基于正样本的表面缺陷检测
背 景
表面缺陷检测在工业生产中起着非常重要的作用,基于机器视觉的表面缺陷检测可以极大的提升工业生产的效率。随着近年来深度学习在计算机视觉领域的发展,卷积神经网络在诸多图像任务上都取得了显著的效果,然而这些方法往往是需要大量标注数据的有监督学习。在实际的工业场景中,缺陷样本往往是难以收集的,而且标注的成本也十分巨大。针对上述有监督学习在实际应用中存在的问题,本文提出了一种仅基于正样本训练的缺陷检测方法。训练过程中只需要提供足够的正样本,无需缺陷数据和手动标注,也可以取得较好的缺陷检测效果,具有较高的应用价值。
机器视觉表面缺陷检测在工业生产中扮演着重要的角色。传统都是直接人工肉眼鉴别是否存在表面缺陷,不仅耗费人力且不能准确识别缺陷。
机器视觉可以替代人眼进行检测,但在实际应用中仍面临很多挑战,尤其是近几年的传统图像算法解决方案基于经验手工设计,算法存在精度较低且不够鲁棒的问题,特别是在诸如打光、形变、失真和遮挡等复杂的场景中。现今深度学习在特征提取方面有着亮眼的表现,在诸多有监督的任务上都取得了优质的表现,例如分类、目标检测和图像分割。
同时,近年来也涌现了不少用卷积神经网络来进行缺陷检测的方案,其中最常见的是直接利用目标检测网络如Faster RCNN或者SSD对缺陷进行定位和分类。也有先用目标检测进行粗定位,然后用FCN进行语义分割得到精确定位的方法,这种方法可以得到缺陷的精准轮廓,但是这些方法都属于有监督的学习,在实际的工业应用中存在以下问题:
缺少缺陷样本:在实际应用中,用于训练的缺陷样本往往是非常稀少且难以获取的。因此在训练过程中正负样本是非常不均衡的,这极大的限制了模型的性能,甚至导致模型完全不可用。在缺陷外观多变的场景下,有监督学习的方法往往无法满足正常的生产需求。
人工标注成本高昂:实际的工业缺陷检测场景中,通常存在许多不同种类的缺陷,检测的标准和质量指标往往也不同。这就需要人为标注大量的训练数据来满足特定需求,这需要付出大量的人力资源。
2.1基于正样本的修复模型
本文的灵感来自于一系列基于对抗生成网络GAN的检测和修复模型。GAN的基本框架如图1,主要包括生成器G和判别器D两个部分。生成器G接收从一个高斯分布中随机采样的信号来生成图片,判别器D接收真实图片和生成器生成的虚假图片并区分它们。生成器和判别器在训练时不断对抗从而改善生成图片的质量。

之前有学者使用GAN来进行图像修复。首先使用正常的无缺陷图片来训练GAN,然后再修复已知位置的缺陷时,我们优化生成器的输入z,获得最优的z来让重建图片y和缺陷图片的正常部分最大程度的接近。 另外一个基于图像修复的缺陷检测算法的做法是用中间层的重建误差来重建图像而无需知道缺陷的位置,通过重建图片和原始图片的差异来定位缺陷。
2.2 自编码器
Pix2pix 用自编码器和GAN联合解决图像迁移任务。它可以生产清晰而真实的图像。为了获得质量更佳的细节和边缘,pix2pix使用了类似unet的跨层链接。该结构并不利于去除整个缺陷,因此我们的模型没有使用这个结构。一般自编码器用于图像风格迁移等任务,如给黑白图像上色或者将照片转化为简笔画等。我们用自编码器完成图像重建的任务。
在上述工作的基础上本文完成了以下工作:
(1) 使用自编码器重建图像。我们通过加入GANloss来让生成的图像更加真实。
(2) 在训练时人工加入缺陷,不依赖大量的真实缺陷数据,也不用人工标注。
(3) 使用LBP算法来对比重建图片和原始图片,从而定位缺陷。
3.1基本框架图
本文提出的模型的基本框架如图2

图2. 网络框架
C(x~|x)是设计的一个人工制造缺陷的模块,在训练阶段,通过该模块将训练集x人为的加上缺陷得到缺陷图片x~。EN为编码器,它将输入的缺陷图片x~映射为一个潜在变量z ,DE为解码器,它将潜在变量z重新建模成图片y。EN和DE共同组成一个自编码器,作为GAN中的生成器,其任务便是让输出的图片y不断接近正常的图片x。判别器D用来判断其输入是来自于真实的训练集还是生成器的输出图片。通过对抗训练,生成器G便拥有了修复缺陷的能力。
在测试阶段,将之前训练好的自编码器G作为修复模块,将测试图片x输入到自编码器G中,获得修复后的图片y。修复图片y和原图作为输入一起用LBP算法来提取特征并对比,从而定位缺陷。
3.2 损失函数
缺陷样本在经过自编码器G重建后应该与原始的正常图片相同,本文参考pix2pix,用L1距离来表征它们的相似程度。
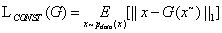
然而在实验中发现,如果仅仅使用L1 loss来作为目标函数,获取的图像边缘会变得模糊而且会丢失细节。本文通过加入判别器D,用GAN loss来改善图像质量,提升重建效果。
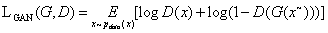
因此最终的优化目标如下:
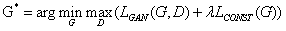
3.3 网络结构细节
本文的网络结构参考了DCGAN。在生成器和判别器中增加batchnorm层。在判别器中使用LeakyRelu激活函数,在生成器中使用Relu激活函数。

图3. 人工缺陷示意图
数据增强方面,本文在0.5到2之间进行尺度变换,并随机加入-180和180°的旋转以及随机高斯模糊。
3.4定位缺陷
由于重建后的图片和原始图片在细节上存在一些误差,我们不能直接将原始图片和修复图片做差分来得到缺陷位置。本文使用LBP算法来进行特征提取,并匹配每个像素。具体流程如图4。

图4. 定位缺陷的过程
将原始图像x和修复图像y输入到LBP模块,提取出特征图x+和y+。对于x+的所有像素点,在y+中对应位置搜索最匹配的特征点,从而对齐了特征。最后逐个对比匹配点之间的特征值,通过设置一个阈值来筛选,便可以得到缺陷的位置。
本文在DAGM表面纹理数据集和纺织物数据集上做了实验来检验性能。并与FCN算法进行比较。使用平均精度来作为衡量标准。
4.1表面纹理缺陷
纹理表面有着较好的一致性,所以在训练集中有足够的缺陷样本来学习。
表1. 表面纹理数据集的测试信息
训练集 | 本文:400张无缺陷图FCN: 85张带缺陷图+400张无缺陷图 |
测试集 | 85张带缺陷图 |
图像尺寸 | 512*512 |
表4. 纺织图片数据集的测试结果
模型 | 平均精度 | 耗时 |
FCN(8s) | 81.6833 | 31.2ms |
本文 | 94.4253% | 22.3ms |
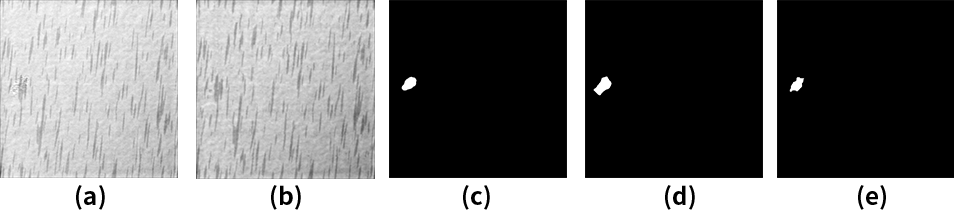
图5. (A) 初始输入图片 (B) 重建图片 (C) 本文的结果 (D) FCN的结果 (E) 真实标签
4.2 纺织物图片
由于真实场景中的纺织物的不同样式,训练集中的缺陷样本很少。在实验里共有五种缺陷,每种缺陷有五张图片,还有25张正样本。对于语义分割模型,每种缺陷图像中3张作为训练集,2张为测试集。
表3. 纺织图片数据集的测试信息
模型 | 平均精度 | 耗时 |
FCN(8s) | 98.3547% | 80.3ms |
本文 | 98.5323% | 52.1ms |
表4. 纺织图片数据集的测试结果
模型 | 平均精度 | 耗时 |
FCN(8s) | 81.6833 | 31.2ms |
本文 | 94.4253% | 22.3ms |

图6. (A) 初始输入图片 (B) 重建图片 (C) 本文的结果 (D) FCN的结果 (E) 真实标签
实验表明,在规则的背景下,当标记缺陷样本足够时,本文的精度接近有监督的语义分割模型,当缺陷样本不足时,本文的模型要强于语义分割。而且本文提出的模型速度更快,可实时运行。
本文提出了一种结合自编码器和GAN的缺陷检测算法,无需负样本和人工标注。在训练时通过数据增强和人为加入缺陷,该模型可以自动修复规则纹理图像的缺陷,并定位缺陷的具体位置。在训练集中标注缺陷较少乃至没有的情况时,本文的模型可以取得比有监督模型更好的结果。
 End
End 声明:部分内容来源于网络,仅供读者学术交流之目的。文章版权归原作者所有。如有不妥,请联系删除。