基于思维链的大型语言模型问题生成方法
作者:子贺Leo@知乎 (北交大 CS硕士在读)
题目:Prompting Large Language Models with Chain-of-Thought for Few-Shot Knowledge Base Question Generation
作者:华东师范大学
来源:Arxiv 2023.10 EMNLP 2023
Prompting Large Language Models with Chain-of-Thought for Few-Shot Knowledge Base Question Generation
https://arxiv.org/abs/2310.08395
Abstract
知识库问题生成(KBQG)任务目的是将结构化的逻辑形式转换为自然语言问题,目前都是fine-tuning微调,但标注成本高 不适合少量数据生成,所以亟需低资源场景low-resource。随着LLMs+CoT的出现,本文提出了一种新的提示方法KQG-CoT:
(1)首先,考虑逻辑形式的结构特征,从未标记的数据池中选择支持的逻辑形式。
(2)其次,构建了一个任务特定的提示,以指导LLMs生成基于选择性逻辑形式的复杂问题。
(3)此外,通过对逻辑形式的复杂性进行排序,KQG-CoT扩展为KQG-Cot+
在三个公共KBQG数据集上进行了广泛的实验,结果表明,我们的提示方法在评估的数据集上始终优于其他提示基线。
1 Introduction
知识库问题生成(KBQG)任务是将结构化的逻辑形式转换为自然语言问题,由于在QA系统中具有数据增强的潜力及其协助对话系统创建连贯问题的能力,KBQG吸引了工业界和学术界越来越多的兴趣。
面临的挑战:
(1)微调需要大量带注释数据,成本高昂,缺乏低资源可用性。
(2)当涉及到聚合、最高级和比较等操作时,某些逻辑形式会变得复杂。
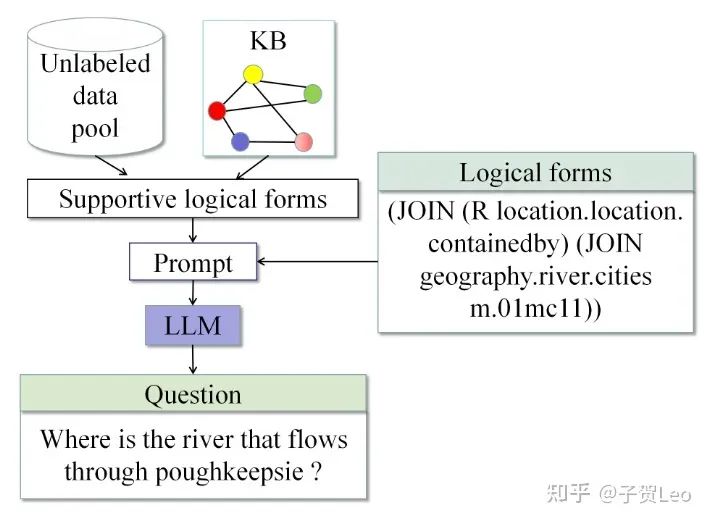
图1:KQG-CoT框架概述。
(如图1所示)于是本文提出了KQG-CoT框架,这是首次尝试使用llm进行无训练的少量KBQG,框架由两个主要步骤组成:
(1)通过聚类获得考虑句法和语义特征的支持性逻辑形式。
(2)通过思维链CoT构造提示,将复杂问题生成拆解为多个子问题。
2 Related work
这里讲到了知识库问题生成最开始是基于模板的,之后基于端到端神经网络。还介绍了少样本few-shot在文本生成的相关研究,以及LLMs上下文学习的相关研究。属于是背景介绍,就不具体展开了。
3 Methodology
3.1 问题定义
KB由一组三元组组成。逻辑形式是KB中子图的结构表达式,它可以由复杂的操作(例如,聚合、比较和最高级)组成,并且可以用于对KB执行。KBQG任务要求系统在给定逻辑形式和具有一致语义的相应KBs时生成自然语言问题。
3.2 方法综述
最近,LLMs已经展示了其令人印象深刻的上下文少样本学习能力。我们可以简单地将预训练模型应用于新任务,而不是对其进行微调以使其适应下游任务。对于KBQG任务,我们采用了两阶段的方法来设计CoT提示符,使LLM能够有效地理解复杂的逻辑形式并生成问题。
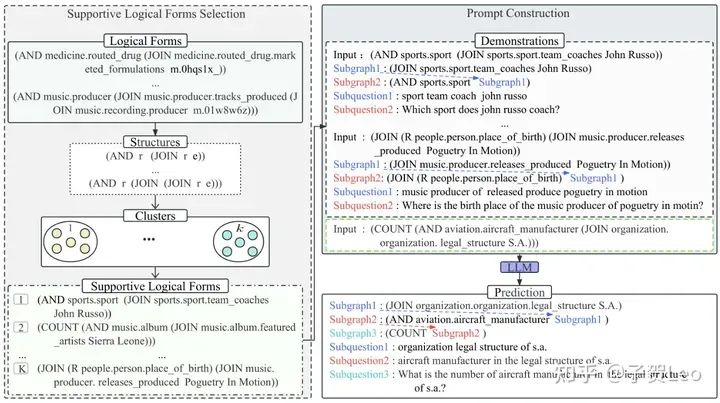
图2:KQG-CoT框架
3.3 支持性逻辑形式选择
逻辑形式是程序结构和模式项(即实体和关系)的组合;而支持性逻辑形式是指能够涵盖多种逻辑规则的逻辑形式,从而为llm生成问题提供更多的语法信息,需要以下三个步骤进行选择:
(1)结构编码:保持逻辑形式的语法不变。然后,我们用符号“r”代替关系,用“e”代替实体。这种结构也被称为抽象查询图,它过滤独特语义,反映了逻辑形式的拓扑结构和组件类。

(3)聚类:编码为向量后,利用k -means (Hartigan and Wong, 1979)聚类算法,根据编码结构的句法相似性将其分成k个聚类。
(2)逻辑形式采样:每个聚类包含一组具有相似结构的逻辑形式,我们从每一组中随机选取一个结构,得到k个具有代表性的结构。因为每个结构可以对应多个逻辑形式。我们进一步从k个选择的结构中识别出具有不同语义的k个逻辑形式。我们贪婪地选择一个与所选逻辑形式语义相似性最小的候选,其中相似性是通过原始逻辑形式的编码来衡量的。我们重复这个过程,直到遍历了k个结构。
3.4 提示构造
由于一些逻辑形式具有复杂的语义,甚至包含嵌套的语法结构。按照CoT方法,我们基于上面检索到的支持性逻辑形式构造一个推理链提示。对于每个示例,我们需要生成一个基于逻辑形式的推理链,以引出llm生成由简单到复杂的问题。为此,我们在构造推理链时遵循两个标准:
(1)模板应该将复杂问题的生成分解为一步一步的过程。
(2)模板应该以逻辑形式清楚地标识子组件,以便llm在每个步骤中关注这些子组件。
(图2所示)prompt的第一步将整个逻辑形式解析为一跳关系子图,第二步包括作为组件附加到前一步的解析逻辑形式,因此,我们不断地展开逻辑形式,直到形成一个完整的问题。这个循序渐进的过程确保生成的问题在语义上是连贯的,在语法上是准确的。
在推理过程中,我们将所有演示和查询的逻辑形式连接起来作为最后的提示。LLM收到提示后,输出预测,明确subquestion1、subquestion2和subquestion3的中间生成步骤,最终生成预测的自然语言问题。
4 Experiment
4.1 数据和指标
Data:WebQuestions(WQ)、PathQuestions(PQ)、GrailQA(GQ)
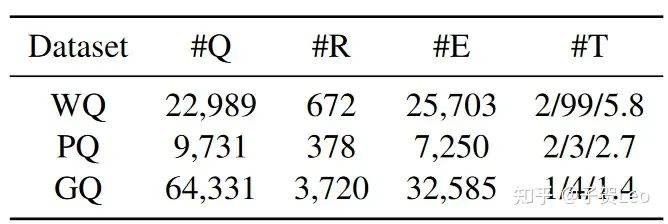
表1:评估数据集的统计数据。#Q表示问题的数量。#R和#E分别表示关系和实体的总数。#T表示每个问题中涉及的最小/最大/平均三联体数。
Metrics:BLEU-4、METEOR、ROUGEL(B、M、R)
4.2 对比方法
KQG-CoT:本文提出的提示方法
KQG-CoT+:采样后将演示从短到长排序来实现改进版本。
由于目前还没有使用llm进行几次KBQG任务的尝试,因此本文呢采用五种few-shot场景下的通用提示方法作为基准。
Standard Prompt:标准提示(Brown et al., 2020)是一种上下文学习的标准提示方法,将k个随机逻辑形式和问题连接起来形成提示。预测是一步生成的。
Random-CoT:随机思维链是一个直观的CoT提示基线,其中k个逻辑形式是从数据池中随机选择的,我们遵循原始工作(Brown et al., 2020)在叙述中描述子任务。
Manual-CoT :(Wei et al., 2022)是一种CoT提示,以k个人类书写的范例作为演示,子任务以叙述的形式呈现。
Active-CoT:(Diao et al., 2023)是CoT提示的集成框架。多个逻辑形式随机选择作为验证集。然后利用多个度量(例如:不一致,方差)作为每个逻辑形式的不确定值来产生最终问题。
Auto-CoT: (Zhang et al., 2023c)通过基于聚类的算法选择k个演示自动构建提示,子任务以叙述的形式呈现。我们将所有的逻辑形式以文本的方式编码,简单地对KBQG任务采用提示方法。
4.3 实现细节
对于逻辑形式的编码,我们利用Huggingface中的SentenceTransformers库中的allMiniLM-L6-v24检查点进行有效编码。由于这是一个只有几个镜头的场景,因此我们在链提示符中手动编写k个演示的基本原理。我们使用OpenAI API5中的text- davici -003生成问题,并将簇数设置为k = 126。
4.4 主要结果
与基线方案的比较: (1)KQG-CoT+提示在所有KBQG数据集上的表现都明显优于其他方法。(2)发现所有的CoT提示方法都优于标准提示方法,这表明为了生成逻辑复杂、依赖关系长的问题,将整个生成任务分解成子任务对于保持问题的连贯性和准确性至关重要。(3)通过对Auto-CoT、KQG-CoT和KQGCoT+方法的比较发现,尽管这些方法都采用聚类选择k个演示,但KQG-CoT和KQG-CoT+方法更有效,因为我们精心设计了KBQG任务的编码算法和提示模板,使其更适合从逻辑形式生成问题。
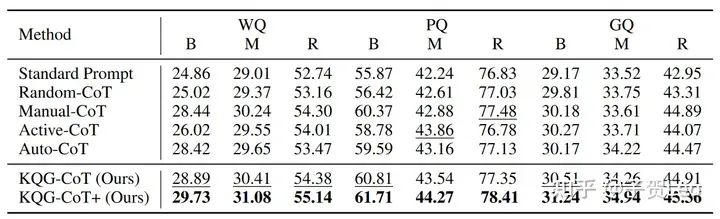
表2:在三个KBQG数据集上对现有的Frozen llm提示方法进行了几次评估。最好和次好的结果分别用黑体字和下划线表示。
与其他系统的比较: 据我们所知,我们是第一个使用GQ数据集处理KBQG任务的,因此没有现有的方法可用于比较。我们的方法仍然可以获得比大多数现有的全训练KBQG模型更好的结果。值得注意的是,AutoQGS只需要0.1%的训练实例进行训练,我们只需要利用12个实例进行推理,这凸显了我们方法的优越性。
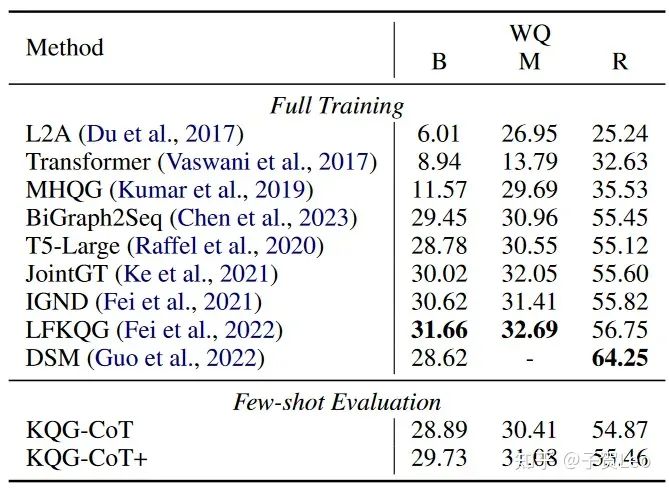
表3:KQG-CoT/KQG-CoT+的少样本评价与其他系统对WQ的全训练评价对比。
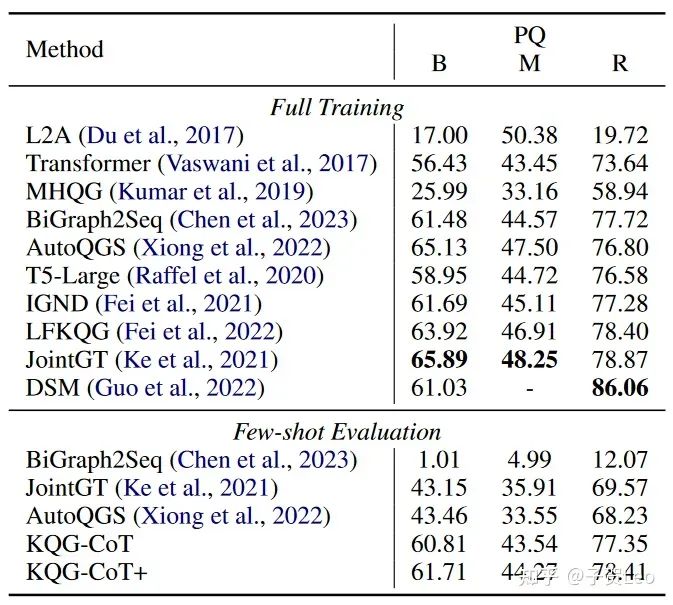
表4:同表3,在PQ数据集上的实验结果
4.5 更多分析
人类的评价:我们进一步通过从WQ数据集的测试集中随机抽取300个样本进行人工评估。考虑到语法正确性、复杂性和与给定逻辑形式的相关性,生成的问题被评为1到5的等级。我们要求三名注释者对生成的问题进行评分,1分为差,5分为完美。每个问题的分数是所有注释者的平均值。我们在表6中给出了结果,从中我们可以观察到人工评估和自动评估之间的类似趋势。我们的方法优于所有可比较的方法,这些方法的评估分数接近真实情况。
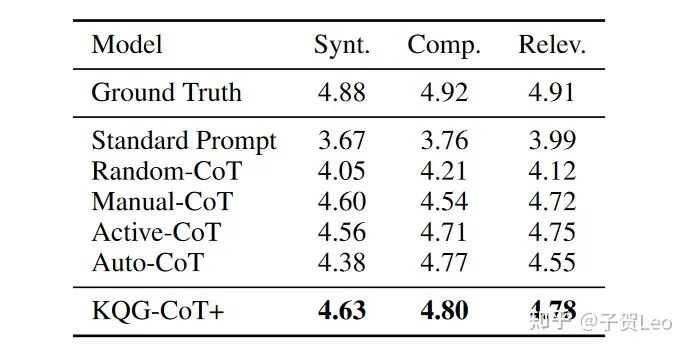
表6:WQ人工评价结果。Synt.,Comp.和Relev.分别表示语法正确性、复杂性和相关性。
消融实验:我们进行了消融研究,以评估模型各部分的有效性,并将结果显示在表7中。我们首先排除了CoT推理链,并观察到评估指标的性能下降。这表明CoT在生成复杂问题中起着重要的作用。然后我们去掉K-means算法,随机选择支持的逻辑形式。结果的减少表明我们的聚类算法可以提供更多样化的逻辑形式。
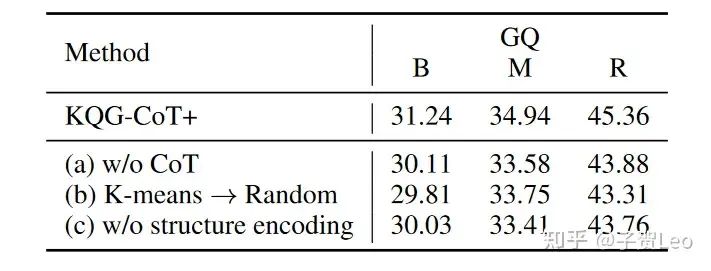
表7:KQG-CoT+方法对GQ的消融研究。
k的影响:我们在图3中研究了k的影响。可以观察到,随着演示次数的增加,我们的方法和RandomCoT的BLEU-4和ROUGE-L评分都在增加。这表明,在激活llm的电位中,演示的数量是显著的。与Random-CoT相比,当k的值变大时,我们的方法显示出更大的增益,这表明我们的方法确实选择了最具代表性的逻辑形式作为演示
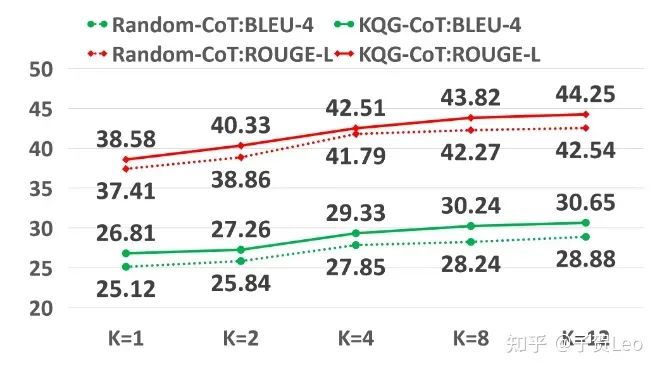
图3:我们的方法和Random-CoT在GQ上的BLEU-4和ROUGE-L评分随采样次数的增加。
案例研究:表5所示,我们的方法引出了中间生成步骤,并为LLMs提供了更多的指导,以便我们的KQG-CoT+生成语法正确且语义接近给定逻辑形式的问题。相反,基线方法可能会遇到逻辑形式不一致、修饰符错位或表达式不流畅等问题

表5:KQG-CoT+和GQ基线方法的说明性示例。
5 Conclusion
在本文中,我们提出了KQG-CoT方法来处理少量KBQG任务。KQG-CoT从未标记的数据中检索相关的逻辑形式并合并其特征。然后,它生成显式提示,以展示基于所选示例生成复杂问题的推理过程。实验结果表明,与基线相比,我们的方法达到了最先进的性能,甚至显示出与全训练方法相比具有竞争力的结果。
——The End——

分享
收藏
点赞
在看