
机器学习的心腹大患:数据泄漏

应用于整个数据集的简单的数据准备方法会导致数据泄漏,从而导致对模型性能的错误估计。
为了避免数据泄漏,数据准备应该只在训练集中进行。
如何在Python中用训练测试集划分和k折交叉验证实现数据准备而又不造成数据泄漏。
用原始数据准备方法进行训练-测试评估
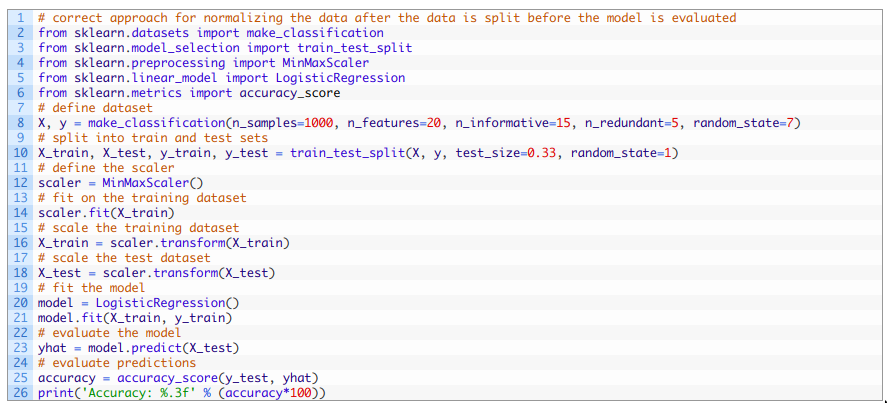
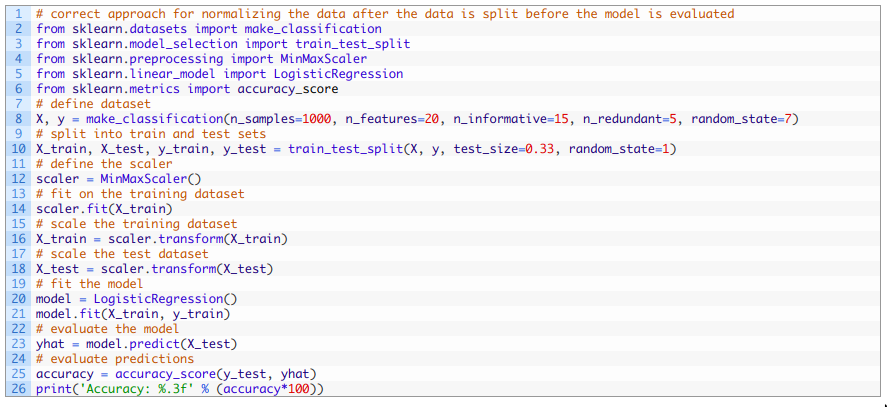
用正确的数据准备方法进行训练-测试评估
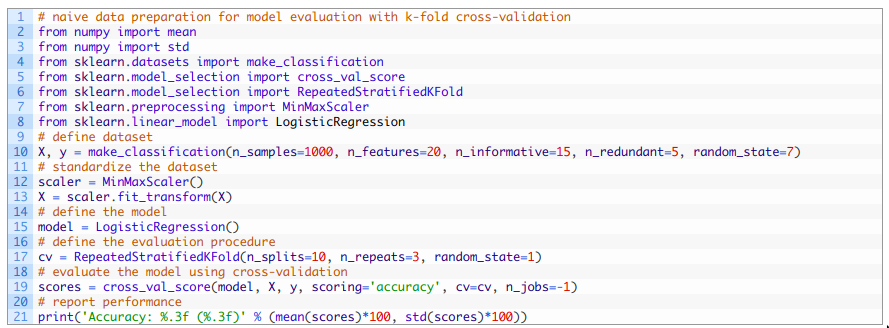
用原始数据准备方法进行交叉验证评估
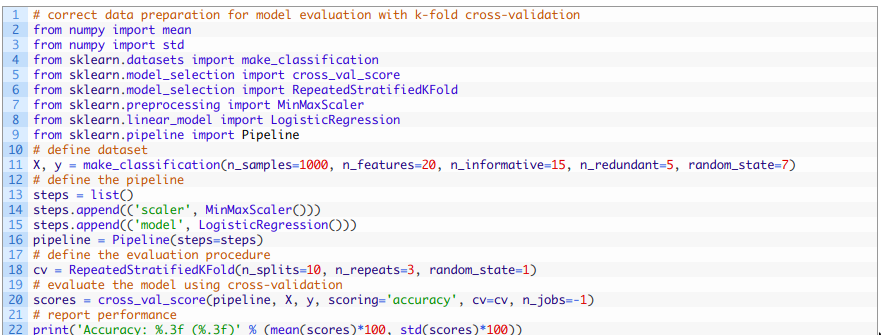
用正确的数据准备方法进行交叉验证评估
—第54-55页,特征工程与选择,2019年。”













—第55页,特征工程与选择,2019年。”



直接将数据准备方法应用于整个数据集会导致数据泄漏,从而导致对模型性能的错误估计。
为了避免数据泄漏,必须仅在训练集中进行数据准备。
如何在Python中为训练集-测试集分割和k折交叉验证实现数据准备而又不会造成数据泄漏。
原文链接:
https://machinelearningmastery.com/data-preparation-without-data-leakage/
推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓
评论