
数据流管理方案 | Redux 和 MobX 哪个更好?
嗨,我是你稳定更新、持续输出的勾勾。

面试中常问的一道问题就是“你了解哪些数据流管理方案”,面对这样的提问,先搞懂为什么要学数据流管理,再来梳理、对比你所知道的方案。真正的前端开发,不仅仅要面试造火箭,实际工作中依然需要这样的能力。
数据流管理方案有哪些?
基于 props 的单向数据流
父->子组件通信
原理讲解:这是最常见、也是最好解决的一个通信场景。React 的数据流是单向的,父组件可以直接将 this.props 传入子组件,实现父-子间的通信。
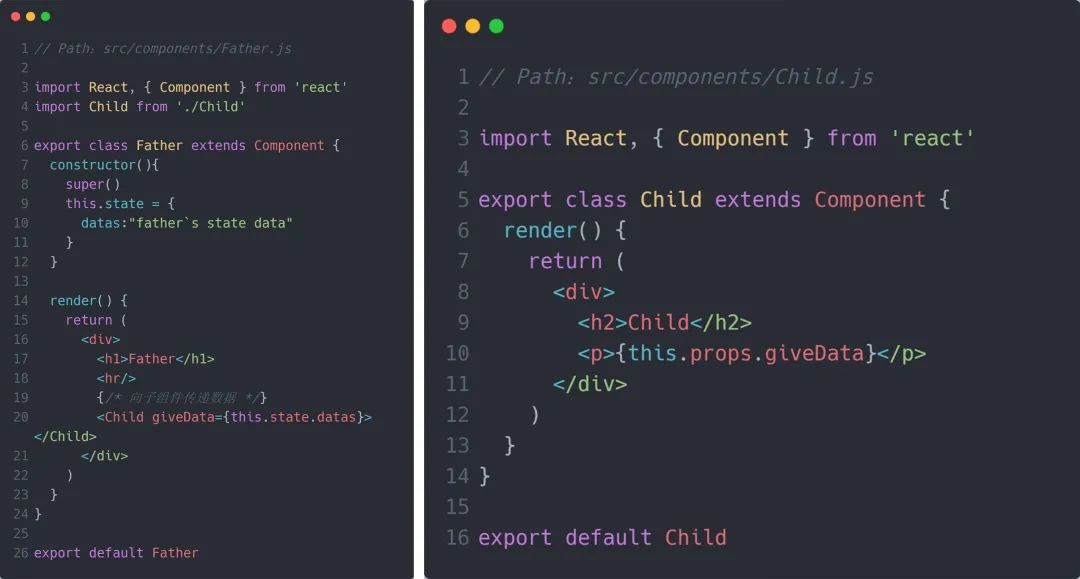
子->父组件通信
考虑到 props 是单向的,子组件并不能直接将自己的数据塞给父组件,但 props 的形式也可以是多样的。假如父组件传递给子组件的是一个绑定了自身上下文的函数,那么子组件在调用该函数时,就可以将想要交给父组件的数据以函数入参的形式给出去,以此来间接地实现数据从子组件到父组件的流动。

兄弟组件通信
兄弟组件之间共享了同一个父组件,如下图所示,这是一个非常重要的先决条件。
在上面的组件间通信中,直接兄弟间的通信需要借助父级组件实现。原理也很简单,就是回调函数加 Props 属性。但是如果不是直接兄弟,那么,基于回调函数和 Props 的单向数据流,在实现跨组件通信时会无限增加代码量,而且也无法做到状态同步以及状态共享。
使用 Context API 维护全局状态
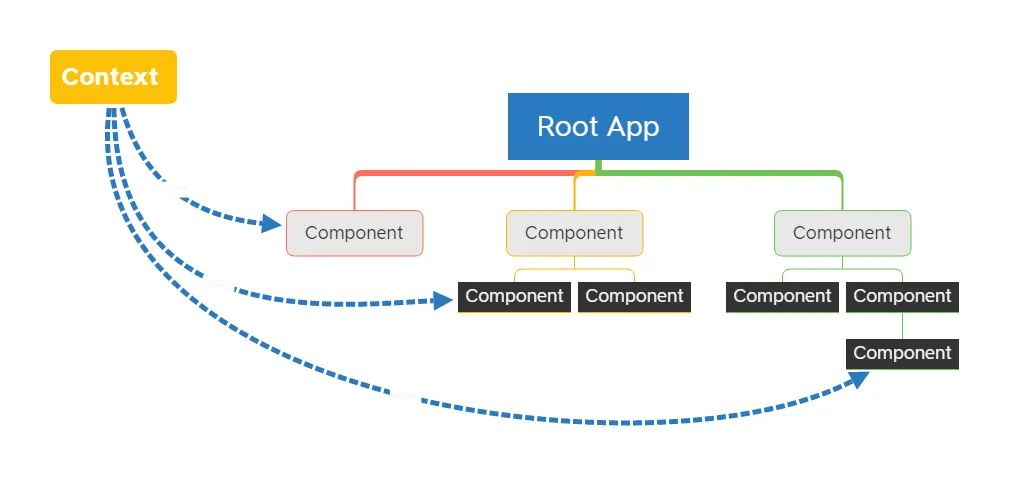
Context API 是 React 官方提供的一种组件树全局通信的方式。在 React 16.3 之前,Context API 由于存在种种局限性,并不被 React 官方提倡使用。从 16.3 这个版本开始,React 对 Context API 进行了改进,新的 Context API 具备更强的可用性。
Context API 有 3 个关键的要素:React.createContext、Provider、Consumer。
我们通过调用 React.createContext,可以创建出一组 Provider。Provider 作为数据的提供方,可以将数据下发给自身组件树中任意层级的 Consumer。
注意:Cosumer 不仅能够读取到 Provider 下发的数据,还能读取到这些数据后续的更新。这意味着数据在生产者和消费者之间能够及时同步,这对 Context 这种模式来说至关重要。
接着,我们在代码中展示具体的用法,重点部分加了注释:
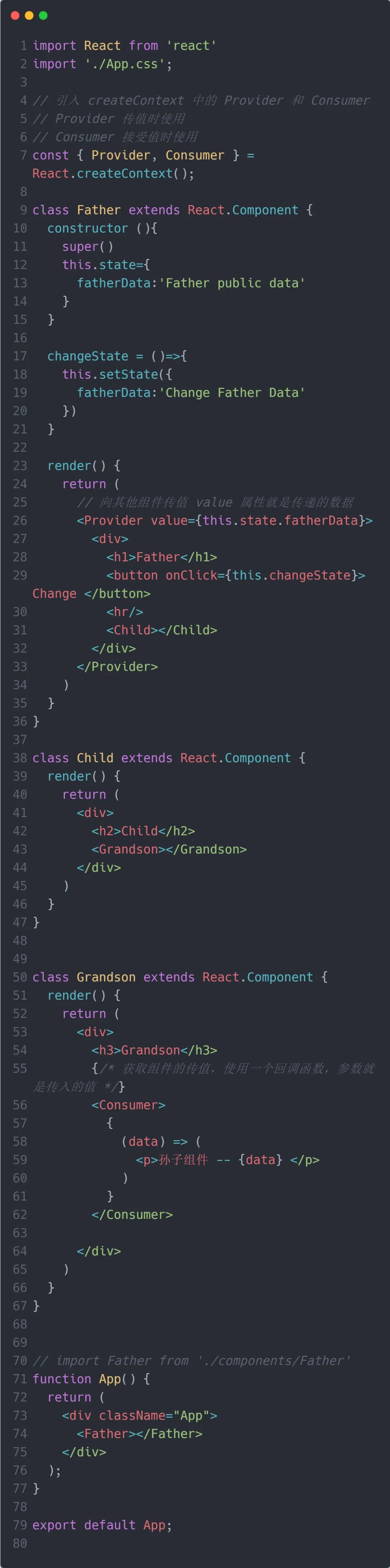
Context API 确实从一定程度上解决了 Props 存在的问题,但当某个组件的业务逻辑非常复杂时,代码必然越写越多,使用 Context API 进行数据流管理的问题就会出现。其实,通过上面的代码我们也能观察出问题的所在,Context API 并没有将数据层和展示层分开,在组件内部的 UI 代码中去控制数据流,没办法抽离。最终,整个组件会显得臃肿不堪,业务逻辑统统堆在一块,难以维护,数据流也会变得非常混乱,难以管理。
而当数据流混乱时,我们的一个执行动作可能会触发一系列的 setState。因此,如何能够让整个数据流变得可“监控”,甚至可以更细致地去控制每一步数据或状态的变更,就显得尤为重要。我们希望数据流的管理,是真正脱离 React 组件概念的,从 UI 层完全抽离出来,只负责管理数据,让 React 只专注于 View 层的绘制。那么,就需要我们梳理清楚专业级的数据流管理框架。上篇内容也提到过,社区有非常多的优秀方案。
Redux 设计原理
Flux
2014 的 Facebook F8 大会上提出了一个观点,MVC 更适用于小型应用。但在面向大型前端项目时,MVC 会使项目足够复杂,即每当添加新的功能,系统复杂度就会疯狂增长。如下图所示,Model 与 View 的关联是错综复杂的,很难理解和调试,尤其是 Model 与 View 之间还存在双向数据流动。
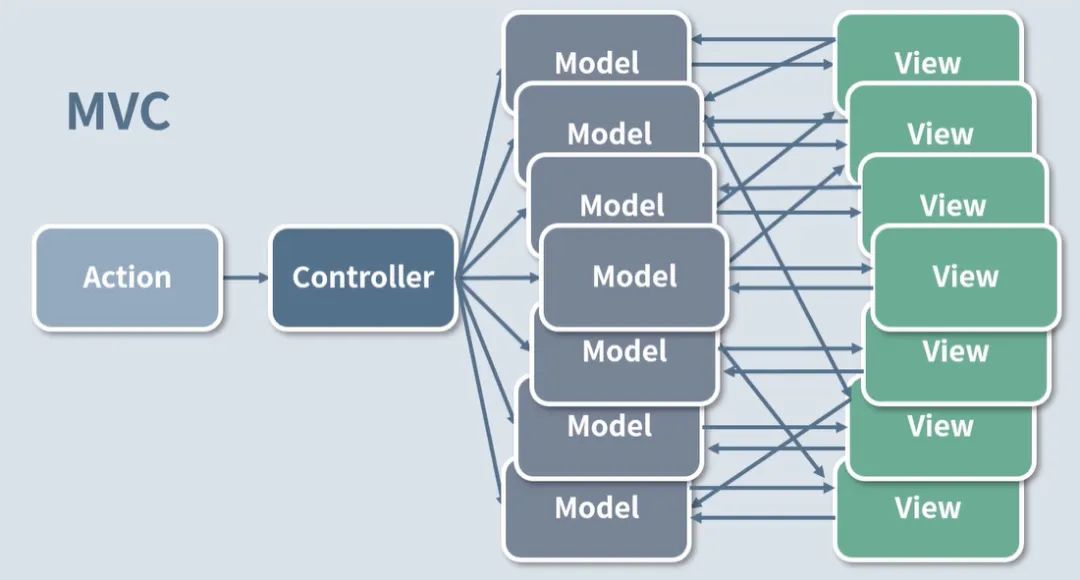
所以他们提出了一种基于单向数据流的架构。这个结构思想,对于数据流管理来说可谓是开天劈地的存在, 如下图所示:

我先解释下上图中涉及的概念。
View(视图层):用户界面。该用户界面可以是以任何形式实现出来的,React 组件是一种形式,Vue、Angular 也完全 OK。Flux 架构与 React 之间并不存在耦合关系。
Action(动作):也可以理解为视图层发出的“消息”,它会触发应用状态的改变。
Dispatcher(派发器):它负责对 action 进行分发。
Store(数据层):它是存储应用状态的“仓库”,此外还会定义修改状态的逻辑。store 的变化最终会映射到 view 层上去。
一个典型的 Flux 工作流是这样的:用户与 View 之间产生交互,通过 View 发起一个 Action。Dispatcher 会把这个 Action 派发给 Store,通知 Store 进行相应的状态更新。Store 状态更新完成后,会进一步通知 View 去更新界面。
Flux 最重要的不是 Flux 本身,而是 Flux 的设计理念和方案思路。这是一个横空出世的全新品种,带着全新的思想架构,来到现代化前端开发的世界。但是,从应用场景来看,Flux 目前除了在 Facebook 内部大规模应用以外,业界很少使用。因为具体的应用代码实现起来还是要相对复杂一些的,所以,Flux 最重要的不是 Flux 本身,在 Flux 基础上演变而来的 Redux 才是现在的明星款式。它继承了所有 Flux 的设计思路和优秀理念,而又减低了具体编码的难度(其实依然比较复杂,但相对 Flux 要简单很多 ) 。
Redux
官方手册介绍 Redux:Redux 是 JavaScript 状态容器,提供可预测化的状态管理。
Redux 是为 JavaScript 应用而生的,也就是说它不是 React 的专利,React 可以用,Vue 可以用,原生 JavaScript 也可以用。
Redux 是一个状态容器,这里我举个例子来解释下什么是状态容器。就像办公室里的饮水机,所有员工不分高低贵贱,有人口渴就去接水就行了。饮水机就对应 Redux 管理着数据(水),有人(组件)需要就可以去取。也就是说数据(水)与组件(员工)是相互独立的,使用 Redux 管理数据,Store 就是独立于组件维护的数据,这使得数据管理与组件之间相互独立,解决了组件与组件之间传递数据困难的问题。
在 React 中使用 Redux ,需要先进行安装:
npm install redux react-reduxRedux 主要由三部分组成:store、reducer 和 action。我们先来看看它们各自代表什么:
store:就好比饮水机里的“水”,它是一个单一的数据源,而且是只读的。
action:人如其名,是 “动作” 的意思,它是对变化的描述。
reducer:是一个函数,它负责对变化进行分发和处理, 最终将新的数据返回给 store。
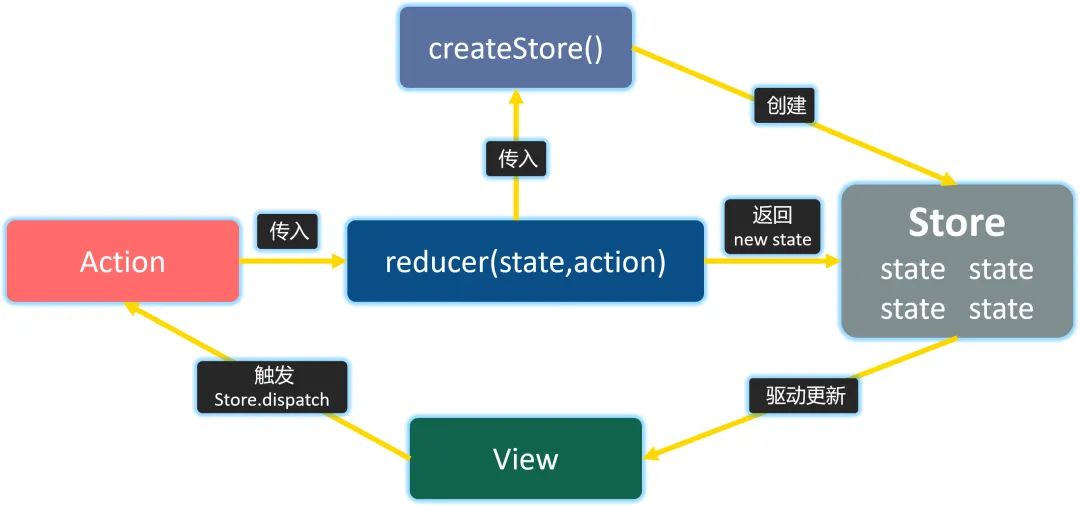
store、action 和 reducer 三者紧密配合,形成了 Redux 闭环的工作流:

在 Redux 的整个工作过程中,数据流是严格单向的。这句话非常重要,一定要牢记。
对于一个 React 应用来说,视图(View)层面的所有数据(state)都来自 store。如果你想对数据进行修改,只有一种途径:派发 action,action 会被 reducer 读取,进而根据 action 内容的不同对数据进行修改、生成新的 state(状态),这个新的 state 会更新到 store 对象里,进而驱动视图层面做出对应的改变。
对于组件来说,任何组件都可以通过约定的方式从 store 读取到全局的状态,任何组件也都可以通过合理地派发 action 来修改全局的状态。Redux 通过提供一个统一的状态容器,使得数据能够自由而有序地在任意组件之间穿梭,这就是 Redux 实现组件间通信的思路。
从编码的角度理解 Redux 工作流
到这里,你已经了解了 Redux 的设计思想和要素关系。接下来我们将站在编码的角度,继续探讨 Redux 的工作流,将上文中所提及的各个要素和流程具象化。
1. 使用 createStore 来完成 store 对象的创建。

createStore 方法是一切的开始,它接收三个入参:reducer、初始状态内容、指定中间件。一般来说,只有 reducer 是你不得不传的。下面我们就看看 reducer 的编码形态是什么样的。
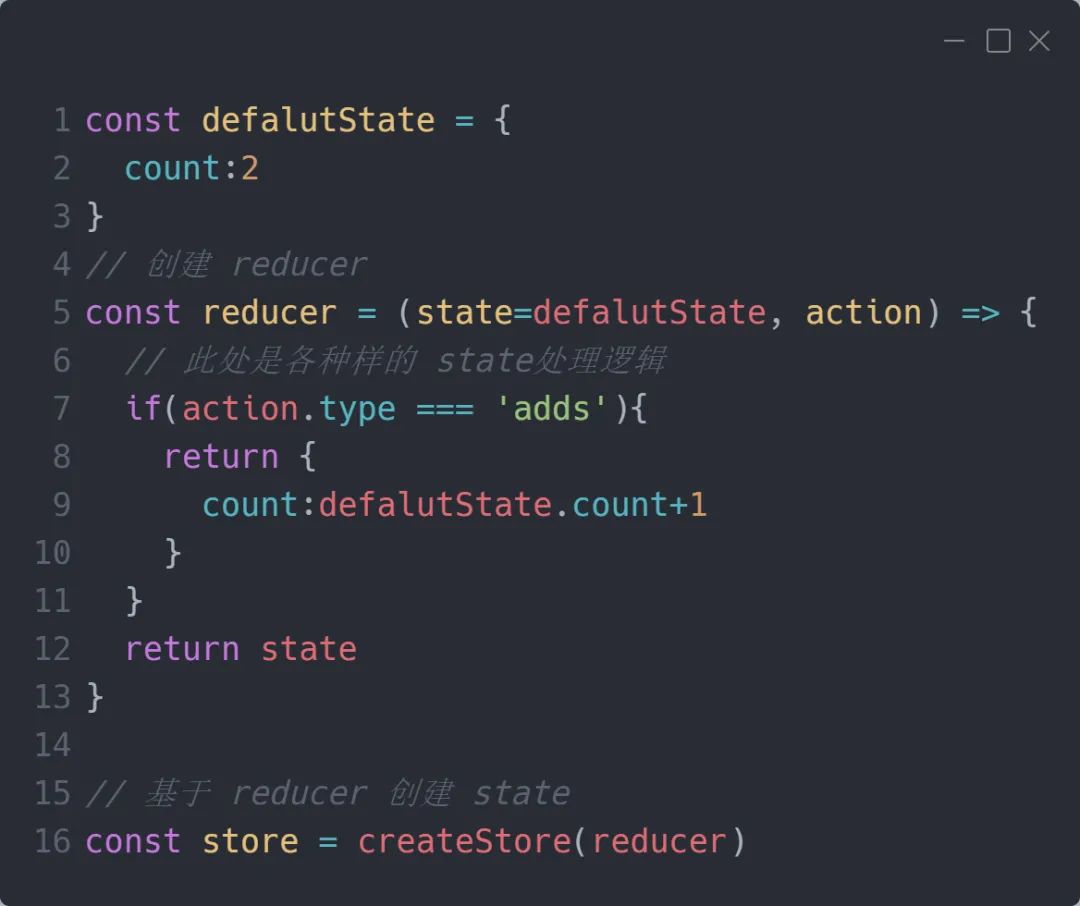
2. reducer 的作用是将新的 state 返回给 store。
一个 reducer 一定是一个纯函数,它可以有各种各样的内在逻辑,但它最终一定要返回一个 state,当我们基于某个 reducer 去创建 store 的时候,其实就是给这个 store 指定了一套更新规则:
3. 靠 dispatch,派发 action,通知 reducer “让改变发生”
要想让 state 发生改变,就必须用正确的 action 来驱动这个改变。action 对象中允许传入的属性有多个,但只有 type 是必传的。type 是 action 的唯一标识,reducer 正是通过不同的 type 来识别出需要更新的不同的 state,由此才能够实现精准的 “定向更新”。
action 本身只是一个对象,要想让 reducer 感知到 action,还需要 “派发 action” 这个动作,这个动作是由 store.dispatch 完成。

完整的代码结构如下:
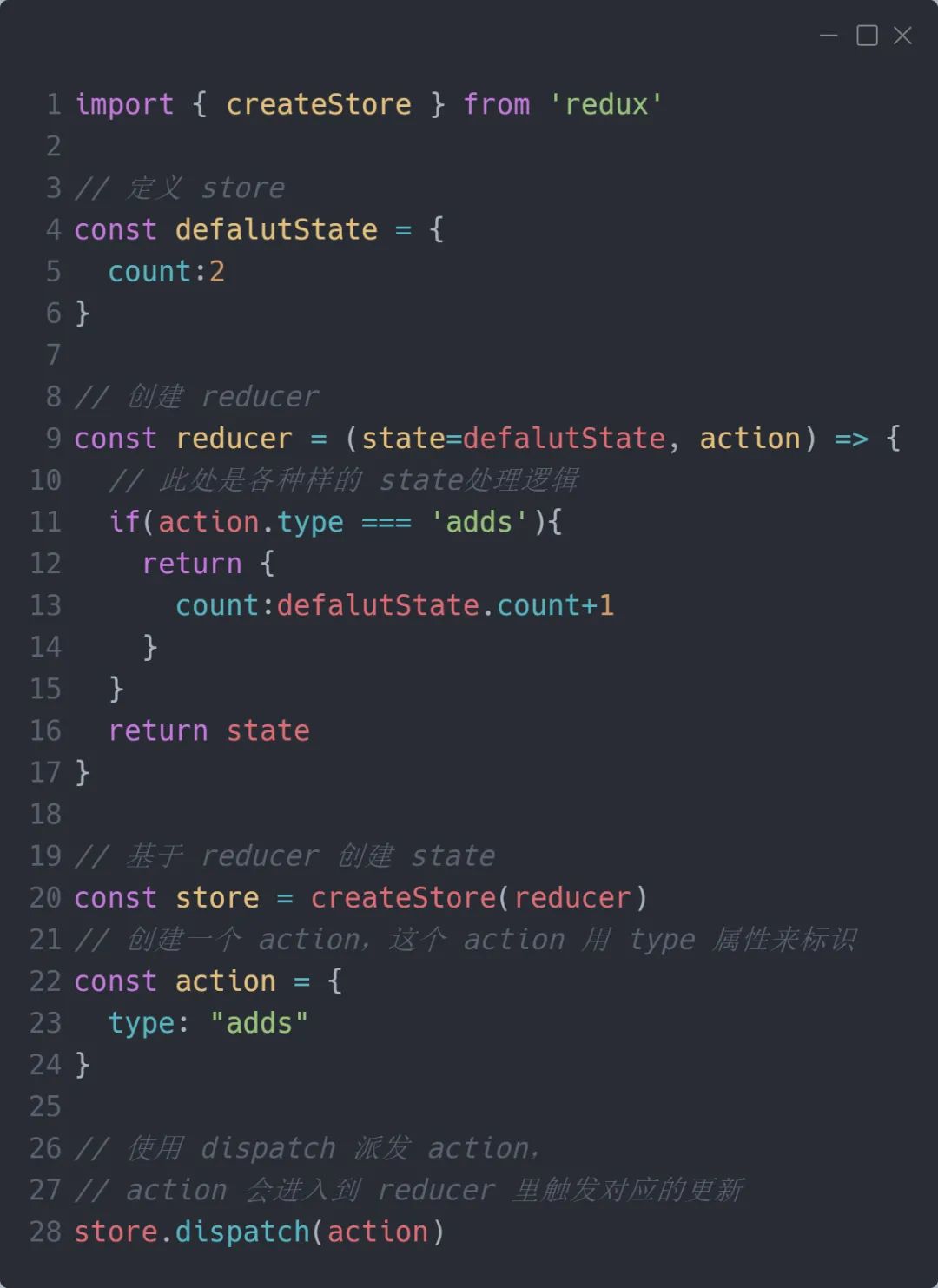
我们根据上面的代码,再来看看整个的工作流:
下面是一个数字加减的小案例:
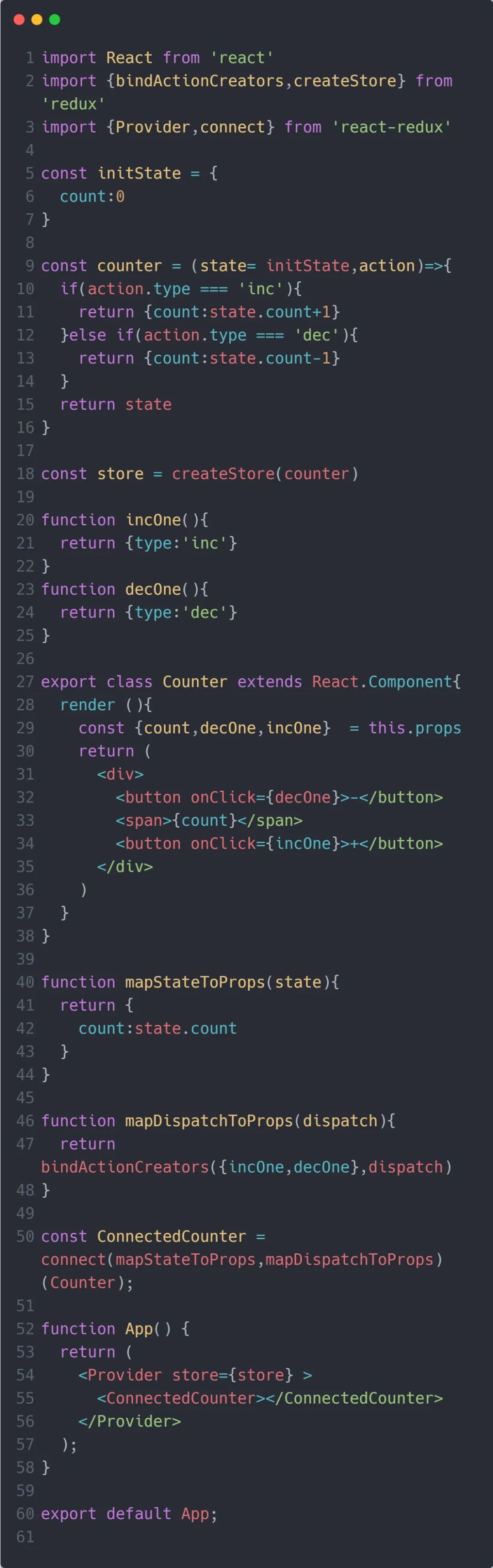
不知道你看完这个小案例有什么感受?我知道你可能感到了极其反感的繁琐代码,就像老奶奶的裹脚布,又臭又长。很多人在用了一段时间的 Redux 之后,最大的感想就是,Redux 要写大量的模板代码,很麻烦,还不如只用React 来管理。其实仔细想想会发现,看上去是 Redux 来帮助 React 管理状态,但实际情况是我们将 React 的部分状态移交至 Redux 那里,区别就在于谁主动谁被动的问题。
注意:Redux 实际就是提供一套工具,React 照着说明书来操作就行了。
所以这注定了想要使用 Redux ,就必须按照它的规矩来做,除非你不愿意接受这种模式。这种模式有利有弊,好处就是在一个大型的多人团队中,这种开发模式反而容易形成一种规约,让整个状态流程变得清晰。弊端则是对于快速迭代的小规模团队,这种繁重的代码模板无疑是一种不小的负担。
接下来,我们对 Redux 来做一个整体的分析。
Redux 的优点
1)状态持久化:globalstore 可以保证组件就算销毁了也依然保留之前状态。
2)状态可回溯:每个 action 都会被序列化,Reducer 不会修改原有状态,总是返回新状态,方便做状态回溯。
3)Functional Programming:使用纯函数,输出完全依赖输入,没有任何副作用。
4)中间件:针对异步数据流,提供了类 express 中间件的模式,社区也出现了一大批优秀的第三方插件,能够更精细地控制数据的流动,对复杂的业务场景起到了缓冲的作用。
Redux 的缺点
1)繁重的代码模板:修改一个state可能要动四五个文件,可谓牵一发而动全身。
2)store 里状态残留:多组件共用 store 里某个状态时要注意初始化清空问题。
3)无脑的发布订阅:每次 dispatch 一个 action 都会遍历所有的 reducer,重新计算 connect,这无疑是一种损耗;
4)交互频繁时会有卡顿:如果 store 较大时,且频繁地修改 store,会明显看到页面卡顿。
5)不支持 Typescript。
Redux 与 MobX 的对比
我们先来介绍一下 MobX 。这里以 Mobx 5 版本为例,实际上它是利用了 ES6 的 proxy 来追踪属性(旧版本是用 Object.defineProperty 来实现的)通过隐式订阅,自动追踪被监听的对象变化,进行数据的更新。

Redux 是把要做的事情都交给了用户,来保证自己的纯净,那么 MobX 就是把最简易的操作给了用户,其它的交给 MobX 内部去实现。用户不必关心这个过程,当然,基本理念依然是 Model 和 View 完全分离。我们完全可以将业务逻辑写在 action 里,用户只需要操作 Observabledata 就行了。
限于篇幅,具体代码的实现,这里就不展开了。Observerview 会自动做出响应,这就是 MobX 主打的响应式设计,但是编程风格依然是传统的面向对象的 OO 范式。熟悉Vue 的朋友一定对这种响应式设计不陌生,Vue 就是利用了数据劫持来实现双向绑定,其实 React + Mobx 就是一个复杂点的 Vue,Vue3 版本的一个重大改变也是将代理交给了 proxy。
刚刚 MobX 的优势说得比较多了,这里再简单地做个总结:
1)代码量少。
2)基于数据劫持来实现精准定位(真正意义上的局部更新)。
3)多 store 抽离业务逻辑(Model View 分离)。
4)响应式性能良好(频繁的交互依然可以胜任)。
5)完全可以替代 React 自身的状态管理。
6)支持 Typescript。
其实现在主流的数据流管理分为两大派:一类是以 Redux 为首的函数式库,还有一类就是以 MobX 为首的响应式库了。
文章所涉及到的代码均已开源,欢迎访问交流:https://gitee.com/xilinglaoshi1/react-redux
推荐阅读:
点个“在看”和“赞”吧,
毕竟我是要成为前端网红的人。