
从输入 URL 到页面加载完成的过程中都发生了什么事情?
日期 : 2021年01月14日
正文共 :13095字


第一个问题:从输入 URL 到浏览器接收的过程中发生了什么事情?
从触屏到 CPU
CPU 内部的处理
移动设备中的 CPU 并不是一个单独的芯片,而是和 GPU 等芯片集成在一起,被称为 SoC(片上系统)。

从 CPU 到操作系统内核
/proc/interrupts 文件来查看系统中所有设备的中断请求号,以下是 Nexus 7 (2013) 的部分结果:shell@flo:/ $ cat /proc/interrupts
CPU0
17: 0 GIC dg_timer
294: 1973609 msmgpio elan-ktf3k
314: 679 msmgpio KEY_POWER
/dev/input/event0 这个设备文件中,比如下面展示了一次触摸事件所产生的信息:130|shell@flo:/ $ getevent -lt /dev/input/event0
[ 414624.658986] EV_ABS ABS_MT_TRACKING_ID 0000835c
[ 414624.659017] EV_ABS ABS_MT_TOUCH_MAJOR 0000000b
[ 414624.659047] EV_ABS ABS_MT_PRESSURE 0000001d
[ 414624.659047] EV_ABS ABS_MT_POSITION_X 000003f0
[ 414624.659078] EV_ABS ABS_MT_POSITION_Y 00000588
[ 414624.659078] EV_SYN SYN_REPORT 00000000
[ 414624.699239] EV_ABS ABS_MT_TRACKING_ID ffffffff
[ 414624.699270] EV_SYN SYN_REPORT 00000000
从操作系统 GUI 到浏览器
/dev/input/event0 文件的变化就能知道用户进行了哪些触摸操作,不过如果每个程序都这么做实在太麻烦了,所以在图像操作系统中都会包含 GUI 框架来方便应用程序开发,比如 Linux 下著名的 X。/dev/input/ 目录下的文件,然后将这些信息传递到 Android 的窗口管理服务(WindowManagerService)中,它会根据位置信息来查找相应的 app,然后调用其中的监听函数(如 onTouch 等)。扩展学习
《计算机体系结构》
《计算机体系结构:量化研究方法》
《计算机组成与设计:硬件/软件接口》
《编码》
《CPU自制入门》
《操作系统概念》
《ARMv7-AR 体系结构参考手册》
《Linux内核设计与实现》
《精通Linux设备驱动程序开发》
第二个问题:浏览器如何向网卡发送数据?
从浏览器到浏览器内核
需要注意浏览器和浏览器内核是不同的概念,浏览器指的是 Chrome、Firefox,而浏览器内核则是 Blink、Gecko,浏览器内核只负责渲染,GUI 及网络连接等跨平台工作则是浏览器实现的
HTTP 请求的发送
DNS 查询
dig +trace fex.baidu.com命令得到的结果(省略了一些):; <<>> DiG 9.8.3-P1 <<>> +trace fex.baidu.com
;; global options: +cmd
. 11157 IN NS g.root-servers.net.
. 11157 IN NS i.root-servers.net.
. 11157 IN NS j.root-servers.net.
. 11157 IN NS a.root-servers.net.
. 11157 IN NS l.root-servers.net.
;; Received 228 bytes from 8.8.8.8#53(8.8.8.8) in 220 ms
com. 172800 IN NS a.gtld-servers.net.
com. 172800 IN NS c.gtld-servers.net.
com. 172800 IN NS m.gtld-servers.net.
com. 172800 IN NS h.gtld-servers.net.
com. 172800 IN NS e.gtld-servers.net.
;; Received 503 bytes from 192.36.148.17#53(192.36.148.17) in 185 ms
baidu.com. 172800 IN NS dns.baidu.com.
baidu.com. 172800 IN NS ns2.baidu.com.
baidu.com. 172800 IN NS ns3.baidu.com.
baidu.com. 172800 IN NS ns4.baidu.com.
baidu.com. 172800 IN NS ns7.baidu.com.
;; Received 201 bytes from 192.48.79.30#53(192.48.79.30) in 1237 ms
fex.baidu.com. 7200 IN CNAME fexteam.duapp.com.
fexteam.duapp.com. 300 IN CNAME duapp.n.shifen.com.
n.shifen.com. 86400 IN NS ns1.n.shifen.com.
n.shifen.com. 86400 IN NS ns4.n.shifen.com.
n.shifen.com. 86400 IN NS ns2.n.shifen.com.
n.shifen.com. 86400 IN NS ns5.n.shifen.com.
n.shifen.com. 86400 IN NS ns3.n.shifen.com.
;; Received 258 bytes from 61.135.165.235#53(61.135.165.235) in 2 ms
这里为了方便描述,忽略了很多不同的情况,比如 127.0.0.1 其实走的是 loopback,和网卡设备没关系;比如 Chrome 会在浏览器启动的时预先查询 10 个你有可能访问的域名;还有 Hosts 文件、缓存时间 TTL(Time to live)的影响等。
通过 Socket 发送数据
chrome://net-internals/#spdy 页面来发现。浏览器对同一个域名有连接数限制,大部分是 6,我以前认为将这个连接数改大后会提升性能,但实际上并不是这样的,Chrome 团队有做过实验,发现从 6 改成 10 后性能反而下降了,造成这个现象的因素有很多,如建立连接的开销、拥塞控制等问题,而像 SPDY、HTTP 2.0 协议尽管只使用一个 TCP 连接来传输数据,但性能反而更好,而且还能实现请求优先级。
Socket 在内核中的实现
底层网络协议的具体例子
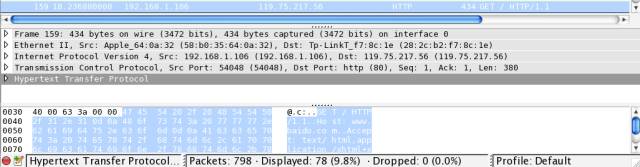
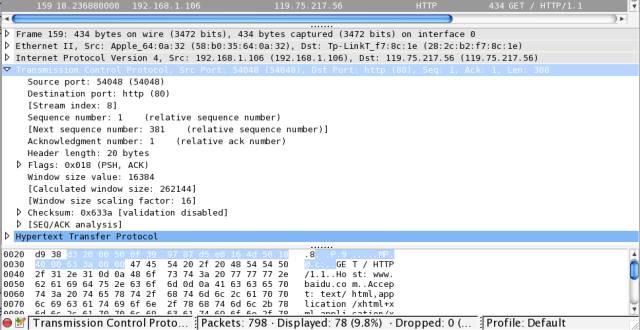
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Port | Destination Port |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Acknowledgment Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Data | |U|A|E|R|S|F| |
| Offset| Reserved |R|C|O|S|Y|I| Window |
| | |G|K|L|T|N|N| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Checksum | Urgent Pointer |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options | Padding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| data |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
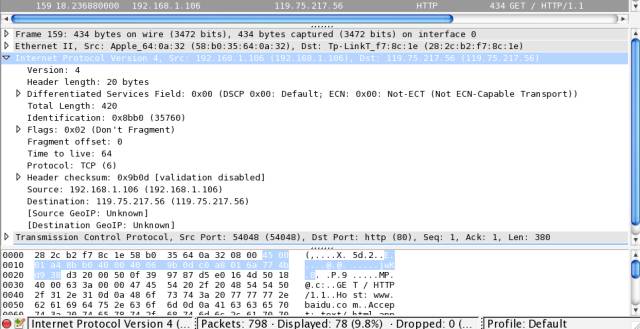
192.168.1.106,目标(Destination) IP 为 119.75.217.56,因此 IP 协议最重要的作用就是确定 IP 地址。192.168.1.1,但到公司就变成 172.22.22.22 了,所以在底层通信时需要使用一个固定的地址,这就是 MAC(media access control) 地址,每个网卡出厂时的 MAC 地址都是固定且唯一的。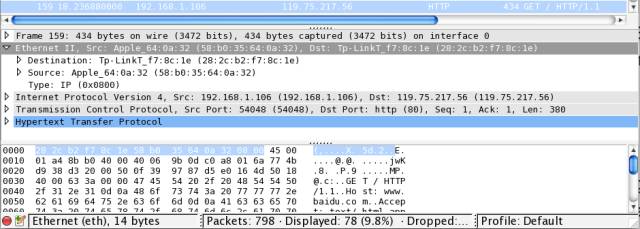
扩展学习
《计算机网络:自顶向下方法与Internet特色》
《计算机网络》
《Web性能权威指南》
第三个问题:数据如何从本机网卡发送到服务器?
从内核到网络适配器(Network Interface Card)
连接 Wi-Fi 路由
而同样基于无线电原理的 2G/3G/LTE 也会遇到类似的问题,但它并没有采用 Wi-Fi 那样的独占方案,而是通过频分(FDMA)、时分(TDMA)和码分(CDMA)来进行复用,具体细节这里就不展开了。
192.168.1.x 这样的内网地址,外网无法直接向这个地址发送数据,所以网络数据在经过路由时,路由会修改相关地址和端口,这个操作称为 NAT 映射。运营商网络内的路由
主干网间的传输
IDC 内网
这里的带宽成本很高,是按照峰值来结算的,以每月每 Gbps(注意这里指的是 bit,而不是 Byte)为单位,北京这边价格在十万人民币以上,一般网站使用 1G 到 10G 不等。
需要注意的是,一般网络书中提到的交换机都只具备二层(MAC 协议)的功能,但在 IDC 中的交换器基本上都具备三层(IP 协议)的功能,所以不需要有专门的路由了。
服务器 CPU
扩展学习
The Datacenter as a Computer
Open Computer
《软件定义网络》
《大话无线通信》
第四个问题:服务器接收到数据后会进行哪些处理?
负载均衡
进行很多统一处理,比如防攻击策略、防抓取、SSL、gzip、自动性能优化等
应用层的分流策略都能在这里做,比如对 /xx 路径的请求分到 a 服务器,对 /yy 路径的请求分到 b 服务器,或者按照 cookie 进行小流量测试等
缓存,并在后端服务挂掉的时候显示友好的 404 页面
监控后端服务是否异常
⋯⋯
Web Server 中的处理
进入后端语言
Web 框架(Framework)
读取数据
扩展学习
《深入理解Nginx》
《Python源码剖析》
《深入理解Java虚拟机》
《数据库系统实现》
第五个问题:服务器返回数据后浏览器如何处理?
从 01 到字符
用户设置,在浏览器中可以指定页面编码
HTTP 协议中
中的 charset 属性值对于 JS 和 CSS
对于 iframe
外链资源的加载
JavaScript 的执行
从字符到图片
跨平台 2D 绘制库
GPU 合成
扩展学习
Chromium
Mozilla Hacks
Surfin’ Safari
第六个问题:浏览器如何将页面展现出来?
Framebuffer
/dev/fb0 文件中,这个文件实际上一个内存区域的映射,这段内存区域称为 Framebuffer。从内存到 LCD
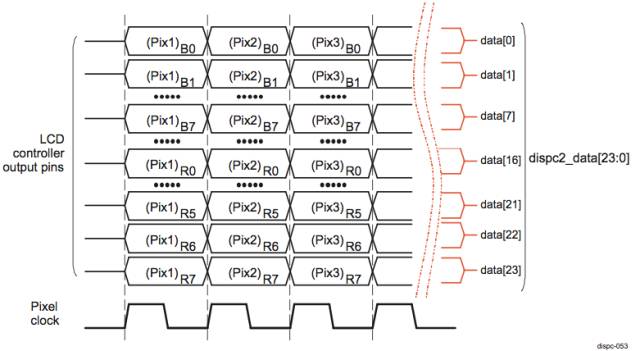
LCD 显示

另外直接使用三种颜色的 LED 也是可行的,它能避免了滤光导致的光子浪费,降低耗电,很适用于智能手表这样的小屏幕,Apple 收购的 LuxVue 公司就采用的是这种方式,感兴趣的话可以去研究它的专利

并不是所有显示器的亮度都能达到 256,在选择显示器时有个参数是 8-Bit 或 6-Bit 面板,其中 8-Bit 的面板能在物理上达到 256 种亮度,而 6-Bit 的则只有 64 种,它需要靠刷新率控制(Frame rate control)技术来达到 256 的效果。
扩展学习
《Computer Graphics, 3rd Edition : Principles and Practices》
《交互式计算机图形学》
本文所忽略的内容
内存相关
堆,这里的分配策略有很多,比如 malloc 的实现
栈,函数调用,已经有很多优秀的文章或书籍介绍了
内存映射,动态库加载等
队列几乎无处不在,但这些细节和原理没太大关系
各种缓存
CPU 的缓存、操作系统的缓存、HTTP 缓存、后端缓存等等
各种监控
很多日志会保存下来以便后续分析
FAQ
大家的讨论
最后
— THE END —
