
用 Python 做一个B站宅舞词云视频
朝朝暮暮里,祝愿我们每个人都能沉淀过往,迎来新光,
找到生生不息的热爱和梦想。
一、前言

B站上的漂亮的小姐姐真的好多好多,利用 you-get 大法下载了一个 B 站上跳舞的小姐姐视频,利用视频中的弹幕来制作一个漂亮小姐姐词云跳舞视频,一起来看看吧。
二、实现思路
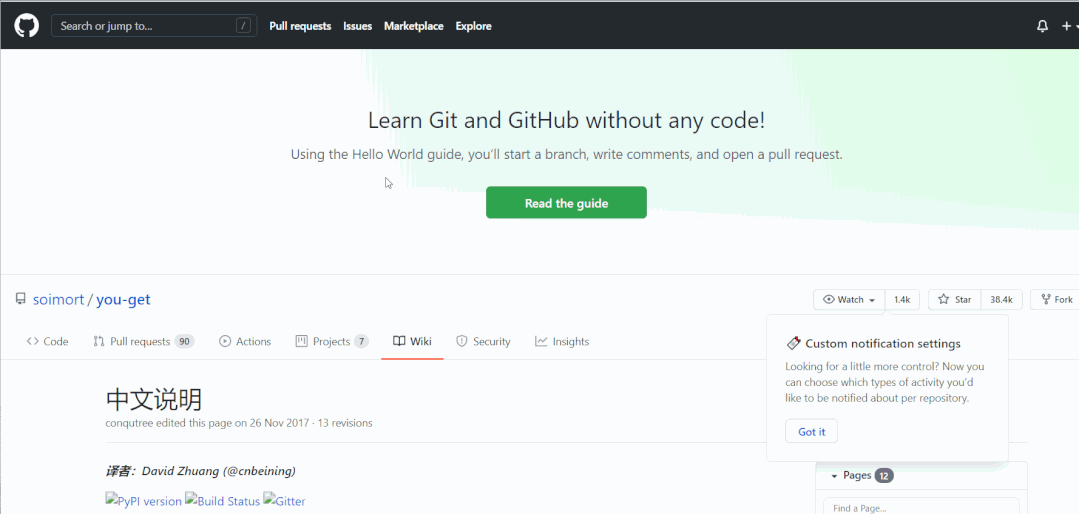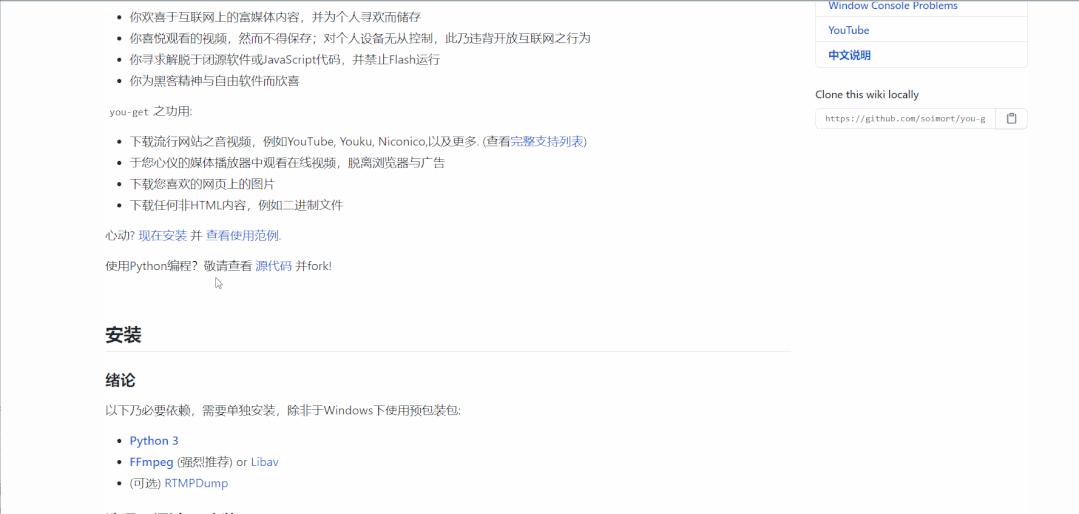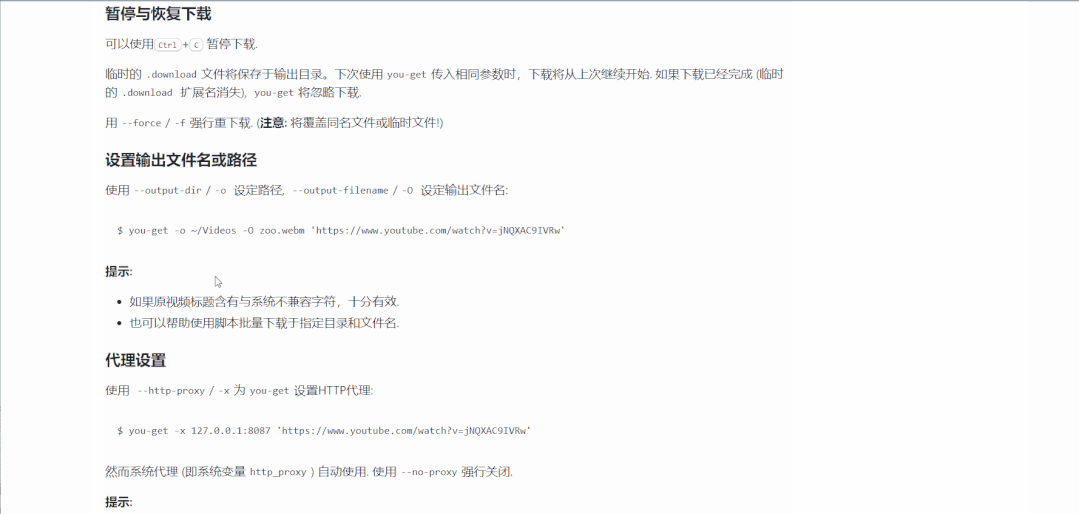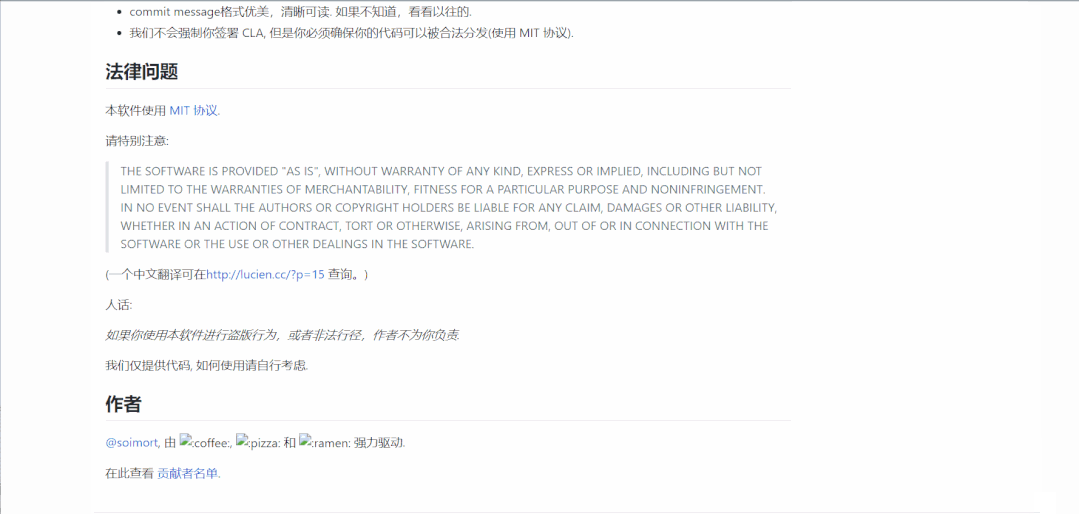
1. you-get下载视频
pip install you-get -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
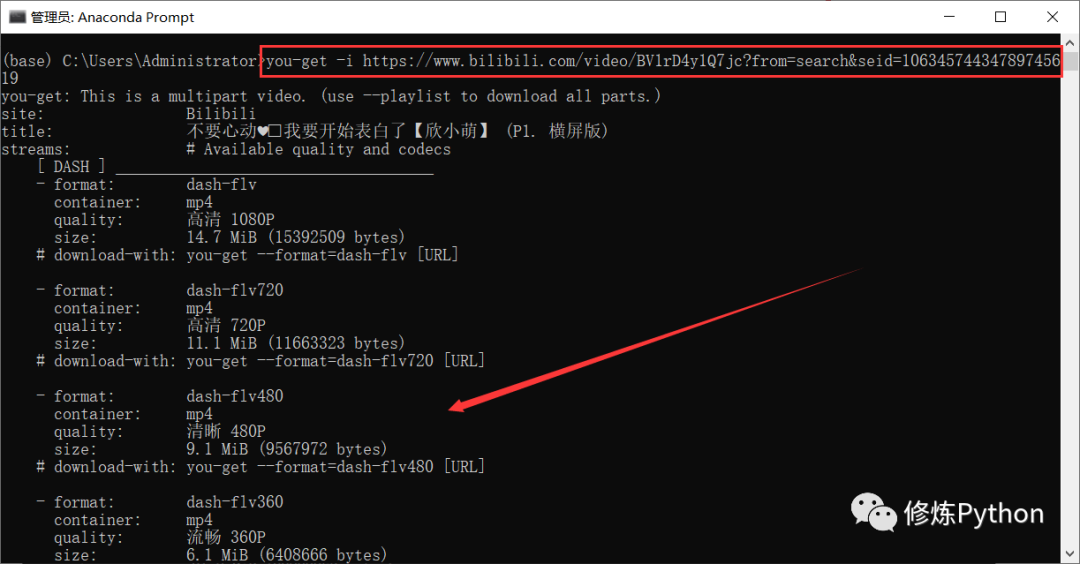
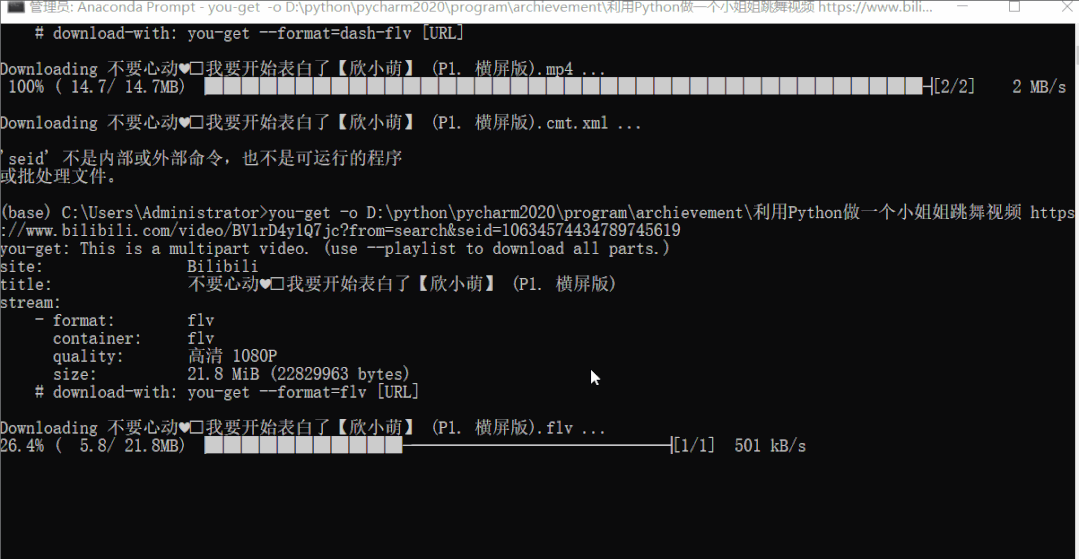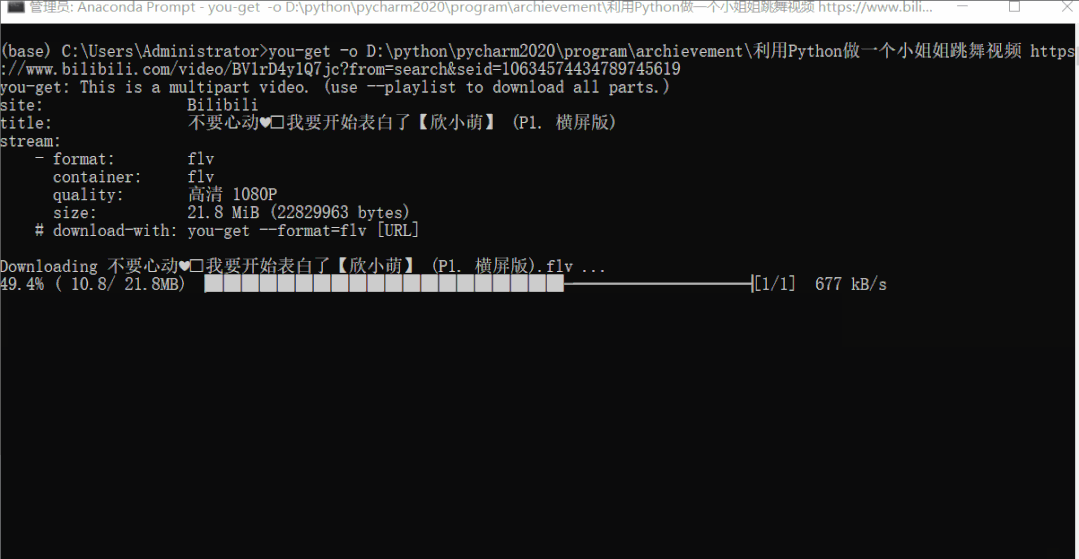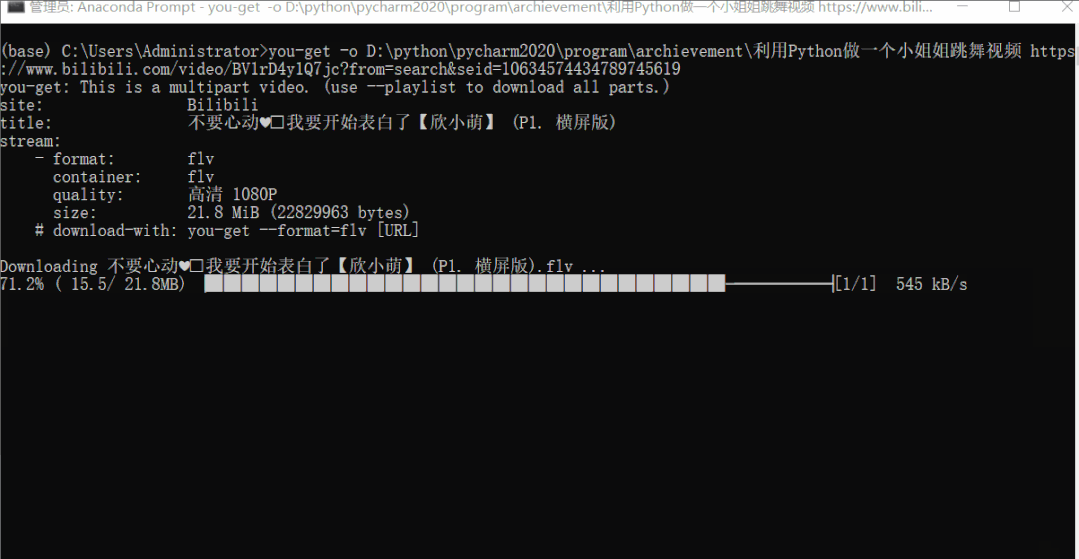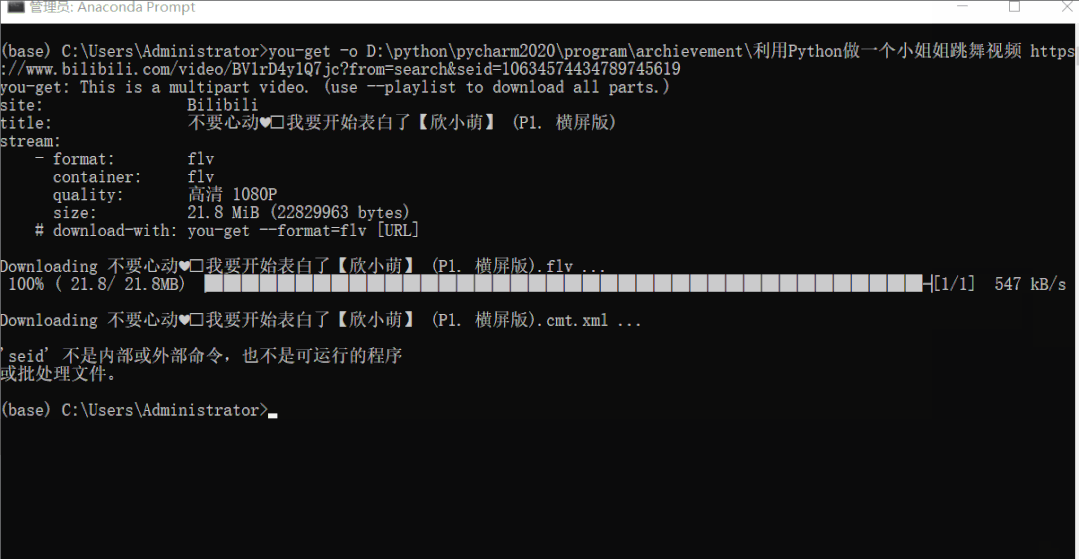
利用 you-get 下载 B 站视频到本地 视频链接:https://www.bilibili.com/video/BV1rD4y1Q7jc?from=search&seid=10634574434789745619
you-get -i https://www.bilibili.com/video/BV1rD4y1Q7jc?from=search&seid=10634574434789745619
you-get -o 本地保存路径 视频链接
更多 you-get 大法的详细使用,可以参考官方文档:
2. 爬取弹幕内容
写 python 爬虫,解析网页、提取弹幕数据保存到txt,注意构造 URL 参数和伪装请求头。
import requests
import pandas as pd
import re
import time
import random
from concurrent.futures import ThreadPoolExecutor
import datetime
from fake_useragent import UserAgent
# 随机产生请求头
ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
start_time = datetime.datetime.now()
爬取弹幕数据
def Grab_barrage(date):
# 伪装请求头
headers = {
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-site",
"accept-encoding": "gzip",
"origin": "https://www.bilibili.com",
"referer": "https://www.bilibili.com/video/BV1rD4y1Q7jc?from=search&seid=10634574434789745619",
"user-agent": ua.random,
"cookie": "_uuid=0EBFC9C8-19C3-66CC-4C2B-6A5D8003261093748infoc; buvid3=4169BA78-DEBD-44E2-9780-B790212CCE76155837infoc; sid=ae7q4ujj; rpdid=|(JJmlY|YukR0J'ulmumY~u~m; LIVE_BUVID=AUTO4315952457375679; CURRENT_QUALITY=80; blackside_state=1; CURRENT_FNVAL=80; PVID=1; fingerprint3=89f3acebeacc72a0a25afa9c05f6d87c; fingerprint=2c691e81ffde16dfbb39b8f6d20eb5f0; fingerprint_s=99dc5d2a438924de14f663d6a4cf9cc8; buivd_fp=4169BA78-DEBD-44E2-9780-B790212CCE76155837infoc; bp_video_offset_501048197=472333401972842834; buvid_fp=4169BA78-DEBD-44E2-9780-B790212CCE76155837infoc; buvid_fp_plain=0AE6F247-D84F-48C7-87A8-F8F35A578544184985infoc; bfe_id=1e33d9ad1cb29251013800c68af42315; DedeUserID=501048197; DedeUserID__ckMd5=1d04317f8f8f1021; SESSDATA=2ae431c2%2C1625306326%2Ca312a*11; bili_jct=d4edec1bd2ab84e0eb453adb3971b19a"
}
# 构造url访问 需要用到的参数 爬取指定日期的弹幕
params = {
'type': 1,
'oid': '206344228',
'date': date
}
# 发送请求 获取响应
response = requests.get(url, params=params, headers=headers)
# print(response.encoding) 重新设置编码
response.encoding = 'utf-8'
# print(response.text)
# 正则匹配提取数据 转成集合去除重复弹幕
comment = set(re.findall('(.*?)' , response.text))
# 将每条弹幕数据写入txt
with open('bullet.txt', 'a+') as f:
for con in comment:
f.write(con + '\n')
print(con)
time.sleep(random.randint(1, 3)) # 休眠
def main():
# 开多线程爬取 提高爬取效率
with ThreadPoolExecutor(max_workers=4) as executor:
executor.map(Grab_barrage, date_list)
# 计算所用时间
delta = (datetime.datetime.now() - start_time).total_seconds()
print(f'用时:{delta}s -----------> 弹幕数据成功保存到本地txt')
if __name__ == '__main__':
# 目标url
url = "https://api.bilibili.com/x/v2/dm/history"
start = '20201201'
end = '20210128'
# 生成时间序列
date_list = [x for x in pd.date_range(start, end).strftime('%Y-%m-%d')]
print(date_list)
count = 0
# 调用主函数
main()
结果如下: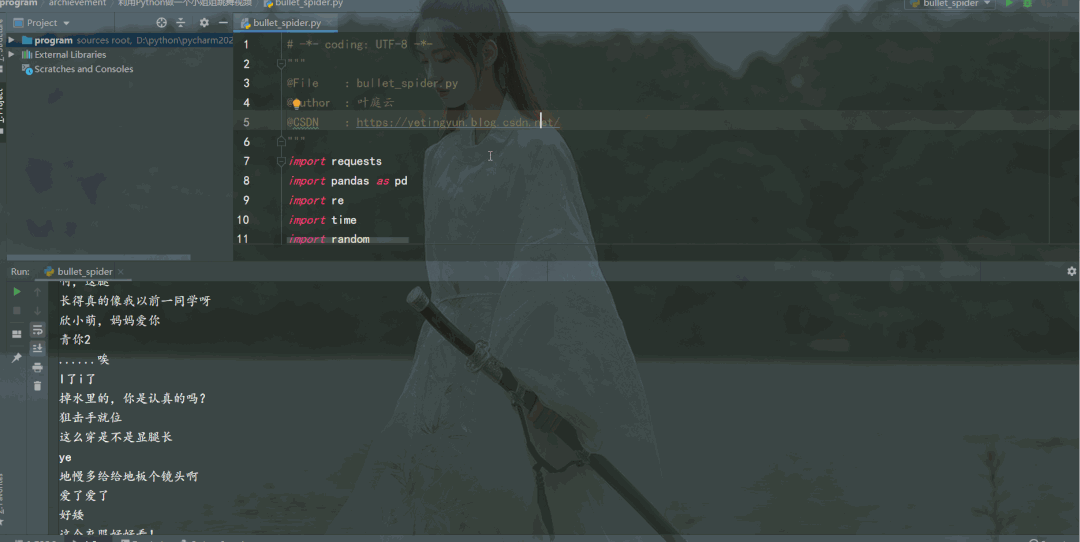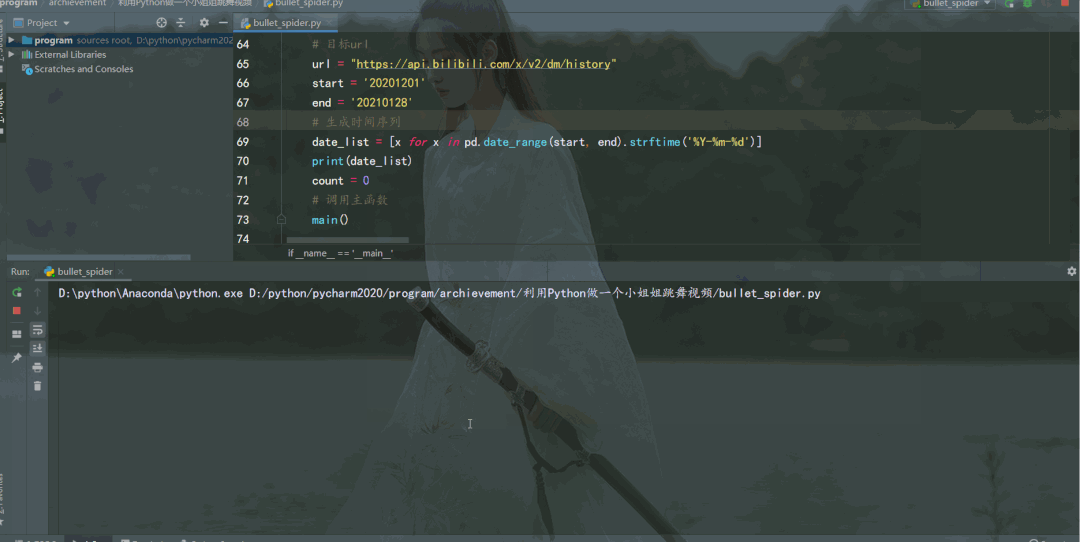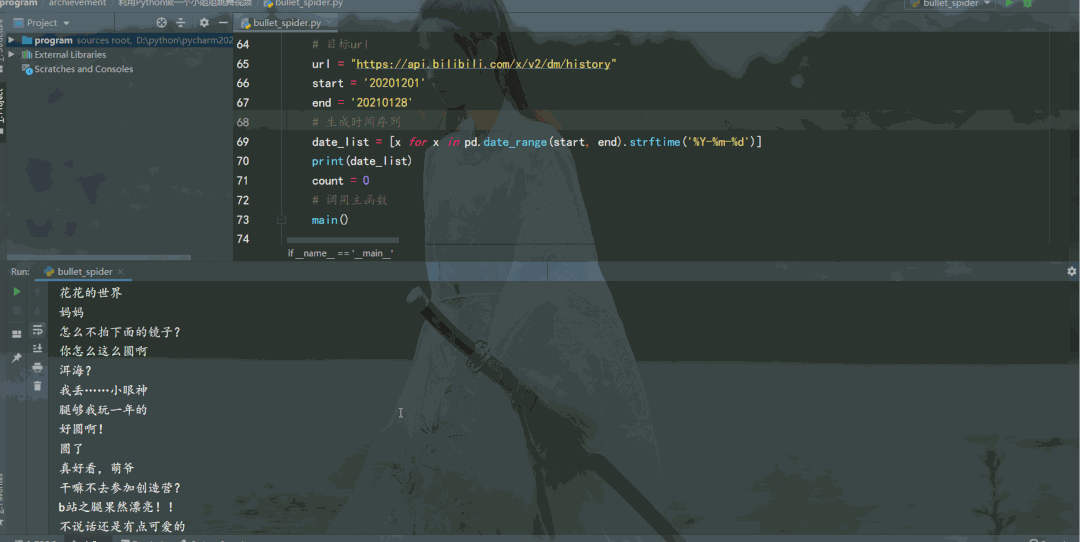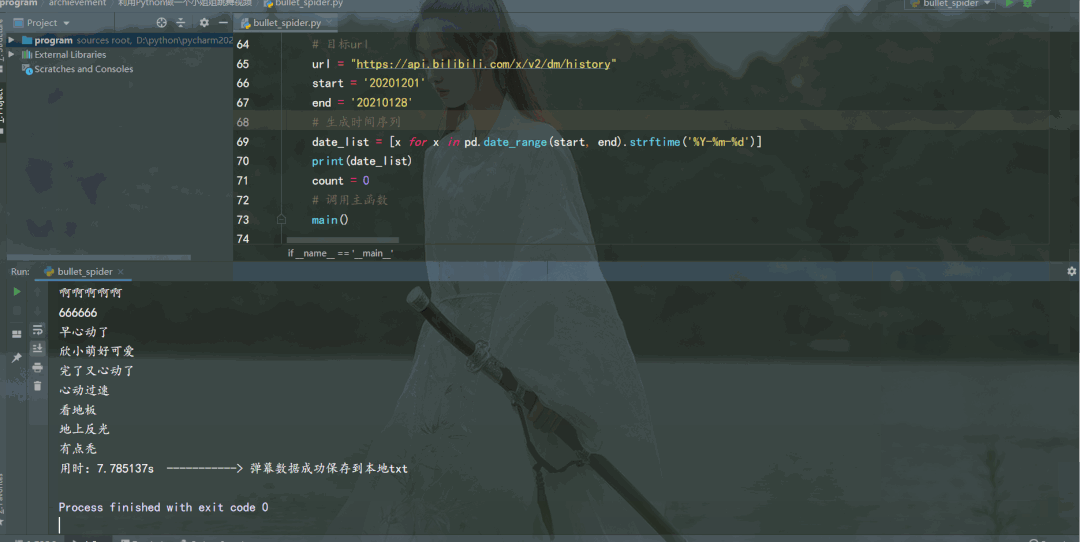

3. 从视频中提取图片
import cv2
# ============================ 视频处理 分割成一帧帧图片 =======================================
cap = cv2.VideoCapture(r"beauty.flv")
num = 1
while True:
# 逐帧读取视频 按顺序保存到本地文件夹
ret, frame = cap.read()
if ret:
if 88 <= num < 888:
cv2.imwrite(f"./pictures/img_{num}.jpg", frame) # 保存一帧帧的图片
print(f'========== 已成功保存第{num}张图片 ==========')
num += 1
else:
break
cap.release() # 释放资源
结果如下: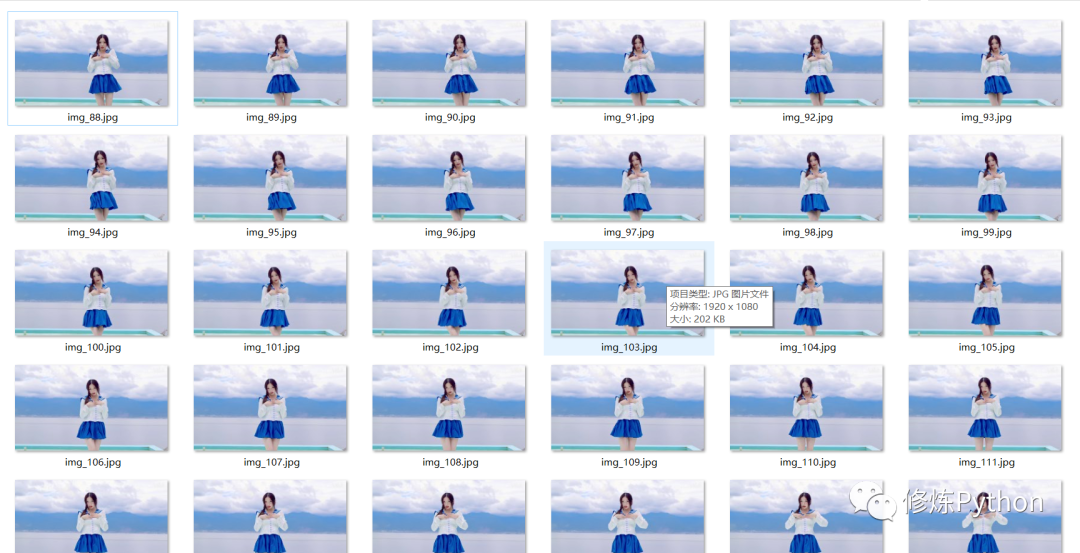
4. 利用百度AI进行人像分割
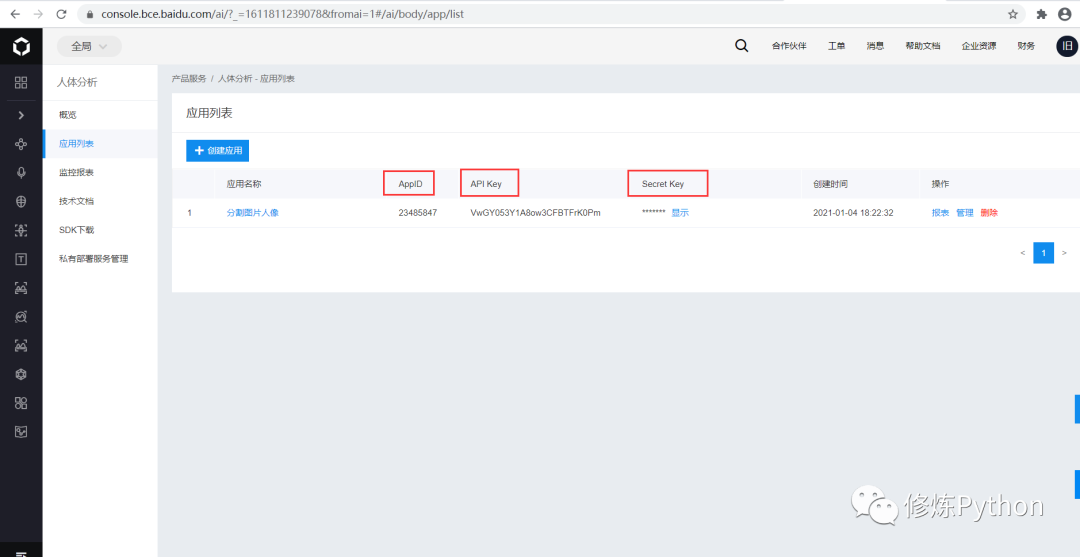 查看人像分割的Python SDK 文档,熟悉它的基本使用。
查看人像分割的Python SDK 文档,熟悉它的基本使用。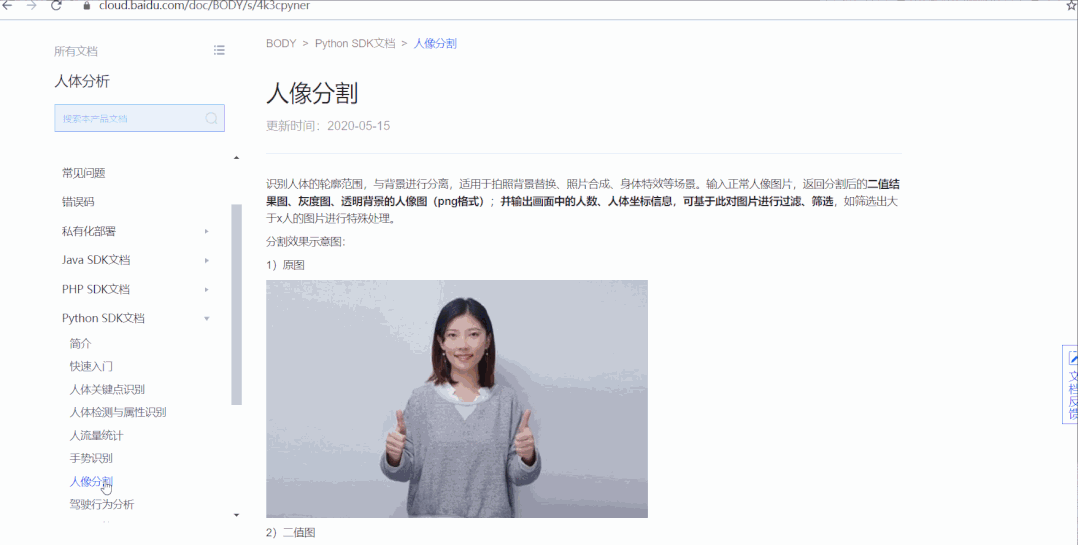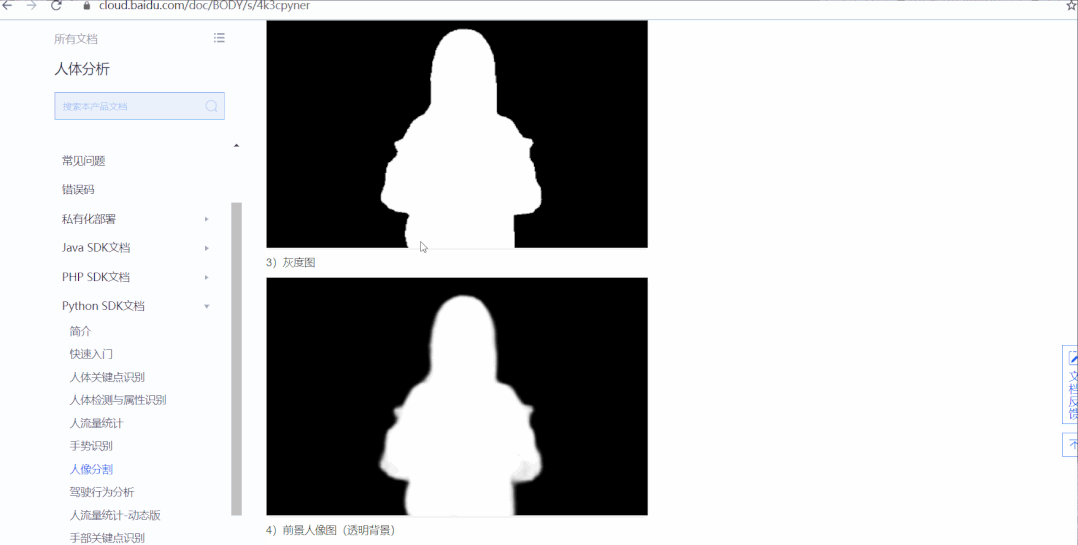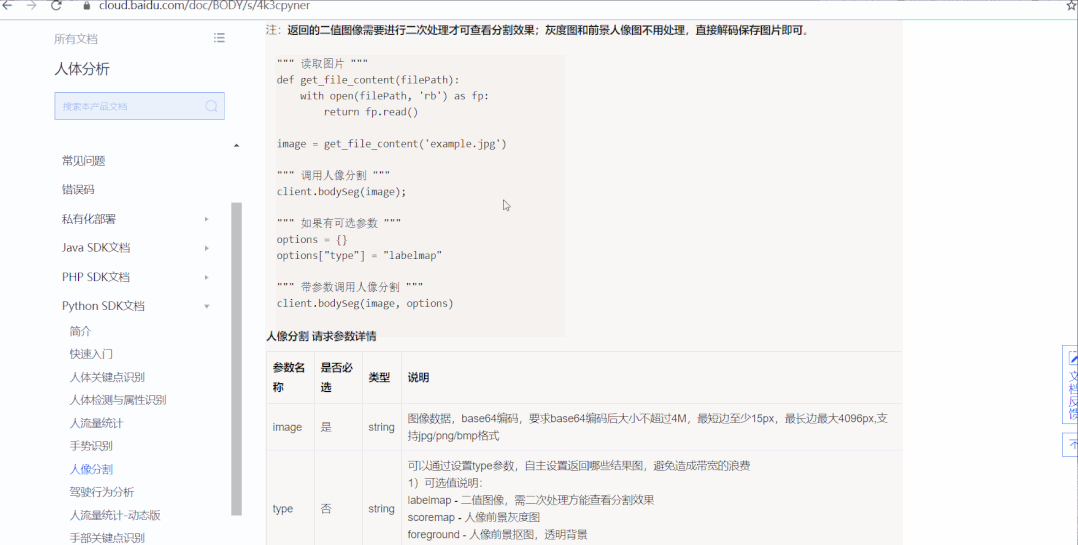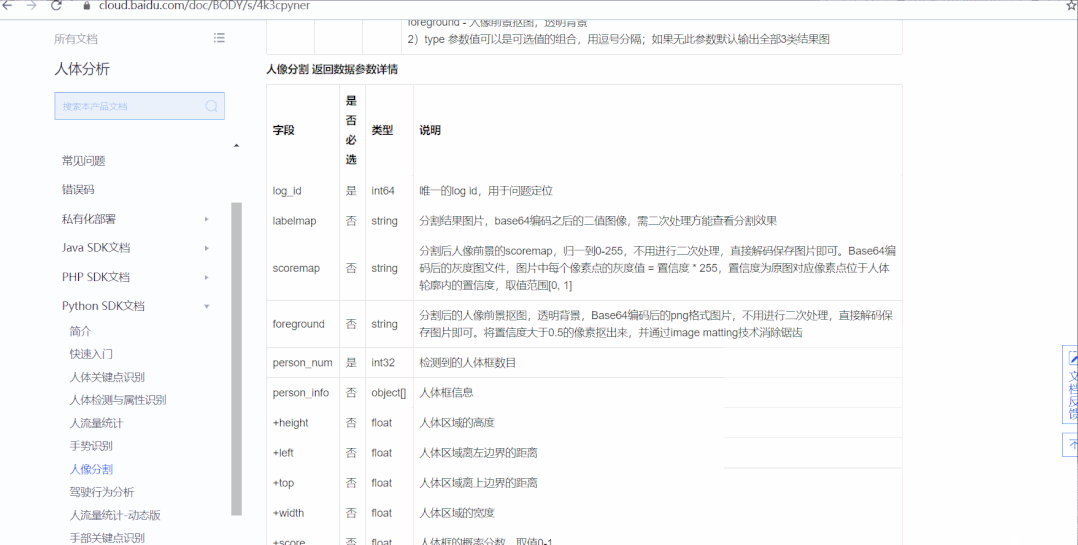
# -*- coding: UTF-8 -*-
"""
@File :人像分割.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
@百度AI :https://ai.baidu.com/tech/body/seg
"""
import cv2
import base64
import numpy as np
import os
from aip import AipBodyAnalysis
import time
import random
# 利用百度AI的人像分割服务 转化为二值图 有小姐姐身影的蒙版
# 百度云中已创建应用的 APP_ID API_KEY SECRET_KEY
APP_ID = '23485847'
API_KEY = 'VwGY053Y1A8ow3CFBTFrK0Pm'
SECRET_KEY = '**********************************'
client = AipBodyAnalysis(APP_ID, API_KEY, SECRET_KEY)
# 保存图像分割后的路径
path = './mask_img/'
# os.listdir 列出保存到图片名称
img_files = os.listdir('./pictures')
print(img_files)
for num in range(88, len(img_files) + 1):
# 按顺序构造出图片路径
img = f'./pictures/img_{num}.jpg'
img1 = cv2.imread(img)
height, width, _ = img1.shape
# print(height, width)
# 二进制方式读取图片
with open(img, 'rb') as fp:
img_info = fp.read()
# 设置只返回前景 也就是分割出来的人像
seg_res = client.bodySeg(img_info)
labelmap = base64.b64decode(seg_res['labelmap'])
nparr = np.frombuffer(labelmap, np.uint8)
labelimg = cv2.imdecode(nparr, 1)
labelimg = cv2.resize(labelimg, (width, height), interpolation=cv2.INTER_NEAREST)
new_img = np.where(labelimg == 1, 255, labelimg)
mask_name = path + 'mask_{}.png'.format(num)
# 保存分割出来的人像
cv2.imwrite(mask_name, new_img)
print(f'======== 第{num}张图像分割完成 ========')
time.sleep(random.randint(1,2))

5. 小姐姐跳舞词云生成
# -*- coding: UTF-8 -*-
"""
@File :词云.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
from wordcloud import WordCloud
import collections
import jieba
import re
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
# 读取数据
with open('bullet.txt') as f:
data = f.read()
# 文本预处理 去除一些无用的字符 只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = "/".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data, cut_all=True)
result_list = []
with open('stop_words.txt', encoding='utf-8') as f:
con = f.read().split('\n')
stop_words = set()
for i in con:
stop_words.add(i)
for word in seg_list_exact:
# 设置停用词并去除单个词
if word not in stop_words and len(word) > 1:
result_list.append(word)
# 筛选后统计词频
word_counts = collections.Counter(result_list)
path = './wordcloud/'
for num in range(88, 888):
img = f'./mask_img/mask_{num}'
# 获取蒙版图片
mask_ = 255 - np.array(Image.open(img))
# 绘制词云
plt.figure(figsize=(8, 5), dpi=200)
my_cloud = WordCloud(
background_color='black', # 设置背景颜色 默认是black
mask=mask_, # 自定义蒙版
mode='RGBA',
max_words=500,
font_path='simhei.ttf', # 设置字体 显示中文
).generate_from_frequencies(word_counts)
# 显示生成的词云图片
plt.imshow(my_cloud)
# 显示设置词云图中无坐标轴
plt.axis('off')
word_cloud_name = path + 'wordcloud_{}.png'.format(num)
my_cloud.to_file(word_cloud_name) # 保存词云图片
print(f'======== 第{num}张词云图生成 ========')
结果如下:

6. 合成跳舞视频
# -*- coding: UTF-8 -*-
"""
@File :生成视频.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import cv2
import os
# 输出视频的保存路径
video_dir = 'result.mp4'
# 帧率
fps = 30
# 图片尺寸
img_size = (1920, 1080)
fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', 'V') # opencv3.0 mp4会有警告但可以播放
videoWriter = cv2.VideoWriter(video_dir, fourcc, fps, img_size)
img_files = os.listdir('./wordcloud')
for i in range(88, 888):
img_path = './wordcloud/' + 'wordcloud_{}.png'.format(i)
frame = cv2.imread(img_path)
frame = cv2.resize(frame, img_size) # 生成视频 图片尺寸和设定尺寸相同
videoWriter.write(frame) # 写进视频里
print(f'======== 按照视频顺序第{i}张图片合进视频 ========')
videoWriter.release() # 释放资源
效果如下: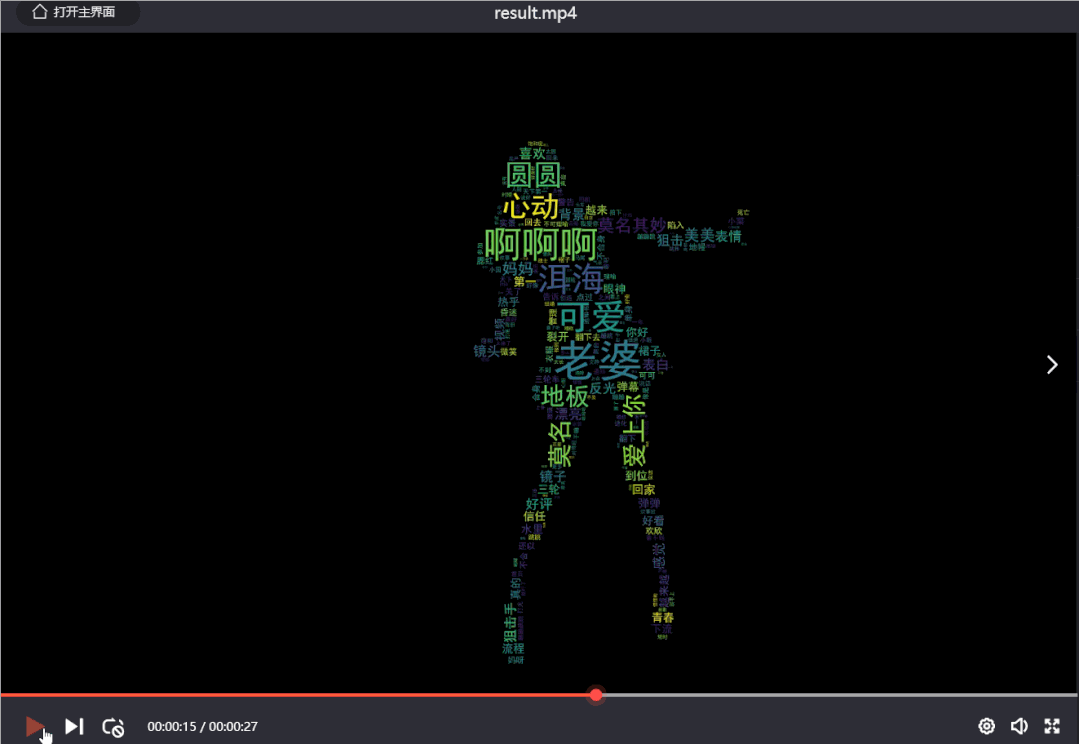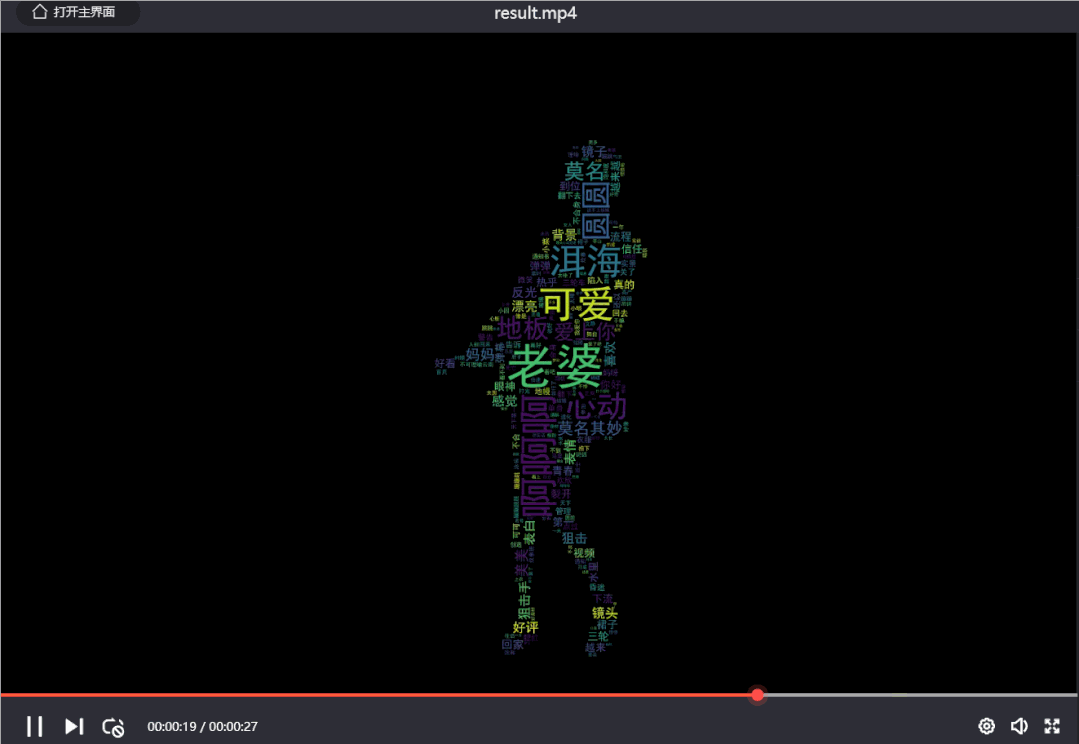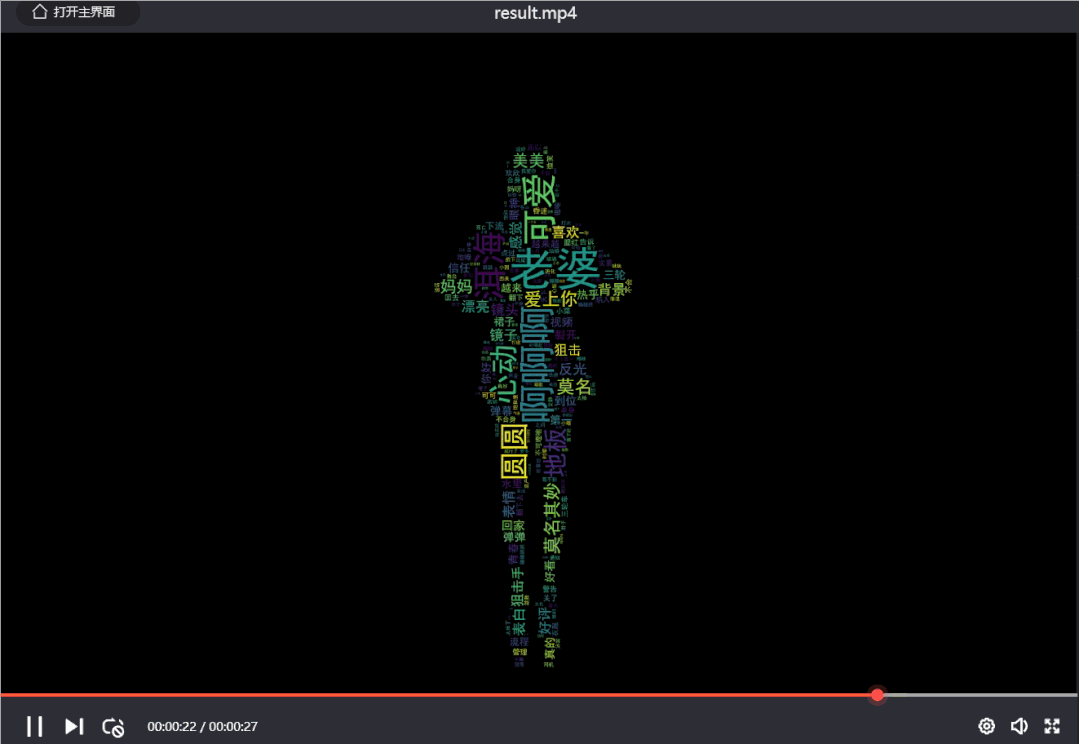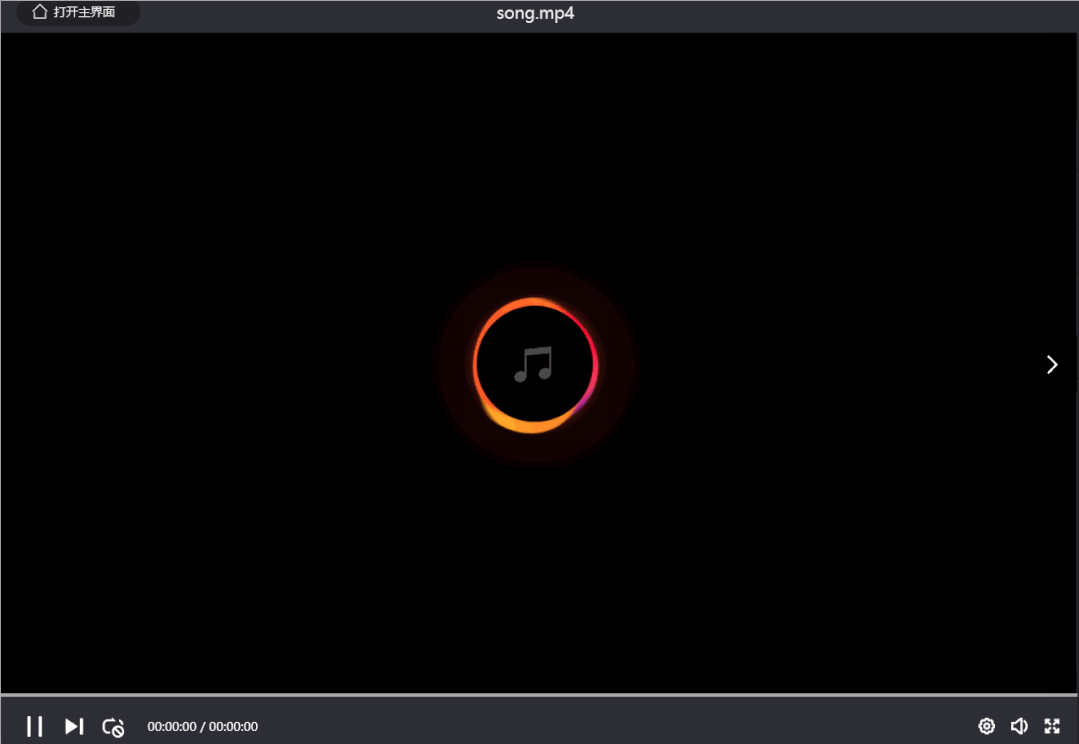
7. 视频插入音频
漂亮小姐姐跳舞那么好看,再加上自己喜欢的背景音乐,岂不美哉。
# -*- coding: UTF-8 -*-
"""
@File :插入音频.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import moviepy.editor as mpy
# 读取词云视频
my_clip = mpy.VideoFileClip('result.mp4')
# 截取背景音乐
audio_background = mpy.AudioFileClip('song.mp4').subclip(17, 44)
audio_background.write_audiofile('vmt.mp3')
# 视频中插入音频
final_clip = my_clip.set_audio(audio_background)
# 保存为最终的视频 动听的音乐!漂亮小姐姐词云跳舞视频!
final_clip.write_videofile('final_video.mp4')
作者:叶庭云
CSDN:https://yetingyun.blog.csdn.net/本文仅用于交流学习,未经作者允许,禁止转载,更勿做其他用途,违者必究。
热爱可抵岁月漫长,发现求知的乐趣,在不断总结和学习中进步,与诸君共勉。
更多阅读
特别推荐

点击下方阅读原文加入社区会员
评论