
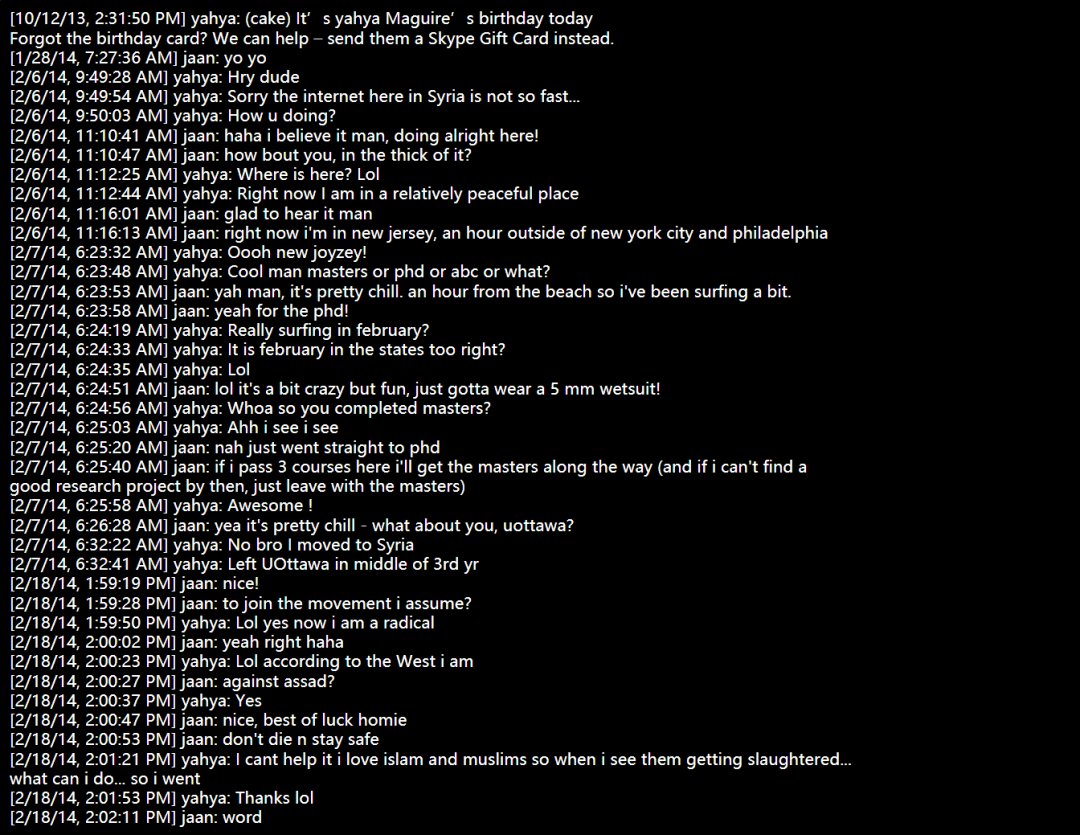
我的朋友受到社交媒体的算法推荐“蛊惑”,加入了激进组织

在社交媒体中使用机器学习的风险
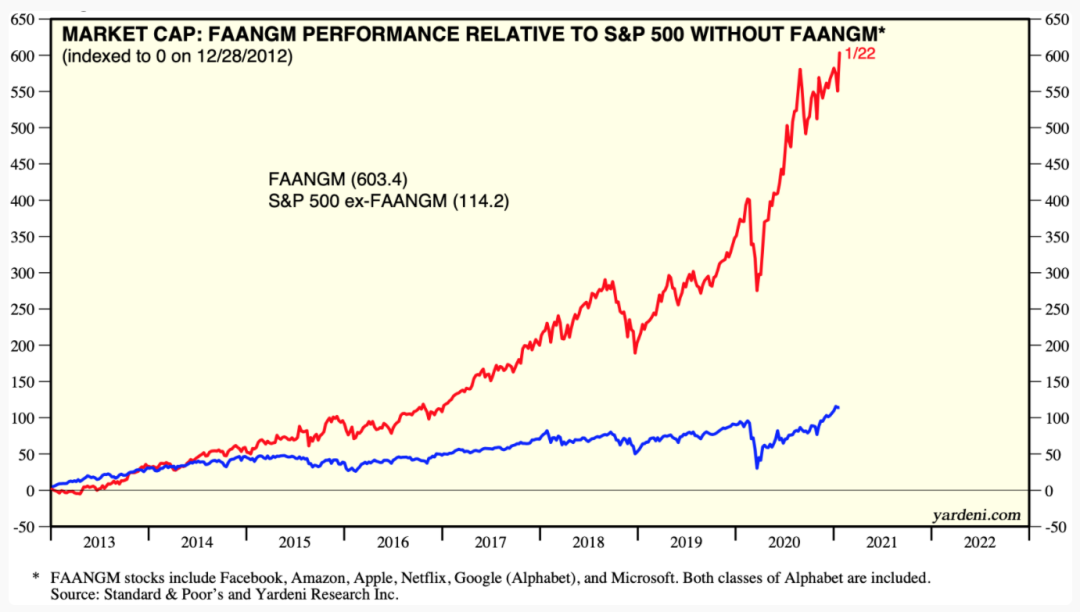
如何减轻机器学习的社会风险
个人应该怎么做

https://www.reddit.com/r/MachineLearning/comments/l8n1ic/discussion_how_much_responsibility_do_people_who/
https://jaan.io/my-friend-radicalized-this-made-me-rethink-how-i-build-AI/
评论