
总结 | CNN中的目标多尺度处理
点击左上方蓝字关注我们

作者 | 点点点
链接 | https://zhuanlan.zhihu.com/p/70523190
图像金字塔:经典的基于简单矩形特征(Haar)+级联Adaboost与Hog特征+SVM的DPM目标识别框架,均使用图像金字塔的方式处理多尺度目标,早期的CNN目标识别框架同样采用该方式,但对图像金字塔中的每一层分别进行CNN提取特征,耗时与内存消耗均无法满足需求。但该方式毫无疑问仍然是最优的。值得一提的是,其实目前大多数深度学习算法提交结果进行排名的时候,大多使用多尺度测试。同时类似于SNIP使用多尺度训练,均是图像金字塔的多尺度处理。 特征金字塔:这个概念早在ACF目标识别框架的时候已经被提出(PS: ACF系列这个我前两年入过一段时间的坑,后来发现他对CPU内存要求太大,不过确实是前几年论文灌水利器,效果也还不错,但还是不能落地的,我已果断弃坑)。而在CNN网络中应用更为广泛,现在也是CNN中处理多尺度的标配。目前特征提取部分基本是FCN,FCN本质上等效为密集滑窗,因此不需要显示地移动滑动窗口以处理不同位置的目标。而FCN的每一层的感受野不同,使得看到原图中的范围大小不同,也即可以处理不同尺度的目标。因此,分析CNN中的多尺度问题,其实本质上还是去分析CNN的感受野,一般认为感受野越大越好,一方面,感受野大了才能关注到大目标,另一方面,小目标可以获得更丰富的上下文信息,降低误检。

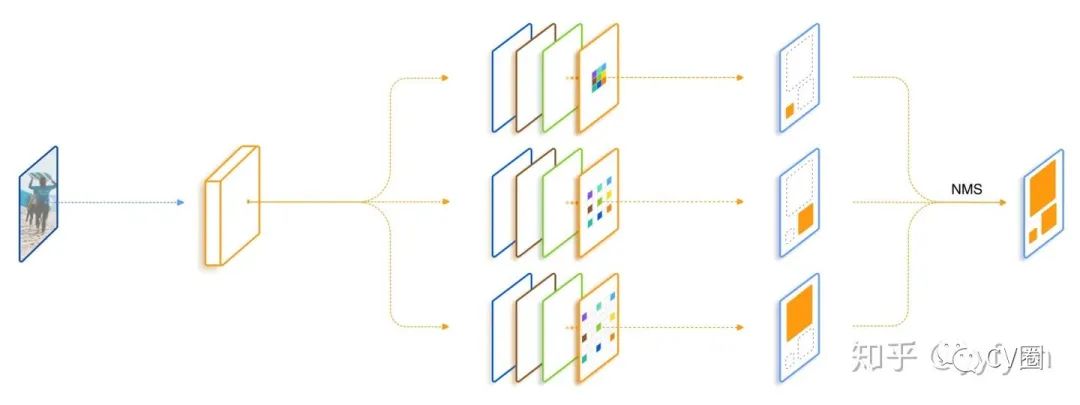
SSD中的多尺度处理

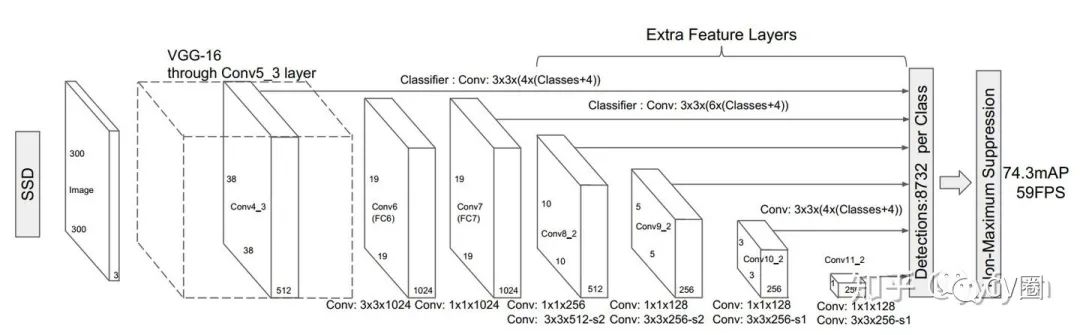
一般使用低层检测小目标,但低层感受野小,上下文信息缺乏,容易引入误检;
使用简单的单一检测层多尺度信息略显缺乏,很多任务目标尺度变化范围十分明显;
高层虽然感受野较大,但毕竟经过了很多次降采样,大目标的语义信息是否已经丢失;
多层特征结构,是非连续的尺度表达,是非最优的结果;
U-shape/V-shape型多尺度处理
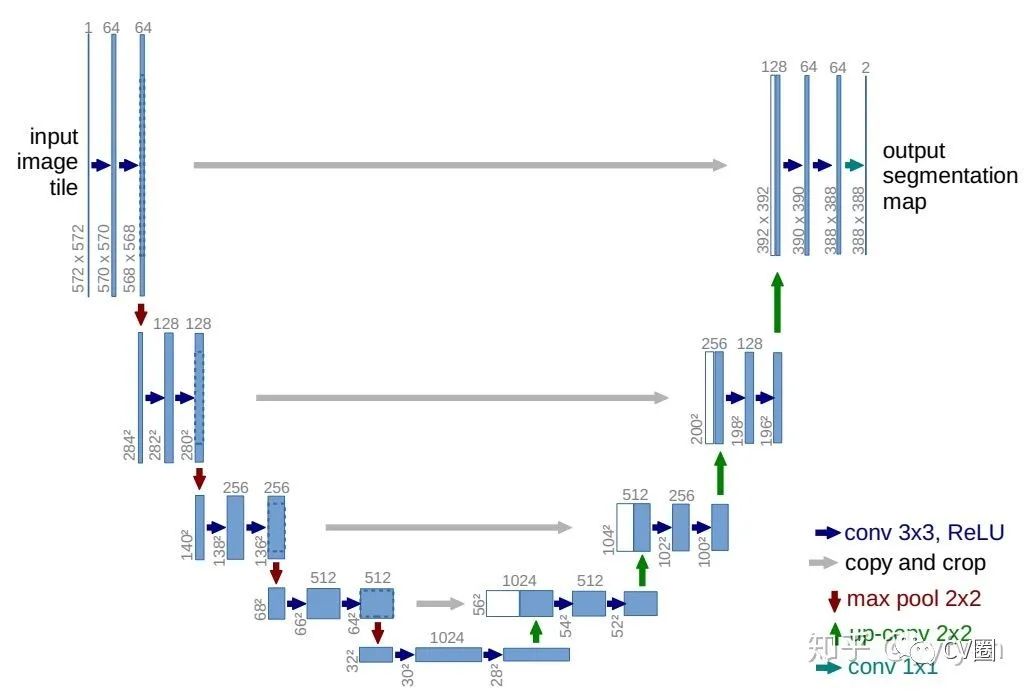
由于decoder使用的通道数与encoder相同,导致了大量的计算量;
上采样结构不可能完全恢复已经丢失的信息;
SNIP/SNIPER中的多尺度处理
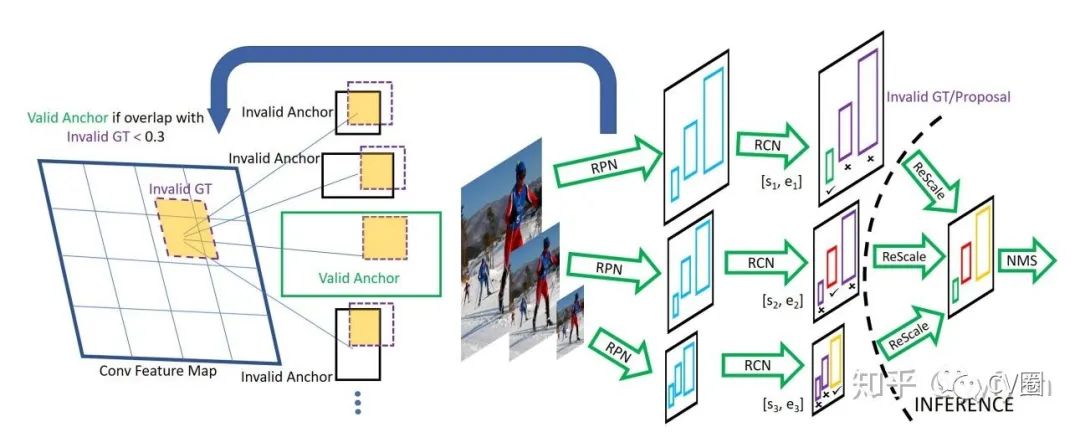
训练与测试分辨率从不一致的时候性能会下降;
大分辨率输入图像虽然能提升小目标检测性能,但同时使得大目标过大导致其很难分类,此消彼长,最终精度提升并不明显;
多尺度训练(Mutil-Scale training),采样到的图像分辨率很大(1400x2000),导致大目标更大,而图像分辨率过小时(480x640),导致小目标更小,这些均产生了非最优的结果;
SNIP针对不同分辨率挑选不同的proposal进行梯度传播,然后将其他的设置为0。
即针对每一个图像金字塔的每一个尺度进行正则化表示;
空洞卷积处理多尺度
控制实验证明了感受野大小与目标尺度呈现正相关;
设计三个并行分支获取不同大小的感受野,以分别处理不同尺度的目标,感受野使用空洞卷积表征;
每个分支采用Trident block构建,取代ResNet-res4中的多个原始的Block;
训练类似于SNIP,三个分支分别采用不同尺度的目标训练。
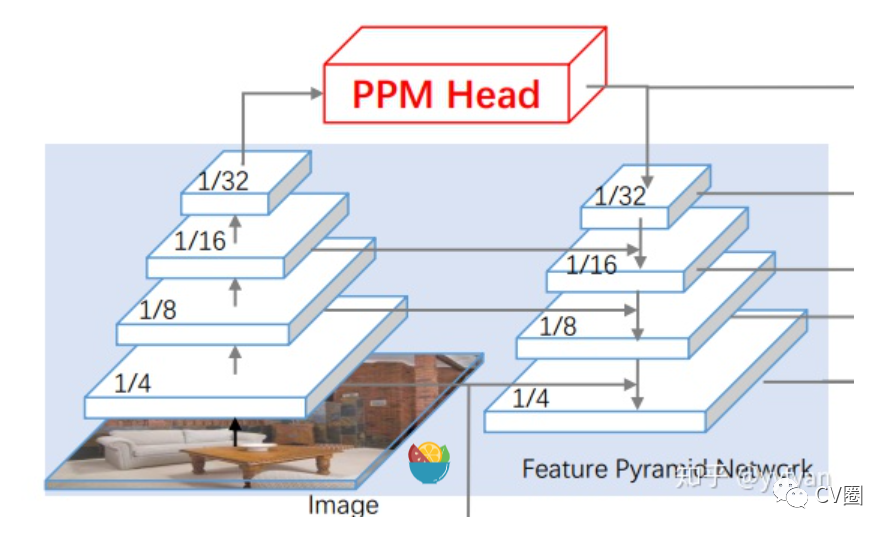
FPN中的多尺度处理
在上采样时使用了比较粗糙的最近邻插值,使得高层的语义信息不一定能有效传播;
由于经过多次下采样,最高层的感受野虽然很丰富,但可能已经丢失了小目标的语义信息,这样的传播是否还合适;
FPN的构建只使用了backbone的4个stage的输出,其输出的多尺度信息不一定足够;
FPN中虽然传播了强的语义信息到其他层,但对于不同尺度的表达能力仍然是不一样的,因为本身就提取了不同backbone的输出。
FPN的各种改进版本
Shu Liu, et al. Path Aggregation Network for Instance Segmentation.//CVPR 2018
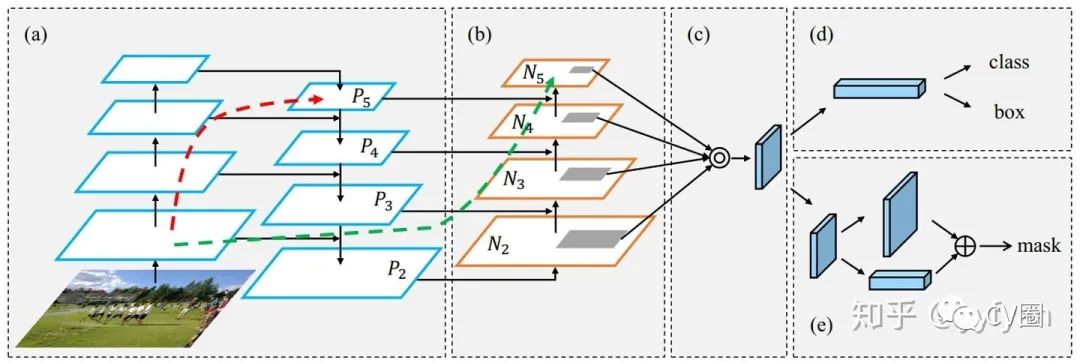
Di Lin,et al. ZigZagNet: Fusing Top-Down and Bottom-Up Context for Object Segmentation.//CVPR 2019
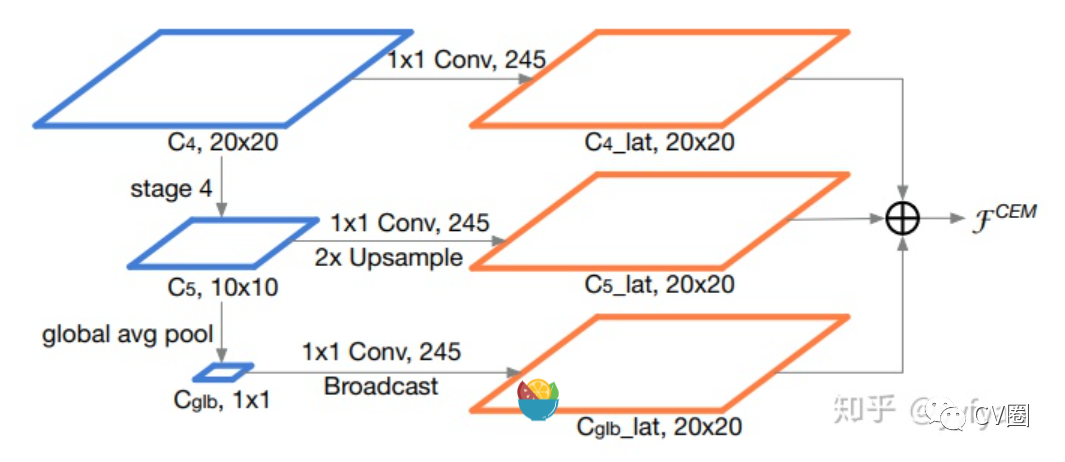
Zheng Qin,et al. ThunderNet: Towards Real-time Generic Object Detection.//CVPR 2019
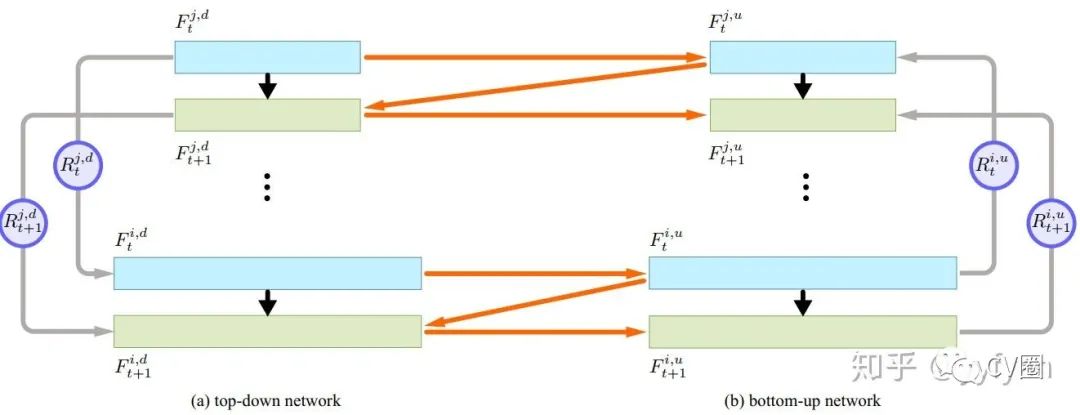
Wenbo Li, et al. Rethinking on Multi-Stage Networks for Human Pose Estimation.//arxiv 2019
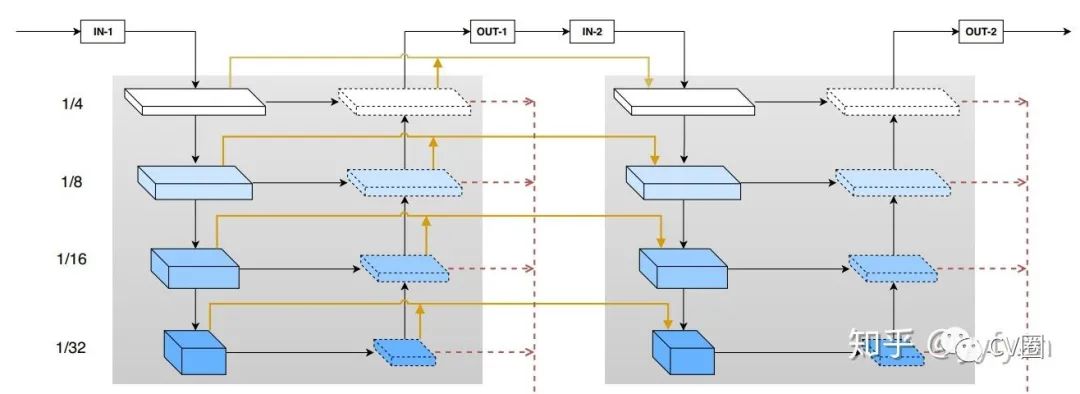
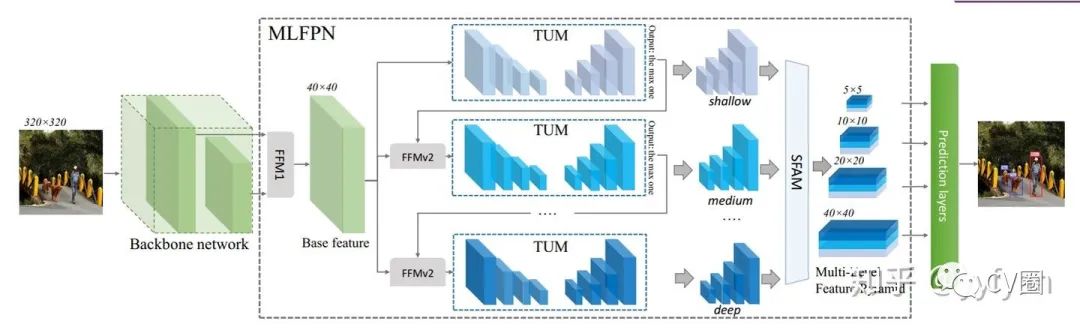
Qijie Zhao,et al. M2Det: A Single-Shot Object Detector based on Multi-Level Feature PyramidNetwork.//AAAI 2019
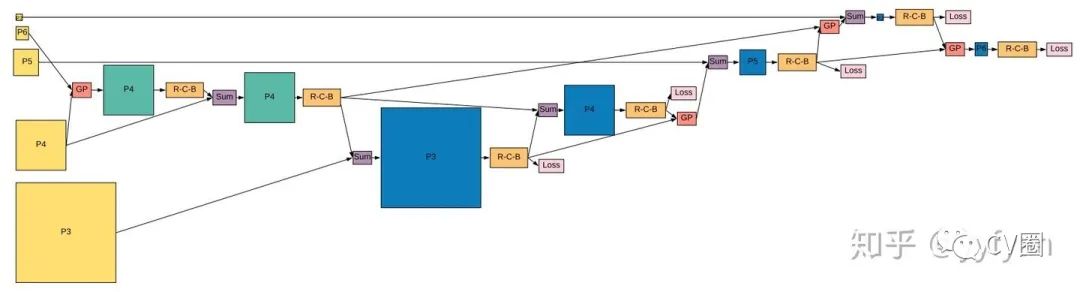
Golnaz Ghaisi, et al. NAS-FPN: Learning Scalable Feature Pyramid Architecturefor Object Detection.//CVPR2019
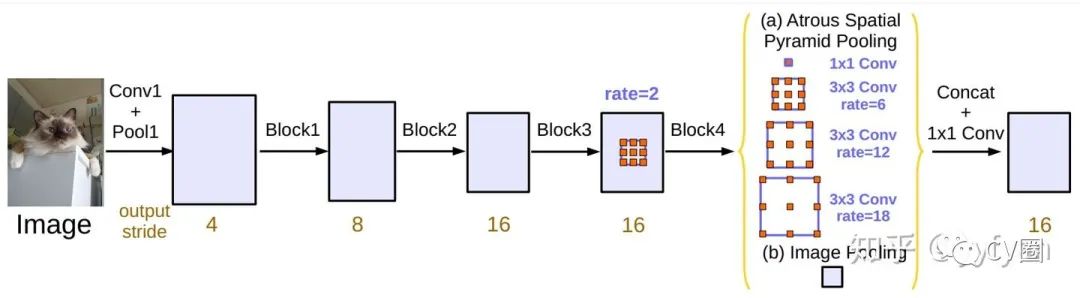
上下文模块加强多尺度信息
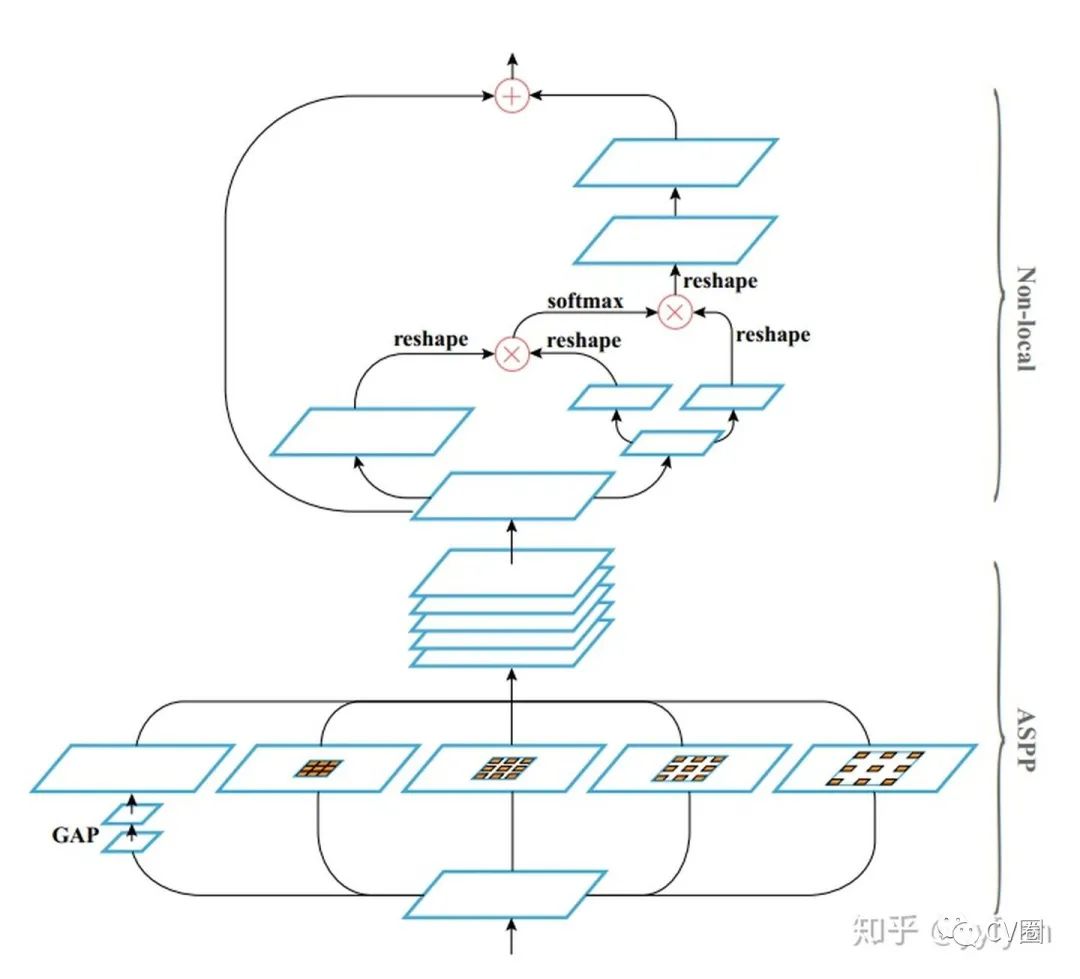
Liang-Chieh Chen, et al. Rethinking Atrous Convolution for Semantic Image Segmentation.//arxiv 2017
Hengshuang Zhao, et al. Pyramid Scene Parsing Network.//CVPR 2017
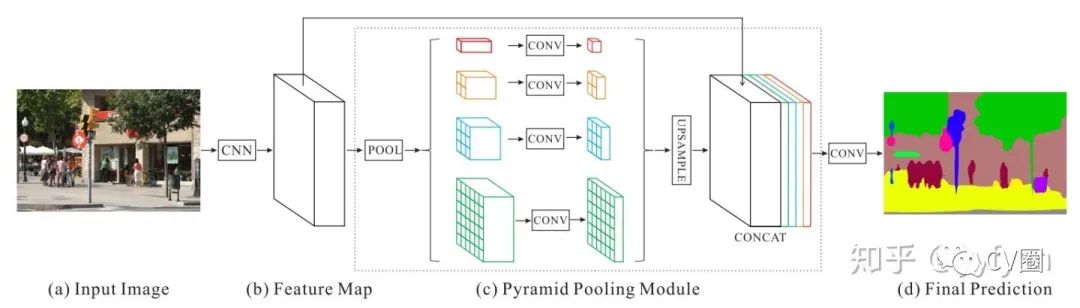
Tete Xiao,et al. Unified Perceptual Parsing for Scene Understanding.//ECCV 2018
Lu Yang,et al. Parsing R-CNN for Instance-Level Human Analysis. //CVPR 2019
END
整理不易,点赞三连↓