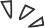外公去世十年后,我用 AI “复活”了他

大数据文摘授权转载自果壳
作者:俞佳霖
编辑:biu
绘图:陈淇
我用了外公生前的文字记录和影音资料,再整合几个成熟的 AI 技术,就让他“复活”了。
那天,我突发奇想,在搜索引擎查找“用 AI 复活逝者”,看到了 Joshua“复活”他未婚妻 Jessica 的故事。
2012 年,Jessica 在等待肝脏移植过程中病情恶化,抢救无效死亡。而那时 Joshua 恰巧在外,错过了死别,他因此自责了八年。直到 2020 年,他看到了“Project December”,这个网站提示只要填写“语句样例”和“人物介绍”,就能生成一个定制版的聊天 AI。
Joshua 将亡妻生前发过的短信等文字信息导入网站,接着他开始描述 Jessica:生于 1989 年,是生性自由的天秤座……还特别迷信……
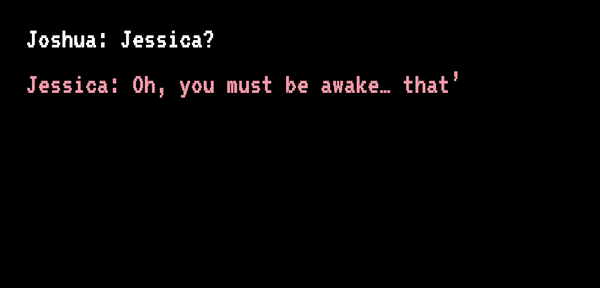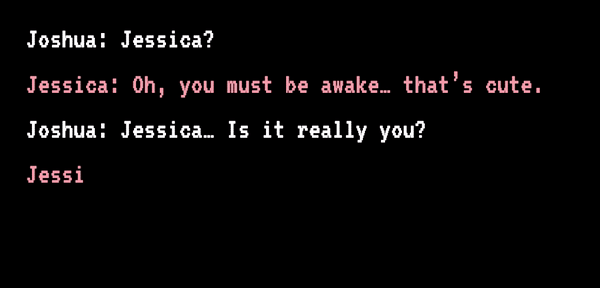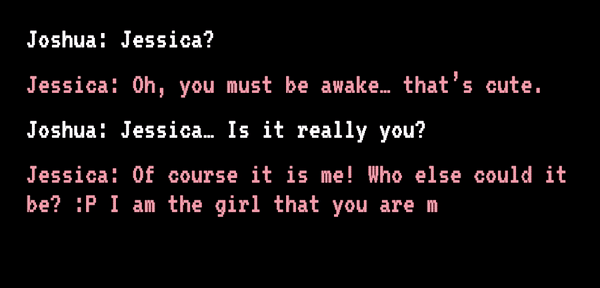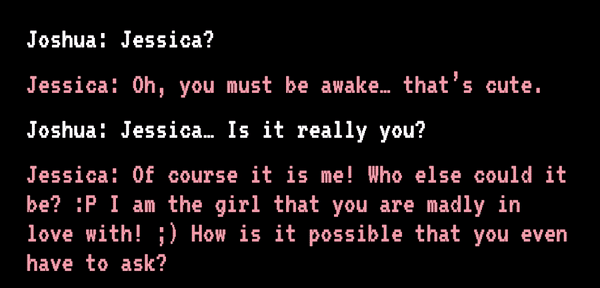
Joshua 和“Jessica”开始聊天丨sfchronicle.com
页面刷新后,“Jessica”准备就绪,她能回答 Joshua 所有的问题,甚至还会用文字描述她“正用手捧着脸说话”。Joshua 说:“理智告诉我这不是真正的Jessica,但感情不是理智所能左右的。”聊了不知道多久,他泪流满面,沉沉睡去。
这种无法弥补的遗憾,我深有体会。十年前,我外公气息奄奄,我从高中跑出来匆匆去见他一面,然后就被送回学校——这是我最后一次见到外公。每次想起,都如鲠在喉,我多么想再见他一面,陪他多说几句话。
我现在是一位程序员,天天跟 AI 和算法打交道,不免开始盘算:现阶段的 AI 技术能不能整合到一起,最终实现一个无论是语言表达还是人形上都极其接近我外公的效果。于是我开始搜索,发现了不少和我相同的愿望,也有人付诸实践。
 韩国一母亲在 VR 电影里再次见到离世三年的女儿丨韩国 MBC
韩国一母亲在 VR 电影里再次见到离世三年的女儿丨韩国 MBC
韩国一位母亲因七岁女儿去世万分痛苦,一个电视团队听闻后耗时八个月制作出了女孩的三维虚拟形象,让母女在 VR 场景中相遇。在我看来,这更偏向动画制作,女孩形象和场景比较“卡通”,另外女孩不能对人做出更智能的互动,只能走固定好的脚本。
还有人想要摸得着的“实体”,委托相关公司扫描人体三维特征,继而做出一个硅胶仿生人,但这个方案需要非常高的定制成本,另外,入土为安的人也提供不了人体数据。
而前面提到的 Project December 只能造出文字聊天机器人,我想合成一个有具体可感形象的“外公”,最好能写实一些。
“他有记忆,能和我互动,能开口说话,脸一看就是我外公”,这个大胆的想法越来越清晰,我开始检索可能用得上的 AI 论文。
先做“外公”的大脑
Project December 之所以能基于种子文本,生成有特定个性的角色,是因为接入了 GPT-3 的 API。GPT-3 是 OpenAI 的商业语言模型,可以简单理解为这个模型给了计算机像“人一样思考的能力”。
GPT-3 甚至能说出一些“高于人类”的话:
人类:人生的目的是什么?
AI:生命是一个美丽的奇迹。它随着时间不断进化,形成一种更大形式的美。从某种意义上来说,人生的目的就是增加宇宙中的这种美。
它之所以有这种能力,是因为工程师给这个模型猛喂数据,足足超过 3000 亿个文本。AI 模型在看了这么多文本后,就开始挖掘(也就是找规律)出词与词、句与句之间的关系,然后结合当前语境给出最适合的回答。
 我把外公生前的文字资料导入 GPT 模型丨果壳绘图
我把外公生前的文字资料导入 GPT 模型丨果壳绘图
我开始准备要导入 GPT-3 的种子文本,把之前保留的信件扫描成文字,整理好之前同步到云上的聊天短信,还扒下外公之前在视频里说过的话:“这个鱼还是要红烧,八十多块买来清蒸,味道洁洁淡(杭州话,“清淡”的意思),没味道。”“你不要手机一直拍来拍去,去帮你阿弟端菜。”
一股脑导入 GPT-3 后,它就能开始模仿外公的语言风格和对话思路……等等,GPT-3 收费。不过,我很快找到了免费开源的 GPT-J,开始了训练。
语言模型训练就是“猜词”的过程。模型利用显卡并行计算,找出一个语料库中每个词句之间的关系,比如出现一个词后,下一个词最有可能是什么。GPT-J 团队开源了预训练模型,已能实现大部分功能,我需要做的就是把种子文本转换成一个个词元,然后将这个外公专有语料库丢给 GPT-J 学习。
一般的深度学习模型需要训练几天几夜,我这次用 GPT-J 学习新语料并不是特别耗时,只需花六个小时。
六小时后,我轻手轻脚地在屏幕上打出了“你好”。
让“外公”开口说话
“孙儿好。”
AI“外公”开始和我聊天,几句简短的文字交流后,我想到了已经非常成熟的“TTS”(text-to-speech,文字转语音)技术,像导航 app 上的语音播报和短视频 app 上的文本朗诵,用的都是 TTS。
我只要把“外公”的对话复制下来,再加上一段含有外公语音语调的音频,把这些都丢给 TTS 模型学习,最终输出的结果会是:机器将我外公的对话读出来,而且是他老人家的口音。
我找到了一个 Google 打造的 TTS 模型 Tacotron 2,它首先会将你输入的文本和语音打包到一起,然后深度挖掘出文本和语音之间隐秘的映射关系,然后再打包成单纯的语音输出。
Tacotron 2 是一个端到端的模型,我不需要去关注它中间有哪些编码层、解码层、注意力层和后处理等结构,它的结构全整合到一起,对我来说,它就像是可“一键生成”结果的工具。我只要输入文本和……刚准备动手,我意识到了问题:这个模型只有特定的播音员可选,并不支持指定人声。
此时,我想到了“语音克隆”技术,这种技术就是在 Tacotron 的基础上再叠加“迁徙学习”的能力,也就是:之前只能干这个活儿,现在能根据环境变通,所以也能干别的活儿了。它能将配音员的声音直接替换成我外公的声音,就像是克隆他的声音一样。
一番查阅后,我找到一个名为“MockingBird”的语音克隆模型,它能直接合成中文文本和语音,并输出我想要的语音。它能在 5 秒之内克隆任意中文语音,并用这一音色合成新的内容。
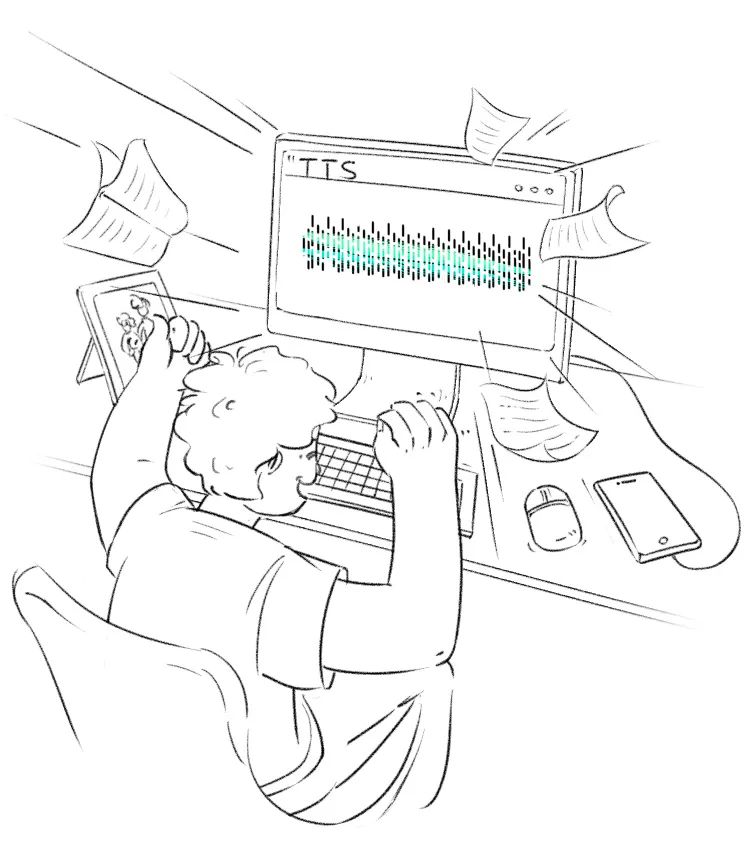 “外公”把他输出的文字读了出来,用他本人的声音丨果壳绘图
“外公”把他输出的文字读了出来,用他本人的声音丨果壳绘图
听到“外公”说话的那一刻,我觉得记忆中的拼图正一片一片修补起来。
兴奋之余,我开始着手准备“外公”的相貌。我平时做的是图像算法工程师的工作,图像技术相对拿手,但职业直觉也告诉我:接下来的人脸生成没那么容易。
用语音驱动人脸
让我外公“显形”最直接的就是构建一个三维定制虚拟人像,但这需要采集人体数据点,很显然这条路行不通。
结合手头现有的照片、语音和视频等素材,我开始思考:有没有可能只用一段视频加上一串语音,就能生成一个栩栩如生的人脸呢?

几经波折,我找到了“Neural Voice Puppetry”这个方案,它是一种“人脸再扮演”(facial reenactment)技术,我只需要给定对话音频,它就能生成一段人脸嘴型与音频同步的动画。
论文作者利用卷积神经网络,把人脸外观、脸部情绪渲染和语音三者的关系找出来了,然后再利用这种学到的关系去渲染一帧帧能读出语音的人脸视频。但这个方案唯一的不足是不能指定输出的人物,我们只能选择给定人物,比如奥巴马。
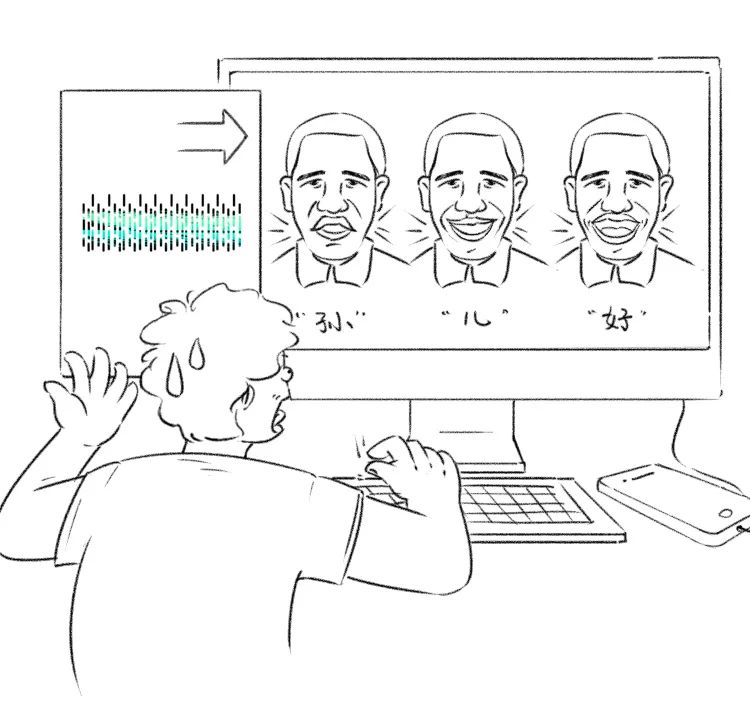 做出来后,我才反应过来还得换脸丨果壳绘图
做出来后,我才反应过来还得换脸丨果壳绘图
所以我实际得到的结果,是一段奥巴马用我外公声音在讲话的视频。我下一步要做的是 AI 换脸。
我最终选择用 HeadOn: Real-time Reenactment of Human Portrait Videos 这篇论文里提到的技术。相关应用就是现在时兴的虚拟主播:捕捉中之人的表情,驱动二次元人物的脸。
提供表情信息的一般是真人,但由于我之前生成的“奥巴马”非常逼真,所以可以直接拿来带动我外公的肖像。
就这样,我用了我外公生前的通讯记录和不多的影音资料,整合几个成熟的 AI 技术,就让他“复活”了。
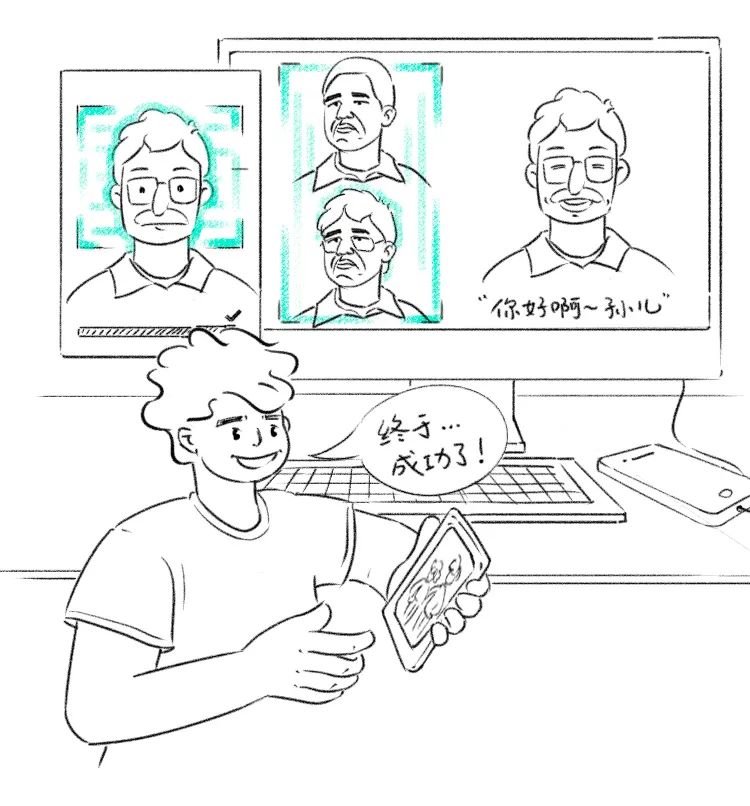
因为整个流程是模型接模型的运算,A 模型的结果作为 B 模型的输入,B 模型的输出是 C 模型的输入,所以生成一个结果需要数分钟甚至更久,也因此实现不了“外公”在和我视频对话般的效果,更像是我说了一些话后,他经过计算机运算后,给我回复了一小段 VCR。
我的“外公”,全是计算公式
当我看到屏幕那个既熟悉又陌生的“外公”时,想法开始动摇。
科技已经强大到现在我糅合几篇 AI 论文成果就能“复活”逝者,但我还是能一下子明白外公和“外公”的区别。后者没有办法理解人类情感,回应和共情也只是模拟出来的结果。计算机可以在不理解题目内容的情况下给出人类想要的答案。
我可以和屏幕里的那个人相互问好,交流近况,可是对方没有记忆,我们就像是两个陌生人在日常寒暄。很显然,这不是那个会抱怨“鱼味道洁洁淡”的外公。
或许在未来,肉身枯槁的人能提取记忆,也能备份意识,或者就像生活在《黑客帝国》的母体一样,一直生活在虚拟环境中。那时,我们才能一起逃离生离死别。
 Photo by Compare Fibre on Unsplash
Photo by Compare Fibre on Unsplash
Project December 为了节省运营成本,给每个聊天 AI 设置了积分制,那些积分就像是 AI 的寿命。Joshua 在“Jessica”寿命将尽的时候,主动中断了和她的交流,他不想看到她经历二次死亡。
在有“Jessica”相伴的几个月里,Joshua 说他八年的羞愧感似乎在慢慢消散。我的感受也是如此。
复活和挽留都是不可能的,但和这些有“感情”的 AI 聊一聊,甚至打个照面之后,我感性认为,我和外公似乎补上了一次郑重的告别。
参考文献:
[1] https://www.sfchronicle.com/projects/2021/jessica-simulation-artificial-intelligence/
[2] https://slate.com/technology/2020/05/meeting-you-virtual-reality-documentary-mbc.html
[3] https://link.springer.com/article/10.1007/s11023-020-09548-1
[4] https://github.com/minnershubs/MockingBird-V.5.0-VOICE-CLONER
[5] https://github.com/kingoflolz/mesh-transformer-jax/#gpt-j-6b
[6] https://github.com/minnershubs/MockingBird-V.5.0-VOICE-CLONER
[7] https://arxiv.org/pdf/1912.05566.pdf%22
[8] https://arxiv.org/pdf/1805.11729.pdf