
从零实现深度学习框架(六)理解广播和常见的乘法

引言
本着“凡我不能创造的,我就不能理解”的思想,本系列文章会基于纯Python以及NumPy从零创建自己的深度学习框架,该框架类似PyTorch能实现自动求导。
要深入理解深度学习,从零开始创建的经验非常重要,从自己可以理解的角度出发,尽量不适用外部完备的框架前提下,实现我们想要的模型。本系列文章的宗旨就是通过这样的过程,让大家切实掌握深度学习底层实现,而不是仅做一个调包侠。
本文来理解下什么是广播,以及其他框架是如何实现各种乘法)的。
广播
在这之前,必须先弄懂广播机制。在NumPy和PyTorch中都有广播机制。
当要进行运算(不仅仅是乘法)的两个向量的形状不同时,如果符合某种条件,小向量会被广播成大的向量,使得它们的维度一致。
当要进行广播时,会逐元素地比较它们的形状。如果两个向量a和b的形状相同。那么像a*b就是对应元素相乘。
> a = np.array([1.0, 2.0, 3.0])
> b = np.array([2.0, 2.0, 2.0])
> a * b
array([2., 4., 6.])
当运算中的两个向量形状不同,但满足某些条件时,将触发广播机制。
> a = np.array([[ 0, 0, 0],
[10,10,10],
[20,20,20],
[30,30,30]])
> b = np.array([1,2,3]) # (3,) -> (1,3) -> (4,3)
> a + b
array([[ 1, 2, 3],
[11, 12, 13],
[21, 22, 23],
[31, 32, 33]])
下图很好的图示了上面的计算过程:
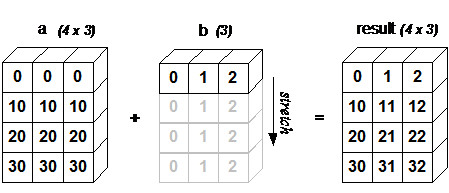
这里b是一个元素个数为3的数组,把它从左边添加一个维度,变成的向量,然后在第1个维度上重复4次,变成了的矩阵,使得a和b的维度一致,再进行对应元素相加的加法运算。
上面说的某些条件是,首先让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都通过在维度左边加 1 补齐,然后比较对应维度值,需要满足:
它们是相等的 其他一个为1
如果不满足该条件,就无法进行广播。
理论总是枯燥的,需要通过实例来理解。
还是以上面的例子为例,
a # (4,3)
b = np.array([1,2,3]) # (3,) -> (1,3) -> (4,3)
a的形状是,b的形状是,b需要向a看齐,首先在其维度左边加1,直到它们拥有相同的维度个数(即a.ndim == b.ndim 为True),因此这里变成;
比较它们的第一个维度值,a和b分别是和,此时b在该维度上重复4次,向大佬看齐,b变成了;
比较它们的第二个维度值,都是,它们是相等的,啥都不做;
它们只有两个维度,比较完了。
然后这里再进行加法操作。
下面看些其他例子:
> a = np.arange(4) # (4,)
> b = np.ones(5) # (5,)
> a + b
ValueError: operands could not be broadcast together with shapes (4,) (5,)

是的,这不合理。它俩的维度值不一样,无法进行对应元素相加,也无法进行广播。
再来看一个相对复杂一点的例子:
> a = np.arange(4).reshape(4,1) # (4,1)
> b = np.ones(5) # (5,)
> (a + b).shape
(4, 5)
> a + b
array([[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.],
[4., 4., 4., 4., 4.]])
乍看起来有点奇怪,我们来分析一下。
a的形状是,b的形状是,b需要向a看齐,首先在其维度左边加1,因此这里变成;
比较它们的第一个维度值,a和b分别是和,此时b在该维度上重复4次,向大佬a看齐,b变成了;
比较它们的第二个维度值,a和b分别是和,嘿,此时b咸鱼翻身成为被仰望的对象了,a向b看齐,a在该维度上重复5次,a变成了
它们只有两个维度,比较完了。
然后这里再进行加法操作。

我们通过手动广播来执行一遍上面的例子。
# 先来看下a和b长啥样
> a
array([[0],
[1],
[2],
[3]])
> b
array([1., 1., 1., 1., 1.])
> a_new = np.repeat(a, repeats=5, axis=1) # a需要在第二个维度上重复5次
> a_new # (4,5)
array([[0, 0, 0, 0, 0],
[1, 1, 1, 1, 1],
[2, 2, 2, 2, 2],
[3, 3, 3, 3, 3]])
再看对b对转换。
> b_new = b[np.newaxis, :] # 现在左边插入一个维度,变成了(1,5)
> b_new
array([[1., 1., 1., 1., 1.]])
> b_new = np.repeat(b_new, repeats=4,axis=0) # 然后在第一个维度上重复4次,变成了(4,5)
> b_new
array([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
它们的维度一致了,现在可以执行按元素相加了。
> a_new + b_new
array([[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.],
[4., 4., 4., 4., 4.]])
> (a_new + b_new ) == (a + b) # 验证一下
array([[ True, True, True, True, True],
[ True, True, True, True, True],
[ True, True, True, True, True],
[ True, True, True, True, True]])
Numpy
Numpy里面提供了很多种进行乘法计算的方法,主要讨论的是numpy.dot、numpy.matmul、numpy.multiply。
np.dot
numpy.dot(a,b)
两个数组的点乘
如果 a和b都是一维(1-D)数组,计算它们的内积如果 a和b都是二维)(2-D)数组,那么计算的是矩阵积,此时推荐使用matmul或a @ b如果 a或b是标量(0-D),等同于multiply,推荐使用numpy.multiply(a,b)或a * b如果 a是一个N维(N-D)数组,b是一个一维数组,那么就是计算a和b最后一个维度(轴)上的内积(按元素相乘再求和)如果 a是一个N维数组,b是一个M维(M-D,M>=2)数组,那么就是a最后一个维度(轴)上和b倒数第二个维度上的内积(对应元素相乘再求和)
> np.dot(3, 4) # 两个标量,等同于a*b
12
> a = np.arange(3) # [0 1 2]
> b = np.arange(3,6) # [3 4 5]
> print(a,b)
[0 1 2] [3 4 5]
> print(np.dot(a,b)) # 0*3 + 1*4 + 2*5=14 两个一维数组,计算它们的内积
14
> a = np.arange(6).reshape(-1,2) # (3,2)
> b = np.arange(2).reshape(2,-1) # (2,1)
> print(a)
[[0 1]
[2 3]
[4 5]]
> print(b)
[[0]
[1]]
> print(np.dot(a,b)) # (3,2) x (2,1) -> (3,1) 两个二维数组,计算矩阵乘法
[[1]
[3]
[5]]
下面来看一下稍微复杂一点的第4种情况
> a = np.arange(1,7).reshape(-1,3) #(2,3) a是二维数组
[[1 2 3]
[4 5 6]]
> b = np.array([1,2,3]) # (3,) b是一维数组
[1 2 3]
> c = np.dot(a,b) # 计算a和b最后一个轴上的内积之和
[14 32]
相当于是用a的最后一个轴,(2,3)中3对应的那个轴去和b的最后一个轴,也是第一个轴(3)去计算内积,即
[1*1 + 2*2 + 3*3, 4*1 + 5*2 + 6*3] = [14,32]
最复杂的是最后一种情况,由于博主无法想象出超过三维的情况(如果你能想象出来,🎉,你应该可以很好理解),因此这种情况只能根据官网提供的公式去计算,无法打印出具体元素。
其实下面的例子已经简化成三维来,实际上是可以画一个立方体矩阵出来的,上面说的话都是借口,主要是懒。
a = np.arange(3*4*5).reshape((3,4,5)) # (3,4,5)
b = np.arange(5*6).reshape((5,6)) #(5,6)
a是一个三维数组,b是一个二维数组,np.dot(a,b)就是a最后一个维度(轴)上和b倒数第二个维度上的内积(对应元素相乘再求和)
> c = np.dot(a, b) # (3,4,5) (5,6) ⚠️a的最后一个轴上元素个数是5,b的倒数第二个轴上的元素个数也是5
> print(c.shape)
(3, 4, 6)
sum(a[i,j,:] * b[:,m]) -> [i,j,m]
主要是通过上面这么计算的,证明:
print(c[2,3,5]) # 4905
print(sum(a[2,3,:] * b[:,5])) # 4905
实际上官网给的公式是这样的:
dot(a, b)[i,j,k,m] = sum(a[i,j,:] * b[k,:,m]) -> [i,j,k,m]
窃以为四维有点复杂,因此改成了三维。
为了理解一个复杂的知识点,我们应该把复杂的问题简单化,抓住主要脉络(规律),理解了之后再去拓展。类似阅读源码,我们应该先理清楚主要流程,一些支流像异常处理,调用某个复杂的函数实现都可以先不管。
计算公式就是这样子,暂时想不到应用场景。
因此为了代码的可读性,建议只有在都是一维数组时,才用np.dot,其他情况使用相应的推荐函数。可能这也是torch对此进行简化的原因。
np.matmul
numpy.matmul(a,b)
计算两个数组的矩阵积:
如果两者都是2-D数组,此时就像我们常见的矩阵乘法
如果任意一个参数的维度是N-D(N > 2),它将被视为位于最后两个维度中的矩阵的堆叠,并相应地广播。
如果
a的维度是1-D,它会通过在左边插入1到它的维度提升为矩阵,然后与b进行矩阵乘法,完了之后插入的1会被移除如果
b的维度是1-D,它会通过在右边插入1到它的维度提升为矩阵,然后与a进行矩阵乘法,完了之后插入的1会被移除
matmul与dot主要有两个不同:
不允许与标量做乘法,用 *代替矩阵堆叠,按元素广播: (n,k) x (k,m) -> (n,m)
情形1:
> a = np.array([[1, 0],
[0, 1]])
> b = np.array([[4, 1],
[2, 2]])
> np.matmul(a, b) # 第一行是[1*4+0*2, 1*1+0*2] = [4,1]
array([[4, 1],
[2, 2]])
情形2:
> a = np.arange(2 * 2 * 4).reshape((2, 2, 4))
> b = np.arange(2 * 2 * 4).reshape((2, 4, 2))
> np.matmul(a,b).shape # (2,2,4)x (2,4,2) -> (2,2,2)
(2, 2, 2)
对于a,它被看成是两个的矩阵的堆叠;
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 8, 9, 10, 11],
[12, 13, 14, 15]]])
同样对于b,也会看成是两个的矩阵的堆叠。
array([[[ 0, 1],
[ 2, 3],
[ 4, 5],
[ 6, 7]],
[[ 8, 9],
[10, 11],
[12, 13],
[14, 15]]])
因此np.matmul(a,b)则会将a的第一个矩阵和b的第一个矩阵相乘,将a的第二个矩阵b的第二个矩阵相乘,最终得到一个的矩阵。
情形3:
> a = np.array([1, 2]) # (2,) -> (1,2) 就像执行了后面的代码 a = a[np.newaxis, ...]
> b = np.array([[1, 0],
[0, 1]]) # (2,2)
> np.matmul(a, b) # (1,2) x (2,2) -> (1,2) -> (2,)
array([1, 2])
情形4:
> a = np.array([[1, 0],
[0, 1]]) # (2,2)
> b = np.array([1, 2]) #(2,) -> (2,1)
> np.matmul(a, b) # (2,2) x (2,1) -> (2,1) -> (2,)
array([1, 2])
不能与标量做乘法:
> np.matmul([1,2], 3)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
-36-33405c3e27ac> in ()
----> 1 np.matmul([1,2], 3)
ValueError: matmul: Input operand 1 does not have enough dimensions (has 0, gufunc core with signature (n?,k),(k,m?)->(n?,m?) requires 1)
矩阵堆叠,按元素广播。
> a = np.arange(2*2*4).reshape((2,2,4))
> b = np.arange(2*4).reshape((4,2)) # (4,2) -> (1,4,2) --Repeat--> (2,4,2)
> np.matmul(a, b).shape #(2,2,4) x (2,4,2) -> (2,2,2)
(2, 2, 2)
这里涉及到了广播操作。
首先b会从最左边插入维度1,直到维度数量和多的(a)保持一致;然后把b复制一次,堆叠上去,使它的维度和a保持一致;最后进行情形2的计算。
💡可以用@来代替np.matmul,比如上面可以写成:
> a @ b
array([[[ 28, 34],
[ 76, 98]],
[[124, 162],
[172, 226]]])
numpy.multiply
numpy.multiply(x1,x2)
对两个参数执行按元素相乘(对应元素相乘)。如果它俩的形状不同,必须进行广播以匹配维度。
> np.multiply(2.0, 4.0)
8
> x1 = np.arange(9.0).reshape((3, 3)) # (3,3)
> x1
array([[0., 1., 2.],
[3., 4., 5.],
[6., 7., 8.]])
> x2 = np.arange(3.0) # (3,) -> (1,3) --Repeat--> (3,3)
array([0., 1., 2.])
> np.multiply(x1, x2) # (3,3) x (3,3) -> (3,3)
array([[ 0., 1., 4.],
[ 0., 4., 10.],
[ 0., 7., 16.]])
这里再解释一下广播里的repeat,这里复制了2次,堆叠在一起,就像下面这样:
> x2_new = np.array([x2,x2,x2])
> x2_new
array([[0., 1., 2.],
[0., 1., 2.],
[0., 1., 2.]])
我们来乘一下验证一下:
> np.multiply(x1, x2_new)
array([[ 0., 1., 4.],
[ 0., 4., 10.],
[ 0., 7., 16.]])
💡可以用*来代替np.multiply。
好了,NumPy的乘法先探讨这么多,我们下面来看PyTorch中常用的乘法。
Torch
PyTorch里面也提供了很多种进行乘法计算的方法,主要讨论的是torch.dot、torch.matmul、torch.mm和torch.bmm。
torch.dot
⚠️和numpy不同, a和b必须都是一维向量,并且元素个数相同。
> a = torch.tensor([2, 3])
> b = torch.tensor([2, 1])
> print(a.shape)
torch.Size([2])
> print(b.shape)
torch.Size([2])
> print(torch.dot(a,b)) # 2x2 + 3x1
tensor(7)
torch.dot很简单,torch.matmul就会复杂一些了,相当于把np.dot中的相关特性移到此方法了。
torch.matmul
torch.matmul(a,b)
两个张量(Tensor)的矩阵乘法。
乘法的结果取决于两个张量的形状:
如果都是一维的,返回它们的内积,结果是一个标量。 如果都是二维的,返回矩阵积。 如果 a是一维的,b是二维的,那么a会通过在左边插入1到它的维度提升为矩阵,然后进行矩阵乘法,完了之后,插入的维度会被移除。如果 a是二维的,b是一维的,那么会返回矩阵-向量乘法结果。如果两个参数都至少是一维的,且至少一个参数是N维的(其中N > 2),则返回一个批量(batched)矩阵乘法。如果 a是一维的,为了进行批量矩阵乘法,在维数左边加1,运算之后维度1删除。如果b是一维的,在其维数右边加1,然后删除。非矩阵维度(即批量)会被广播。
下面一个一个来看。
情形1:
# vector x vector
> a = torch.randn(3)
> b = torch.randn(3)
> torch.matmul(a, b).size() # 得到一个标量
torch.Size([])
情形2:
# matrix x matrix
> a = torch.randn(3,2)
> b = torch.randn(2,4)
> torch.matmul(a,b).size() # (3,2) x (2,4) -> (3,4)
torch.Size([3, 4])
情形3:
# vector x matrix
> a = torch.randn(3) # (3) -> (1,3)
> b = torch.randn(3,4) # (3,4)
> torch.matmul(a,b).size() # (1,3) x (3,4) -> (1,4) -> (4)
torch.Size([4])
情形4:
# matrix x vector
> a = torch.randn(3, 4) # (3,4)
> b = torch.randn(4) # -> (4,1)
> torch.matmul(a, b).size() # (3,4) x (4,1) -> (3,1) -> (3)
torch.Size([3])
情形5 - 批矩阵 ✖️ 广播向量
# batched matrix x broadcasted vector
> a = torch.randn(10, 3, 4) # (10,3,4) 相当于10个(3,4)的矩阵
> b = torch.randn(4) # (4,1) -> (10,4,1) 会复制(4,1)的矩阵9次,得到10个一样的(4,1)矩阵
> torch.matmul(a, b).size() #(10,3,4) x (10,4,1) -> (10,3,1) -> (10,3)
torch.Size([10, 3])
情形5 - 批矩阵 ✖️ 批矩阵
# batched matrix x batched matrix
> a = torch.randn(10, 3, 4) # (10,3,4) 相当于10个(3,4)的矩阵
> b = torch.randn(10, 4, 5) # (10,4,5) 相当于10个(4,5)的矩阵
> torch.matmul(a, b).size() # (10,3,4) x (10,4,5) -> (10,3,5) 得到10个(3,5)的矩阵
torch.Size([10, 3, 5])
情形5 - 批矩阵 ✖️ 广播矩阵
# batched matrix x broadcasted matrix
> a = torch.randn(10, 3, 4) # (10,3,4)
> b = torch.randn(4, 5) # (4,5) -> (10,4,5)
> torch.matmul(a, b).size() # (10,3,4) x (10,4,5) -> (10,3,5)
torch.Size([10, 3, 5])
可以看到,情形5先把某一参数转换为矩阵,然后进行矩阵运算,对于(10,3,4)这种维度可以理解为堆叠了10个(3,4)的矩阵,也可以理解为该批次内有10个(3,4)的矩阵。
⚠️广播逻辑只应用于批次维度上,而不是矩阵维度上。比如a是一个的张量,然后b是一个的张量。这里的批次维度和是可以被广播的,两者都广播为。因此,最后得到的结果是。
> a = torch.randn(10, 1, 3, 4) # 矩阵维度(3,4) ,批维度(10,1),广播为(10,2)
> b = torch.randn(2, 4, 5) # 矩阵维度(4,5),批维度(2),广播为(10,2)
> torch.matmul(a, b).size() # (10,2,3,4) x (10,2,4,5) -> (10,2,3,5)
torch.Size([10, 2, 3, 5])
torch.mm
torch.mm(a,b)
在这两个矩阵上进行矩阵乘法。
如果a是张量,b是张量,结果就是的张量。
⚠️ 这个函数不支广播。
> a = torch.randn(2, 3)
> b = torch.randn(3, 3)
> torch.mm(a, b).size() # (2,3)
torch.Size([2, 3])
torch.bmm
torch.bmm(a,b)
进行一个批矩阵-矩阵乘法。
两个参数都必须是3-D张量,并且含有相同的矩阵个数(批次数相同)。
若a是一的张量,b是一的张量,输出为的张量。
⚠️该函数也不支持广播。
> a = torch.randn(10, 3, 4)
> b = torch.randn(10, 4, 5)
> torch.bmm(a, b).size()
torch.Size([10, 3, 5])
总结
本文我们知道了什么是广播,下篇文章来看一下我们自己的metagrad如何支持广播操作。
Reference
NumPy官方文档
PyTorch官方文档
Numpy广播
最后一句:BUG,走你!


Markdown笔记神器Typora配置Gitee图床
不会真有人觉得聊天机器人难吧(一)
Spring Cloud学习笔记(一)
没有人比我更懂Spring Boot(一)
入门人工智能必备的线性代数基础
1.看到这里了就点个在看支持下吧,你的在看是我创作的动力。
2.关注公众号,每天为您分享原创或精选文章!
3.特殊阶段,带好口罩,做好个人防护。