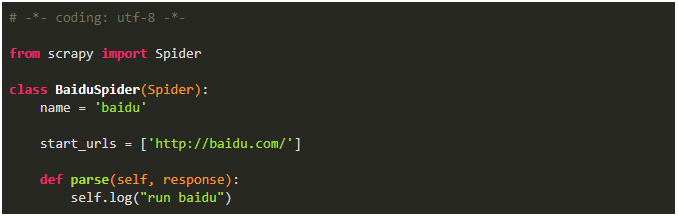
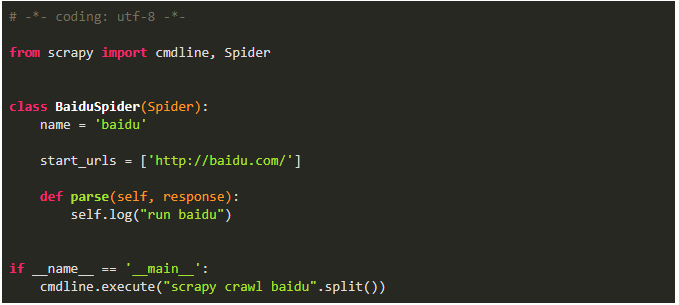
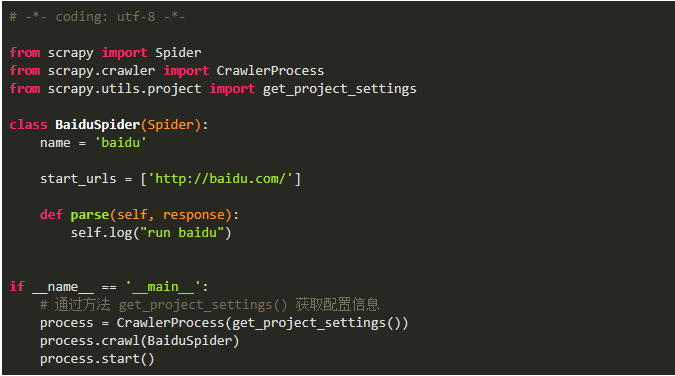
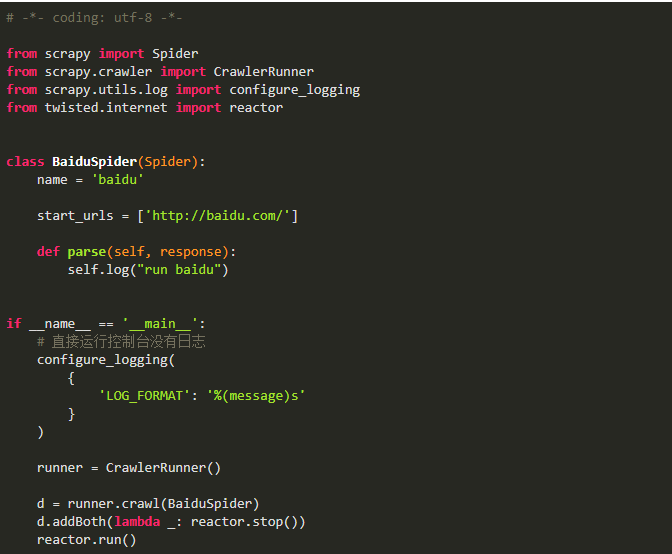
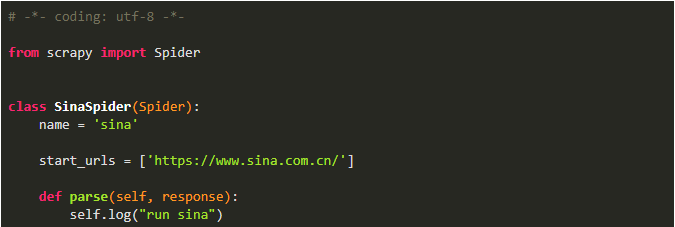
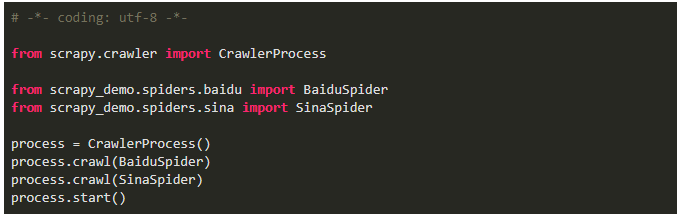
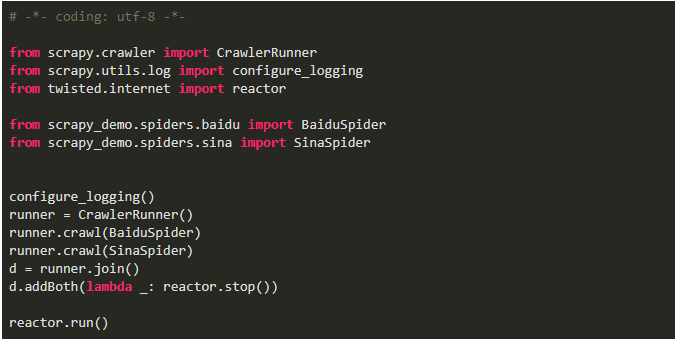
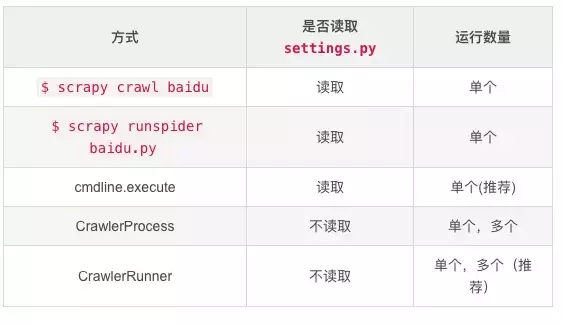
Python爬虫:Scrapy从脚本运行爬虫的5种方式!马哥Linux运维关注共 641字,需浏览 2分钟 ·2021-06-02 02:25 测试环境一、命令行运行爬虫1、编写爬虫文件 baidu.py2、运行爬虫(2种方式)二、文件中运行爬虫1、cmdline方式运行爬虫2、CrawlerProcess方式运行爬虫3、通过CrawlerRunner 运行爬虫三、文件中运行多个爬虫项目中新建一个爬虫 SinaSpider1、cmdline方式不可以运行多个爬虫如果将两个语句放在一起,第一个语句执行完后程序就退出了,执行到不到第二句不过有了以下两个方法来替代,就更优雅了2、CrawlerProcess方式运行多个爬虫备注:爬虫项目文件为:scrapy_demo/spiders/baidu.pyscrapy_demo/spiders/sina.py此方式运行,发现日志中中间件只启动了一次,而且发送请求基本是同时的,说明这两个爬虫运行不是独立的,可能会相互干扰3、通过CrawlerRunner 运行多个爬虫此方式也只加载一次中间件,不过是逐个运行的,会减少干扰,官方文档也推荐使用此方法来运行多个爬虫总结cmdline.execute 运行单个爬虫文件的配置最简单,一次配置,多次运行文章转载:Python编程学习圈(版权归原作者所有,侵删)点击下方“阅读原文”查看更多 浏览 117点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 Scrapyd运行 Scrapy 爬虫的守护进程Scrapyd是一个部署和运行Scrapy爬虫的应用,它允许使用HTTPJSONAPI部署Scrapy项目并控制其爬虫。手把手带你入门Python爬虫Scrapy大数据DT0Scrapy 爬虫框架的基本使用Python大数据分析0Python爬虫:一些常用的爬虫技巧总结恋习Python0送书 |《Python网络爬虫框架Scrapy从入门到精通》Python乱炖0Python爬虫学习教程:Python爬虫可以做什么?python教程0详解python的运行方式做一个柔情的程序猿0爬虫必备,案例对比 Requests、Selenium、Scrapy 爬虫库!菜鸟学Python0python爬虫接单本人精通python爬虫,如果需要,请联系Python爬虫的4种姿势裸睡的猪0点赞 评论 收藏 分享 手机扫一扫分享分享 举报





 下载APP
下载APP