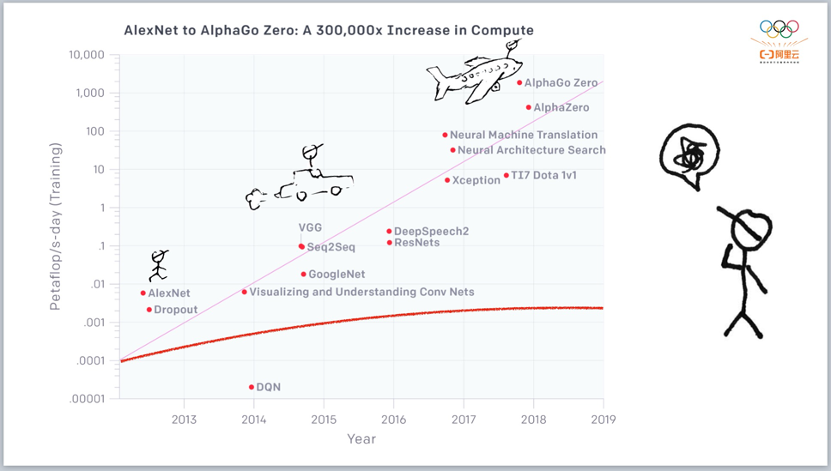
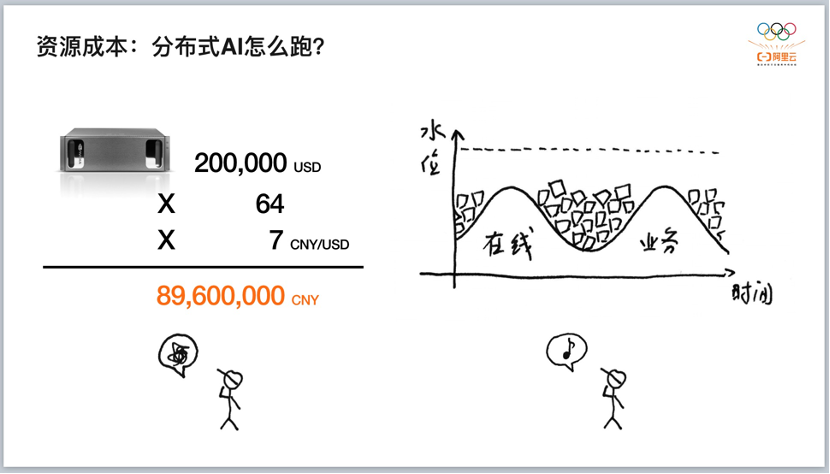
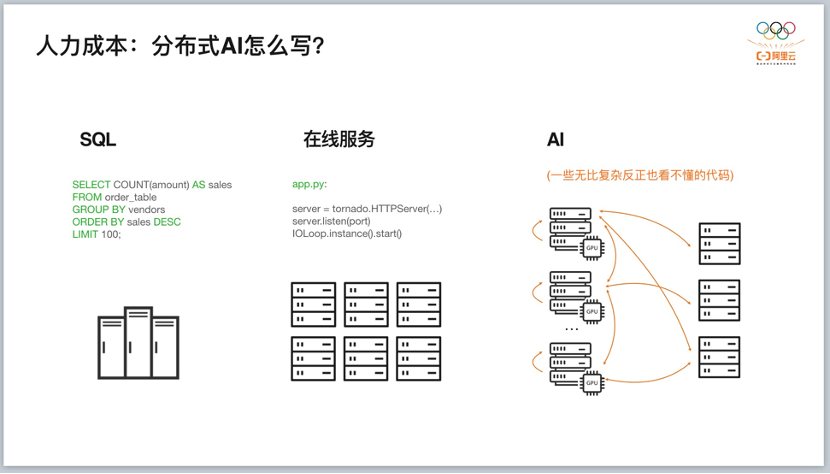
管理大规模的集群和大规模的系统,需要用到非常典型的「削峰填谷」方法,考验我们是否能够把 AI 计算任务掰开、揉碎,变成一小块一小块的任务,部署在资源空闲的机器上。这背后是一个巨大的训练任务,AI 工程师需要做非常多的工作。我们在训练 M6 模型的时候没有买新的机器,就是在现有的生产集群上面,利用「潮汐效应」,把计算量提出来,用来训练模型。 另一个是人的成本。AI 没有 SQL 那么清晰干净的、以目标导向的框架,比如,写一句 SQL,就能驱动 MaxCompute 等计算引擎拉一堆机器来做运算;AI 也不像在线服务一样,可以实现非常简单的、一台机器和几台机器的简单复制,机器间不需要交互,操作简单。 AI 程序要在各种各样的机器、资源之间(GPU 与 GPU 间,或 GPU 与 CPU 间)捣腾数据,要把一个算法(一个数学公式)放到参数服务器上,告诉机器 A 何时与机器 B 说话,机器 B 何时与机器 C 说话,并且最好是快一点。于是,AI 工程师就得写一堆无比复杂、很多人看不懂的代码。
AI 工程师都听说过数据并行、模型并行等概念,这些概念下需要有一个相对简单的软件编程范式,让我们更加容易把集群以及计算的需求切片,把 Computer 跟 Communication 比较好地分配。但是编程范式今天还没有达到一个让彼此都很好理解的程度。因此,人力成本非常高。 也就是说,在大量的数据和算力基础上,一个非常明显的需求是如何更好地做到资源调度和资源调配,以及如何让工程师更容易撰写分布式编程范式,特别是如何来规模化,这是 AI 工程化的第二个体现。 我们设计了一个相对简单、干净的编程框架 Whale,让开发者能够更容易地从单机的编程范式跳到分布式的编程范式。比如,只需告诉 Whale,将模型分为 4 个 stage,Whale 就会自动把这些 stage 放到不同的机器上去做运算。
第三,从需求或者出口的角度看,AI 工程化是开发和服务的标准化、普惠化。 AI 做了非常多有意思的模型,为了使这些模型能够更加紧密地应用在实际场景中,还需要很多工作。但并不是每个人都有时间来学习 AI 如何建模,如何训练和部署等。 所以,我们一直在思考,如何让大家更容易上手这些高大上的 AI 技术。
阿里云机器学习平台 PAI 团队,基于阿里云 IaaS 产品,在云上构建了一个完整的 AI 开发全生命周期的管理体系,从最开始写模型,到训练模型,到部署模型。其中,Studio 平台提供可视化建模,DLC 平台(Deep Learning Container)提供云原生一站式的深度学习训练,DSW 平台(Data Science Workshop)提供交互式建模, EAS 平台(Elastic Algorithm Service )提供更简易、省心的模型推理服务。我们的目标是,希望 AI 工程师能在几分钟之内就开始写第一行 AI 代码。
迄今为止,阿里云通过大数据、AI 平台已经服务了各行各业的客户,宝钢、三一集团、四川农信、太平洋保险、小红书、VIPKID、斗鱼、亲宝宝等。我们希望通过我们的大数据和 AI 能力,给企业提供升级的动力。 来源 | 机器之心 版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。







 下载APP
下载APP