
Elasticsearch原理解析与性能调优
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
作者 | 谭英智
来源 | urlify.cn/URVFju
基本概念
定义
一个分布式的实时文档存储,每个字段 可以被索引与搜索
一个分布式实时分析搜索引擎
能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
用途
全文检索
结构化搜索
分析
VS传统数据库
传统数据库
提供精确匹配
ES
提供精确匹配
全文检索
处理同义词
给文档相关性评分
生成分析与聚合数据
实时
专有名词
索引(名词)
类似于数据库
索引(动词)
类似于insert。例如索引一个文档到一个索引
倒排索引
默认每个属性都会有一个倒排索引,可以设置属性不被索引,它只能被覆盖,不能被修改
类型
类似表,同一索引的不同类型,可以拥有不同的字段,但应该拥有大部分相似的字段。它可以包含大小写,不能包含句号,不能以下划线开头,长度限制为256.
Id
文档的id,可以在生成文档时指定或自动生成,自动生成的ID,在大部分情况下多个节点的时候唯一。如果在创建文档时,ID冲突,服务器会返回409
文档
类似于记录,文档只能被替换,而不能被修改,文档的字段类型需要一致,否则无法进行精确匹配
精确值字段
对于数字,日期,布尔和一个not_analyzed字段,进行查询,会适用精确匹配
全文搜索字段
否则,进行相关性搜索
PUT /megacorp/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
例如
megacorp是索引
employee是类型
1是文档id
json内容是文档
交互
RESTful API
curl -X '://:/?' -d ''
VERB | 适当的 HTTP 方法 或 谓词 : GET、 POST、 PUT、 HEAD 或者 DELETE。 |
|---|---|
PROTOCOL | http 或者 https(如果你在 Elasticsearch 前面有一个 https 代理) |
HOST | Elasticsearch 集群中任意节点的主机名,或者用 localhost 代表本地机器上的节点。 |
PORT | 运行 Elasticsearch HTTP 服务的端口号,默认是 9200 。 |
PATH | API 的终端路径(例如 _count 将返回集群中文档数量)。Path 可能包含多个组件,例如:_cluster/stats 和 _nodes/stats/jvm 。 |
QUERY_STRING | 任意可选的查询字符串参数 (例如 ?pretty 将格式化地输出 JSON 返回值,使其更容易阅读) |
BODY | 一个 JSON 格式的请求体 (如果请求需要的话) |
例子
request:
curl -XGET 'http://localhost:9200/_count?pretty' -d '
{
"query": {
"match_all": {}
}
}
'
response:
{
"count" : 0,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
}
}
检索文档功能
获取一个文档
GET /megacorp/employee/1简单查询
GET /megacorp/employee/_search #查询前十条记录GET /megacorp/employee/_search?q=last_name:Smith #查询smith的前十条记录表达式查询
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"last_name" : "Smith"
}
}
}GET /megacorp/employee/_search
{
"query" : {
"bool": {
"must": {
"match" : {
"last_name" : "smith"
}
},
"filter": {
"range" : {
"age" : { "gt" : 30 }
}
}
}
}
}全文检索
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"about" : "rock climbing"
}
}
}短语查询
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
}
}分析(类似于聚合group by)
request:
GET /megacorp/employee/_search
{
"aggs" : {
"all_interests" : {
"terms" : { "field" : "interests" },
"aggs" : {
"avg_age" : {
"avg" : { "field" : "age" }
}
}
}
}
}response:
...
"all_interests": {
"buckets": [
{
"key": "music",
"doc_count": 2,
"avg_age": {
"value": 28.5
}
},
{
"key": "forestry",
"doc_count": 1,
"avg_age": {
"value": 35
}
},
{
"key": "sports",
"doc_count": 1,
"avg_age": {
"value": 25
}
}
]
}修改文档
PUT /website/blog/123
{
"title": "My first blog entry",
"text": "I am starting to get the hang of this...",
"date": "2014/01/02"
}旧文档不会马上删掉
新文档会被索引
文档的version会加一
删除文档
DELETE /megacorp/employee/123文档的version依然会加一
分布式特性
ES自动执行的分布式动作
分配文档到不同的容器 或 分片 中,文档可以储存在一个或多个节点中
按集群节点来均衡分配这些分片,从而对索引和搜索过程进行负载均衡
复制每个分片以支持数据冗余,从而防止硬件故障导致的数据丢失
将集群中任一节点的请求路由到存有相关数据的节点
集群扩容时无缝整合新节点,重新分配分片以便从离群节点恢复
水平扩展VS垂直扩展
ES对水平扩展是友好的,通过购置更多的机器,可以更好的使用ES的分布式功能
集群
集群拥有一个或多个节点,当有节点加入或者退出集群时,集群会重新平均分配所有数据的分布
主节点功能
增加/删除索引
增加/删除节点
不涉及文档的变更和搜索,因此单一的主节点不会成为集群的性能瓶颈
索引分片的元数据在每个ES节点都有存储,每个节点在接到请求后,都知道到哪台ES node找到数据,通过转发请求到ES node所在的机器
一个分片的最大文档数:(2^31-128)
一个索引的主分片数在建立时被确定,且无法修改:因为文档的存储是用shard = hash(routing) % number_of_primary_shards来确定文档的位置的。routing默认是id,也可以自定义
分片的副本数可以随时修改
建立索引
PUT /blogs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
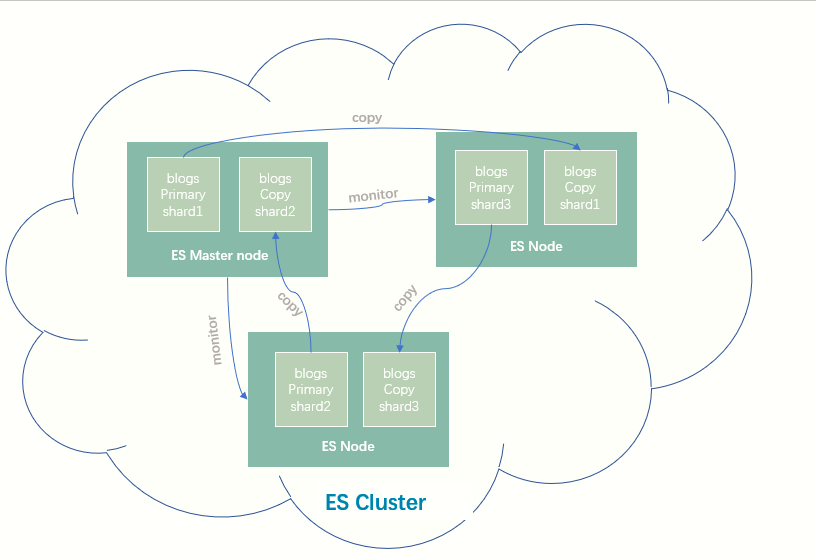
故障转移
增加一台机器到集群

删除节点
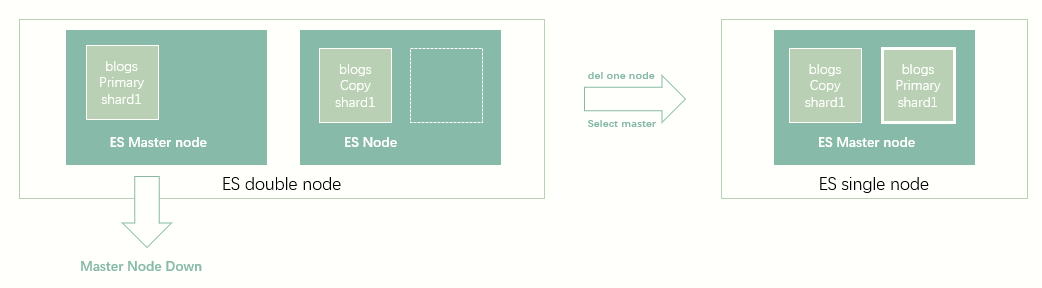
分布式写入冲突
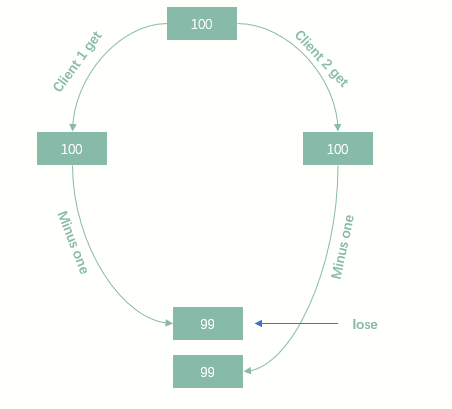
对于多个client的写入ES,有可能造成写入冲突,导致数据的丢失
在一些场景下,数据丢失是可以接受的
但是在某些场景下,是不允许的。
悲观控制并发
传统数据库的控制方式。通过对记录加锁,来实现并发的串行执行
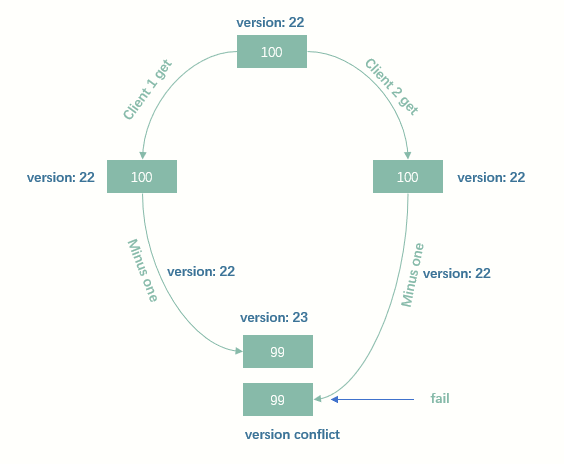
乐观并发控制
ES采用乐观控制
所谓乐观控制,就是服务器假设大部分情况下,是不会发生冲突的,如果发生冲突,则拒绝修改,客户端可以需要通过重新获取并重试进行处理。
过程如下图
分布式文档存储
确定文档位于那个shard
shard = hash(routing) % number_of_primary_shards
API支持带routing参数,来自定义路由,来确保相关文档路由到同一个分片
以ID新建,写入和删除文档
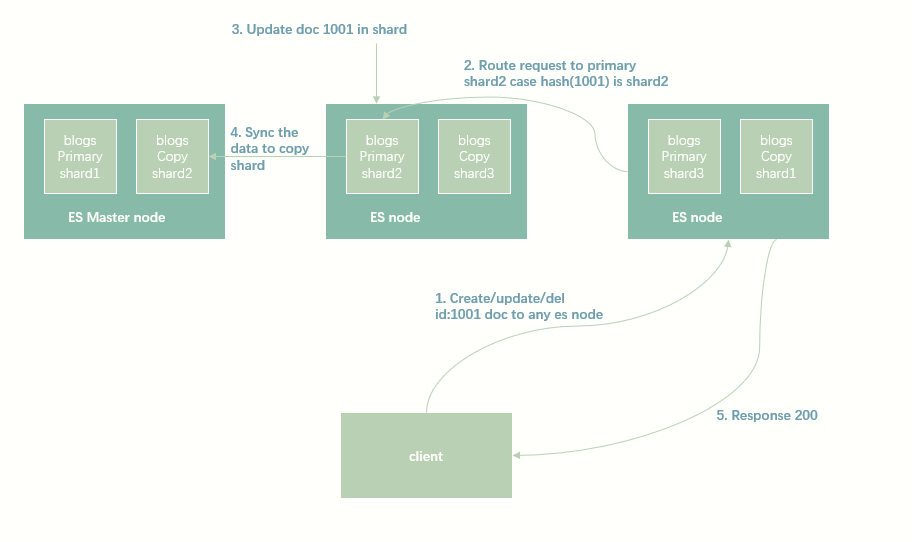
一致性保证
none: 主分片活跃,允许写入
all: 在所有分片活跃,允许写入
quorum: 半数以上节点活跃,允许写入
如果暂时没有足够的分片活跃,ES会等待,默认等待1分钟,可以通过参数timeout改变这个值,如果超时,则失败返回
新索引默认有
1个副本分片,这意味着为满足规定数量应该 需要两个活动的分片副本。但是,这些默认的设置会阻止我们在单一节点上做任何事情。为了避免这个问题,要求只有当number_of_replicas大于1的时候,规定数量才会执行。
以ID检索文档
与上图类似
以ID更新文档
与上图类似,但在更新完文档后,会重建索引
在局部更新文档的时候,主分片会以整份文档来同步给副本,来保证数据的完整性
通过条件获取多个文档
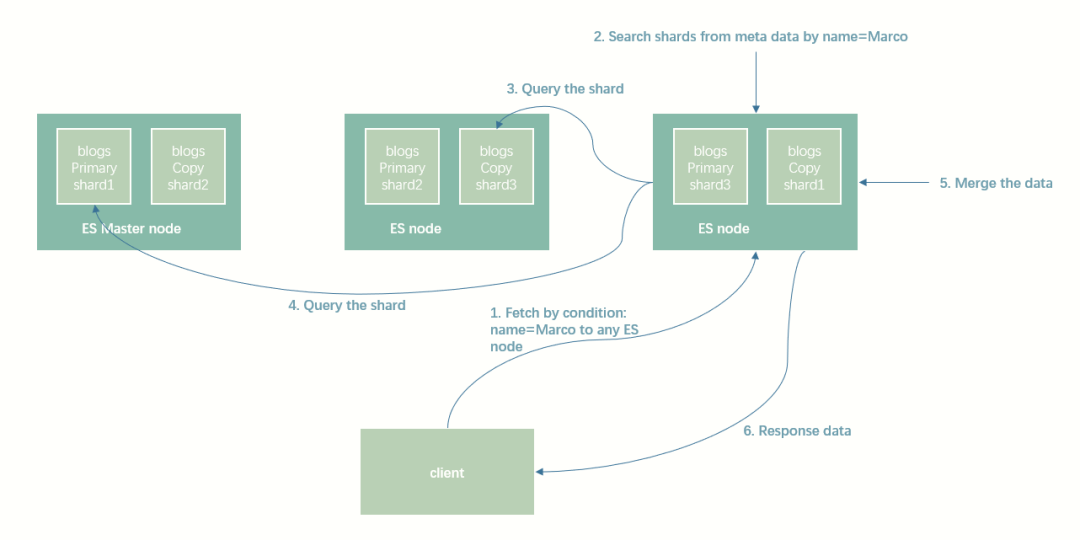
搜索
返回特殊字段
GET /_search
{
"hits" : {
"total" : 14,
"hits" : [
{
"_index": "us",
"_type": "tweet",
"_id": "7",
"_score": 1,
"_source": {
"date": "2014-09-17",
"name": "John Smith",
"tweet": "The Query DSL is really powerful and flexible",
"user_id": 2
}
},
... 9 RESULTS REMOVED ...
],
"max_score" : 1
},
"took" : 4,
"_shards" : {
"failed" : 0,
"successful" : 10,
"total" : 10
},
"timed_out" : false
}
took
执行的毫秒数
_shards
查询分片的状态,例如有几个分片是失败的,几个是成功的
timeout
可以通过在查询设定超时,如果查询超过时间,则只返回已经成功获得的数据,剩余的数据将丢弃
_index
数据来源的Lucene索引,文档的每一个字段,都拥有一个不同的Lucene索引
在查询中可以指定Lucene的索引,默认是不指定的,所以会查询该文档的所有索引,并汇总结果。如果指定,则会限定仅在指定的Lucene索引中查询数据
分页
GET /_search?size=5&from=5
此方式只适用于浅分页,如果查询过深,会导致严重的性能问题。
因为例如查询size为5,from=10000。那么ES会从各分片中都查询10005条记录,如果有100个shard,那么就会有100*10005条记录,ES再对这100*10005排序,并仅返回5条记录
深分页
使用游标scroll
它在ES中建立了一个有有效期的快照,提供给scroll进行数据的深度查询
倒排索引
对一下文档进行倒排:
The quick brown fox jumped over the lazy dog
Quick brown foxes leap over lazy dogs in summer
得到:
Term Doc_1 Doc_2
-------------------------
Quick | | X
The | X |
brown | X | X
dog | X |
dogs | | X
fox | X |
foxes | | X
in | | X
jumped | X |
lazy | X | X
leap | | X
over | X | X
quick | X |
summer | | X
the | X |
------------------------
倒排面临的挑战
Quick跟quick,用户有可能认为它们是相同的,也有可能认为是不同的
dog和dogs非常接近,在相关性搜索时,它们应该都被搜索到
jump和leap是同义词,在相关性搜索时,它们应该都被搜索到
理解相关性
相关性的分数是一个模糊的概念。没有精确值,没有唯一正确的答案。是一种根据各种规则对文档进行的一种量化的估计。
它评分的准则如下:
检索词频率
检索词在该字段出现的频率越高,分数越高
反向文档频率
检索词在索引出现的频率越高,分数越低
字段长度准则
字段的长度越长,分数越低
相关性破坏
在使用全文检索某个关键字的时候,会出现,相关度低的文档的得分高于相关度高的文档的得分。
例如检索词milk。索引内有两个主分片,milk在P1出现了5次,在P2出现了6次。由于P1和P2的词分布不一样。
P1的词量比P2的词量高,那么milk算在P1出现占比小,导致在P1得相关性得分高,而在P2,占比da,导致在P2的相关性得分低。
原因
是因为局部数据分布不均匀导致的
解决方法
插入更多的文档
使用?search_type=dfs_query_then_fetch进行全局评分。但会有严重的性能问题。不推荐使用。
查询过滤bitset
每次使用检索词查询,都会为检索词建立一个bitset,bitset包含了匹配的文档的序号。在热搜索的检索词,ES会对这些bitset有针对的进行缓存,而不用在再次查询的时候,重新查找倒排索引。
对于多个查询可以有下图

当倒排索引重建的时候,bitset在缓存会自动失效
缓存的策略
最近256次被使用的bitset,会被缓存
段内记录小于1w的,不会被缓存
索引管理
创建索引
可以显式创建,也可以隐式创建。
在大集群下,索引的创建,涉及元数据的同步,有可能导致集群负载的大量增加。此时需要禁用索引的隐式创建
action.auto_create_index: false
删除索引
删除索引,会涉及大量数据的删除,如果用户意外地试图通过一条命令,把所有索引删掉,这可能导致可怕的后果
通过禁用此操作,可以设置如下
action.destructive_requires_name: true
分析器
每个索引都可以设置自己的分析器,分析器的用途主要是在全文索引上面,通过对不同的语言,使用不同的分词,不同的词转换来构造倒排索引和计算相关性。
分片
倒排索引的不变性
好处
一旦被读入系统缓存,就会一直留在那里,直到LRU算法把不常用的倒排索引剔除。这对ES的读取性能提供了非常大的提升
不好
新的文档加入,不能增量更新,只能重建索引并替换
如何保证新数据能实时能查询到
用更多的索引。
对于新的文档,不马上重建索引,而是通过新增额外的索引。在查询数据时,通过轮询所有的索引,并合并结果返回。
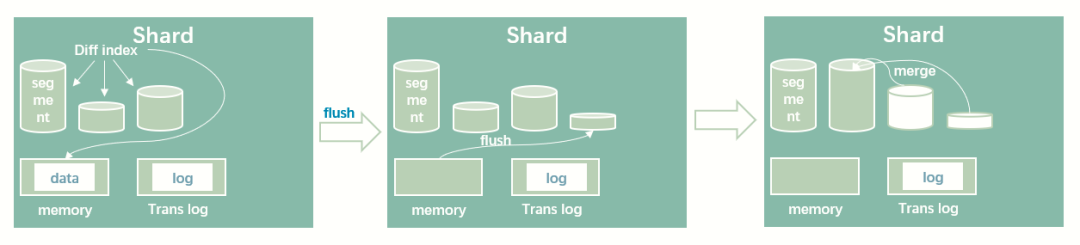
ES并不是严格意义上的实时,准确来说是准实时,由于data从插入到建立倒排索引这段时间,新数据是不能访问的
聚合
像数据库的group by。只是语法不一样。功能相通
应用层性能调优
调大 refresh interval
默认刷新时间是1s,每次刷新都会有一次磁盘写入,并创建一个新的段。通过设置更大的刷新时间,可以让磁盘写入的次数更低,写入的段更大。减少段合并的次数。
禁止OS把ES置换出去
OS的内核会在内存紧张的时候,把进程置换到外村。而对于性能跟内存强相关的ES来说,置换到外存是致命的。通过设置进程在内核的参数,禁止置换,可以避免OS的这种动作
预留大量的文件系统缓存给ES
由于ES大部分数据的不变性,使得ES的大部分磁盘操作,都可以通过文件系统的缓存来加快速度。一旦ES的倒排索引和数据缓存到系统,如果没有其他进程的干扰,而且是比较频繁访问的数据,则会一直驻留在系统缓存,使得ES的大部分操作都是走内存的。一般来说,分配一半的内存给文件系统,是合适的。
使用自动生成ID
如果指定ID,ES会在集群内检查是否ID已经存在,这对大集群来说,是昂贵的。如果ID是自动生成的,ES会跳过检查,直接插入文档
更好的硬件
更大的内存
SSD
本地磁盘
不要使用join关联查询
ES不适合做关联查询,会导致严重的性能问题。
如果业务一定要join,可以把关联的数据都写到一个索引内,或者通过应用程序来做关联的动作。
强制merge只读索引
merge成一个单一的段,会得到更好的性能
增加副本
有更多的机器,通过提高副本数,可以提高读效率
不要返回大数据
ES不适合这场景
避免稀疏
不要把不相关的信息存入同一个索引
数据预热
对于热点数据,可以通过一个客户端请求ES,让数据先占据filesystem cache。
冷热数据分离
冷热数据部署在不同的机器,可以让热数据在缓存内不会被冷数据冲走
内核层性能调优
限流
如果ES出现高负载的请求,ES的协调节点会累积大量的请求在内存在等待处理,随着请求数的增加,协调节点的内存占用会越来越大,最后导致OOM。
通过限流,可以有效缓解。
大查询
如果客户端发来了一个复杂的查询,使得需要返回的数据异常的大,这也会导致OOM问题。
通过修改内核,让如果请求的内存占用超过系统可以承受的范围,则截断来解决
FST过大引发OOM
FST是对倒排索引在内存的索引,它通过前缀状态机的方法,快速的定位检索词在倒排索引的磁盘位置,达到减少磁盘访问次数而加快检索速度的目的。
但由于FST是常驻内存的,如果倒排索引达到一定规模时,FST必然会引起OOM问题。而且FST是存放在JVM堆内内存的。堆内内存的上限时32G。
而10 TB的数据就需要10G到15G的内存来存放FST。
通过把FST的存储放到堆外内存
通过LRU算法来管理FST,对不常用的FST置换出内存
修改ES访问FST的逻辑,使得ES可以从堆内直接访问堆外的FST
在堆内增加FST的cache,加快命中速度
Ref:
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
https://zhuanlan.zhihu.com/p/99718374
https://blog.csdn.net/wangnan9279/article/details/79287907/
粉丝福利:实战springboot+CAS单点登录系统视频教程免费领取
???
?长按上方微信二维码 2 秒 即可获取资料
感谢点赞支持下哈 