
『每周译Go』开启并发模式

在这篇文章中,我将介绍在 Go 中使用基本并发模式和原生原语来构建并发应用程序的一些最佳实践。模式本身适用于任何语言,但对于这些示例,我们将使用 Go。
可以下载本文的源码配合阅读。
git clone https://github.com/benjivesterby/may2021-triangle-meetup.git
流水线模式
流水线模式 1 2 通常由若干个阶段组成,每个阶段都通过一系列 channel 连接。第一阶段是数据来源,最后阶段是数据汇总。数据流水线就是很好的例子,第一步挖掘数据,接下来清洗数据,最后一步将清洗的数据存储到数据库中。

Example Pipeline
如上图所示,第一阶段是数据的来源,最后阶段为数据汇总。下面是流水线模式实战的示例代码。
// Example of a pipeline pattern
func main() {
// Call each function passing the output of the previous function
// as the input to the next function
d := []data{
// ... data ...
}
// Create the pipeline
sink(sanitize(source(d)))
}
func source(in []data) <-chan data {
out := make(chan data)
go func(in []data) {
defer close(out)
for _, d := range data {
// Load data into the front of the pipeline
out <- d
}
}(in)
return out
}
func sanitize(in <-chan data) <-chan data {
out := make(chan data)
go func(in <-chan data, out chan<-data) {
defer close(out)
for {
d, ok := <- in
if !ok {
return
}
// ... Do some work
// push the data out
out <- d
}
}(in, out)
return out
}
func sink(in <-chan data) {
for {
d, ok := <- in
if !ok {
return
}
// ... Process the sanitized data
}
}
有关该模式可执行的示例代码,可以查看本文的 Github 项目代码 pipeline 目录。在项目根目录下运行下面的命令来执行流水线示例。
go run patterns/pipeline/main.go流水线模式通过一系列 goroutine 组成,每个 goroutine 由一个 channel 传入数据,另一个 channel 输出数据。使用此模式,你可以创建任何大小和复杂性的流水线。
扇出模式
扇出模式是指允许多个协程来使用来自单个数据源的的模式。当你需要对多协程进行的大数据处理做负载均衡时,该模式很有用。
有关该模式可执行的示例代码,可以查看本文的 Github 项目代码 fan-out 目录。在项目根目录下运行下面的命令来执行扇出示例。
go run patterns/fanout/main.go
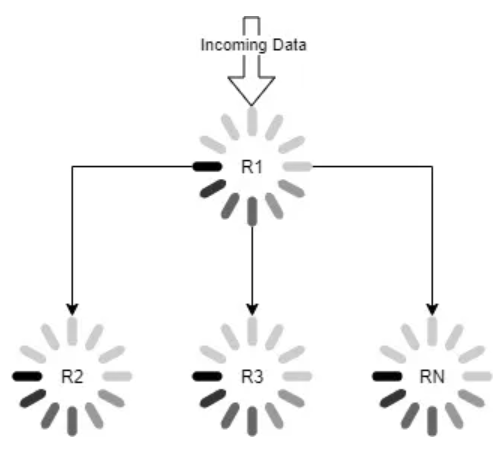
Example Fan-Out
下面是扇出模式的示例代码,其中数据被一系列的工作协程处理。
// Example of a fan-out pattern for processing data in parallel
func main() {
dataPipeline := make(chan data)
// Create three worker routines
go process(dataPipeline)
go process(dataPipeline)
go process(dataPipeline)
// Load the data into the pipeline
for _, d := range ReadData() {
dataPipeline <- d
}
// Close the pipeline when all data has been read in
// NOTE: This will immediately close the application regardless
// of whether the workers have completed their processing.
// See the section on Best Practices at the end of the post
// for more information on how to handle this.
close(dataPipeline)
}
func ReadData() []data {
// ...
}
func process(in <-chan data) {
for {
d, ok := <- in
if !ok {
return
}
// ... Do some work
}
}
上面例子中 process 函数被调用了三次,每个 goroutine 各行其事。channel in 作为入参传给每个 goroutine ,并通过一个 for 循环读取数据。当数据读取完毕时,channel in 被关闭。
复制模式
我们看到扇出模式不仅可以用来并行处理数据,还可以用作多线程复制数据。
// Example of a fan-out replication pattern
func main() {
dataPipeline := make(chan data)
// Pass the write-only channels from the three proc calls to the fan-out
go replicate(dataPipeline, proc1(), proc2(), proc3())
// Load the data into the pipeline
for _, d := range ReadData() {
dataPipeline <- d
}
}
func proc1() chan<- data {/* ... */}
func proc2() chan<- data {/* ... */}
func proc3() chan<- data {/* ... */}
func replicate(in <-chan data, outgoing ...chan<- data) {
for {
d, ok := <- in // Read from the input channel
if !ok {
return
}
// Replicate the data to each of the outgoing channels
for _, out := range outgoing {
out <- d
}
}
}
当使用复制模式的时候请注意数据的类型。特别是使用指针时候,因为复制器不是在复制数据而是在传递指针。
上面是一个扇出模式的示例代码,replicate 函数通过可变参数传入了三个 channel 被调用。channel in 提供了原始数据,并将其复制到输出 channel。
类型扇出
最后一个扇出模型我们将介绍 类型扇出 。当处理 interface{} 类型的 channel 时非常有用。此模式允许根据数据类型将数据定向到适当的处理器。
// Example of a type fan-out pattern from the github project
// for this post
func TypeFan(in <-chan interface{}) (
<-chan int,
<-chan string,
<-chan []byte,
) {
ints := make(chan int)
strings := make(chan string)
bytes := make(chan []byte)
go func(
in <-chan interface{},
ints chan<- int,
strings chan<- string,
bytes chan<- []byte,
) {
defer close(ints)
defer close(strings)
defer close(bytes)
for {
data, ok := <-in
if !ok {
return
}
// Type Switch on the data coming in and
// push the data to the appropriate channel
switch value := data.(type) {
case nil: // Special case in type switch
// Do nothing
case int:
ints <- value
case string:
strings <- value
case []byte:
bytes <- value
default:
fmt.Printf("%T is an unsupported type", data)
}
}
}(in, ints, strings, bytes)
return ints, strings, bytes
}
上面的例子展示了如何接收一个空的 interface(即 interface{})并使用类型开关来决定将数据发送到哪个 channel。
扇入/合并器模式
使用扇入模式时,数据会从多个 channel 读取后合并到一个 channel 输出。3 扇入模式与扇出模式刚好相反。
有关该模式可执行的示例代码,可以查看本文的 Github 项目代码 fan-in 目录。在项目根目录下运行下面的命令来执行扇入示例。
go run patterns/fanin/main.go

Example Fan-In
下面是一个扇入模式的代码示例,数据被多个工作协程挖掘并全部集中到一个单独的 channel 中。
// Example of a fan-in pattern mining data in
// parallel, but processing it all synchronously
func main() {
miner1 := mine()
miner2 := mine()
miner3 := mine()
// Take miner data and consolidate it into a single channel
out := consolidate(miner1, miner2, miner3)
// Process the data
for {
data, ok := <- out
if !ok {
return
}
// ... Do some work
}
}
func consolidate(miners ...<-chan data) <-chan data {
out := make(chan data)
// Iterate over the miners and start a routine for
// consuming each one and merging them into the output
for _, in := range miners {
go func(in <-chan data, out chan<- data) {
for {
d, ok := <-in // Pull data from the miner
if !ok {
return
}
out <- d // Send the data to the output
}
}(in, out)
}
return out
}
func mine() <-chan data {
out := make(chan data)
go func() {
// ... populate the channel with mined data
}()
return out
}
上面的例子利用扇入模式从多个模拟数据挖掘器中整合输入的数据。
组合和嵌套模式
这些模式中的每一个都可以组合起来以创造更复杂的模式。这会非常有用,因为大多数应用不会只使用一种并发模式。
下面是一个将所有模式组合到一个请求响应生命周期的例子。该例子中,数据来自单一来源,扇出到多个流水线,最后扇入成单个响应返回给用户。
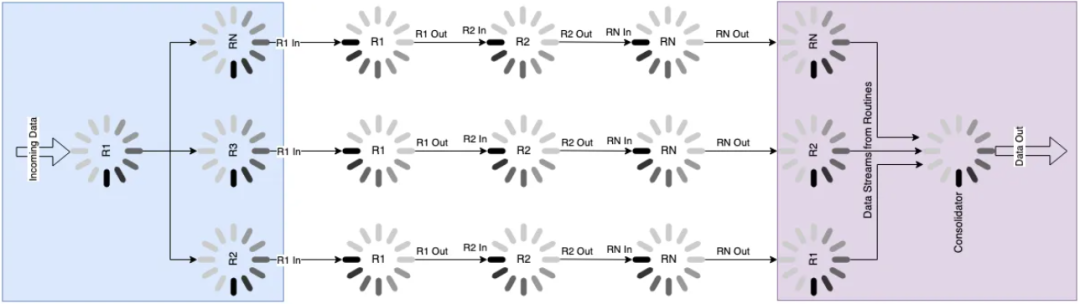
当构建应用程序时,我建议先构建一个设计图来帮助概念化这些并发设计元素。我真的很喜欢用 diagrams.net 来画设计图。构建这些设计图的过程有助于巩固最终产品并使设计更易于理解。将设计作为流程的一部分也将有助于将设计出售给其他工程师和领导层。
尽可能使用 Go 的原生并发原语
最佳实践
虽然主要使用 Go 的并发原语来管理 Go 应用程序中的并发被认为是最佳实践,但是在某些情况下,需要使用 sync 包来辅助管理并发。
一个很好的例子就是当你实现了类似于io.Closer 时需要确保所有协程都退出了。例如,如果你的代码产生了 N 个协程并且希望调用 io.Closer 方法时所有的协程都正确退出,你可以使用 sync.WaitGroup 来等待所有的协程直到它们被关闭。
执行此操作方法如下所示。
// Example of using a wait group to
// ensure all routines are properly exited
type mytype struct {
ctx context.Context
cancel context.CancelFunc
wg sync.WaitGroup
wgMu sync.Mutex
}
// DoSomething spawns a go routine
// every time it's called
func (t *mytype) DoSomething() {
// Increment the waitgroup to ensure
// Close properly blocks
t.wgMu.Lock()
t.wg.Add(1)
t.wgMu.Unlock()
go func() {
// Decrement the waitgroup
// when the routine exits
defer t.wg.Done()
// ... do something
}()
}
func (t *mytype) Close() error {
// Cancel the internal context
t.cancel()
// Wait for all routines to exit
t.wgMu.Lock()
t.wg.Wait()
t.wgMu.Unlock()
return nil
}
上面的代码有几个重点。首先,使用 sync.WaitGroup来增加和减少正在运行的协程数量。其次,使用 sync.Mutex 来确保只有同时只有一个协程在修改 sync.WaitGroup(.Wait() 方法不需要 mutex )
单击此处阅读 Leo Lara 对此的详细解释 4
有关需要使用 sync 包的情况的功能示例,请参阅 Plex 库。
泛型 (即将到来!)
随着 Go 1.18 中泛型的引入,这些模式使用起来会变得更加容易,我将在下一篇文章中介绍。
Pipelines - Concurrency in Go by Katherine Cox-Buday - Page 100 ↩︎
Go Concurrency Patterns: Pipelines and cancellation ↩︎
Multiplexing - Concurrency in Go by Katherine Cox-Buday - Page 117 ↩︎
Closing a Go channel written by several goroutines ↩︎
原文地址:https://benjiv.com/beginning-concurrency-patterns/
原文作者:Benjamin Vesterby
本文永久链接:https://github.com/gocn/translator/blob/master/2022/w09_Beginning_Concurrency_Patterns.md
译者:朱亚光
校对:4+6

『每周译Go』Go原生并发基本原理与最佳做法
『每周译Go』以Go为例-探究并行与并发的区别
想要了解关于 Go 的更多资讯,还可以通过扫描的方式,进群一起探讨哦~