
一键实现图像、视频卡通化,GAN又进化了
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者 | Xinrui Wang, Jinze Yu
译者 | 刘畅
出品 | AI科技大本营(ID:rgzani100)
卡通爱好者的福利来了。
现在,通过在Cartoonize这个应用上一键上传你拍摄的图像或视频,就可以在很短时间内将它卡通化。其核心技术来自CVPR 2020的投稿论文,作者的背景是字节跳动和东京大学,他们提出了用白盒卡通表征实现图像卡通化。
目前,这项工作已在GitHub获得1400个Stars。作者称,他们还计划很快将开源所有代码。下一步,他们的目标是通过将模型移植到tensorflow.js来适应实时视频推理。
GitHub链接:
https://github.com/SystemErrorWang/White-box-Cartoonization
来看看这项工作的卡通化效果。

很有卡通化的味道吧?

视频卡通化的效果也可以。


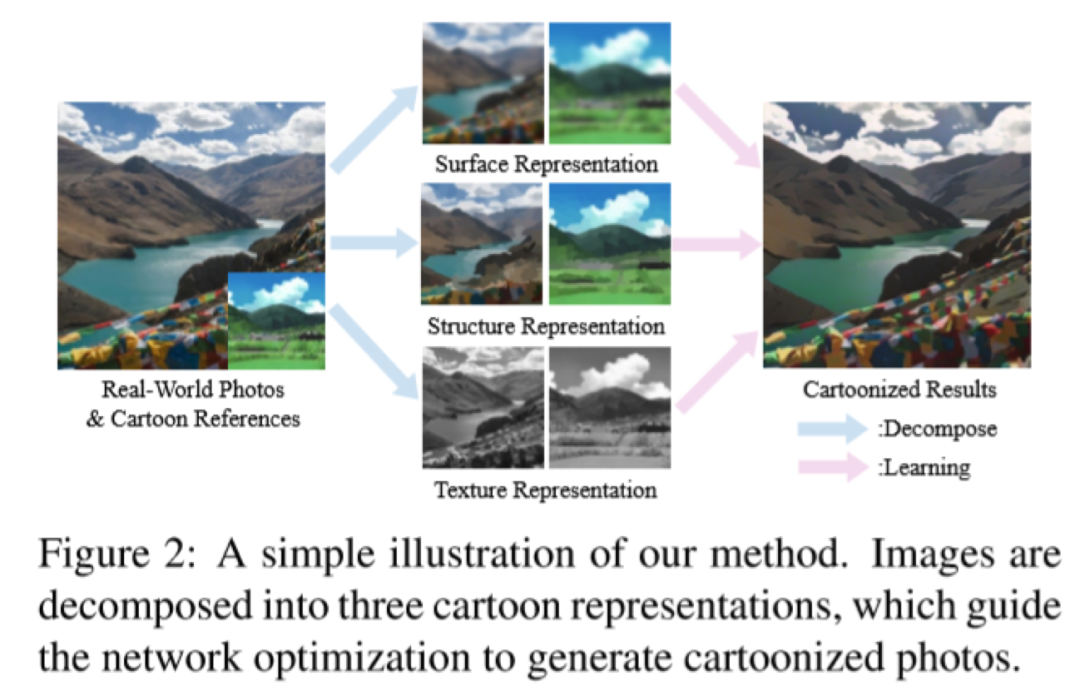
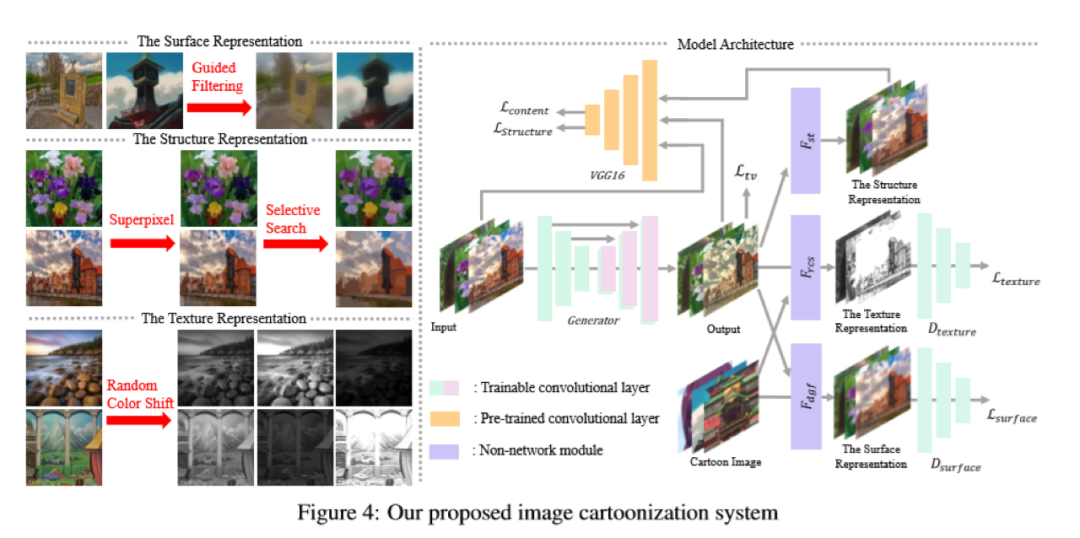
根据对卡通绘画行为的观察,本文提出了三种卡通表示:轮廓表示,结构表示和纹理表示。然后引入图像处理模块以提取每个表示。
在提取表示的指导下优化了基于GAN的图像卡通化框架。用户可以通过平衡每个表示的权重来调整模型输出的样式。
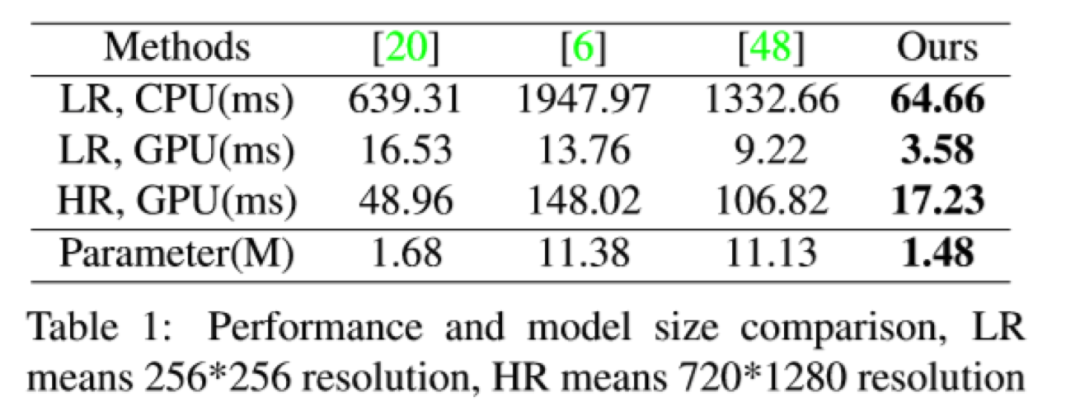
已经进行了广泛的实验,表明我们的方法可以生成高质量的卡通图像。我们的方法在定性比较,定量比较和用户偏爱方面均优于现有方法。

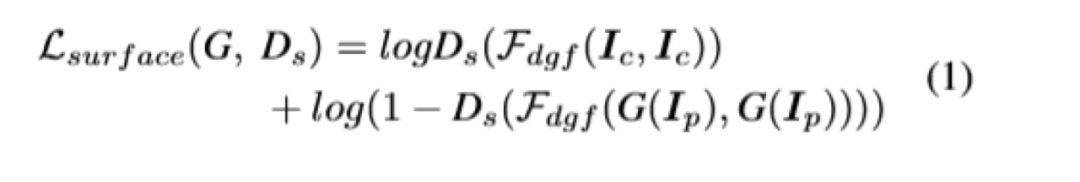
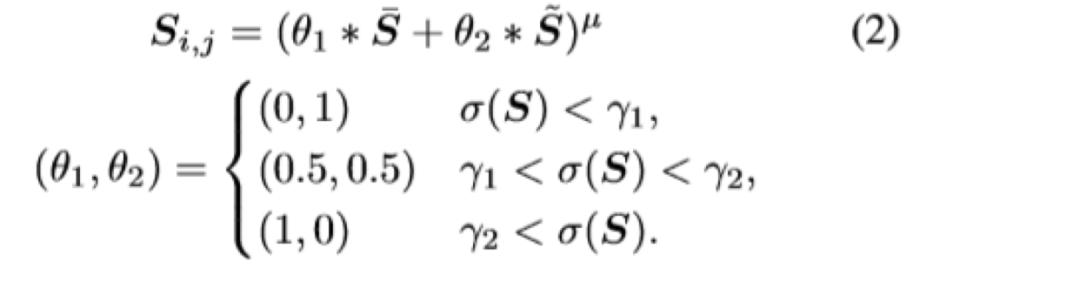
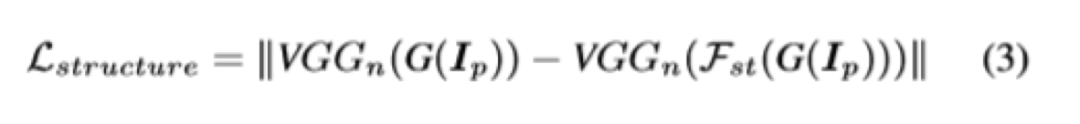



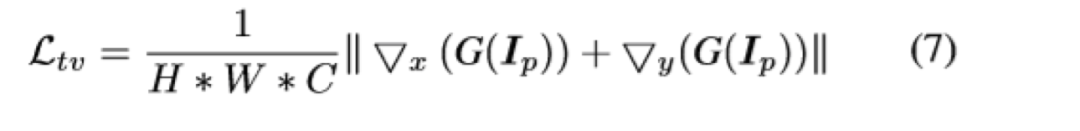
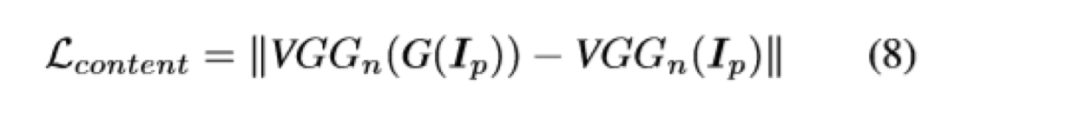






最后的最后求一波分享!
YOLOv4 trick相关论文已经下载并放在公众号后台
关注“AI算法与图像处理”,回复 “200714”获取
个人微信 请注明:地区+学校/企业+研究方向+昵称 如果没有备注不拉群!

评论