
scikit-learn保姆级入门教程
来源:机器学习杂货店
在本篇内容中,我们展开讲解SKLearn的进阶与核心内容。SKLearn 中有六大任务模块,如下图所示:分别是分类、回归、聚类、降维、模型选择和预处理。
SKLearn官网:https://scikit-learn.org/stable/[2]
SKLearn的快速使用方法也推荐大家查看ShowMeAI的文章和速查手册 AI建模工具速查|Scikit-learn使用指南[3]
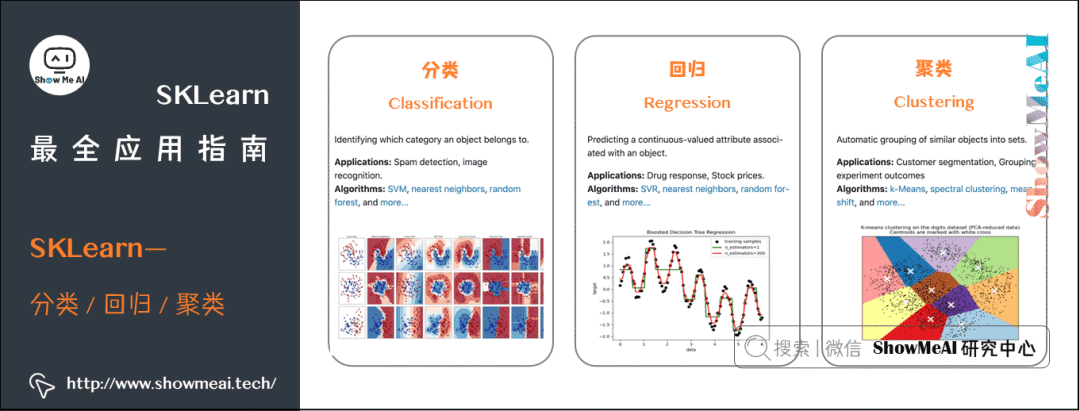

在SKLearn中,因为做了上层的封装,分类模型、回归模型、聚类与降维模型、预处理器等等都叫做估计器(estimator),就像在Python里『万物皆对象』,在SKLearn里『万物皆估计器』。
在本篇内容中,我们将给大家进一步深入讲解scikit-learn工具库的使用方法,力求完整覆盖SKLearn工具库应用的方方面面。本文的内容板块包括:
① 机器学习基础知识:机器学习定义与四要素:数据、任务、性能度量和模型。机器学习概念,以便和SKLearn对应匹配上。
1.机器学习简介
关于本节内容,强烈推荐大家阅读ShowMeAI文章 图解机器学习 | 机器学习基础知识[4] 和 图解机器学习 | 模型评估方法与准则[5] ,ShowMeAI对相关知识内容展开做了详细讲解。
定义和构成元素
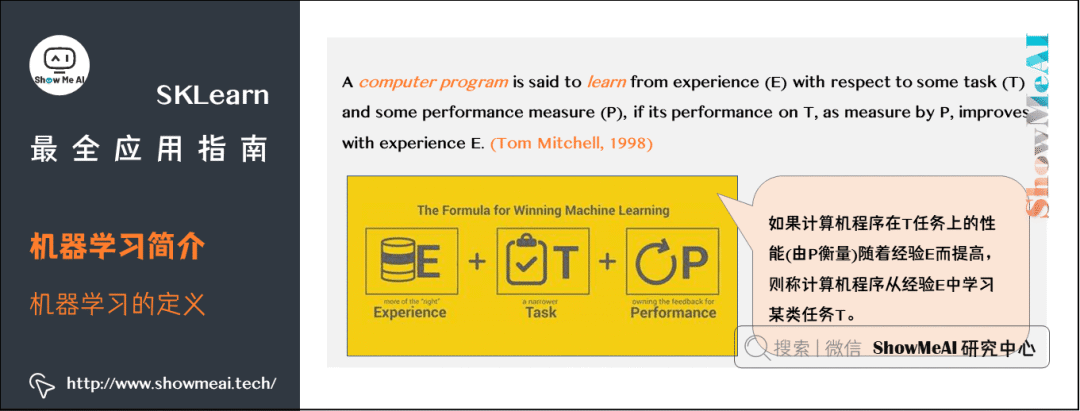
何为机器学习?大师汤姆米切尔(Tom Mitchell)对机器学习定义的原话是:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.
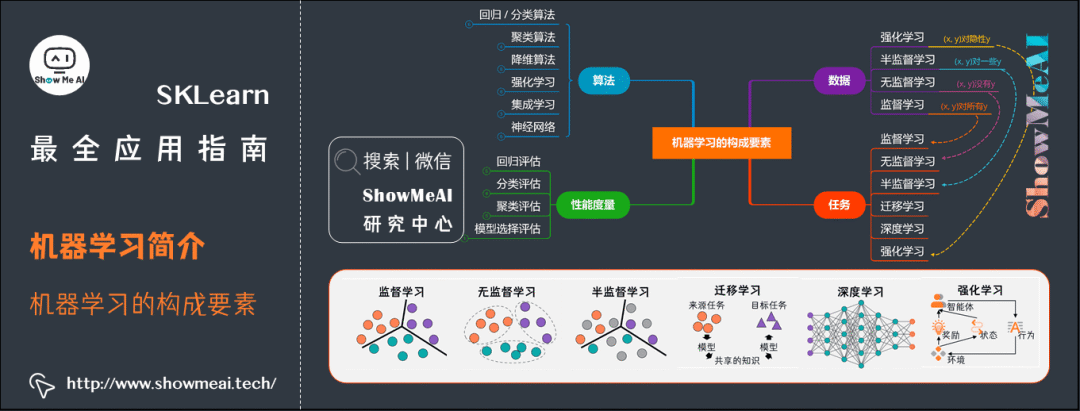
由上述机器学习的定义可知机器学习包含四个元素:
数据(Data)
任务(Task)
性能度量(Quality Metric)
算法(Algorithm)
数据
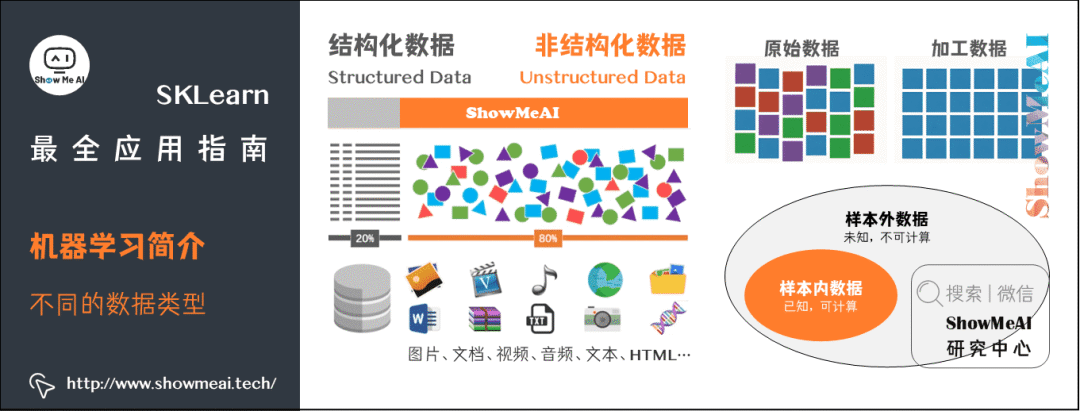
数据(data)是信息的载体。数据可以有以下划分方式:
-
从『数据具体类型』维度划分:结构化数据和非结构化数据。
-
结构化数据(structured data)是由二维表结构来逻辑表达和实现的数据。
-
非结构化数据是没有预定义的数据,不便用数据库二维表来表现的数据。非结构化数据包括图片,文字,语音和视频等。
-
从『数据表达形式』维度划分:原始数据和加工数据。
-
从『数据统计性质』维度划分:样本内数据和样本外数据。
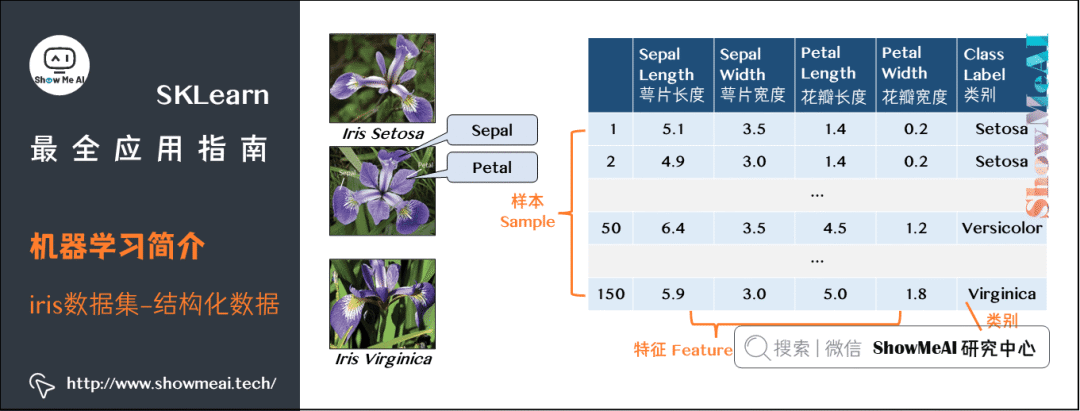
下面术语大家在深入了解机器学习前一定要弄清楚:
每行的记录(这是一朵鸢尾花的数据统计),称为一个『样本(sample)』。
反映样本在某方面的性质,例如萼片长度(Sepal Length)、花瓣长度(Petal Length),称为『特征(feature)』。
特征上的取值,例如『样本1』对应的5.1、3.5称为『特征值(feature value)』。
关于样本结果的信息,例如Setosa、Versicolor,称为『类别标签(class label)』。
包含标签信息的示例,则称为『样例(instance)』,即样例=(特征,标签)。
从数据中学得模型的过程称为『学习(learning)』或『训练(training)』。
在训练数据中,每个样例称为『训练样例(training instance)』,整个集合称为『训练集(training set)』。
任务
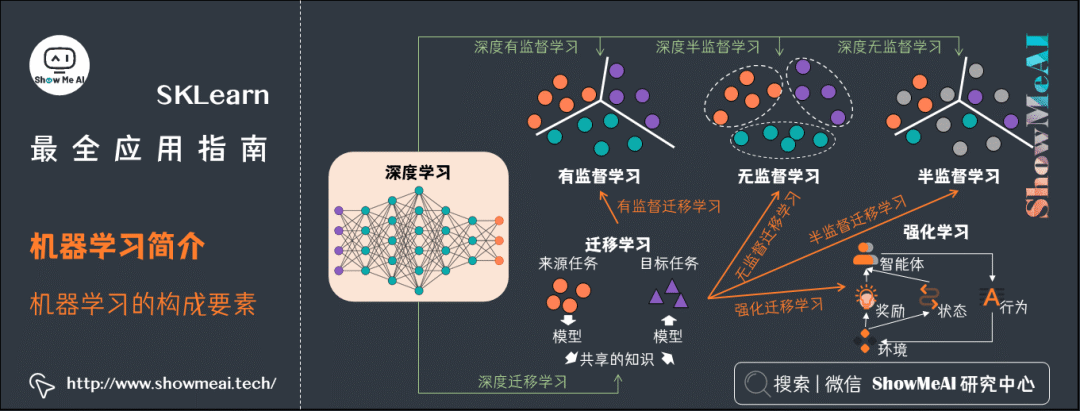
根据学习的任务模式(训练数据是否有标签),机器学习可分为几大类。上图画出机器学习各类之间的关系。
监督学习(有标签)
无监督学习(无标签)
半监督学习(有部分标签)
强化学习(有延迟的标签)
性能度量
回归和分类任务中最常见的误差函数以及一些有用的性能度量如下,详细内容可以参考ShowMeAI文章 机器学习评估与度量准则[7]。


2. SKLearn数据
SKLearn作为通用机器学习建模的工具包,包含六个任务模块和一个数据导入模块:
监督学习:分类任务[8]
监督学习:回归任务[9]
无监督学习:聚类任务[10]
无监督学习:降维任务[11]
模型选择任务[12]
数据预处理任务[13]
数据导入模块[14]
首先看看 SKLearn 默认数据格式和自带数据集。
SKLearn默认数据格式
Sklearn 里模型能直接使用的数据有两种形式:
Numpy二维数组(ndarray)的稠密数据(dense data),通常都是这种格式。
SciPy矩阵(scipy.sparse.matrix)的稀疏数据(sparse data),比如文本分析每个单词(字典有100000个词)做独热编码得到矩阵有很多0,这时用ndarray就不合适了,太耗内存。
自带数据集
SKLearn 里面有很多自带数据集供用户使用。
比如在之前文章Python机器学习算法实践中用到的鸢尾花数据集,包含四个特征(萼片长/宽和花瓣长/宽)和三个类别。
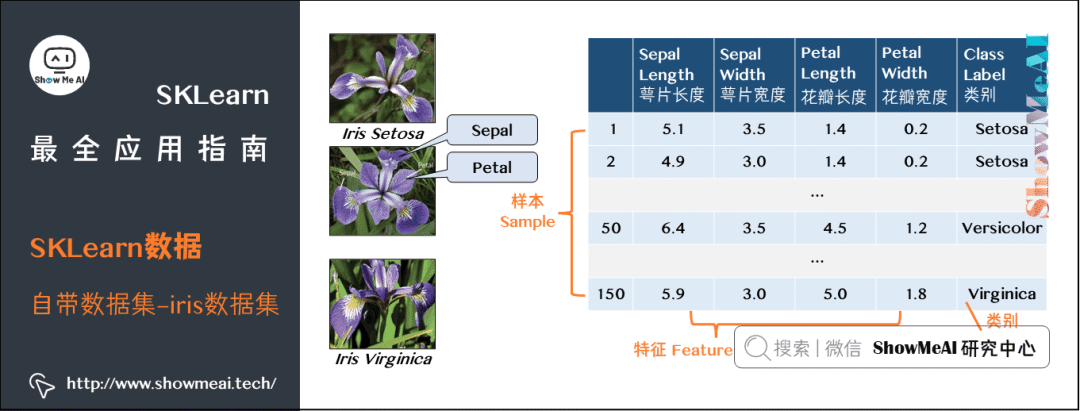
我们可以直接从SKLearn里面的datasets模块中引入,代码如下(代码可以在 线上Jupyter环境[15] 中运行):
# 导入工具库from sklearn.datasets import load_irisiris = load_iris()#数据是以『字典』格式存储的,看看 iris 的键有哪些。iris.keys()
输出如下:
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
读取数据集的信息:
#输出iris 数据中特征的大小、名称等信息和前五个样本。n_samples, n_features = iris.data.shapeprint((n_samples, n_features))print(iris.feature_names)print(iris.target.shape)print(iris.target_names)iris.data[0:5]
构建Dataframe格式的数据集:
# 将X和y合并为Dataframe格式数据import pandas as pdimport seaborn as snsiris_data = pd.DataFrame( iris.data,columns=iris.feature_names )iris_data['species'] = iris.target_names[iris.target]iris_data.head(3).append(iris_data.tail(3))
输出如下:
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
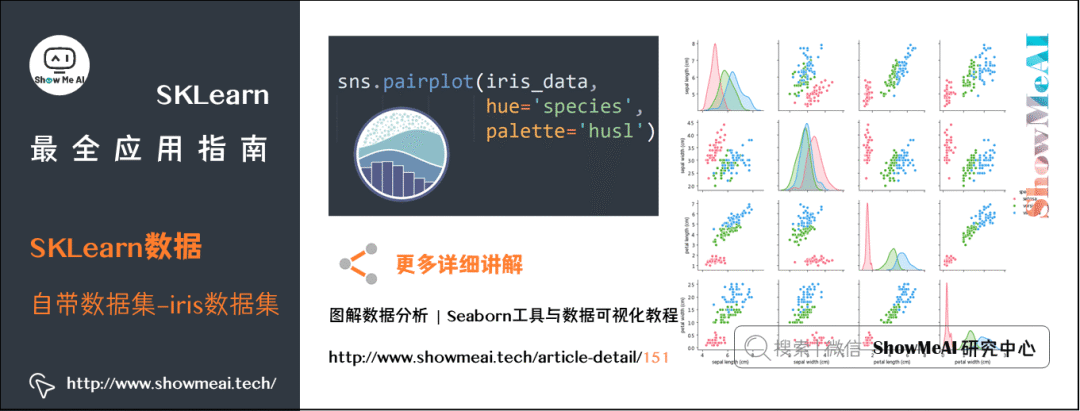
我们使用 seaborn 来做一些数据分析,查看一下数据的分布特性。这里使用到的是成对维度的关联分析,关于seaborn的使用方法可以参阅ShowMeAI的文章 seaborn工具与数据可视化教程[16]。
# 使用Seaborn的pairplot查看两两特征之间的关系sns.pairplot( iris_data, hue='species', palette='husl' )
数据集引入方式
前面提到的是鸢尾花iris数据集,我们通过load_iris加载进来,实际上SKLearn有三种引入数据形式。
打包好的数据:对于小数据集,用sklearn.datasets.load_*
分流下载数据:对于大数据集,用sklearn.datasets.fetch_*
随机创建数据:为了快速展示,用sklearn.datasets.make_*
上面这个星号*指代具体文件名,如果大家在Jupyter这种IDE环境中,可以通过tab制表符自动补全和选择。
datasets.load_
datasets.fetch_
datasets.make_
比如我们调用load_iris
from sklearn importdatasetsdatasets.load_iris
输出如下:
<function sklearn.datasets.base.load_iris(return_X_y=False)>
我们调用load_digits加载手写数字图像数据集
digits = datasets.load_digits()digits.keys()
输出:
dict_keys(['data', 'target', 'target_names', 'images', 'DESCR'])
我们再来看看通过fetch拉取数据的示例:
#加州房屋数据集california_housing = datasets.fetch_california_housing() california_housing.keys()
输出:
dict_keys(['data', 'target', 'feature_names', 'DESCR'])3.SKLearn核心API
我们前面提到SKLearn里万物皆估计器。估计器是个非常抽象的叫法,不严谨的一个理解,我们可以视其为一个模型(用来回归、分类、聚类、降维),或一套流程(预处理、网格搜索交叉验证)。

本节三大API其实都是估计器:
估计器(estimator)通常是用于拟合功能的估计器。
预测器(predictor)是具有预测功能的估计器。
转换器(transformer)是具有转换功能的估计器。
估计器
任何可以基于数据集对一些参数进行估计的对象都被称为估计器,它有两个核心点:
① 需要输入数据。
② 可以估计参数。

估计器首先被创建,然后被拟合。
-
创建估计器:需要设置一组超参数,比如
-
线性回归里超参数normalize=True
-
K均值里超参数n_clusters=5
-
拟合估计器:需要训练集
-
在监督学习中的代码范式为model.fit(X_train, y_train)
-
在无监督学习中的代码范式为model.fit(X_train)
-
model.coef_
-
model.labels_
(1) 线性回归
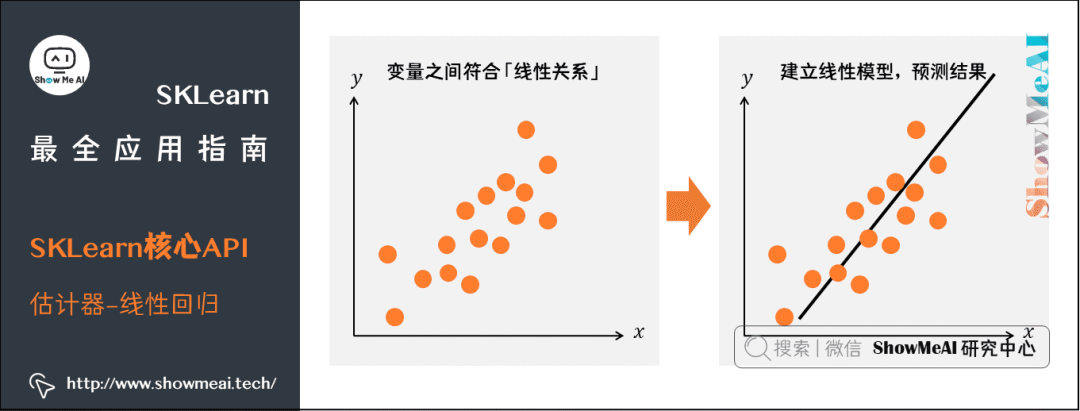
from sklearn.linear_model import LinearRegressionmodel = LinearRegression(normalize=True)model
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=True)
import numpy as npimport matplotlib.pyplot as pltx = np.arange(10)y = 2 * x + 1plt.plot( x, y, 'o' )

X = x[:, np.newaxis]model.fit( X, y )
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=True)
print( model.coef_ )print( model.intercept_ )# 输出结果#[2.]# 0.9999999999999982
(2) K均值
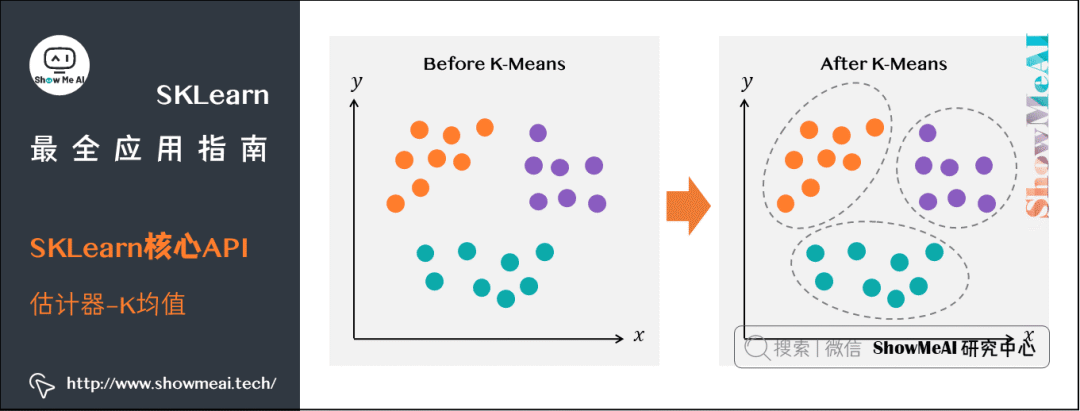
from sklearn.cluster import KMeansmodel = KMeans( n_clusters=3 ) model
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,n_clusters=3, n_init=10, n_jobs=None, precompute_distances='auto',random_state=None, tol=0.0001, verbose=0)
注意下面代码X = iris.data[:,0:2]其实就是提取特征维度。
from sklearn.datasets import load_irisiris = load_iris()X = iris.data[:,0:2]model.fit(X)
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,n_clusters=3, n_init=10, n_jobs=None, precompute_distances='auto',random_state=None, tol=0.0001, verbose=0)
print( model.cluster_centers_, '\n')print( model.labels_, '\n' )print( model.inertia_, '\n')print(iris.target)[[5.77358491 2.69245283][6.81276596 3.07446809][5.006 3.428 ]][2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 1 0 1 0 1 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 1 1 1 0 1 1 1 1 1 1 0 0 1 1 1 1 0 1 0 1 0 1 1 0 0 1 1 1 1 1 0 0 1 1 1 0 1 1 1 0 1 1 1 0 1 1 0] 37.05070212765958 [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
-
model.clustercenters:簇中心。三个簇意味着有三个坐标。
-
model.labels_:聚类后的标签。
-
model.inertia_:所有点到对应的簇中心的距离平方和(越小越好)
小结

# 有监督学习from sklearn.xxx import SomeModel# xxx 可以是 linear_model 或 ensemble 等model = SomeModel( hyperparameter )model.fit( X, y )# 无监督学习from sklearn.xxx import SomeModel# xxx 可以是 cluster 或 decomposition 等model = SomeModel( hyperparameter )model.fit( X )
预测器
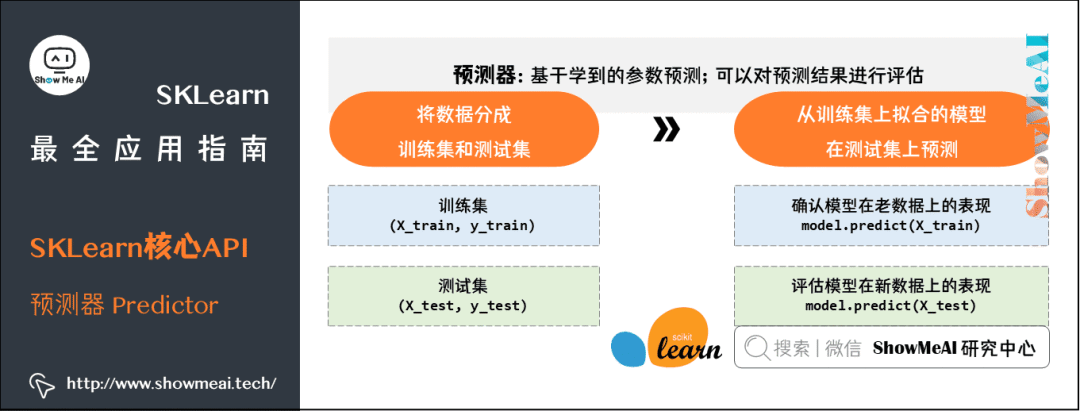
-
model.predict(X_test):评估模型在新数据上的表现。
-
model.predict(X_train):确认模型在老数据上的表现。
from sklearn.datasets import load_irisiris = load_iris()from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split( iris['data'],iris['target'],test_size=0.2 )print( 'The size of X_train is ', X_train.shape )print( 'The size of y_train is ', y_train.shape )print( 'The size of X_test is ', X_test.shape )print( 'The size of y_test is ', y_test.shape )The size of X_train is (120, 4)The size of y_train is (120,)The size of X_test is (30, 4)The size of y_test is (30,)
predict & predict_proba
y_pred = model.predict( X_test )p_pred = model.predict_proba( X_test )print( y_test, '\n' )print( y_pred, '\n' )print( p_pred )
score & decision_function
-
score()返回的是分类准确率。
-
decision_function()返回的是每个样例在每个类下的分数值。
print( model.score( X_test, y_test ) )print( np.sum(y_pred==y_test)/len(y_test) )decision_score = model.decision_function( X_test )print( decision_score )
小结
# 有监督学习from sklearn.xxx import SomeModel# xxx 可以是 linear_model 或 ensemble 等model = SomeModel( hyperparameter )model.fit( X, y )y_pred = model.predict( X_new )s = model.score( X_new )# 无监督学习from sklearn.xxx import SomeModel# xxx 可以是 cluster 或 decomposition 等model = SomeModel( hyperparameter )model.fit( X )idx_pred = model.predict( X_new )s = model.score( X_new )
转换器
-
估计器里fit + predict
-
转换器里fit + transform
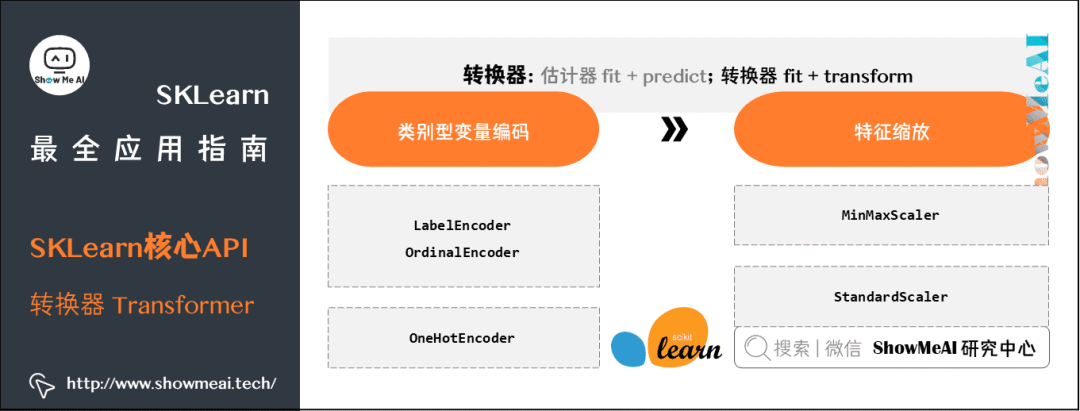
-
将类别型变量(categorical)编码成数值型变量(numerical)
-
规范化(normalize)或标准化(standardize)数值型变量

(1) 类别型变量编码
-
LabelEncoder的输入是一维,比如1d ndarray
-
OrdinalEncoder的输入是二维,比如 DataFrame
# 首先给出要编码的列表 enc 和要解码的列表 dec。enc = ['red','blue','yellow','red']dec = ['blue','blue','red']# 从sklearn下的preprocessing中引入LabelEncoder,再创建转换器起名LE,不需要设置任何超参数。from sklearn.preprocessing import LabelEncoderLE = LabelEncoder()print(LE.fit(enc))print( LE.classes_ )print( LE.transform(dec) )LabelEncoder()['blue' 'yellow' 'red'][0 1 2]
除了LabelEncoder,OrdinalEncoder也可以完成编码。如下代码所示:
from sklearn.preprocessing import OrdinalEncoderOE = OrdinalEncoder()enc_DF = pd.DataFrame(enc)dec_DF = pd.DataFrame(dec)print( OE.fit(enc_DF) )print( OE.categories_ )print( OE.transform(dec_DF) )OrdinalEncoder(categories='auto', dtype=<class 'numpy.float64'>)[array(['blue', 'yellow', 'red'], dtype=object)][[0.][1.][2.]]
-
① 用LabelEncoder编码好的一维数组
-
② DataFrame
from sklearn.preprocessing import OneHotEncoderOHE = OneHotEncoder()num = LE.fit_transform( enc )print( num )OHE_y = OHE.fit_transform( num.reshape(-1,1) )OHE_y[2 0 1 2]
<4x3 sparse matrix of type '<class 'numpy.float64'>'with 4 stored elements in Compressed Sparse Row format>
-
第3行打印出编码结果[2 0 1 2]。
-
第5行将其转成独热形式,输出是一个『稀疏矩阵』形式,因为实操中通常类别很多,因此就一步到位用稀疏矩阵来节省内存。
OHE_y.toarray()
array([[0., 0., 1.],[1., 0., 0.],[0., 1., 0.],[0., 0., 1.]])
OHE = OneHotEncoder()OHE.fit_transform( enc_DF ).toarray()
array([[0., 0., 1.],[1., 0., 0.],[0., 1., 0.],[0., 0., 1.]])
(2) 特征缩放
-
标准化(standardization):每个维度的特征减去该特征均值,除以该维度的标准差。
-
规范化(normalization):每个维度的特征减去该特征最小值,除以该特征的最大值与最小值之差。
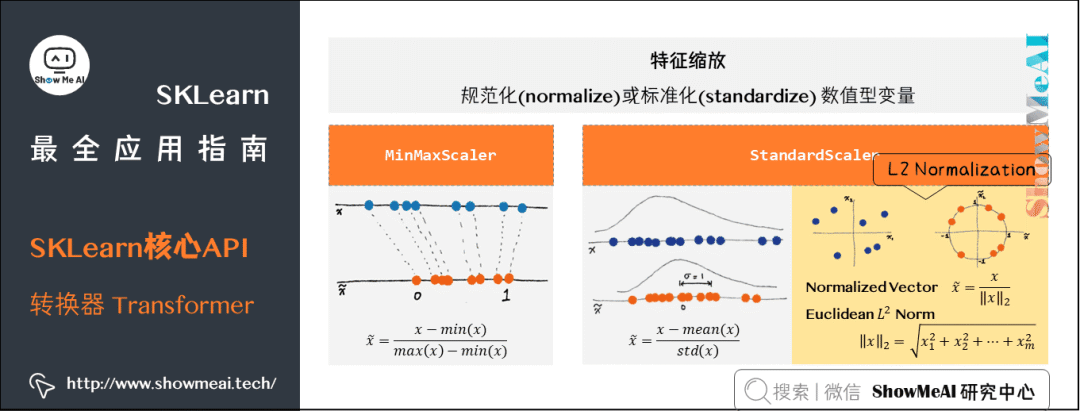
from sklearn.preprocessing import MinMaxScalerX = np.array( [0, 0.5, 1, 1.5, 2, 100] )X_scale = MinMaxScaler().fit_transform( X.reshape(-1,1) )X_scale
array([[0. ],[0.005],[0.01 ],[0.015],[0.02 ],[1. ]])
from sklearn.preprocessing import StandardScalerX_scale = StandardScaler().fit_transform( X.reshape(-1,1) )X_scale
array([[-0.47424487],[-0.46069502],[-0.44714517],[-0.43359531],[-0.42004546],[ 2.23572584]])
注意:
fit()函数只能作用在训练集上,如果希望对测试集变换,只要用训练集上fit好的
转换器去transform即可。不能在测试集上fit再transform,否则训练集和测试
集的变换规则不一致,模型学习到的信息就无效了。
4.高级API
-
ensemble.BaggingClassifier
-
ensemble.VotingClassifier
-
multiclass.OneVsOneClassifier
-
multiclass.OneVsRestClassifier
-
multioutput.MultiOutputClassifier
-
model_selection.GridSearchCV
-
model_selection.RandomizedSearchCV
-
pipeline.Pipeline
Ensemble 估计器
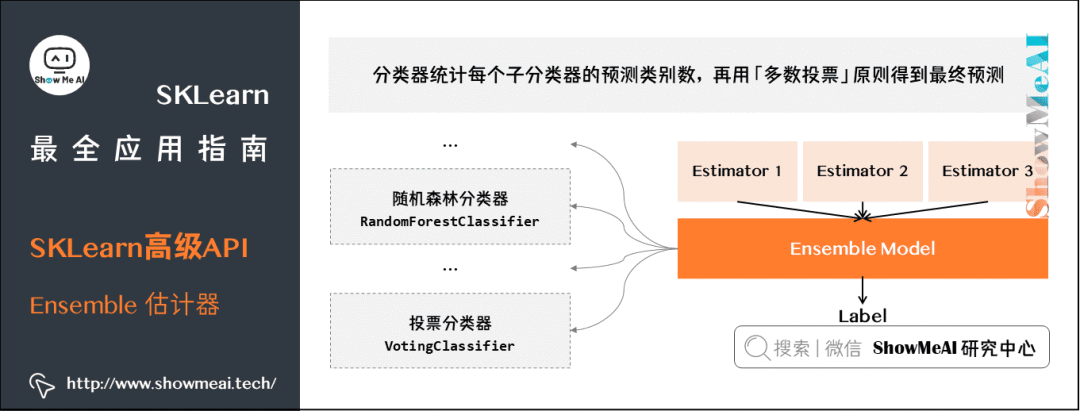
-
AdaBoostClassifier:逐步提升分类器
-
AdaBoostRegressor:逐步提升回归器
-
BaggingClassifier:Bagging分类器
-
BaggingRegressor:Bagging回归器
-
GradientBoostingClassifier:梯度提升分类器
-
GradientBoostingRegressor:梯度提升回归器
-
RandomForestClassifier:随机森林分类器
-
RandomForestRegressor:随机森林回归器
-
VotingClassifier:投票分类器
-
VotingRegressor:投票回归器
-
含同质估计器RandomForestClassifier
-
含异质估计器VotingClassifier
from sklearn.datasets import load_irisiris = load_iris()from sklearn.model_selection import train_test_splitfrom sklearn import metricsX_train, X_test, y_train, y_test = train_test_split(iris['data'], iris['target'], test_size=0.2)
(1) RandomForestClassifier

from sklearn.ensemble import RandomForestClassifierRF = RandomForestClassifier( n_estimators=4, max_depth=5 )RF.fit( X_train, y_train )
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',max_depth=5, max_features='auto', max_leaf_nodes=None,min_impurity_decrease=0.0, min_impurity_split=None,min_samples_leaf=1, min_samples_split=2,min_weight_fraction_leaf=0.0, n_estimators=4,n_jobs=None, oob_score=False, random_state=None,verbose=0, warm_start=False)
rint( RF.n_estimators )RF.estimators_
4[DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=5,max_features='auto', max_leaf_nodes=None,min_impurity_decrease=0.0, min_impurity_split=None,min_samples_leaf=1, min_samples_split=2,min_weight_fraction_leaf=0.0, presort=False,random_state=705712365, splitter='best'),DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=5,max_features='auto', max_leaf_nodes=None,min_impurity_decrease=0.0, min_impurity_split=None,min_samples_leaf=1, min_samples_split=2,min_weight_fraction_leaf=0.0, presort=False,random_state=1026568399, splitter='best'),DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=5,max_features='auto', max_leaf_nodes=None,min_impurity_decrease=0.0, min_impurity_split=None,min_samples_leaf=1, min_samples_split=2,min_weight_fraction_leaf=0.0, presort=False,random_state=1987322366, splitter='best'),DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=5,max_features='auto', max_leaf_nodes=None,min_impurity_decrease=0.0, min_impurity_split=None,min_samples_leaf=1, min_samples_split=2,min_weight_fraction_leaf=0.0, presort=False,random_state=1210538094, splitter='best')]
print ( "RF - Accuracy (Train): %.4g" %metrics.accuracy_score(y_train, RF.predict(X_train)) )print ( "RF - Accuracy (Test): %.4g" %metrics.accuracy_score(y_test, RF.predict(X_test)) )
RF - Accuracy (Train): 1RF - Accuracy (Test): 0.9667
(2) VotingClassifier

from sklearn.linear_model import LogisticRegressionfrom sklearn.naive_bayes import GaussianNBfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.ensemble import VotingClassifierLR = LogisticRegression( solver='lbfgs', multi_class='multinomial' )RF = RandomForestClassifier( n_estimators=5 )GNB = GaussianNB()Ensemble = VotingClassifier( estimators=[('lr', LR), (‘rf', RF), ('gnb', GNB)], voting='hard' )Ensemble. fit( X_train, y_train )
VotingClassifier(estimators=[('lr', LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,intercept_scaling=1, max_iter=100, multi_class='multinomial',n_jobs=None, penalty='12', random_state=None, solver='lbfgs',tol=0.0001, verbose=6, warm_start=False)), ('rf', ...e, verbose=0,warm_start=False)), ('gnb', GaussianNB(priors=None, var_smoothing=1e-09))],flatten_transform=None, n_jobs=None, voting='hard', weights=None)print( len(Ensemble.estimators_) )Ensemble.estimators_
3[LogisticRegression(C=1.0, class_weight-None, dual-False, fit_intercept=True,intercept_scaling=1, max_iter=100, multi_class='multinomial',n_jobs-None, penalty="12", random_state-None, solver='1bfgs',t01=0.0001, verbose=0, warm_start=False),RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',max_depth=None, max_features='auto', max_leaf_nodes=None,min_impurity_decrease-0.0, min_impurity_splitmin_samples_leaf=1, min_samples_split=2,min_weight_fraction_leaf=0.0, n_estimator:oob_score=False, random_state-None, verbose=warm_start=False),GaussianNB(priors-None, var_smoothing=1e-9)]
# 拟合LR.fit( X_train, y_train )RF.fit( X_train, y_train )GNB.fit( X_train, y_train )
# 评估效果print ( "LR - Accuracy (Train): %.4g" % metrics.accuracy_score(y_train, LR.predict(X_train)) )print ( "RF - Accuracy (Train): %.4g" % metrics.accuracy_score(y_train, RF.predict(X_train)) )print ( "GNB - Accuracy (Train): %.4g" % metrics.accuracy_score(y_train, GNB.predict(X_train)) )print ( "Ensemble - Accuracy (Train): %.4g" % metrics.accuracy_score(y_train, Ensemble.predict(X_train)) )print ( "LR - Accuracy (Test): %.4g" % metrics.accuracy_score(y_test, LR.predict(X_test)) )print ( "RF - Accuracy (Test): %.4g" % metrics.accuracy_score(y_test, RF.predict(x_test)) )print ( "GNB - Accuracy (Test): %.4g" % metrics.accuracy_score(y_test, RF.predict(X_test)) )print ( "Ensemble - Accuracy (Test): %.4g" % metrics.accuracy_score(y test, Ensemble.predict(X_test)) )
# 运行结果LR - Accuracy (Train): 0.975RF - Accuracy (Train): 0.9833GNB - Accuracy (Train): 0.95Ensemble - Accuracy (Train): 0.9833LR - Accuracy (Test): 1RF - Accuracy (Test): 1GNB - Accuracy (Test): 1Ensemble - Accuracy (Test): 1
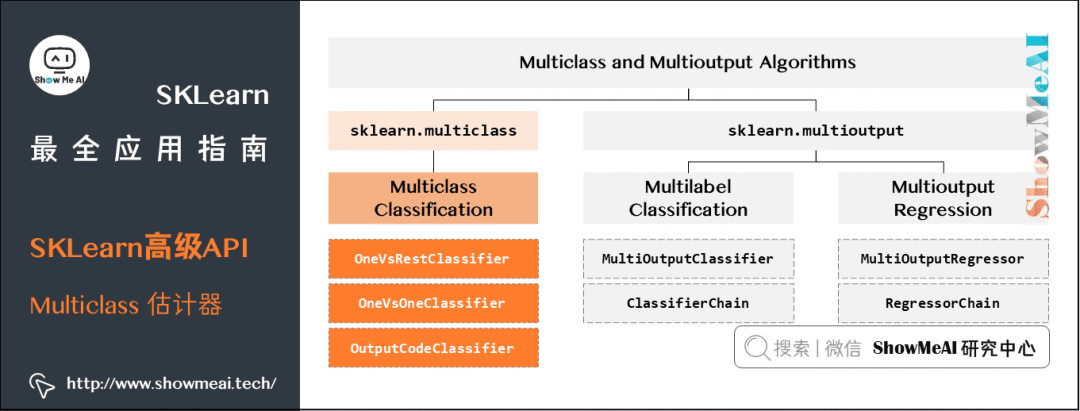
Multiclass 估计器
# 导入数据from sklearn.datasetsimport load_digits digits = load_digits()digits.keys()
# 输出结果dict_keys(['data', 'target', 'target_names','images', 'DESCR'])
下面我们切分数据集:
# 数据集切分X_train, X_test, y_train, y_test = train_test_split( digits['data'], digits['target'], test_size=0.2 )print( 'The size of X_train is ', X_train.shape )print( 'The size of y_train is ', y_train.shape )print( 'The size of X_test is ', X_test.shape )print( 'The size of y_test is ', y_test.shape )
输出如下
The size of X_train is (1437, 64)The size of y_train is (1437,)The size of X_test is (360, 64)The size of y_test is (360,)
训练集和测试集分别有1437和360张图像。每张照片是包含8×8的像素,我们用flatten操作把2维的8×8展平为1维的64。
看看训练集中前100张图片和对应的标签(如下图)。像素很低,但基本上还是能看清。
fig, axes = plt.subplots( 10, 16, figsize=(8, 8) )fig.subplots_adjust( hspace=0.1, wspace=0.1 )for i, ax in enumerate( axes.flat ):ax.imshow( X_train[i,:].reshape(8,8), cmap='binary’, interpolation='nearest’)ax.text( 0.05, 0.05, str(y_train[i]),transform=ax.transAxes, color='blue')ax.set_xticks([])ax.set_yticks([])

(1) 多类别分类
-
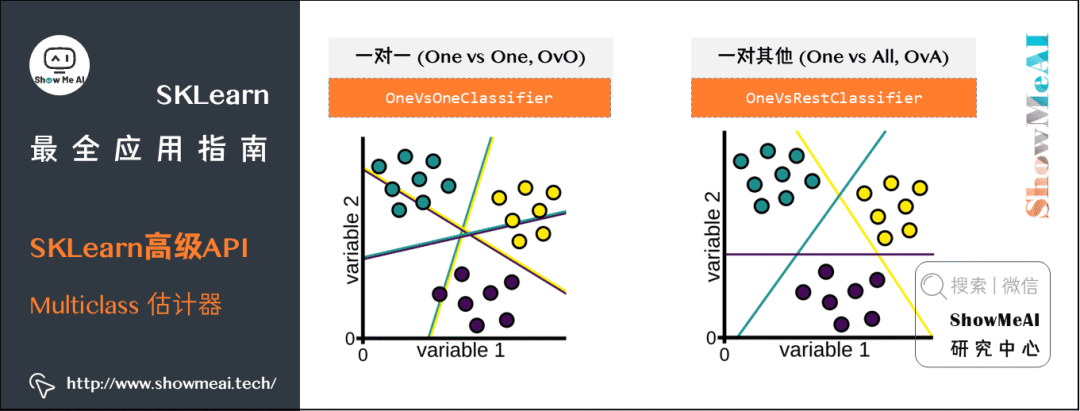
一对一(One vs One,OvO):一个分类器用来处理数字0和数字1,一个用来处理数字0和数字2,一个用来处理数字1和2,以此类推。N个类需要N(N-1)/2个分类器。
-
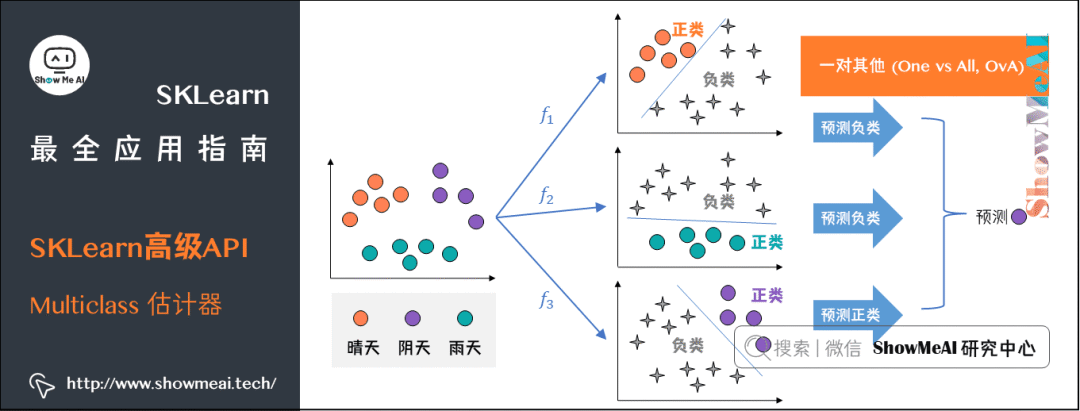
一对其他(One vs All,OvA):训练10个二分类器,每一个对应一个数字,第一个分类『1』和『非1』,第二个分类『2』和『非2』,以此类推。N个类需要N个分类器。
-
f1负责区分橙色和绿色样本
-
f2负责区分橙色和紫色样本
-
f3负责区分绿色和紫色样本

from sklearn.multiclass import OneVsOneClassifierfrom sklearn.linear_model import LogisticRegressionovo_lr = OneVsOneClassifier( LogisticRegression(solver='lbfgs', max_iter=200) )ovo_lr.fit( X_train, y_train )
OnevsOneClassifier(estimator=LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,intercept_scaling=1, max_iter=200, multi_class=‘warn’,n_jobs=None, penalty='12', random_state=None, solver='lbfgs’,tol=0.0001, verbose=6, warm_start=False),n_jobs=None)
10*9/2=45,10类总共45个OvO分类器。
print( len(ovo_lr.estimators_) )ovo_lr.estimators_
45(LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,intercept_scaling=1, max_iter=200, multi_class='warn',n_jobs=None, penalty='12', random_state=None, solver='lbfgs',tol=60.0001, verbose=0, warm_start=False),LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=200, multi_class='warn', n_jobs=None, penalty='l2', random_state=None, solver='lbfgs',tol=0.0001, verbose=0, warm_start=False),LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=200, multi_class='warn', n_jobs=None, penalty='12', random_state=None, solver='lbfgs', tol=60.0001, verbose=0, warm_start=False),LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=200, multi_class='warn', n_jobs=None, penalty="12", random_state=None, solver='lbfgs', tol=0.0001, verbose=0, warm_start=False),LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,...
print ( “OvO LR - Accuracy (Train): %.4g" % metrics.accuracy_score(y_train, ovo_Ir.predict(X_train)) )print ( "OvO LR - Accuracy (Test): %.4g" % metrics.accuracy_score(y_test, ovo_lr.predict(X_test}) )
# 运行结果OvO LR - Accuracy (Train): 1OvO LR - Accuracy (Test): 0.9806
-
图一,某个=橙色,其他=绿色和紫色
-
图二,某个=绿色,其他=橙色和紫色
-
图三,某个=紫色,其他=橙色和绿色
-
f1预测负类,即预测绿色和紫色
-
f2预测负类,即预测橙色和紫色
-
f3预测正类,即预测紫色
三个分类器都预测了紫色,根据多数原则得到的预测是紫色,即阴天。
from sklearn.multiclass import OneVsRestClassifierova_lr = OneVsRestClassifier( LogisticRegression(solver='lbfgs', max_iter=800) )ova_lr.fit( X_train, y_train )
OnevsRestClassifier(estimator=LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=800, multi_class=‘warn’, n_jobs=None, penalty='12', random_state=None, solver='lbfgs’, tol=0.0001, verbose=6, warm_start=False), n_jobs=None)10类总共10个OvA分类器。
print( len(ova_lr.estimators_) )ova_lr.estimators_
结果如下:
10[LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=800, multi_class='warn', n_jobs=None, penalty='12', random_state=None, solver='lbfgs',tol=0.0001, verbose=0, warm_start=False),LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=800, multi_class='warn', n_jobs=None, penalty='12', random_state=None, solver='lbfgs', tol=0.0001, verbose=0, warm_start=False),LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,intercept_scaling=1, max_iter=800, multi_class=‘warn',n_jobs=None, penalty='12', random_state=None, solver="lbfgs',tol=0.0001, verbose=0, warm_start=False),LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,intercept_scaling=1, max_iter=800, multi_class='warn', n_jobs=None, penalty='12', random_state=None, solver='lbfgs', tol=0.0001, verbose=0, warm_start=False),LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,...
print ( “OvA LR - Accuracy (Train): %.4g" % metrics.accuracy_score(y_train, ova_Ir.predict(X_train)) )print ( "OvA LR - Accuracy (Test): %.4g" % metrics.accuracy_score(y_test, ova_lr.predict(X_test}) )物体识别是一个复杂的深度学习问题,我们在这里暂且不深入探讨。我们先看一个简单点的例子,在手写数字的例子上,我们特意为每个数字设计了两个标签:
OvA LR - Accuracy (Train): 6.9993OvA LR - Accuracy (Test}: 6.9639
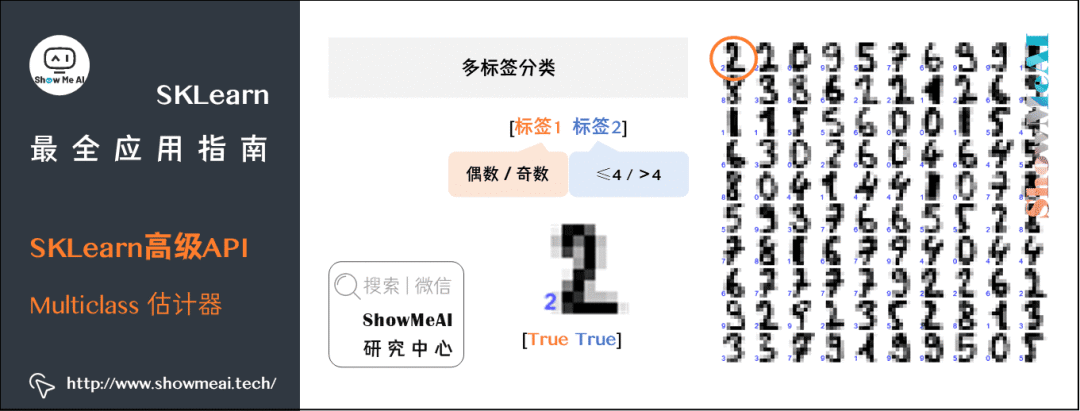
(2) 多标签分类
到目前为止,所有的样例都总是被分配到仅一个类。有些情况下,你也许想让分类器给一个样例输出多个类别。在无人驾驶的应用中,在下图识别出有车和指示牌,没有交通灯和人。

物体识别是一个复杂的深度学习问题,我们在这里暂且不深入探讨。我们先看一个简单点的例子,在手写数字的例子上,我们特意为每个数字设计了两个标签:
-
标签1:奇数、偶数
-
标签2:小于等于4,大于4
from sklearn.multiclass import OneVsRestClassifiery_train_multilabel = np.c_[y_train%2==0, y_train<=4 ]print(y_train_multilabel)
-
[True True]:4是偶数,小于等于4
-
[False False]:5不是偶数,大于4

ova_ml = OneVsRestClassifier( LogisticRegression(solver='lbfgs', max_iter=800) )ova_ml.fit( X_train, y_train_multilabel )
# 运行结果OnevsRestClassifier(estimator=LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=800, multi_class=‘warn’, n_jobs=None, penalty='12', random_state=None, solver='lbfgs', tol=0.0001, verbose=6, warm_start=False), n_jobs=None)
print( len(ova_ml.estimators_) )ova_ml.estimators_
2[LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=800, multi_class=‘warn', n_jobs=None, penalty='12°, random_state=None, solver='lbfgs', tol=0.0001, verbose=0, warm_start=False),LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=800, multi_class='warn', n_jobs=None, penalty='l2', random_state=None, solver='lbfgs', tol=0.0001, verbose=0, warm_start=False) ]
fig, axes = plt.subplots( 10, 10, figsize=(8, 8) )fig.subplots_adjust( hspace=0.1, wspace=0.1 )for i, ax in enumerate( axes.flat ):ax.imshow( X_test[i,:].reshape(8,8), cmap='binary', interpolation='nearest')ax.text( 6.05, 0.05, str(y_test[i]), transform=ax.transAxes, color='blue')ax.set_xticks([])ax.set_yticks([])
print( y_test[:1] )print( ova_ml.predict(X_test[:1,:]) )
[2][[1 1]]
Multioutput 估计器


-
MultiOutputRegressor:多输出回归
-
MultiOutputClassifier:多输出分类
(1) MultiOutputClassifier
from sklearn.multioutput import MultiOutputClassifierfrom sklearn.ensemble import RandomForestClassifier
-
标签1:小于等于4,4和7之间,大于等于7(三类)
-
标签2:数字本身(十类)
y_train_1st = y_train.copy()y_train_1st[ y_train<=4 ] = 0y_train_1st[ np.logical_and{y_train>4, y_train<7) ] = 1y_train_ist[ y_train>=7 ] = 2y_train_multioutput = np.c_[y_train_1st, y_train]y_train_multioutput
array( [[0, 4],[],[],[],[],[]])
用含有100棵决策树的随机森林来解决这个多输入分类问题。
MO = MultiOutputClassifier( RandomForestClassifier(n_estimators=100) )MO.fit( X_train, y_train_multioutput )
# 结果MultiOutputClassifier(estimator=RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=None, oob_score=False, random_state=None, verbose=0, warm_start=False), n_jobs=None)
MO.predict( X_test[:5,:] )
array([[0, 2],[0, 2],[0, 0],[2, 9],[1, 5]])

y_test_1st = y_test.copy()y_test_1st[ y_test<=4 ] = 0y_test_1st[ np.logical_and(y_test>4, y_test<7) ] = 1y_test_1st[ y_test>=7 ] = 2y_test_multioutput = np.c_[ y_test_1st, y_test ]y_test_multioutput[:5]
array([[0, 2],[0, 2],[0, 0],[2, 9],[1, 5]])
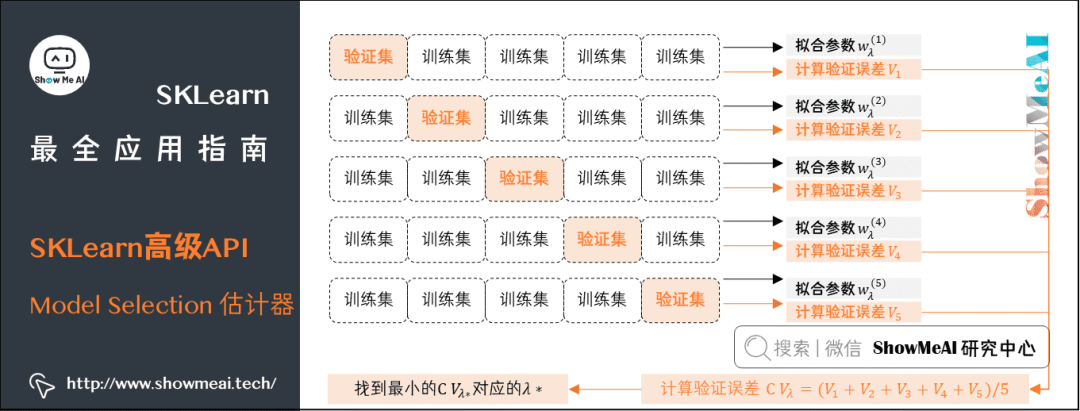
Model Selection 估计器
-
cross_validate:评估交叉验证的结果。
-
learning_curve:构建与绘制学习曲线。
-
GridSearchCV:用交叉验证从超参数候选网格中搜索出最佳超参数。
-
RandomizedSearchCV:用交叉验证从一组随机超参数搜索出最佳超参数。
(1) 交叉验证
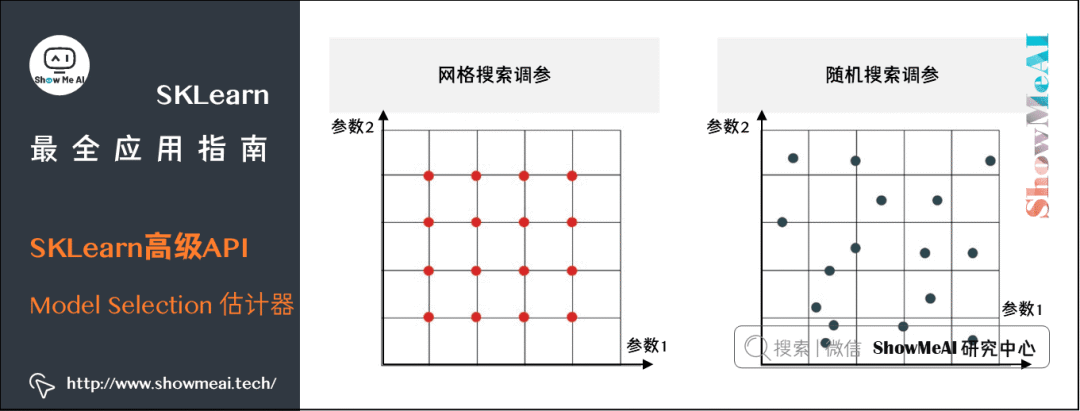
from time import timefrom scipy.stats import randintfrom sklearn.model_selection import GridSearchCvfrom sklearn.model_selection import RandomizedSearchcCvfrom sklearn.ensemble import RandomForestClassifierX, y = digits.data, digits.targetRFC = RandomForestClassifier(n_estimators=20)# 随机搜索/Randomized Searchparam_dist = { "max_depth": [3, 5],"max_features": randint(1, 11),"min_samples_split": randint(2, 11),"criterion": ["gini", "entropy"]}n_iter_search = 20random_search = RandomizedSearchCv( RFC, param_distributions=param_dist, n_iter=n_iter_search, cv=5 )}start = time()random_search.fit(X, y)print("RandomizedSearchCv took %.2f seconds for %d candidates,parameter settings." % ((time() - start), n_iter_search))print( random_search.best_params_ )print( random_search.best_score_ )# 网格搜索/Grid Searchparam_grid = { "max_depth": [3, 5],"max_features": [1, 3, 10],"min_samples_ split": [2, 3, 10],"criterion": ["gini", "entropy"]}grid_search = GridSearchCV( RF, param_grid=param_grid, cv=5 )start = time()grid_search.fit(X, y)print("\nGridSearchcv took %.2f seconds for %d candidate parameter settings." % (time() - start, len(grid_search.cv_results_['params'])))print( grid_search.best_params_ )print( grid_search.best_score_ )
RandomizedSearchCv took 3.73 seconds for 20 candidates parameter settings.{'criterion': 'entropy', '*max_depth': 5, 'max_features': 6, 'min_samples_split': 4}0.8898163606010017GridSearchCV took 2.30 seconds for 36 candidate parameter settings.{'criterion': 'entropy', 'max_depth': 5, 'max_features': 10, 'min_samples_ split': 10}0.841402337228714S5
-
前5行引入相应工具库。
-
第7-8行准备好数据X和y,创建一个含20个决策树的随机森林模型。
-
第10-14和23-27行为对随机森林的超参数『最大树深、最多特征数、最小可分裂样本数、分裂标准』构建候选参数分布与参数网格。
-
第15-18行是运行随机搜索。
-
第18-30行是运行网格搜索。
-
第一行输出每种追踪法运行的多少次和花的时间。
-
第二行输出最佳超参数的组合。
-
第三行输出最高得分。
Pipeline 估计器
(1) Pipeline
-
如果最后一个估计器是预测器,那么Pipeline是预测器。
-
如果最后一个估计器是转换器,那么Pipeline是转换器。
X = np.array([[56,40,30,5,7,10,9,np.NaN,12],[1.68,1.83,1.77,np.NaN,1.9,1.65,1.88,np.NaN,1.75]])X = np.transpose(X)
-
处理缺失值的转换器SimpleImputer。
-
做规划化的转换器MinMaxScaler。
from sklearn.pipeline import Pipelinefrom sklearn.impute import SimpleImputerfrom sklearn.preprocessing import MinMaxScalerpipe = Pipeline([('impute', SimpleImputer(missing_values=np.nan, strategy='mean')),('normalize', MinMaxScaler())])
第5-7行创建了流水线,使用方式非常简单,在Pipeline()里输入(名称,估计器)这个元组构建的流水线列表。在本例中SimpleImputer起名叫impute,MinMaxScaler起名叫normalize。
X_proc = pipe.fit_transform( X )
X_impute = SimpleImputer(missing values=np.nan, strategy='mean').fit_transform( X )X_impute
# 运行结果array( [[50, 1.68],[40, 1.83],[30, 1.77],[5, 1.78],[7, 1.9 ],[10, 1.65],[9, 1.88],[20.375, 1.78],[12, 1.75 ]])
X_normalize = MinMaxScaler().fit_transform( X_impute )X_normalize
运行结果
array( [[1., 0.12 ],[0.77777778, 0.72],[0.55555556, 6.48],[0.52, 1],[0.04444444, 1.],[0.11111111, 9.],[0.08888889, 6.92],[0.34166667, 6.52],[0.15555556, 0.4 ]])
(2) FeatureUnion
-
前两列字段『智力IQ』和『脾气temper』都是类别型变量。
-
后两列字段『收入income』和『身高height』都是数值型变量。
-
每列中都有缺失值。
d= { 'IQ' : ['high','avg','avg','low', high', avg', 'high', 'high',None],'temper' : ['good', None,'good', 'bad', 'bad','bad', 'bad', None, 'bad'],'income' : [50,40,30,5,7,10,9,np.NaN,12],'height' : [1.68,1.83,1.77,np.NaN,1.9,1.65,1.88,np.NaN,1.75]}X = pd.DataFrame( d )X
结果如下:
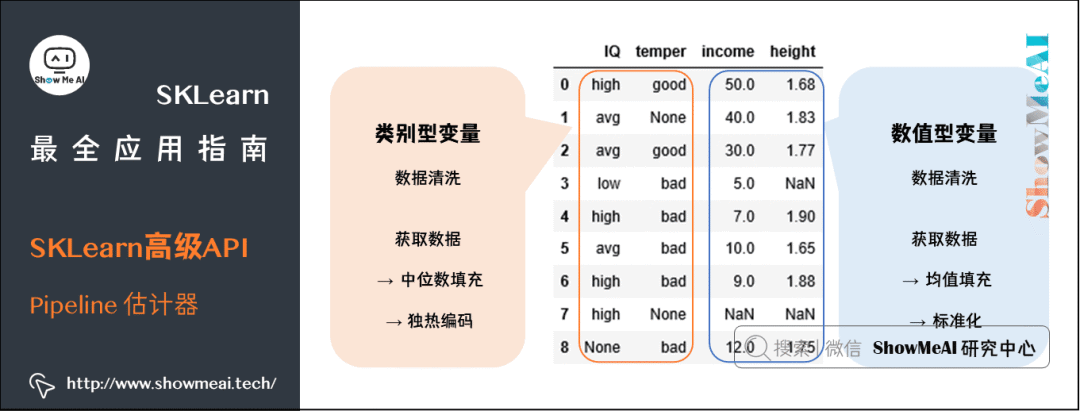
我们现在按下列步骤来清洗数据。
对类别型变量:获取数据 → 中位数填充 → 独热编码
对数值型变量:获取数据 → 均值填充 → 标准化
上面两步是并行进行的。
首先我们自己定义一个从DataFrame里面获取数据列的类,起名叫DataFrameSelector。
from sklearn.base import BaseEstimator, TransformerMixinclass DataFrameSelector( BaseEstimator, TransformerMixin ):def _init_( self, attribute_names ):self.attribute_names = attribute_namesdef fit( self, X, y=None ):return selfdef transform( self, X ):return X[self.attribute_names].values
上述代码在transform函数中,我们将输入的DataFrame X根据属性名称来获取其值。
接下来建立流水线full_pipe,它并联着两个流水线:
-
categorical_pipe处理分类型变量
-
DataFrameSelector用来获取
-
SimpleImputer用出现最多的值来填充None
-
OneHotEncoder来编码返回非稀疏矩阵
-
numeric_pipe处理数值型变量
-
DataFrameSelector用来获取
-
SimpleImputer用均值来填充NaN
-
normalize来规范化数值
from sklearn.pipeline import Pipelinefrom sklearn.pipeline import FeatureUnionfrom sklearn.impute import SimpleImputerfrom sklearn.preprocessing import MinMaxScalerfrom sklearn.preprocessing import OneHotEncodercategorical features = ['IQ', 'temper']numeric_features = ['income', 'height']categorical pipe = Pipeline([('select', DataFrameSelector(categorical_features)),('impute', SimpleImputer(missing values=None, strategy='most_frequent')),('one_hot_encode', OneHotEncoder(sparse=False))])numeric_pipe = Pipeline([('select', DataFrameSelector(numeric_features)),('impute', SimpleImputer(missing values=np.nan, strategy='mean')),('normalize', MinMaxScaler())])full_pipe = FeatureUnion( transformer_list=[('numeric_pipe', numeric_pipe),('categorical_pipe', categorical_pipe)])
X_proc = full_pipe.fit_transform( X )print( X_proc )
[[1. 0.12 0. 1. 0. 0. 1. ][0.77777778 0.72 1. 0. 0. 1. 0. ][0.55555556 0.48 1. 0. 0. 0. 1. ][0. 0.52 0. 0. 1. 1. 0. ][0.04444444 1. 0. 1. 0. 1. 0. ][0.11111111 0. 1. 0. 0. 1. 0. ][0.08888889 0.92 0. 1. 0. 1. 0. ][0.34166667 0.52 0. 1. 0. 1. 0. ][0.15555556 0.4 0. 1. 0. 1. 0. ]]
5.总结
下面我们对上面讲解到的sklearn工具库应用知识做一个总结。
SKLearn五大原则
SKLearn的设计下,它的主要API遵循五大原则
(1) 一致性
所有对象的接口一致且简单,在『估计器』中
创建:model = Constructor(hyperparam)
拟参:
有监督学习:model.fit(X_train, y_train)
无监督学习:model.fit(X_train)
在『预测器』中
有监督学习里预测标签:y_pred = model.predict(X_test)
无监督学习里识别模式:idx_pred = model.predict( Xtest)
在『转换器』中
创建:trm = Constructor(hyperparam)
获参:trm.fit(X_train)
转换:X_trm = trm.transform(X_train)
(2) 可检验
所有估计器里设置的超参数和学到的参数都可以通过实例的变量直接访问来检验其值,区别是超参数的名称最后没有下划线_,而参数的名称最后有下划线_。举例如下:
通例:model.hyperparameter
特例:SVC.kernel
通例:model.parameter_
特例:SVC.support_vectors_
(3) 标准类
SKLearn模型接受的数据集的格式只能是『Numpy数组』和『Scipy稀疏矩阵』。超参数的格式只能是『字符』和『数值』。不接受其他的类!
(4) 可组成
模块都能重复『连在一起』或『并在一起』使用,比如两种形式流水线(pipeline)。
任意转换器序列
任意转换器序列+估计器
(5) 有默认
SKLearn给大多超参数提供了合理的默认值,大大降低了建模的难度。
SKLearn框架流程
sklearn的建模应用流程框架大概如下:
(1) 确定任务
是『有监督』的分类或回归?还是『无监督』的聚类或降维?确定好后基本就能知道用Sklearn里哪些模型了。
(2) 数据预处理
这步最繁琐,要处理缺失值、异常值;要编码类别型变量;要正规化或标准化数值型变量,等等。但是有了Pipeline神器一切变得简单高效。
(3) 训练和评估
这步最简单,训练用估计器fit()先拟合,评估用预测器predict()来评估。
(4) 选择模型
启动ModelSelection估计器里的GridSearchCV和RandomizedSearchCV,选择得分最高的那组超参数(即模型)。
参考资料
加入知识星球【我们谈论数据科学】
600+小伙伴一起学习!