
ExMobileViT | 优化轻量化ViT的不二选择,源于MobileViT又高于MobileViT!
点击下方卡片,关注「AI视界引擎」公众号

该论文提出了一种有效的结构,用于提升移动友好型视觉Transformer的性能,同时计算开销很小。视觉Transformer因其在图像分类中取得了优异的结果而备受青睐,相较于传统的CNNs。
由于其需要大量计算资源,因此已经开发了基于MobileNet的ViT模型,例如MobileViT-S。然而,它们的性能无法达到原始ViT模型。所提出的结构通过存储早期注意力阶段的信息并在最终分类器中重新使用它来缓解上述弱点。
本文的动机是早期注意力阶段的数据本身可能对最终分类具有重要意义。为了重复使用来自注意力阶段早期的信息,使用来自早期注意力阶段的各种尺度特征的平均池化结果来扩展最终分类器的通道。预期通过平均特征引入的归纳偏差可以提高最终的性能。
由于所提出的结构仅需要来自注意力阶段特征的平均池化和最终分类器中的通道扩展,因此其计算和存储开销非常小,保持了低成本的MobileNet-based ViT(MobileViT)的优势。与原始的MobileViT在ImageNet数据集上相比,提出的ExMobileViT在几乎仅增加约5%的参数的情况下,具有显着的准确性提升。
1、简介
除了CNN的成功之外,还开发了基于CNN的各种拓扑结构用于图像分类。然而,有关感受野的限制以及在图像中捕捉长距离依赖性的困难阻碍了CNN在图像分类中实现高性能。另一方面,ViT利用自注意力机制来建模像素之间的长距离交互,学习视觉特征的丰富表示。已经证明,与CNN相比,ViT在图像分类中可以具有更强大和更广义的特性。
然而,由于处理高分辨率图像需要许多标记和参数,ViT需要大量的计算资源和内存。为了克服这一限制,提出了MobileViT,以结合ViT的优势和MobileNet的卷积结构。MobileNet采用了轻量级的CNN拓扑结构,使用深度可分离卷积,降低了模型参数的计算和存储成本。除了低成本的MobileNet的好处,MobileViT将MobileNet的轻量级卷积拓扑结构应用于ViT。
在先前的研究中,MobileViT在各种图像识别领域,如图像分类、目标检测和语义分割等方面展现出了有希望的结果。尽管MobileViT及其各种轻量级版本实现了更小的计算和参数,但与ViT相比,它们仍然可以显示出相当或更好的性能。因此,MobileViT非常适用于资源有限的边缘计算设备。然而,与原始的ViT相比,MobileViT的性能下降,这可能是其主要缺点。
为了克服MobileViT的上述弱点,作者提出了一种名为ExMobileViT的新型结构,以增强其性能,成本增加很小。预计早期关注阶段的数据本身对于分类具有重要意义。为了将它们用于最终的图像分类,从早期关注阶段提取的信息被存储并在最终分类器中重复使用。该信息是从各种尺度的特征图中提取的。从早期关注阶段的各种尺度特征的平均池化用于扩展最终分类器中的通道。由于其简单的附加结构,ExMobileViT仍然保持了MobileViT的成本效益,而附加存储成本很小。与ImageNet数据集上的MobileViT-S相比,提出的ExMobileViT在几乎只增加了约5%的参数的情况下,具有明显的精度提升。
2、ExMobileViT
2.1 增加分类器通道的动机
作者关注MobileViT的优点。MobileViT将CNN与ViT结合起来,以在轻量级的同时实现高性能。虽然CNN的感受野在训练中使用了局部特征,但通过Transformer,作者认为在训练中使用了全局特征。尽管其轻量级,MobileViT实现了非常高的准确性。然而,MobileViT在巨大的ViT模型上性能下降的弱点。在ViT中,参数数量和分类准确性之间存在一个权衡关系,这会影响准确性和硬件成本之间的权衡。为了解决这个问题,作者关注了在ViT中对预处理数据进行数据重用。
通过数据重用,作者希望避免通过添加额外的层或高成本块来增加模型的深度以获得更好的性能。增加模型复杂性确实会增加计算成本。但是,修改基线模型的整体结构是困难的。因此,数据重用方法激励作者增加ViT的性能。基于传统CNN的思想,有两种方法可以有效实现数据重用:多尺度特征图可以用于从多个角度提取有意义的数据。Shortcuts可以将数据从早期阶段传递到模型的深层。众所周知,通过绕过数据到达深层,Shortcuts可以确保数据的平稳流动。
值得注意的是,利用多尺度特征图在包括目标检测和分割任务在内的各个领域中都是常用的。使用多尺度特征的方法非常有用于检测和识别不同尺寸的目标。例如,U-Net对特征进行下采样,并利用不同层次的图像。在U-Net中,特征逐渐下采样,直到捕获高级上下文信息。U-Net的思想激励作者,即多尺度特征图允许目标模型从各种角度学习信息。因此,预计模型可以通过合并不同尺度的特征图来捕获和编码局部和全局特征。
另一方面,为了补充基于注意力的ViT的不足归纳偏差,作者融合了CNN来编码局部信息。它可以与注意力块的全局特征一起用于训练。此外,在广义金字塔模型架构中,可以轻松获得各种尺度的特征图。为了从每个尺度的特征图中提取数据,可以存储并重复使用不同尺度的每个块的输出。基于上述动机,作者提出了直接馈入分类器的Shortcuts的使用,称为ExShortcut。
2.2 直接连接到分类器的ExShortcut结构
MobileViT的结构包括MV2块和MobileViT运算符。MV2块用于在MobileViT中对图像进行下采样。在MV2块中使用了MobileNetV2中提出的残差块。残差块中的1×1卷积有助于减少CNN操作中使用的参数数量。然后,经过MobileViT块处理下采样的特征图,它结合了CNN和Transformer的优势。
在MobileViT中,模型可以分为5个块,不包括通道级的平均池化。前两个块由MV2块组成,用于对输入图像进行下采样。其他3个块具有MV2块和MobileViT运算符。在MobileViT中,它由CNN和Transformer组成,编码了局部-全局-局部信息。
输出特征图的大小在接下来的CNN操作中很重要。对于轻量级模型,进行了多次下采样。在这种情况下,作者认为在下采样过程中最关键的是数据损失最小化。
为了解决这个问题,作者将ExShortcut连接到Transformer块之后的分类器。通过直接连接ExShortcut,早期阶段的信息可以提供给分类器。因此,分类器的输入通道通过原始分类器输入通道和添加的ExShortcut扩展,如图1所示。
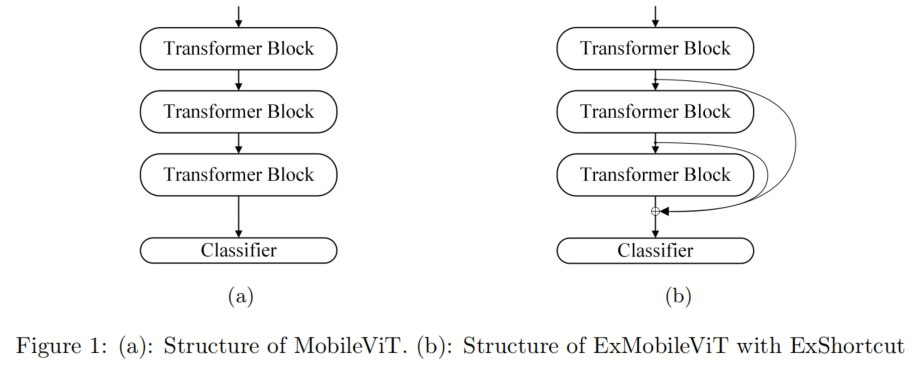
2.3 通道扩展
在大多数模型中,包括MobileViT,随着接近分类器,特征图的大小变得更小,通道数增加。特征图在进入分类器之前被压平为1×1×C的特征。最终,分类性能由输入到分类器的输入数据确定。在先前的研究中,继续研究从多尺度特征图中提取信息的方法。这种方法在目标检测和分割中得到了广泛研究。为了在图像分类中利用多尺度特征图,作者提出了在分类器中进行通道扩展。因此,编码信息差异地加载到多尺度特征图中以供分类器使用。连接Shortcuts到分类器通道后,合并Shortcuts的通道后的参数Ptotal可以表示如下:

其中,
表示每个特征图的通道比率。如(1)所示,
与块的输出特征图的通道(表示为
)相乘。它们被连接在一起以用作分类器的输入。通过调整
,可以扩展或压缩分类器的通道。如果不扩展通道,则
设为0。
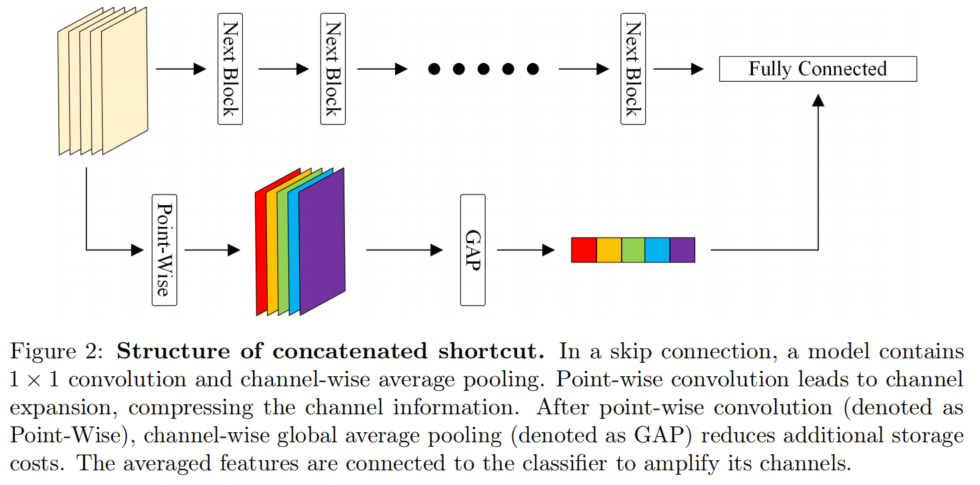
在图2中,ExShortcut由1×1卷积和通道级平均池化组成。逐点卷积对输入特征图中的每个像素进行加权和以激活。
由于ReLU系列是带有非线性的激活函数,使用ReLU系列的逐点卷积也会增加非线性。输出通道使用每个通道的超参数ρ进行调整。完成逐点卷积后,使用1×1×
Kernel信息执行1×1卷积。然后,对分类器进行通道扩展。
2.4 ExMobileViT:用于移动视觉变换器的轻量级分类器扩展
大型模型具有从各种数据中提取特征的强大能力。最近的SOTA模型通过使用多尺度特征聚合(MSFA)或特征金字塔网络(FPN)来实现提取能力。作者的想法是通过从多个尺度提取数据来最大化能力,同时最小化数据存储。为了实现这个想法,作者使用了对图像进行下采样并提取特征图的轻量级模型,通过Shortcuts直接对分类器进行通道扩展。如前所示,模型在应用到分类器之前会使用平均池化将输入转换为标量。为了标准化池化数据大小,每个通道在分类器之前都会经历平均池化。
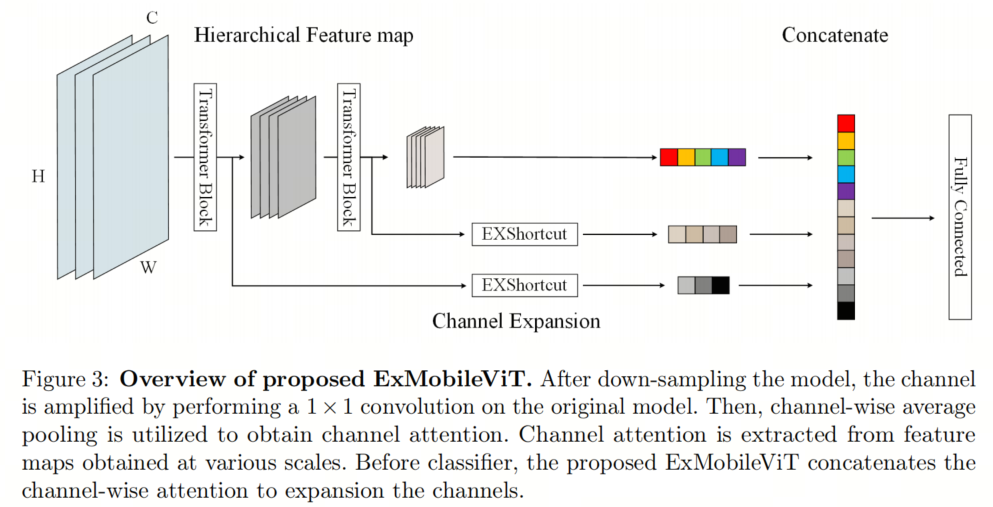
图3展示了基于MobileViT作为骨干的提出的ExMobileViT模型的结构。左侧的特征图被用作它们各自Transformer块的输入,其中从每个Transformer块的输出中提取了Shortcuts。
与原始的MobileViT一样,模型在特征图的下采样中提取局部-全局-局部信息。最后的特征图在最后一个块之后通过通道级平均池化进入分类器。然后,在执行分类器之前,具有1×1×
特征图的Shortcuts扩展通道。
2.5 反向传播
根据链式法则,随着模型的深度增加和计算的进行,梯度趋于收敛于零。Shortcuts被认为可以在训练过程中防止梯度消失[32]。这些Shortcuts可以加快训练速度并稳定模型优化。
尽管提出的模型结构较深,但可以确保Shortcuts提供稳定的反向传播。
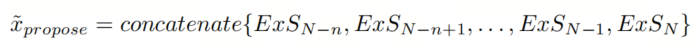
在经典方法中,仅使用最后一个块的输出进行分类。方程(2)描述了分类器的输入,
。符号
表示ExShortcut的连接。当Shortcuts连接到模型时,前一个信号直接连接。如果Shortcuts嵌套,模型的非线性将增加其复杂性。当数据通过Shortcuts传播时,中间块中的值可以收敛。与使用
→
训练模型不同,作者训练了从
→ 的模型。在Shortcuts中,进行1×1卷积,其中卷积增强了模型的非线性。结果表明,与原始模型相比,性能提高了13%。
此外,作者的模型在保持或提高性能的同时在260个Epoch内收敛,而原始模型需要300个Epoch才能收敛。在提出的模型中,通道扩展需要更多的计算资源。然而,训练期间的收敛速度增加,加快了训练速度。
3、实验
3.1、ImageNet实验
基于Transformer的MobileViT在没有足够大的数据集的情况下进行训练也会面临困难。在CIFAR-100数据集上,原始的MobileViT达到了75.5%的准确率,这低于在ImageNet数据集上的准确率。利用预训练模型不适合实验设置。
因此,作者只在ImageNet数据集上进行了实验,与原始的MobileViT一样。提出模型、ExMobileViT系列和原始MobileViT的准确率图可以在图4中找到。为了进行精确的观察,将第200到300个epoch的空白空间放大。相同的模型在三种不同的条件下进行了实验,以观察在不同条件下的性能改善。

实验在相同的环境中进行,以最小化实验产生的错误。实验使用了Intel Xeon Gold 5218R和6块Nvidia RTX A5000进行。在进行MobileViT的实验时,作者使用了先前工作中使用的相同超参数。使用了L2权重衰减为0.01的AdamW优化器。此外,应用了标签平滑交叉熵损失。模型使用了温暖的余弦学习率,这在MobileViT中使用,以增加训练过程中的学习率。学习率从0.0002开始,每3000次迭代增加0.002。然后,使用余弦调度程序将其降至0.0002。至于数据增强,只应用了基本的技术,包括随机调整大小的裁剪和水平翻转。
具有Shortcuts的模型表现出了最佳性能,在收敛速度比原始MobileViT更快的情况下,还实现了更高的准确性。值得注意的是,ExMobileViT-640表现出了高的收敛速度和性能,尽管其参数与输入到分类器的参数相同。此外,ExMobileViT-640的总参数略低于原始MobileViT(5.579M参数)。调整通道的ExMobileViT-640具有5.553M参数,小于具有5.579M参数的原始MobileViT。ExMobileViT-928在Top1准确性方面显示了与额外参数最高增加相比最高的改进。ExMobileViT-928具有5.5867M参数,仅比原始MobileViT模型增加了5%。
每个模型的收敛速度都急剧增加。根据原始MobileViT的论文,它曾经说过在300个epoch时达到了收敛。实验验证也显示出了类似的结果。在作者提出的模型中,ExShortcut允许轻松进行反向传播。这些特性减少了达到最高性能所需的计算成本。收敛速度与ExShortcut的数量成比例增加。一个明显的例子是,ExMobileViT-576模型,它的分类器输入通道减少了10%,其收敛速度也增加到了280个epoch。此外,通道扩展的ExMobileViT-928的收敛速度大幅提高到了260个epoch。
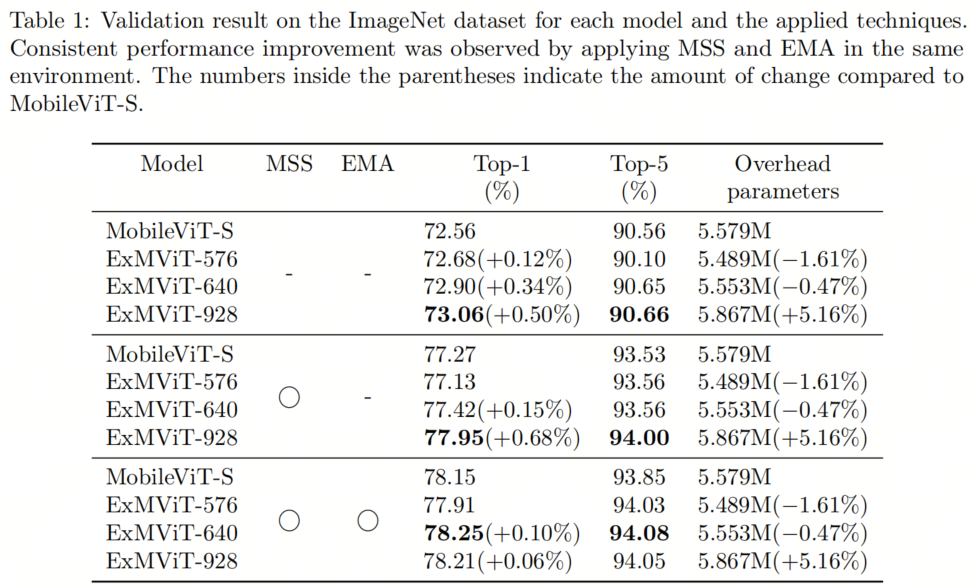
表1显示了MobileViT-S和作者提出的ExMobileViT系列之间的性能改进。每个模型的性能因所应用的各种技术而有所不同。令人惊讶的是,使用MSS导致性能提升最显著。在实验中,预计使用基本技巧将在准确性方面带来最大的提升。然而,实际上,使用多尺度采样器进行训练实现了最高的准确性。
随着对MobileViT(即模型更加优化)采用更具体的技巧,性能的提升显著减小。当同时使用MSS和EMA时,准确性差异仅为0.06%。使用基本技巧时,准确性差异变得更大。
3.2 对分类器通道的影响
基于使用MSS的ExMobileViT,作者研究了与输入通道相关的Top-1准确性变化。随着通道的增加,参数也与通道成比例地增加。为了找出基于Transformer的模型是否依赖于特定通道,通道比率以各种方式进行了更改。
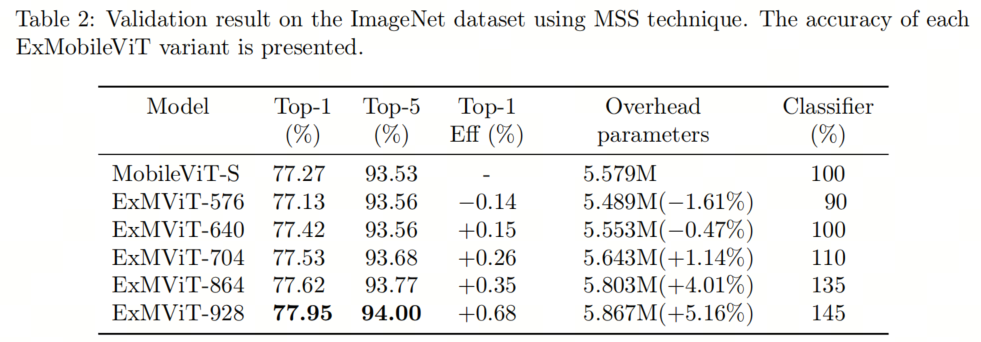
如表2所示,准确性与通道数量成比例增加。特别是,ExMobileViT-640尽管对于分类器具有相同的输入通道,但其性能提升显著。在MobileViT中,有640个通道输入最终块的分类器。在ExMobileViT-640中,分类器输入减少到480,并且通过从中间特征图的Shortcuts直接连接到分类器。该模型的性能提升表明,从中间特征图提取的数据与从最终块的输出的重要性一样关键。
3.3 与SENet的比较
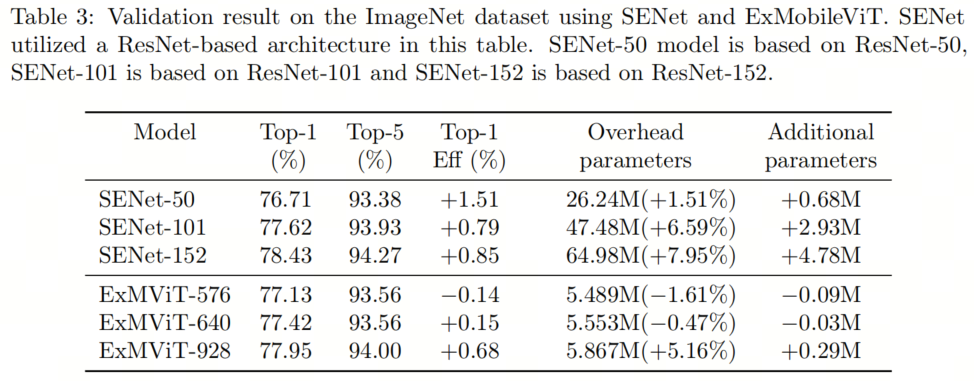
表3表示提高准确性所需的额外参数。ExMobileViT-928,扩展分类器通道,准确性提高了0.68%,模型增加了0.29百万个参数。与参数数量相比,作者提出的模型在Top-1准确性方面显著提高。扩展通道的ExMobileViT-928将ρ设置为D变换块的输入和输出通道之间的比率。
在轻量级模型中,额外的0.29M参数可能显得很重要。在改变模型的规模时,通常会按一定比例改变模型的通道大小。这意味着每个通道的比例会被统一调整。与特定的数值算法相比,基于比率的算法为模型提供了更大的灵活性。通过为一个模型进行优化,可以轻松地应用于该模型的多个版本。
4、参考
[1]. ExMobileViT: Lightweight Classifier Extension for Mobile Vision Transformer.
5、推荐阅读

LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN

大模型系列 | 两张3090显卡就可以玩起来医疗SAM-LST大模型
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香

点击上方卡片,关注「AI视界引擎」公众号