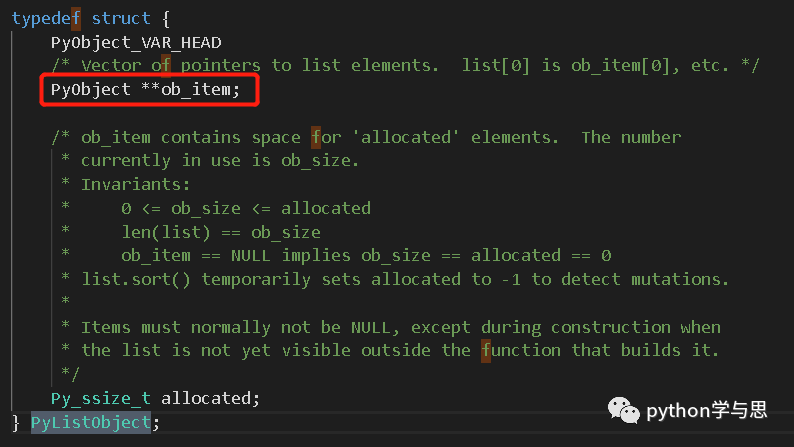
可以看到,PyListObject 中包含了一个 ob_item 的成员,它就是上文所说的变长数组,或者说它指向了那个存放着 PyObject 对象的指针的数组。list 的索引操作就是在这个数组上的随机访问,效率当然高了。
我们再通过 list 的插入操作看一下如何使用这个变长数组。

list_insert() 就是实现插入操作的入口函数。在对入参进行检查后,list_insert 调用了 list_insert_impl()。可以看到,list_insert_impl() 接收的就是插入位置和插入对象两个参数,这和我们之前介绍的 list 的 insert(<index>, <obj>) 方法保持一致。
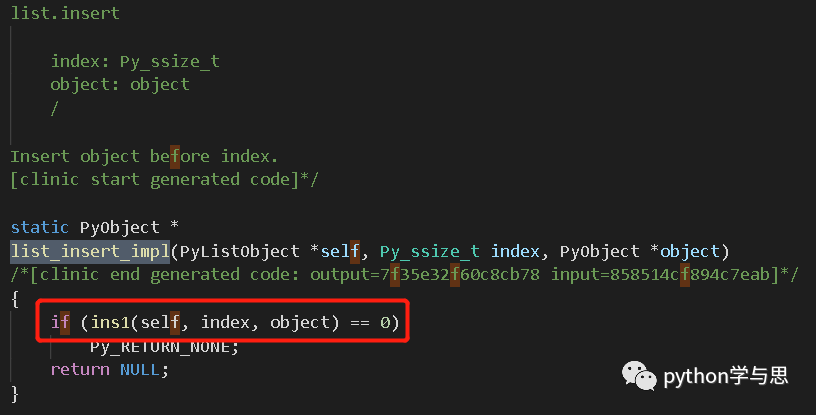
list_insert_impl() 进一步调用 ins1() 来实现插入逻辑。
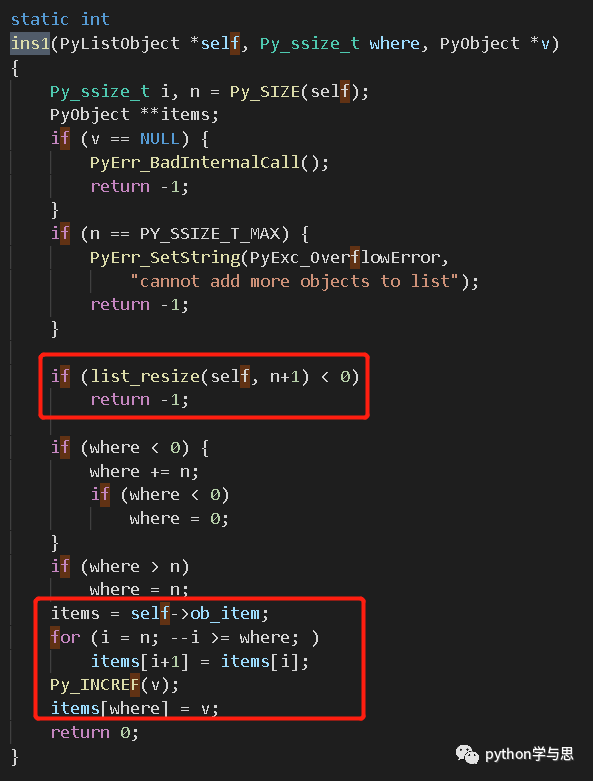
ins1() 首先对变长数组的当前空间进行检查,根据需要 resize 变长数组的大小。然后计算实际的插入位置 where。
之后,ins1() 将 obj_item 中 where 后边的元素逐个后移,将新元素 v (是一个指向待插入对象的指针)保存到 where 位置。同时将 v 的引用计数加 1.
使用变长数组这一数据结构,既提升了访问 list 元素的速度,又不显著影响插入或删除元素的速度,在时间和空间利用上做了很好的平衡。
至此,list 的实现方式已基本可以搞清楚了。
大家都知道 Python 开发效率高,而这种高效率凝结了 Python 设计者的聪明智慧。我们享受便利的时候更应该向他们致敬!

