
数据清洗(data cleaning)的重要性
转自公众号:ArisQ

之前经常和临床试验数据打交道,无论是来自手动录入的数据还是取自数据库的数据,在完成数据获取这一步后,感觉有80%甚至90%的时间和精力会用在做数据清洗(data cleaning)这一环节,即“增”“删”“查”“改”,通过data cleaning要让我们的数据成为可以进入模型的状态,也是就是清洁的数据(tidy data/clean data),过不了这一关,后面的建模就无法实现。
随着网络资源的丰富,很多时候即使没有精通的数据分析或者统计学基础,通过很多网上的step by step的教程或帮助手册文档,使得即使是新手也可以通过编程软件如SAS、R来实现很多高级模型的构建,我也经常会在国内外论坛或者微信公众号上学习这些教程。但是你要知道“几行代码实现XXX”的前提,也就是把一个“脏”数据变成能够在“几行代码”中直接跑出结果的过程可能需要几十行几百行代码进行清洗。通常情况这些教程是不会说明所用的“干净数据”是如何获取的,而且我们并不是FDA,收到的数据也不会像药企提交给FDA的SDTM (Study Data Tabulation Model) & ADaM (Analysis Data Model)那样规范[1],没有清洁的数据,盲目套用别人的code只会得到各种errors。
俗话说心急吃不了热豆腐,如果真的希望能够在数据分析上进一步提高水平,data cleaning是一项基本功并且无论怎样强调也不为过。数据清洗有很多专著(比如后面提到的Cody's book)[2],不同的软件也有不同的语法规则,这篇文章并不探讨具体的方法,旨在引起大家包括提醒我自己对这项基本功的重视。
先了解一下什么是数据清洗。根据Ron Cody在他的《Cody's Data Cleaning Techniques Using SAS》中的定义是:
确保原始数据的准确输入
检查字符型变量仅包含有效值
检查数值型变量在预定范围内
检查是否存在缺失数据
检查并删除重复数据
检查特殊值是否唯一,如患者编号
检查是否存在无效数据
检查每一个文件内的ID编号
确保是否遵循复杂多文件规则
举个例子,当我获得一个包含几百名临床患者的数据集时,一眼看过去,我的电脑屏幕应该是既看不见屏幕的右边还有什么(因为变量太多,或者说列太多),又看不见屏幕下面还有什么(因为观测太多,或者说行太多),比如下面这个样子的:
 图1
图1这个时候,我应该做什么?拉一拉屏幕看看屏幕有什么,屏幕下面有什么吗?可以,但如果你是个数据分析老手,你会知道这并不重要,而且也没有什么用。如果数据量很大的时候,拖动屏幕去看看下面的几万行观测除了让你觉得卡顿之外,也不太可能一眼就看出什么有效的信息,所以没有任何意义。
粗略的来划分变量类型,通常可以分成字符型和数值型组成。还是拿上面的这个例子来说,这个数据集里的group(组别),gender(性别)都是典型的字符型变量,像age(年龄)就是典型的数值型了。那么数据清洗的可以检查字符型和数值型变量的值,是否在合理的区间(比如年龄的范围),是否存在缺失,是否存在异常(比如性别、年龄),患者编号是否存在重复。这一步有的人可能会说这难道不就是统计描述么?没错,这一步本质就是统计描述,这一步可以得到频数表、最大值、最小值、均数、中位数等信息。但数据清洗并没有这么简单,到这里我们通过统计描述只能说看看数据“脏不脏”,如果“脏”,那后面还有的是工作需要去做。但如果“干净”,也不要高兴太早,干净的数据也不见得直接就能拿来用。
还是用上面这个例子,这样的一个数据集,可能需要拆分,可能需要合并(比如双录,即两个研究人员同时录入一批数据,减少单人录入出现的失误),才能够满足后面的数据分析要求。现在我要基线(baseline)的数据,那么需要从刚才的数据集中提取visit=0的观测。这样的话,后面我所有与基线有关的数据分析都在这个新的数据集中操作即可,可以减少对原始数据集的影响,以免一些误操作而引起的麻烦。
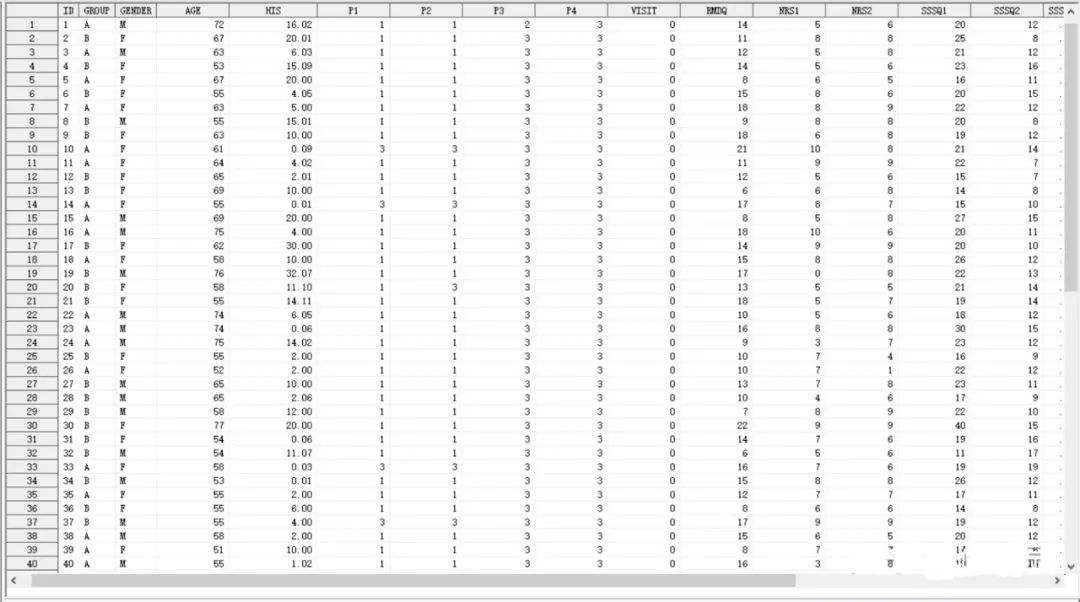 图2
图2
另外有时需要对数据进行转置(transpose),因为有些时候需要特定的数据格式才能进行下一步的数据分析,比如宽数据转长数据,或者长数据转宽数据。比如图1就是一个典型的长数据格式,因为“visit”这个变量被压缩到了一个变量之中,所以每一个ID不仅只有一行观测,而是有9行之多。图3就是对图1中的变量“RMDQ”进行转置之后的结果。可能你会问,为什么要转置RMDQ的这一列数据呢?因为“RMDQ”中存在缺失值(missing data),后面会通过多重填补(multiple imputation)方法进行缺失值的处理,需将数据变换为宽数据格式时才可以。
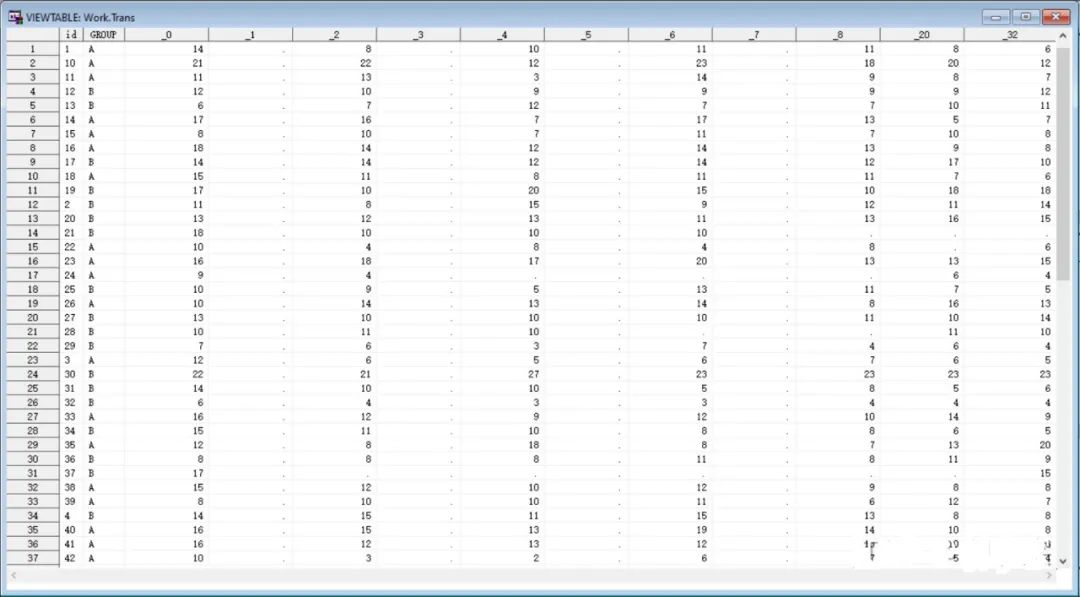 图3
图3
总结一下数据清洗具体包含的操作除了检查变量是否有效、是否在合理范围内,还包括拼接、抽提、拆分、观测和变量的筛选、变量类型转换、行列转置、新变量生成、赋值、缺失数据填补等等只要是为进一步数据分析做准备的工作都可以看做是数据清洗。
数据清洗是数据分析的前提,也会花费较多的时间和精力。希望这篇小文章能让有兴趣在数据分析领域进一步学习了解的朋友们重视数据清洗的过程,夯实基础。
参考资料
Ron Cody, Cody's Data Cleaning Techniques Using SAS, Second edition(有第三版最新版本哦!链接请查收:https://pan.baidu.com/s/1fygwaWWIPuq_iG9dik4i4g 提取码: 2it2 )
FDA,美国食品药物管理局;SDTM,研究数据制表模型;ADaM,分析数据模型