
一文讲透Elasticsearch倒排索引与分词
点击上方“JavaEdge”,关注公众号

1 倒排索引

1.1 书的目录和索引

正排索引即目录页,根据页码去找内容
倒排索引即索引页,根据关键词去找对应页码
1.2 搜索引擎
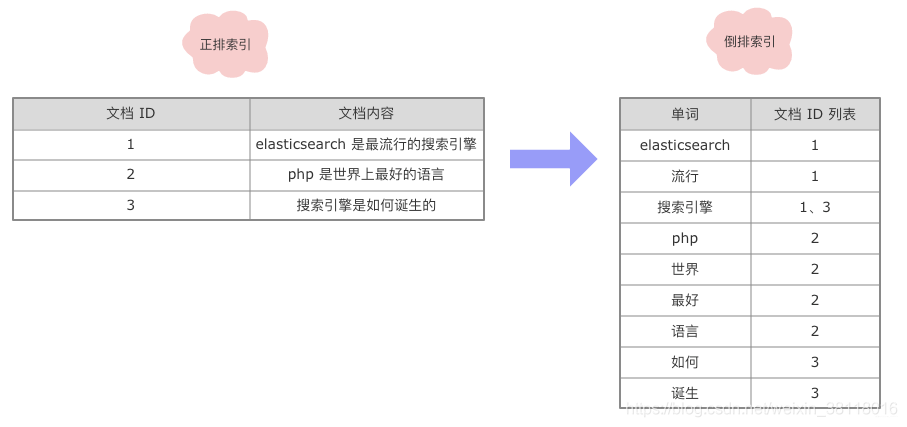
正排索引
文档Id =》文档内容、单词的关联关系倒排索引
单词 =》 文档Id的关联关系左:正排索引 =》 右:倒排索引
倒排索引查询流程
查询包含"搜索引擎”的文档
通过倒排索引获得"搜索引擎”对应的文档Id有1和3
通过正排索引查询1和3的完整内容
返回最终结果
1.3 倒排索引的组成

1.3.1 单词词典( Term Dictionary )

倒排索引的重要组成
记录所有文档的单词 ,一般都比较大
记录单词到倒排列表的关联信息
单词字典的实现一般是用B+ Tree ,示例如下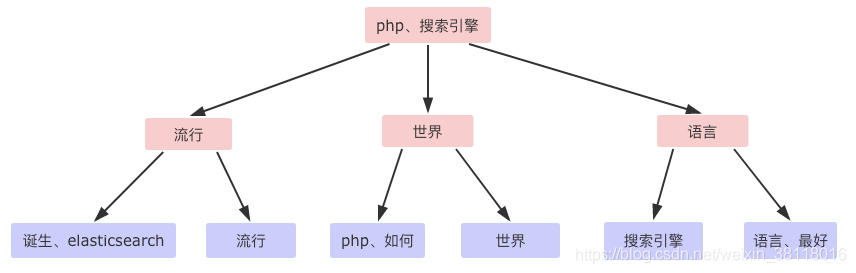
1.3.2 倒排列表( Posting List )
记录了单词对应的文档集合,由倒排索引项( Posting )组成。
倒排索引项( Posting )主要包含如下信息:
文档Id ,用于获取原始信息
单词频率( TF, Term Frequency ),记录该单词在该文档中的出现次数,用于后续相关性算分
位置( Position)
记录单词在文档中的分词位置(多个) , 用于做词语搜索( Phrase Query )
偏移( Offset )
记录单词在文档的开始和结束位置,用于做高亮显示
案例
以搜索引擎为例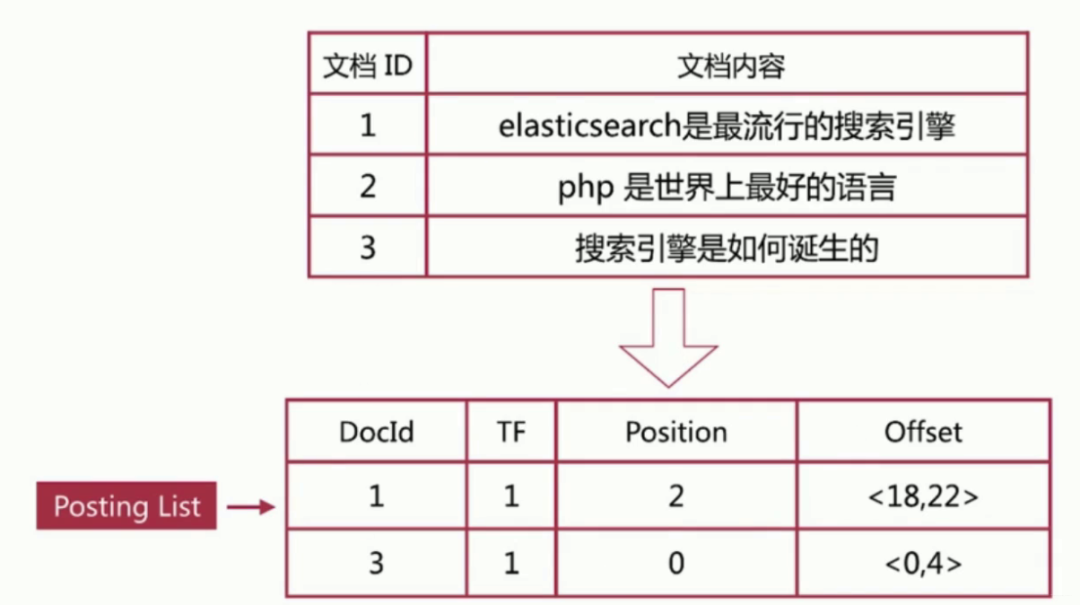
单词字典与倒排列表整合在一起的结构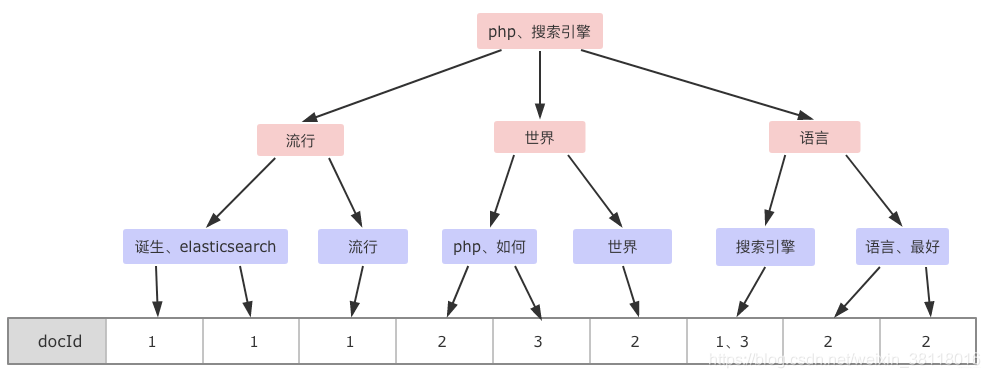
ES存储的是JSON格式文档,其中包含多个字段,每个字段都有自己的倒排索引。
2 分词
将文本转换成一系列单词的过程,也称文本分析,在 ES 里称为 Analysis。
比如文本【JavaEdge 是最硬核的公众号】,分词结果是【JavaEdge、硬核、公众号】
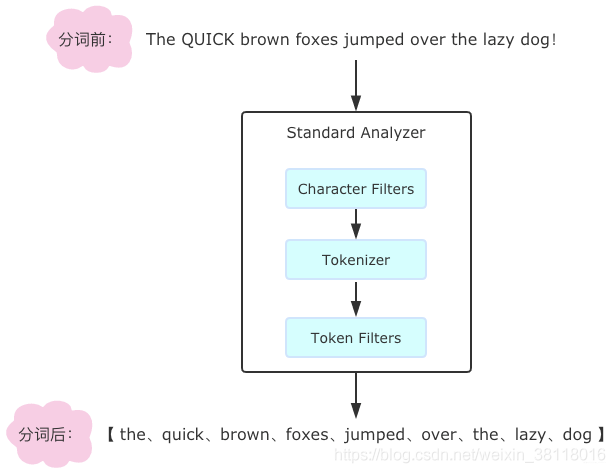
2.1 Analyzer-分词器
分词器是 ES 专门处理分词的组件,组成如下:
2.1.1 Character Filters
在Tokenizer之前对原始文本进行处理,比如增加、删除或替换字符等。
针对原始文本进行处理,比如去除 html 特殊标记符,自带的如下:
HTML Strip 去除 html 标签和转换 html 实体
Mapping 进行字符替换操作
Pattern Replace 进行正则匹配替换
会影响后续tokenizer解析的postion和offset信息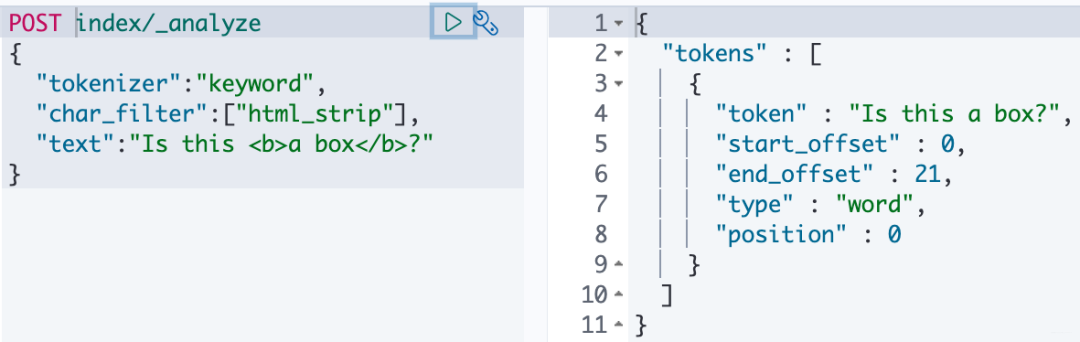
2.1.2 Tokenizer
将原始文本按照一定规则切分为单词,内置:
standard 按单词进行分割
letter 按非字符类进行分割
whitespace 按空格进行分割
UAX URL Email 按 standard 分割,但不会分割邮箱和 url
NGram 和 Edge NGram 连词分割
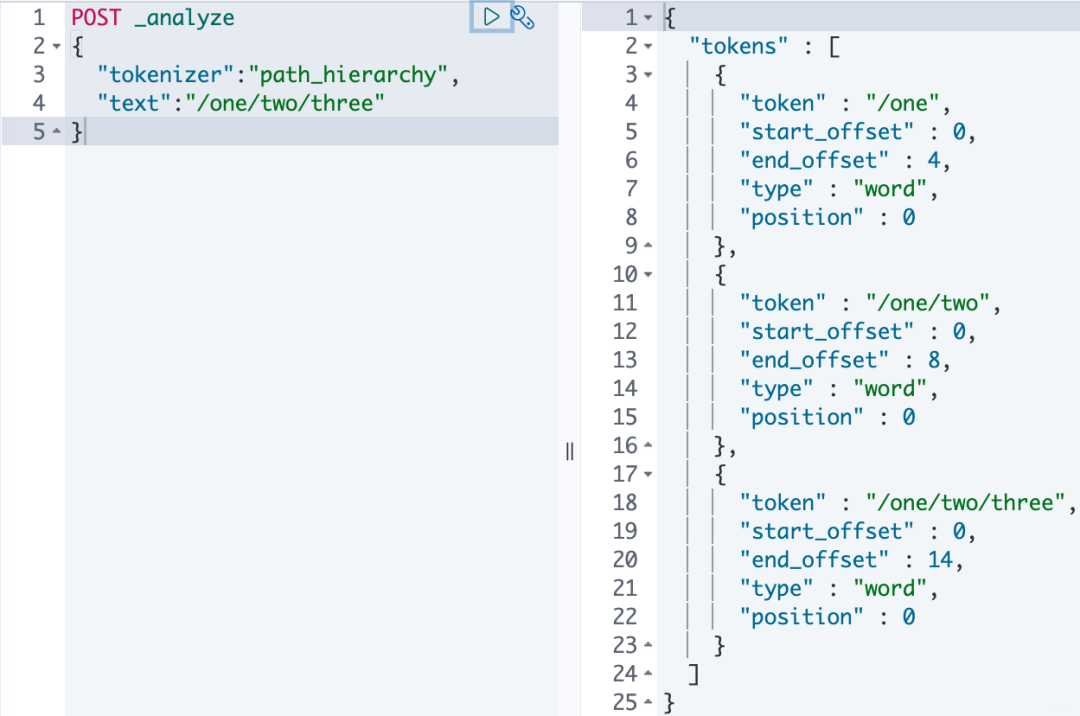
Path Hierachy 按文件路径进行分割
示例:
POST _analyze
{
"tokenizer":"path_hierarchy",
"text":"/one/two/three"
}
2.1.3 Token Filters
针对 tokenizer 处理的单词进行再加工,比如转小写、删除或新增等处理,内置:
lowercase 将所有 term 转换为小写
stop 删除 stop words
NGram 和 Edge NGram 连词分割
Synonym 添加近义词的 term
示例
// filter 可以有多个
POST _analyze
{
"text":"a Hello world!",
"tokenizer":"standard",
"filter":[
"stop", // 把 a 去掉了
"lowercase",// 小写
{
"type":"ngram",
"min_gram":"4",
"max_gram":"4"
}
]
}
// 得到 hell、ello、worl、orld

分词器的调用顺序
3 Analyze API
ES 提供了一个测试分词的 API 接口,方便验证分词效果,endpoint 是 _analyze:
3.1 指定 analyzer
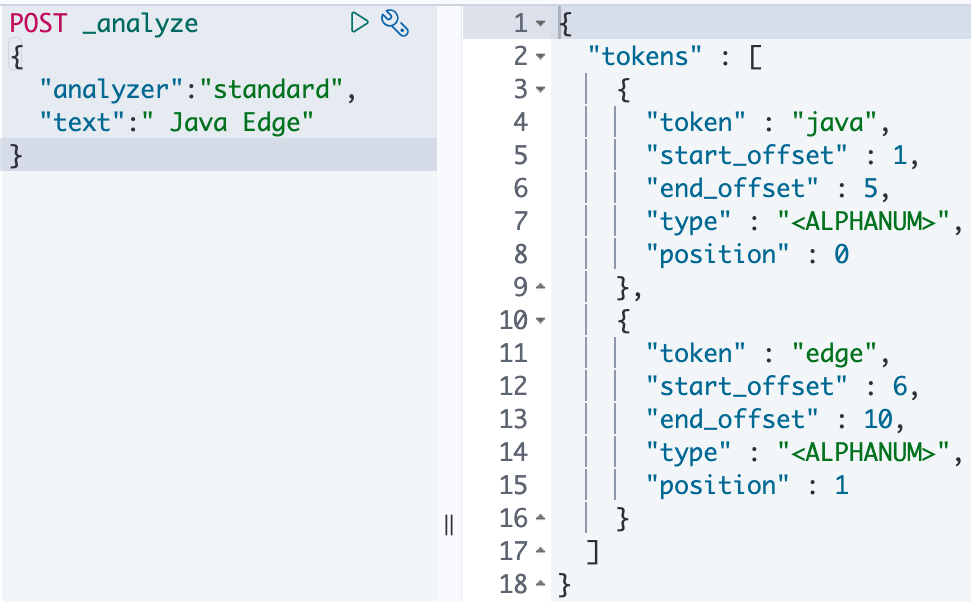
request
POST _analyze
{
"analyzer":"standard", # 分词器
"text":" JavaEdge 公众号" # 测试文本
}
response
{
"tokens" : [
{
"token" : "java", # 分词结果
"start_offset" : 1, # 起始偏移
"end_offset" : 5, # 结束偏移
"type" : "" ,
"position" : 0 # 分词位置
},
{
"token" : "edge",
"start_offset" : 6,
"end_offset" : 10,
"type" : "" ,
"position" : 1
}
]
}
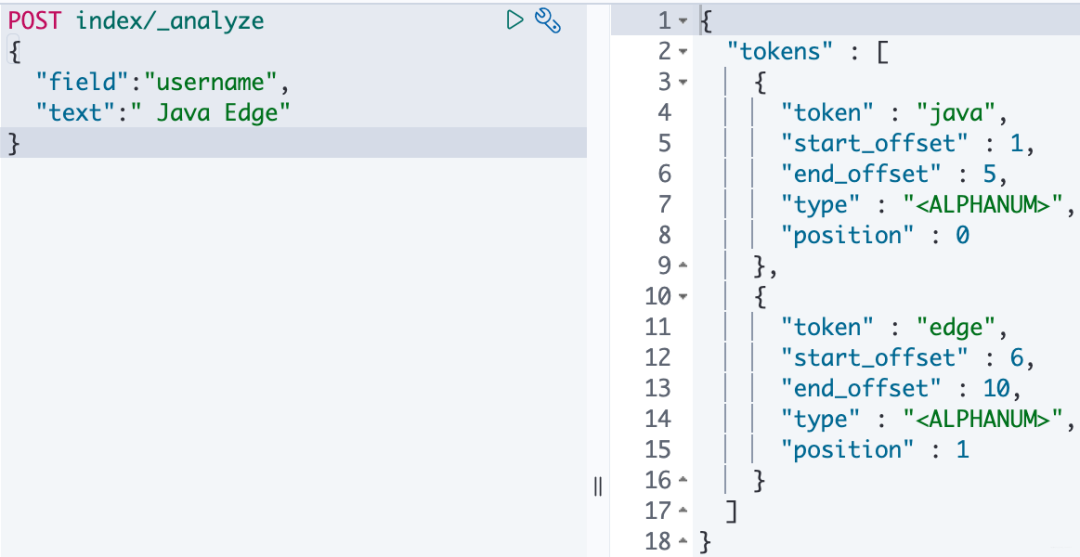
3.2 指定索引中的字段
POST 测试的索引/_analyze
{
"field":"username", # 测试字段
"text":"hello world" # 测试文本
}
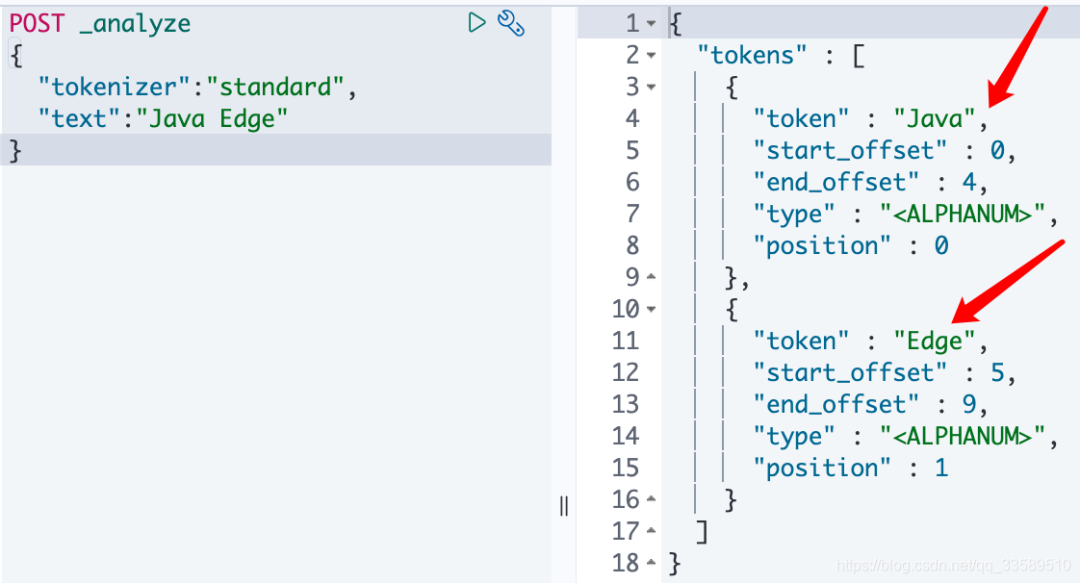
3.3 自定义分词器
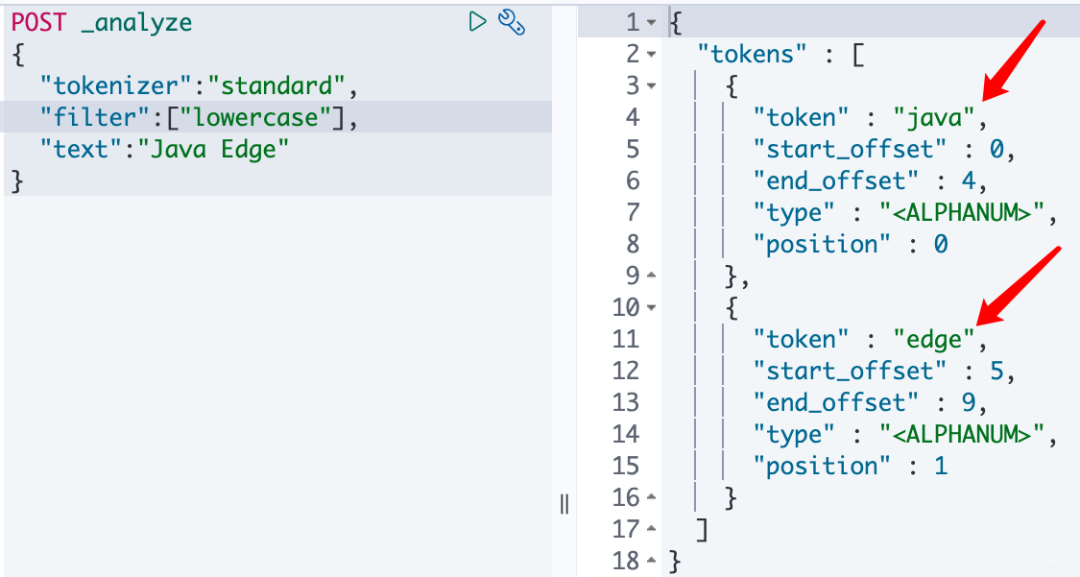
POST _analyze
{
"tokenizer":"standard",
"filter":["lowercase"], # 自定义
"text":"hello world"
}
之前的默认分词器大写
自定义小写分词器
4 内置分词器
Standard Analyzer
默认分词器,按词切分,支持多语言,小写处理
Simple Analyzer
按照非字母切分,小写处理
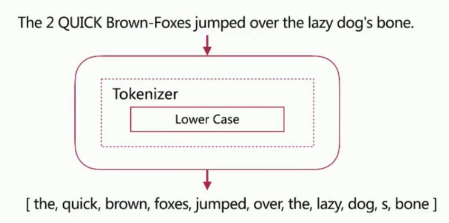
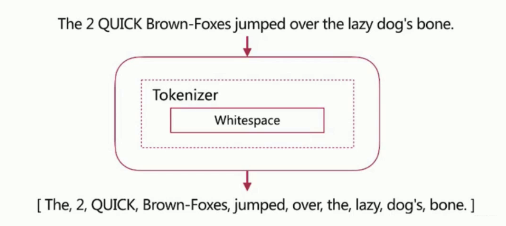
Whitespace Analyzer
按空格切分
Stop Analyzer
Stop Word 指语气助词等修饰性词语,比如 the、an、的、这等等,特性是相比 Simple Analyzer 多 Stop Word 处理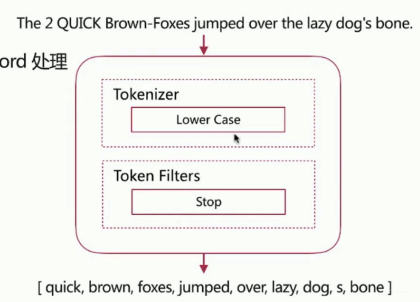
keyword Analyzer
不分词,直接将输入作为一个单词输出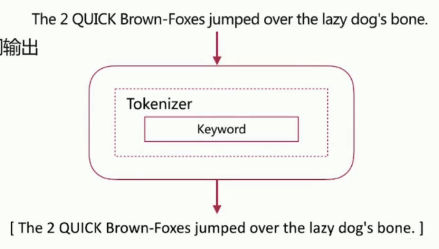
Pattern Analyzer
通过正则表达式自定义分隔符,默认 \W+,即非字词的符号为分隔符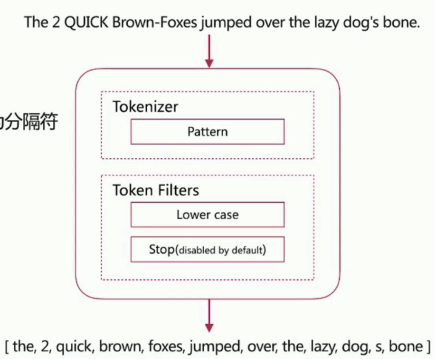
Language Analyzer
提供了 30+ 常见语言的分词器
5 中文分词
将一个汉字序列切分成一个个单独的词。在英文中,单词之间是以空格作为自然分界符,汉语中词没有一个形式上的分界符。而且中文博大精深,上下文不同,分词结果也大不相同。
比如:
乒乓球拍/卖/完了
乒乓球/拍卖/完了
以下是 ES 中常见的分词系统:
IK
实现中英文单词的切分,可自定义词库,支持热更新分词词典
jieba
python 中最流行饿分词系统,支持分词和词性标注,支持繁体分词,自定义词典,并行分词
以下是基于自然语言处理的分词系统:
Hanlp
由一系列模型与算法组成的 java 工具包,支持索引分词、繁体分词、简单匹配分词(极速模式)、基于 CRF 模型的分词、N- 最短路径分词等,实现了不少经典分词方法。目标是普及自然语言处理在生产环境中的应用。
https://github.com/hankcs/HanLP
THULAC
THU Lexical Analyzer for Chinese ,由清华大学自然语言处理与社会人文计算
实验室研制推出的一套中文词法分析工具包,具有中文分词和词性标注功能
https://github.com/microbun/elasticsearch-thulac-plugin
6 自定义分词器
当自带的分词无法满足需求时,可以自定义分词器,通过定义 Character Filters、Tokenizer、Token Filter 实现。自定义的分词需要在索引的配置中设定,示例如下所示:
自定义如下分词器
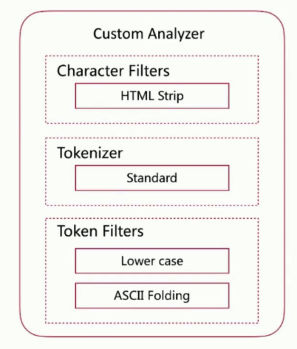
// 自定义分词器PUT test_index_name{"settings":{"analysis":{"analyzer":{"my_customer_analyzer":{"type":"custome","tokenizer":"standard","char_filter":["html_strip"],"filter":["lowercase", "asciifolding"]}}}}}// 测试自定义分词器效果:POST test_index/_analyze{"tokenizer":"keyword","char_filter":["html_strip"],"text":"Is this a box?"}// 得到 is、this、a、box
7 分词使用说明
分词会在如下两个时机使用:
创建或者更新文档时(Index Time)
会对相应的文档进行分词处理
索引时分词是通过配置Index Mapping中每个字段的analyzer属性实现的。不指定分词时,使用默认standard。
查询时(Search Time)
会对查询语句进行分词。查询时分词的指定方式:
查询的时候通过analyzer指定分词器
通过index mapping设置
search_analyzer实现
分词的最佳实践
明确字段是否需要分词,不需要分词的字段就将 type 设置为 keyword,可以节省空间和提高写性能。
善用 _analyze API,查看文档的具体分词结果
多动手测试
参考
https://blog.csdn.net/weixin_38118016/article/details/90416391
https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247486148&idx=1&sn=817027a204650763c1bea3e837d695ea&source=41#wechat_redirect
往期推荐

目前交流群已有 800+人,旨在促进技术交流,可关注公众号添加笔者微信邀请进群
喜欢文章,点个“在看、点赞、分享”素质三连支持一下~