
终于懂了:协程思想的起源与发展
前言
大家好,我的朋友们!
大白干了6年多后端,写过C/C++、Python、Go,每次说到协程的时候,脑海里就只能浮现一些关键字yeild、async、go等等。
但是对于协程这个知识点,我理解的一直比较模糊,于是决定搞清楚。
全文阅读预计耗时10分钟,少刷几个小视频的时间,多学点知识,想想就很划算噻!
协程概念的诞生
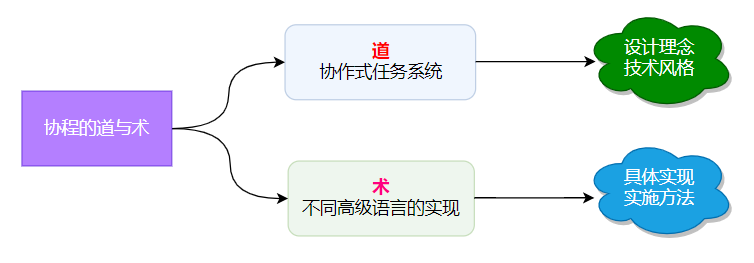
先抛一个粗浅的结论:协程从广义来说是一种设计理念,我们常说的只是具体的实现。
理解好思想,技术点就很简单了,关于协程道与术的区别:
上古神器COBOL
协程概念的出现比线程更早,甚至可以追溯到20世纪50年代,提协程就必须要说到一门生命力极强的最早的高级编程语言COBOL。
最开始我以为COBOL这门语言早就消失在历史长河中,但是我错了。
COBOL语言,是一种面向过程的高级程序设计语言,主要用于数据处理,是国际上应用最广泛的一种高级语言。COBOL是英文Common Business-Oriented Language的缩写,原意是面向商业的通用语言。
截止到今年在全球范围内大约有1w台大型机中有3.8w+遗留系统中约2000亿行代码是由COBOL写的,占比高达65%,同时在美国很多政府和企业机构都是基于COBOL打造的,影响力巨大。
时间拉回1958年,美国计算机科学家梅尔文·康威(Melvin Conway)就开始钻研基于磁带存储的COBOL的编译器优化问题,这在当时是个非常热门的话题,不少青年才俊都扑进去了,包括图灵奖得主唐纳德·尔文·克努斯教授(Donald Ervin Knuth)也写了一个优化后的编译器。
看看这两位的简介,我沉默了:
梅尔文·康威(Melvin Conway)也是一位超级大佬,著名的康威定律提出者。

唐纳德·尔文·克努斯是算法和程序设计技术的先驱者,1974年的图灵奖得主,计算机排版系统TeX和字型设计系统METAFONT的发明者,他因这些成就和大量创造性的影响深远的著作而誉满全球,《计算机程序设计的艺术》被《美国科学家》杂志列为20世纪最重要的12本物理科学类专著之一。
 那究竟是什么问题让这群天才们投入这么大的精力呢?快来看看!
那究竟是什么问题让这群天才们投入这么大的精力呢?快来看看!
COBOL编译器的技术难题
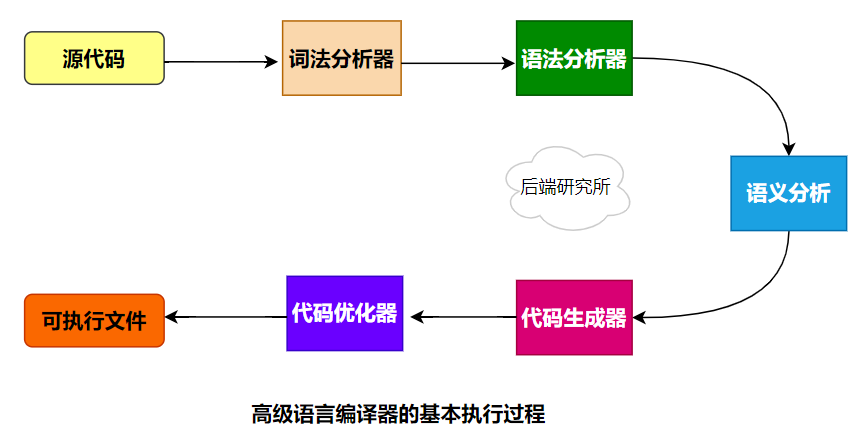
我们都是知道高级编程语言需要借助编译器来生成二进制可执行文件,编译器的基本步骤包括:读取字符流、词法分析、语法分析、语义分析、代码生成器、代码优化器等。
这种管道式的流程,上一步的输出作为下一步的输入,将中间结果存储在内存即可,这在现代计算机上毫无压力,但是受限于软硬件水平,在几十年前的COBOL语言却是很难的。
 在1958年的时候,当时的存储还不发达,磁带作为存储器是1951年在计算机中得到应用的,所以那个时代的COBOL很依赖于磁带。
在1958年的时候,当时的存储还不发达,磁带作为存储器是1951年在计算机中得到应用的,所以那个时代的COBOL很依赖于磁带。
 其实,我在网上找了很多资料去看当时的编译器有什么问题,只找到了一条:编译器无法做到读一次磁带就可以完成整个编译过程,也就是所谓的one-pass编译器还没有产生。
其实,我在网上找了很多资料去看当时的编译器有什么问题,只找到了一条:编译器无法做到读一次磁带就可以完成整个编译过程,也就是所谓的one-pass编译器还没有产生。
当时的COBOL程序被写在一个磁带上,而磁带不支持随机读写,只能顺序读,而当时的内存又不可能把整个磁带的内容都装进去,所以一次读取没编译完就要再从头读。
于是,我脑补了COBOL编译器和磁带之间可能的两种multi-pass形式的交互情况:
可能情况一
对于COBOL的编译器来说,要完成词法分析、语法分析就要从磁带上读取程序的源代码,在之前的编译器中词法分析和语法分析是相互独立的,这就意味着:词法分析时需要将磁带从头到尾过一遍 语法分析时需要将磁带从头到尾过一遍 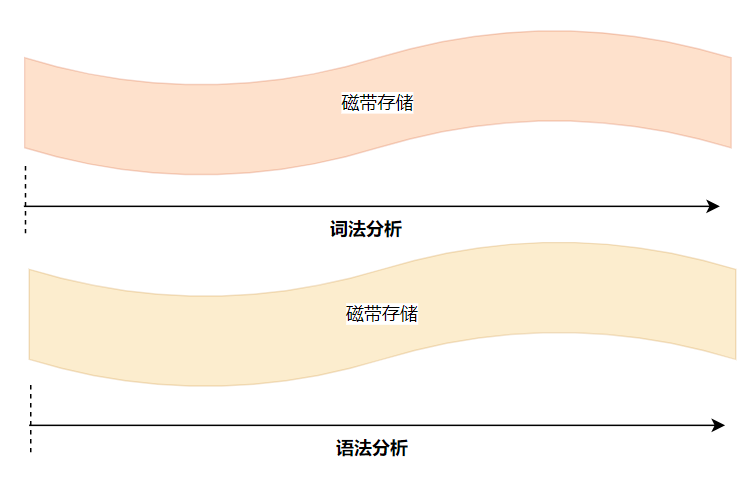
可能情况二
听过磁带的朋友们一定知道磁带的两个基本操作:倒带和快进。
在完成编译器的词法分析和语法分析两件事情时,需要磁带反复的倒带和快进去寻找两类分析所需的部分,类似于磁盘的寻道,磁头需要反复移动横跳,并且当时的磁带不一定支持随机读写。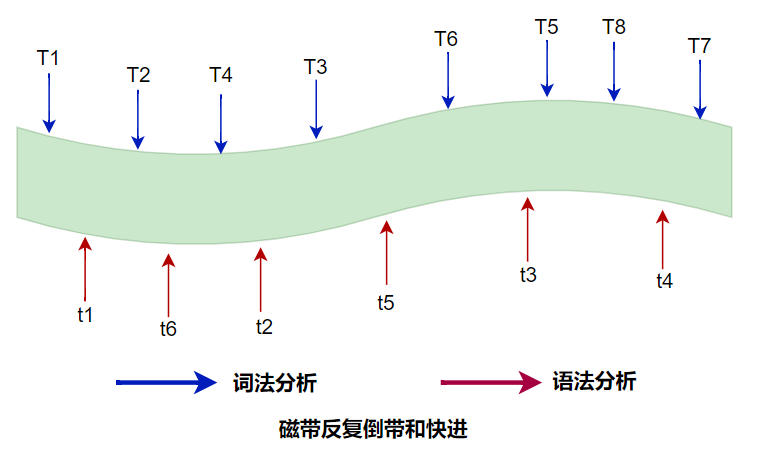
从一些资料可以看到,COBOL当时编译器各个环节相互独立的,这种软硬件的综合限制导致无法实现one-pass编译。
协同式解决方案
在梅尔文·康威的编译器设计中将词法分析和语法分析合作运行,而不再像其他编译器那样相互独立,两个模块交织运行,编译器的控制流在词法分析和语法分析之间来回切换:
当词法分析模块基于词素产生足够多的词法单元Token时就控制流转给语法分析 当语法分析模块处理完所有的词法单元Token时将控制流转给词法分析模块 词法分析和语法分析各自维护自身的运行状态,并且具备主动让出和恢复的能力
可以看到这个方案的核心思想在于:
梅尔文·康威构建的这种协同工作机制,需要参与者让出(yield)控制流时,记住自身状态,以便在控制流返回时能从上次让出的位置恢复(resume)执行。简言之,
协程的全部精神就在于控制流的主动让出和恢复。
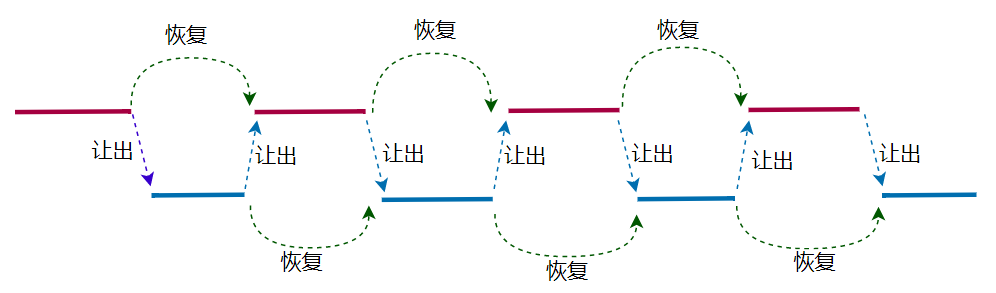 这种协作式的任务流和计算机中断非常像,在当时条件的限制下,由梅尔文·康威提出的这种让出/恢复模式的协作程序被认为是最早的协程概念,并且基于这种思想可以打造新的COBOL编译器。
这种协作式的任务流和计算机中断非常像,在当时条件的限制下,由梅尔文·康威提出的这种让出/恢复模式的协作程序被认为是最早的协程概念,并且基于这种思想可以打造新的COBOL编译器。
在1963年,梅尔文·康威也发表了一篇论文来说明自己的这种思想,虽然半个多世纪过去了,有幸我还是找到了这篇论文:
https://melconway.com/Home/pdf/compiler.pdf
 说实话这paper真是有点难,时间过于久远,很难有共鸣,最后我放弃了,要不然我或许能搞明白之前编译器的具体问题了。
说实话这paper真是有点难,时间过于久远,很难有共鸣,最后我放弃了,要不然我或许能搞明白之前编译器的具体问题了。
怀才不遇的协程
虽然协程概念出现的时间比线程还要早,但是协程一直都没有正是登上舞台,真是有点怀才不遇的赶脚。
我们上学的时候,老师就讲过一些软件设计思想,其中主流语言崇尚自顶向下top-down的编程思想:
对要完成的任务进行分解,先对最高层次中的问题进行定义、设计、编程和测试,而将其中未解决的问题作为一个子任务放到下一层次中去解决。
这样逐层、逐个地进行定义、设计、编程和测试,直到所有层次上的问题均由实用程序来解决,就能设计出具有层次结构的程序。
C语言就是典型的top-down思想的代表,在main函数作为入口,各个模块依次形成层次化的调用关系,同时各个模块还有下级的子模块,同样有层次调用关系。
但是协程这种相互协作调度的思想和top-down是不合的,在协程中各个模块之间存在很大的耦合关系,并不符合高内聚低耦合的编程思想,相比之下top-down使程序结构清晰、层次调度明确,代码可读性和维护性都很不错。
与线程相比,协作式任务系统让调用者自己来决定什么时候让出,比操作系统的抢占式调度所需要的时间代价要小很多,后者为了能恢复现场会在切换线程时保存相当多的状态,并且会非常频繁地进行切换,资源消耗更大。
综合来说,协程完全是用户态的行为,由程序员自己决定什么时候让出控制权,保存现场和切换恢复使用的资源也非常少,同时对提高处理器效率来说也是完全符合的。
那么不禁要问:协程看着不错,为啥没成为主流呢?
协程的思想和当时的主流不符合 抢占式的线程可以解决大部分的问题,让使用者感受的痛点不足
换句话说:协程能干的线程干得也不错,线程干的不好的地方,使用者暂时也不太需要,所以协程就这样怀才不遇了。
其实,协程虽然在x86架构上没有折腾出大风浪,由于抢占式任务系统依赖于CPU硬件的支持,对硬件要求比较高,对于一些嵌入式设备来说,协同调度再合适不过了,所以协程在另外一个领域也施展了拳脚。
协程的雄起
我们对于CPU的压榨从未停止。
对于CPU来说,任务分为两大类:计算密集型和IO密集型。
计算密集型已经可以最大程度发挥CPU的作用,但是IO密集型一直是提高CPU利用率的难点。
IO密集型任务之痛
对于IO密集型任务,在抢占式调度中也有对应的解决方案:异步+回调。
也就是遇到IO阻塞,比如下载图片时会立即返回,等待下载完成将结果进行回调处理,交付给发起者。
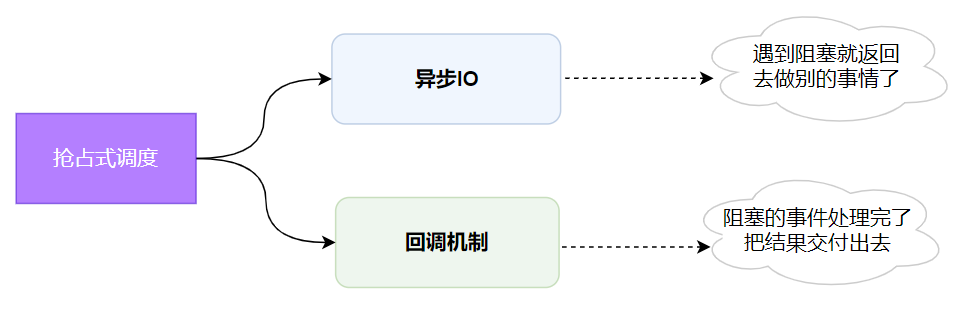
就像你常去早餐店,油条还没好,你和老板很熟悉就先交了钱去座位玩手机了,等你的油条好了,服务员就端过去了,这就是典型的异步+回调。
虽然异步+回调在现实生活中看着也很简单,但是在程序设计上却很让人头痛,在某些场景下会让整个程序的可读性非常差,而且也不好写,相反同步IO虽然效率低,但是很好写,
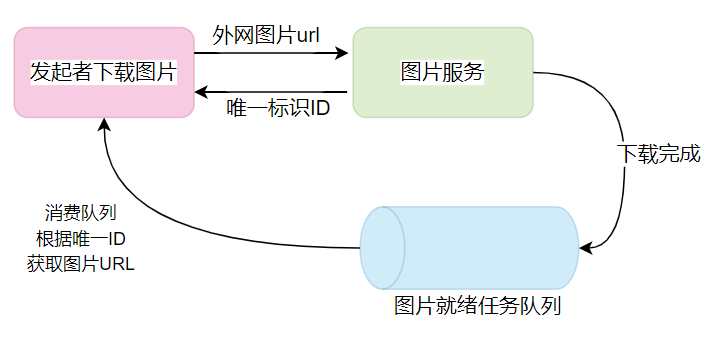
还是以为异步图片下载为例,图片服务中台提供了异步接口,发起者请求之后立即返回,图片服务此时给了发起者一个唯一标识ID,等图片服务完成下载后把结果放到一个消息队列,此时需要发起者不断消费这个MQ才能拿到下载结果。
整个过程相比同步IO来说,原来整体的逻辑被拆分为好几个部分,各个子部分有状态的迁移,对大部分程序员来说维护状态简直就是噩梦,日后必然是bug的高发地。
用户态协同调度
随着网络技术的发展和高并发要求,对于抢占式调度对IO型任务处理的低效逐渐受到重视,终于协程的机会来了。
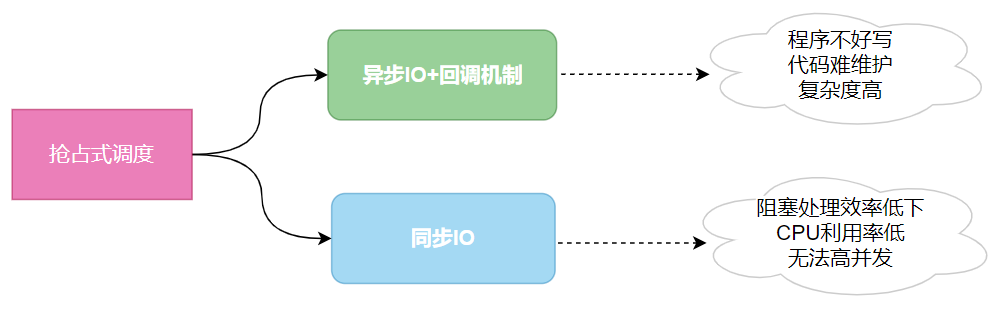
协程将IO的处理权交给了程序员,遇到IO被阻塞时就交出控制权给其他协程,等其他协程处理完再把控制权交回来。
通过yield方式转移执行权的多个协程之间并非调用者和被调用者的关系,而是彼此平等、对称、合作的关系。
协程一直没有占上风的原因,除了设计思想的矛盾,还有一些其他原因,毕竟协程也不是银弹,来看看协程有什么问题:
协程无法利用多核,需要配合进程来使用才可以在多CPU上发挥作用 线程的回调机制仍然有巨大生命力,协程无法全部替代 控制权需要转移可能造成某些协程的饥饿,抢占式更加公平 协程的控制权由用户态决定可能转移给某些恶意的代码,抢占式由操作系统来调度更加安全
综上来说,协程和线程并非矛盾,协程的威力在于IO的处理,恰好这部分是线程的软肋,由对立转换为合作才能开辟新局面。
拥抱协程的编程语言
网络操作、文件操作、数据库操作、消息队列操作等重IO操作,是任何高级编程语言无法避开的问题,也是提高程序效率的关键。
像Java、C/C++、Python这些老牌语言也陆续开始借助于第三方包来支持协程,来解决自身语言的不足。
像Golang这种新生选手,在语言层面原生支持了协程,可以说是彻底拥抱协程,这也造就了Go的高并发能力。
我们来分别看看它们是怎么实现协程的,以及实现协程的关键点是什么。
Python
Python对协程的支持也经历了多个版本,从部分支持到完善支持一直在演进:
Python2.x对协程的支持比较有限,生成器yield实现了一部分但不完全 第三方库gevent对协程的实现有比较好,但不是官方的 Python3.4加入了asyncio模块 在Python3.5中又提供了async/await语法层面的支持 Python3.6中asyncio模块更加完善和稳 Python3.7开始async/await成为保留关键字
我们以最新的async/await来说明Python的协程是如何使用的:
import asyncio
from pathlib import Path
import logging
from urllib.request import urlopen, Request
import os
from time import time
import aiohttp
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
CODEFLEX_IMAGES_URLS = ['https://codeflex.co/wp-content/uploads/2021/01/pandas-dataframe-python-1024x512.png',
'https://codeflex.co/wp-content/uploads/2021/02/github-actions-deployment-to-eks-with-kustomize-1024x536.jpg',
'https://codeflex.co/wp-content/uploads/2021/02/boto3-s3-multipart-upload-1024x536.jpg',
'https://codeflex.co/wp-content/uploads/2018/02/kafka-cluster-architecture.jpg',
'https://codeflex.co/wp-content/uploads/2016/09/redis-cluster-topology.png']
async def download_image_async(session, dir, img_url):
download_path = dir / os.path.basename(img_url)
async with session.get(img_url) as response:
with download_path.open('wb') as f:
while True:
chunk = await response.content.read(512)
if not chunk:
break
f.write(chunk)
logger.info('Downloaded: ' + img_url)
async def main():
images_dir = Path("codeflex_images")
Path("codeflex_images").mkdir(parents=False, exist_ok=True)
async with aiohttp.ClientSession() as session:
tasks = [(download_image_async(session, images_dir, img_url)) for img_url in CODEFLEX_IMAGES_URLS]
await asyncio.gather(*tasks, return_exceptions=True)
if __name__ == '__main__':
start = time()
event_loop = asyncio.get_event_loop()
try:
event_loop.run_until_complete(main())
finally:
event_loop.close()
logger.info('Download time: %s seconds', time() - start)
这段代码展示了如何使用async/await来实现图片的并发下载功能。
在普通的函数def前面加async关键字就变成异步/协程函数,调用该函数并不会运行,而是返回一个协程对象,后续在event_loop中执行 await表示等待task执行完成,也就是yeild让出控制权,同时asyncio使用事件循环event_loop来实现整个过程,await需要在async标注的函数中使用 event_loop事件循环充当管理者的角色,将控制权在几个协程函数之间切换
C++
在C++20引入协程框架,但是很不成熟,换句话说是给写协程库的大佬用的最底层的东西,用起来就很复杂门槛比较高。
C++作为高性能服务器开发语言的无冕之王,各大公司也做了很多尝试来使用协程功能,比如boost.coroutine、微信的libco、libgo、云风用C实现的协程库等。
说实话,C++协程相关的东西有点复杂,后面专门写一下,在此不展开了。
Go
go中的协程被称为goroutine,被认为是用户态更轻量级的线程,协程对操作系统而言是透明的,也就是操作系统无法直接调度协程,因此必须有个中间层来接管goroutine。
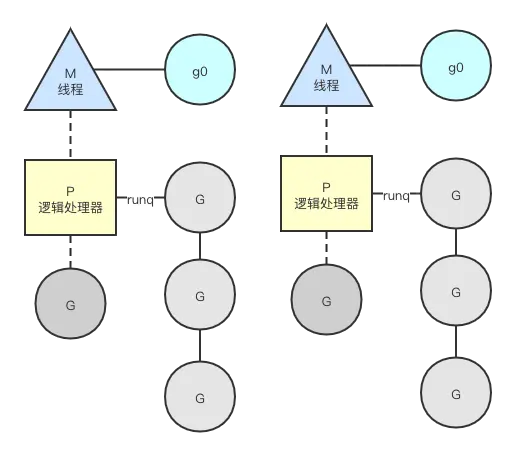
goroutine仍然是基于线程来实现的,因为线程才是CPU调度的基本单位,在go语言内部维护了一组数据结构和N个线程,协程的代码被放进队列中来由线程来实现调度执行,这就是著名的GMP模型。
G:Goroutine
每个Gotoutine对应一个G结构体,G存储Goroutine的运行堆栈,状态,以及任务函数,可重用函数实体G需要保存到P的队列或者全局队列才能被调度执行。
M:machine
M是线程的抽象,代表真正执行计算的资源,在绑定有效的P后,进入调度执行循环,M会从P的本地队列来执行,
P:Processor
P是一个抽象的概念,不是物理上的CPU而是表示逻辑处理器。当一个P有任务,需要创建或者唤醒一个系统线程M去处理它队列中的任务。
P决定同时执行的任务的数量,GOMAXPROCS限制系统线程执行用户层面的任务的数量。
对M来说,P提供了相关的执行环境,入内存分配状态,任务队列等。
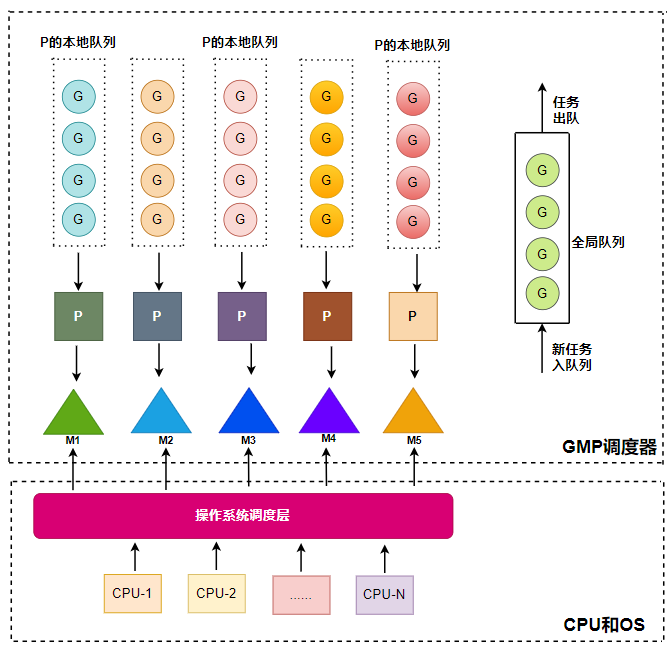
GMP模型运行的基本过程:
首先创建一个G对象,然后G被保存在P的本地队列或者全局队列 这时P会唤醒一个M,M寻找一个空闲的P将G移动到它自己,然后M执行一个调度循环:调用G对象->执行->清理线程->继续寻找Goroutine。 在M的执行过程中,上下文切换随时发生。当切换发生,任务的执行现场需要被保护,这样在下一次调度执行可以进行现场恢复。 M的栈保存在G对象,只有现场恢复需要的寄存器(SP,PC等),需要被保存到G对象。
总结
本文通过1960年对COBOL语言编译器的one-pass问题的介绍,让大家看到了协同式程序的最早背景以及主动让出/恢复的重要理念。
紧接着介绍了主流的自顶向下的软件设计思想和协程思想的矛盾所在,并且抢占式程序调度的蓬勃发展,以及存在的问题。
继续介绍了关于IO密集型任务对于提升CPU效率的阻碍,抢占式调度对于IO密集型问题的异步+回调的解决方案,以及协程的处理,展示了协程在IO密集型任务上处理的重大优势。
最后说明了当前抢占式调度+协程IO密集型处理的方案,包括Python、C++和go的语言层面对于协程的支持和实现。
本文特别具体的内容并不多,旨在介绍协程思想及其优势所在,对于各个语言的协程实现细节并未展开。
最后依然是感谢大家的耐心阅读,我们下期见!

还不过瘾?试试它们