
一个悄然崛起的国产开源项目
转自 GitHubDaily
大家好,我是小 G。
此前,我曾在公众号推荐过 GitHub 上一个性能颇为强悍的国产 AI 开源项目:Colossal-AI,作为一个大规模并行 AI 训练系统、深度学习框架的内核,该项目可帮助用户便捷实现最大化提升 AI 部署效率,同时最小化部署成本。
仅需一半数量的 GPU,便能完成相同效果的 GPT-3 训练工作,极大降低了项目研发成本。

GitHub 地址:https://github.com/hpcaitech/ColossalAI
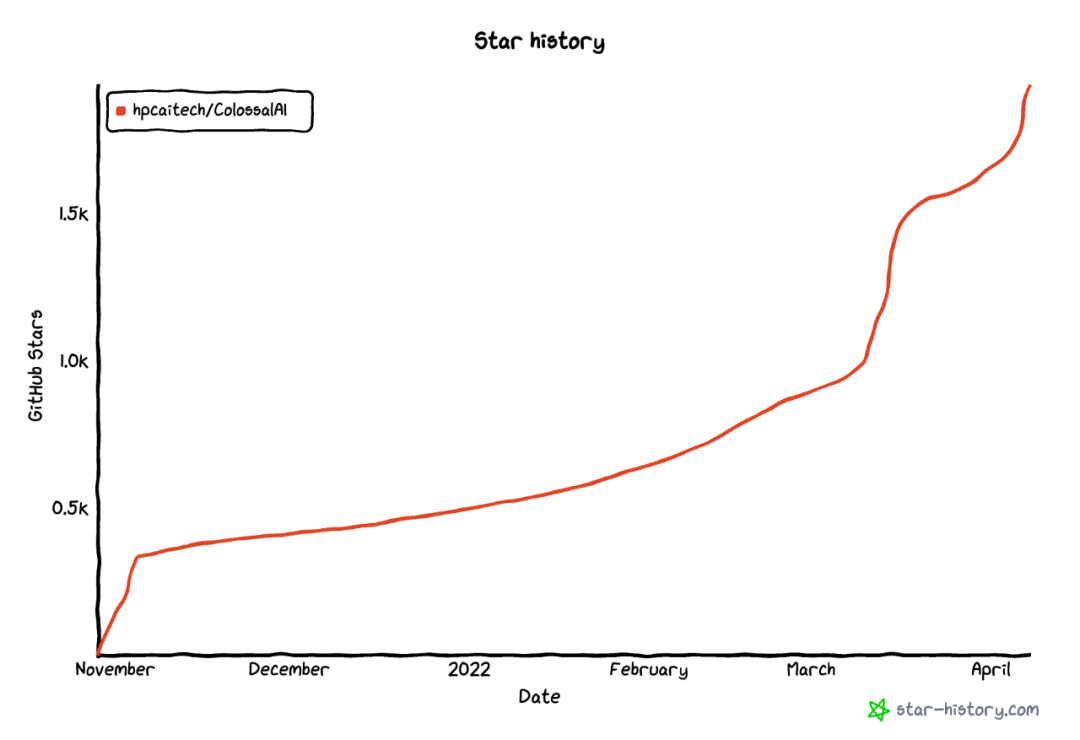
Colossal-AI 一经开源便受到广泛关注,连续多日登上 GitHub Python 方向世界第一的位置,与众多已有数万 star 的明星开源项目一起受到海内外关注!
世界顶尖的人工智能机构 Hugging Face 也主动与 Colossal-AI 接洽合作,对于一个国产项目来说,受到如此关注,这也从侧面反映出了它的实力。
近日,经过开发者们的不断努力后,Colossal-AI 在数月的密集测试后迎来正式版!此版本由 300 多次 commits 组成。
本次正式版更新重点优化了分布式训练性能及开发者的易用性,主要亮点包括:
重构 ZeRO 以改善性能和易用性;
添加细粒度 Profiler TensorBoard 监控插件,监测训练过程中内存、网络等状态;
更灵活的 checkpoint 策略,可扩展的 pipeline 模块;
开源蛋白质预测 FastFold 等丰富行业解决方案;
添加中文教程,PaLM、MOE、BERT等实例,开放用户社群及论坛。
专业助力大模型训练
近年来,随着深度学习的兴起及大模型横扫各大性能榜单,前沿 AI 模型的大小在短短几年内便已增大万倍,远超硬件数倍的缓慢增长。前沿 AI 大模型不仅远超单个 GPU 的容纳能力,所需算力也往往需要单个 GPU 运行数百甚至上千年。
因此,如何提升单个 GPU 的容纳能力,如何高效利用分布式技术,联合多个 GPU 低成本实现并行训练加速已成为 AI 大模型的关键痛点。
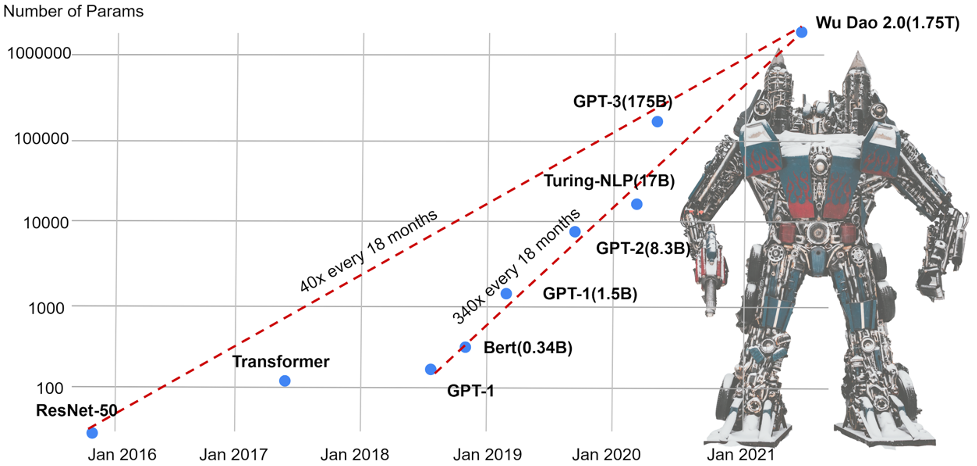
针对现有方案并行维度有限、效率不高、通用性差、部署困难、缺乏维护等痛点,Colossal-AI 通过高效多维并行、显存优化、大规模优化库、细粒度监测等方式,让用户仅需极少量修改,即可高效快速部署 AI 大模型训练。
多维并行
相比现有方案中并行维度仅包括数据并行、一维张量并行、流水并行三种方案,Colossal-AI 进一步提供 2/2.5/3 维张量并行和序列并行,以及便捷的多维混合并行解决方案。
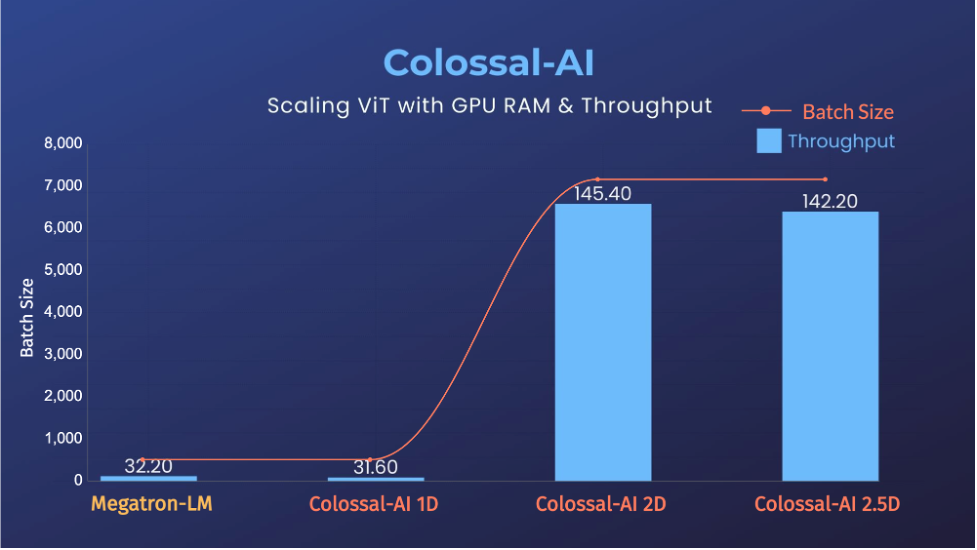
△ViT 张量并行为 64 时,可提升 14 倍批大小和 5 倍训练速度
其中,高维张量并行能极大减轻显存消耗,提升通信效率,使得计算资源利用更加高效。
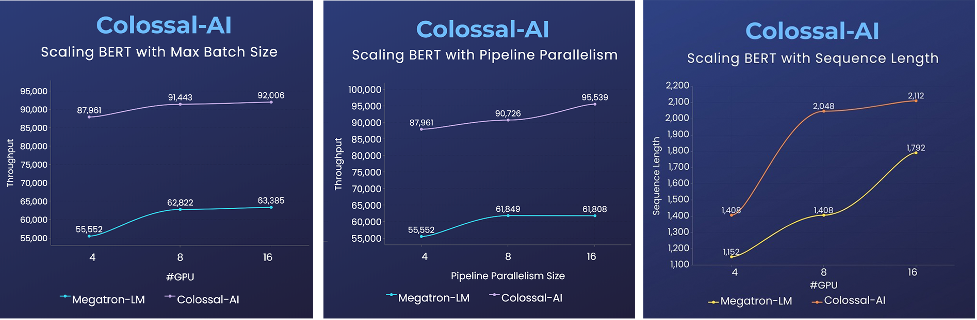
△序列并行帮助 BERT 提升 2 倍训练速度,或 1.5 倍序列长度
而序列并行针对大图片、视频、长文本、长时间医疗监测等数据,可以帮助突破原有机器能力限制,直接处理长序列数据。
显存优化
Colossal-AI 综合了多重显存优化技术,包含多维并行,ZeRO 冗余内存消除,CPU offload,Gradient Checkpoint,自动混合精度(AMP)等前沿技术,最大限度帮助用户避免显存瓶颈,降低训练的硬件需求。
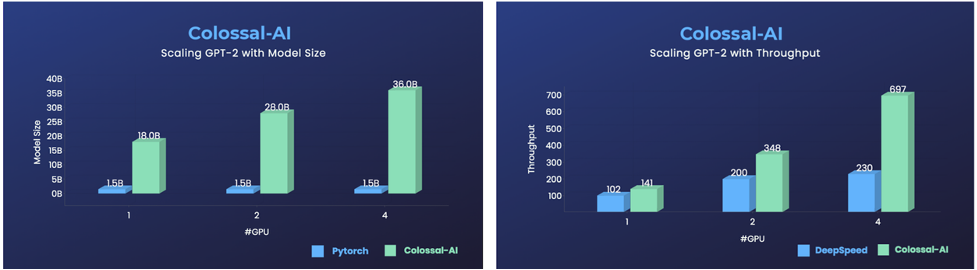
△GPT-2 使用 Colossal-AI,同样硬件下提升 24 倍可训练模型大小,或 3 倍训练速度
灵活易用
Colossal-AI 接口设计与 PyTorch 风格保持一致,降低学习和使用成本,仅需极少量修改,便可将已有项目与 Colossal-AI 结合,便捷扩展至大规模并行。此外,该系统还保持了优秀的扩展性,便于根据需求添加新功能,与已有功能模块兼容。
细粒度监测:细粒度 Profiler TensorBoard 插件,相较于 PyTorch 仅能以 iteration 为单位进行记录训练过程,Colossal-AI 能够监测 iteration 内的网络、通信、内存等状态,方便开发者进行精确分析和调试,提高开发效率。
大规模优化库:Colossal-AI 提供大规模并行优化器 LAMB、LARS 等,首次将训练 batch size 扩展到 65536。Colossal-AI 还与 PyTorch 自带各类 optimizer 兼容,并不断探索添加最新前沿优化技术,满足各类模型需求。
丰富的行业解决方案
Colossal-AI 目前已与自动驾驶、云计算、零售、医药、芯片等行业知名厂商达成合作,与 AI 领域顶级开源组织 Hugging Face 等建立合作。
蛋白质结构预测加速方案:FastFold
AlphaFold 因强大的 AI 预测蛋白质结构能力被 Science 和 Nature 评选为 2021 年十大科学突破之首,但存在训练时间长、成本高等问题。
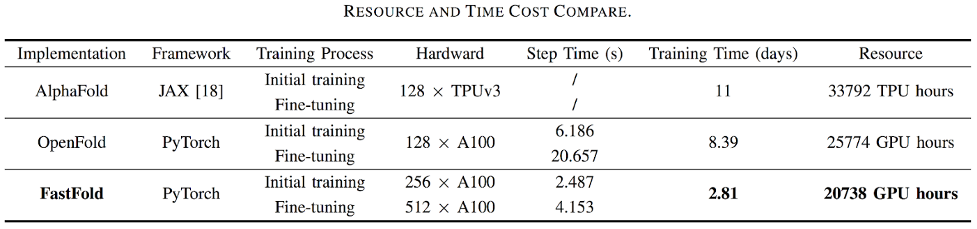
△图片来源:https://arxiv.org/pdf/2203.00854.pdf
基于 Colossal-AI 的加速方案 FastFold,将 GPU 优化和大模型训练技术引入 AlphaFold 的训练和推理,成功超越谷歌和哥伦比亚大学的方案,将 AlphaFold 训练时间从 11 天减少到 67 小时,且总成本更低,在长序列推理中也实现 9.3~11.6 倍的速度提升。
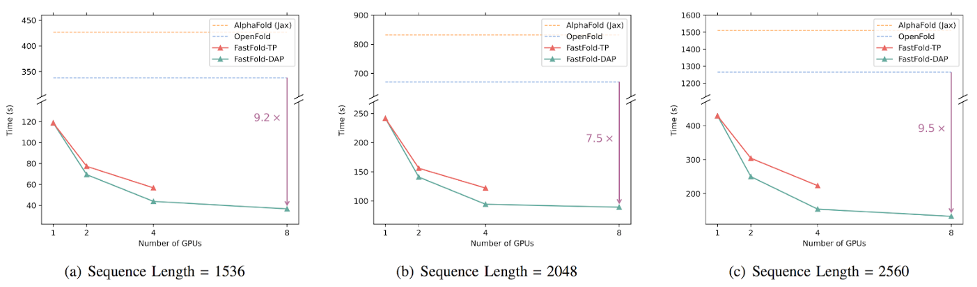
△长序列推理性能对比
半数 GPU 训练 GPT-3

对于超大 AI 模型,如 GPT-3,相比英伟达方案,Colossal-AI 仅需一半的计算资源,即可启动训练;若使用相同计算资源,则能提速 11%,可降低 GPT-3 训练成本超百万美元。
Colossal-AI 注重开源社区建设,提供中文教程,开放用户社群及论坛,对于用户反馈进行高效交流与迭代更新,不断添加 PaLM、MOE 等前沿应用。
项目团队
潞晨技术团队的核心成员均来自美国加州大学伯克利分校,斯坦福大学,清华大学,北京大学,新加坡国立大学,新加坡南洋理工大学等国内外知名高校;拥有 Google Brain、IBM、Intel、 Microsoft、NVIDIA 等知名厂商工作经历。公司成立即获得创新工场、真格基金等多家顶尖 VC 机构种子轮投资。

△潞晨科技创始人尤洋教授:加州大学伯克利分校博士、IPDPS/ICPP 最佳论文、ACM/IEEE George Michael HPC Fellowship、福布斯 30 岁以下精英 (亚洲 2021)、IEEE-CS 超算杰出新人奖、UC 伯克利 EECS Lotfi A. Zadeh 优秀毕业生奖

△潞晨 CSO Prof. James Demmel:加州大学伯克利分校杰出教授、ACM/IEEE Fellow,美国科学院、工程院、艺术与科学院三院院士
传送门
论文地址:https://arxiv.org/abs/2110.14883
项目地址:https://github.com/hpcaitech/ColossalAI
文档地址:https://www.colossalai.org/
* 本文观点参考链接:
https://medium.com/@hpcaitech/5-must-follow-features-that-are-seeing-colossal-ais-success-2d5361e27e4b