
Django敏感词检测
作者:vk
链接:https://0vk.top/zh-hans/article/details/65
来源:爱尚购
点击阅读更多获取极致阅读体验
为了识别和过滤用户提交的恶意内容,每一条人工检查的成本又太大,需要开发一个自动检测敏感词的程序
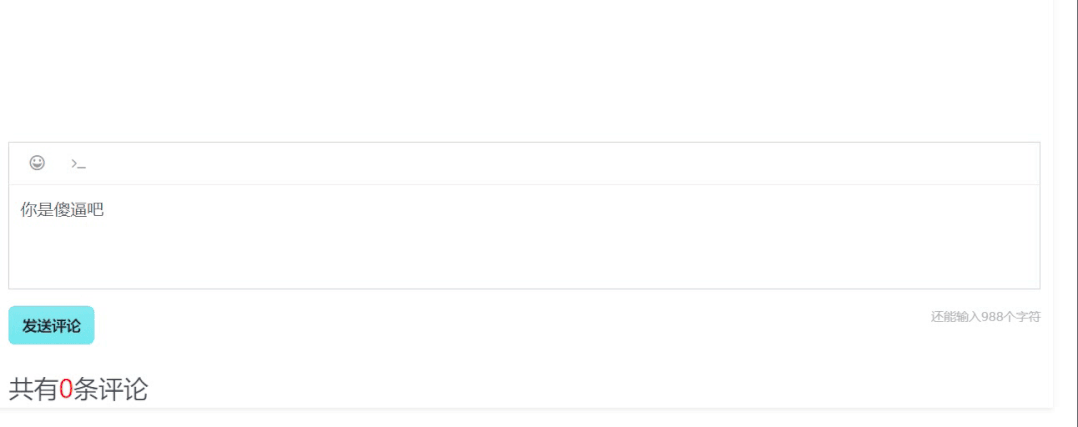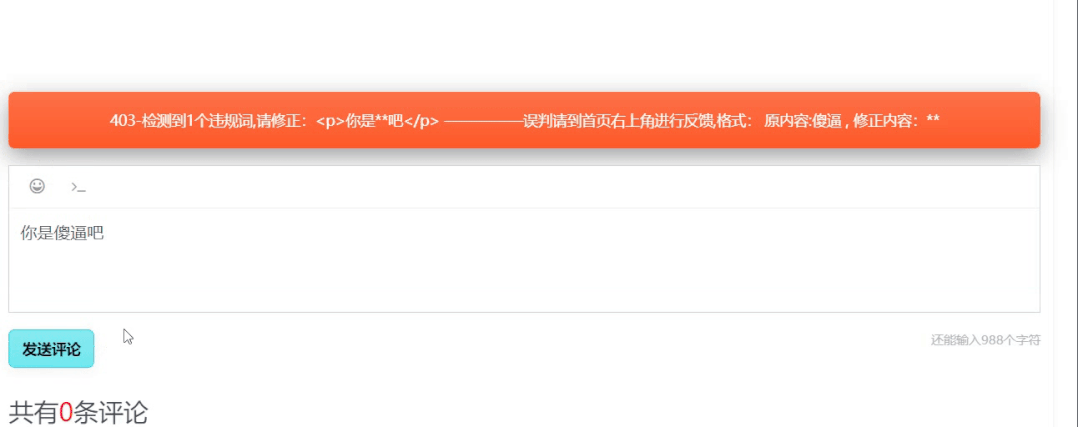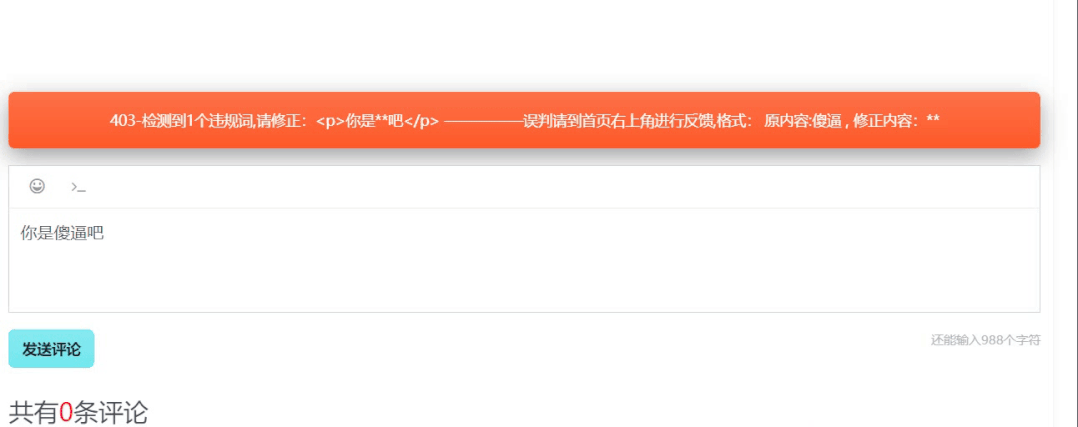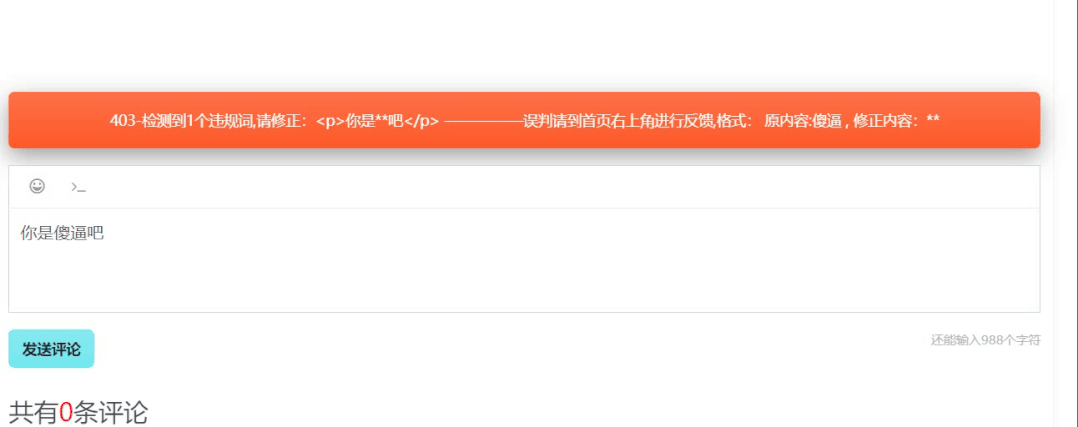
运行效果如下:
整体设计思路:
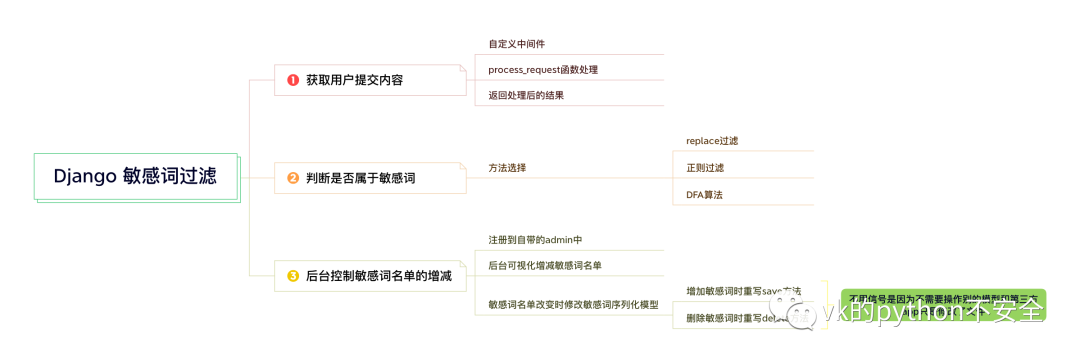 获取用户提交内容
获取用户提交内容通过自定义中间件的方式获取用户提交内容
要在请求来的时候就将恶意内容扼杀在摇篮中,使用process_request方法。获取到内容中如果有敏感词直接在中间件里返回处理内容即可。
新建一个py文件,自定义一个类,并且该类必须继承MiddlewareMixin,然后在process_request方法里写入自己的过滤方法。这个方法名字是不能改的
from django.utils.deprecation import MiddlewareMixin# 定义一个类继承MiddlewareMixin 并实现下面的方法,在这两个方法 中定义或者拦截对应的请求# 可以在中间件中添加用户认证和登录设置等信息class CustomMiddle(MiddlewareMixin):def process_request(self, request):print('过滤代码',request)
然后在settings.py里面注册该中间件即可使用,位置最好放在最后面,因为请求经过中间件是从上到下的,指不定自定义的中间件要依赖上面哪个中间件的结果
判断是否属于敏感词
这里有三种方法:
replace过滤
import timeold = time.time()with open("1", encoding='utf-8') as f:word = '可爱'for keyword in f:if keyword == word:print(word.replace(word, '*'))now = time.time()print(now - old,'replace方法')
这个文件1里存放的就是敏感词库
正则过滤
import reold = time.time()def check_filter(keywords, word):return re.sub("|".join(keywords), "***", word)with open("1", encoding='utf-8') as f:keywords=[]for i in f:keywords.append(i.strip('\n'))print(check_filter(keywords, word))now = time.time()print(now - old, '正则方法')
DFA算法(推荐)
这个算法的核心是把敏感词库构造成树结构,比如现在敏感词库有:“大家好,大人,帅气,大部队”
前两种方法就是循环词库每一行,然后对比,假设词库很大,这样逐行对比效率很低
DFA算法将敏感词生成一个下图这种结构:
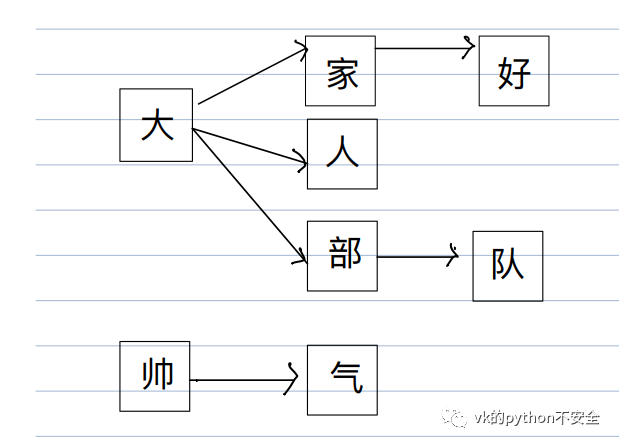
组成树形结构的好处就是可以减少索引次数,理论上只需要遍历⼀遍代检测的⽂本,看看是否在敏感词库中即可。
⽐如输⼊"我感觉我⼗分帅⽓",前⼏个均未在词库中匹配,全部pass掉。直到出现”帅”字时在⼦树中找到了,接下来继续遍历发现”⽓”字出现在⼦树的⼦节点 中,就说明帅⽓是敏感词。
在python中我们可以⽤字典储存敏感词词库树结构,理论上字典的查询时间复杂度为 O(1)。
我们把第⼀个字符作为字典的键,值为另⼀个字典以此类推,字典最后⼀项定义为{'\x00': 0}⽤来表示最后⼀个字符

定义一个类,并且初始化变量,生成树结构:
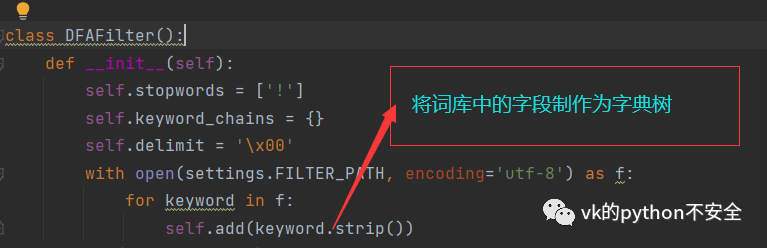
制作的字典如下图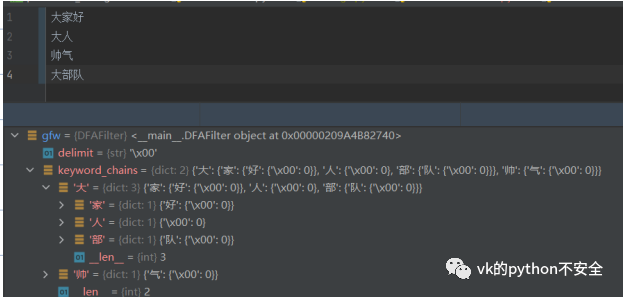
现在我们需要做的就是编写add⽅法的具体内容:
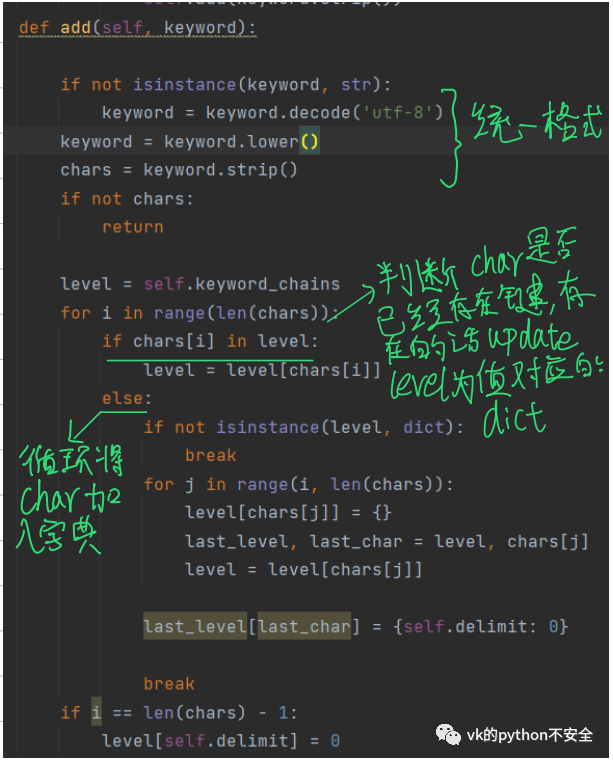
如“大家好”,循环结束后的self.key_chains应该变为:
{大:{家:{好:{}}}} 。当“大家好”处理完成后轮到“大人”时,发现“大”已经为字典的键,所以进入If 判断,update level 的value。
使level update为之前“大”对应的值,这仍旧是一个字典。接着进入else将“大”加到和“家”同级别的dict中
此时的结构如下图:
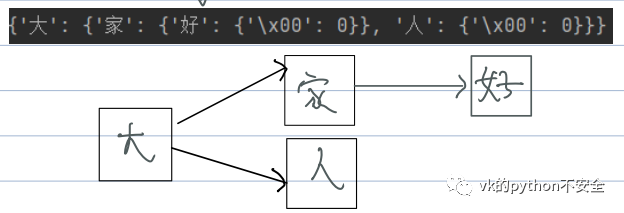
树字典构建好了接下来需要做的就是过滤了
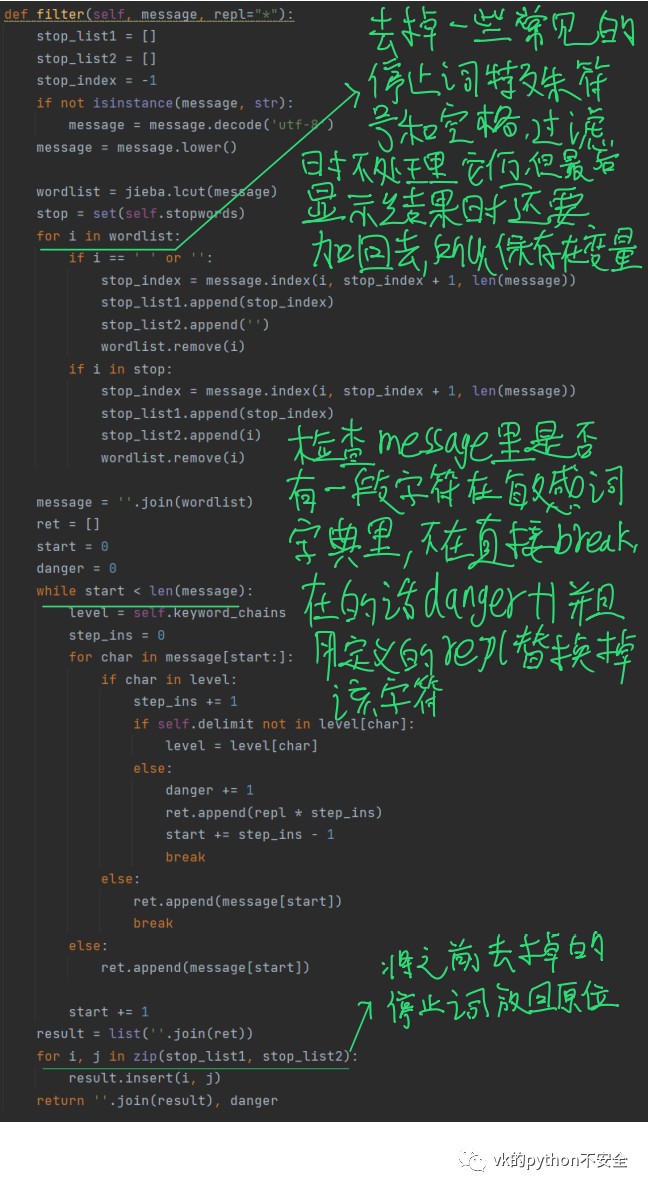
import jiebafrom django.conf import settingsimport timeclass DFAFilter():''' Filter Messages from keywordsUse DFA to keep algorithm perform constantlyf = DFAFilter()f.add("sexy")f.filter("hello sexy baby")hello **** baby'''def __init__(self):self.stopwords = ['!']self.keyword_chains = {}self.delimit = '\x00'with open(settings.FILTER_PATH, encoding='utf-8') as f:for keyword in f:self.add(keyword.strip())def add(self, keyword):if not isinstance(keyword, str):keyword = keyword.decode('utf-8')keyword = keyword.lower()chars = keyword.strip()if not chars:returnlevel = self.keyword_chainsfor i in range(len(chars)):if chars[i] in level:level = level[chars[i]]else:if not isinstance(level, dict):breakfor j in range(i, len(chars)):level[chars[j]] = {}last_level, last_char = level, chars[j]level = level[chars[j]]last_level[last_char] = {self.delimit: 0}breakif i == len(chars) - 1:level[self.delimit] = 0def filter(self, message, repl="*"):stop_list1 = []stop_list2 = []stop_index = -1if not isinstance(message, str):message = message.decode('utf-8')message = message.lower()wordlist = jieba.lcut(message)stop = set(self.stopwords)for i in wordlist:if i == ' ' or '':stop_index = message.index(i, stop_index + 1, len(message))stop_list1.append(stop_index)stop_list2.append('')wordlist.remove(i)if i in stop:stop_index = message.index(i, stop_index + 1, len(message))stop_list1.append(stop_index)stop_list2.append(i)wordlist.remove(i)message = ''.join(wordlist)ret = []start = 0danger = 0while start < len(message):level = self.keyword_chainsstep_ins = 0for char in message[start:]:if char in level:step_ins += 1if self.delimit not in level[char]:level = level[char]else:danger += 1ret.append(repl * step_ins)start += step_ins - 1breakelse:ret.append(message[start])print(ret)breakelse:ret.append(message[start])start += 1result = list(''.join(ret))for i, j in zip(stop_list1, stop_list2):result.insert(i, j)return ''.join(result), danger
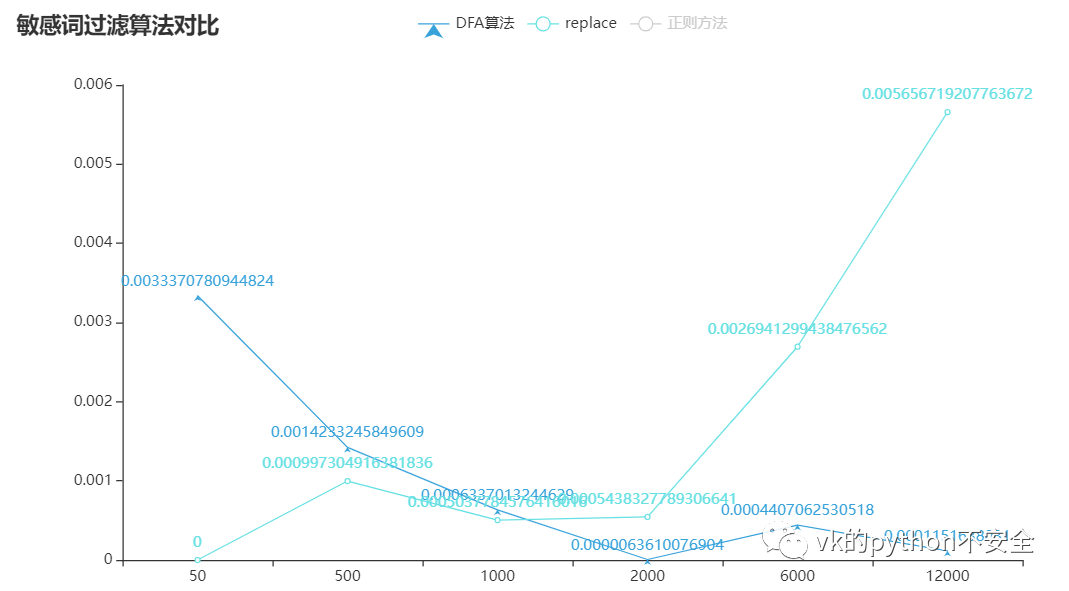
没有数据支持的对比都是诈骗:
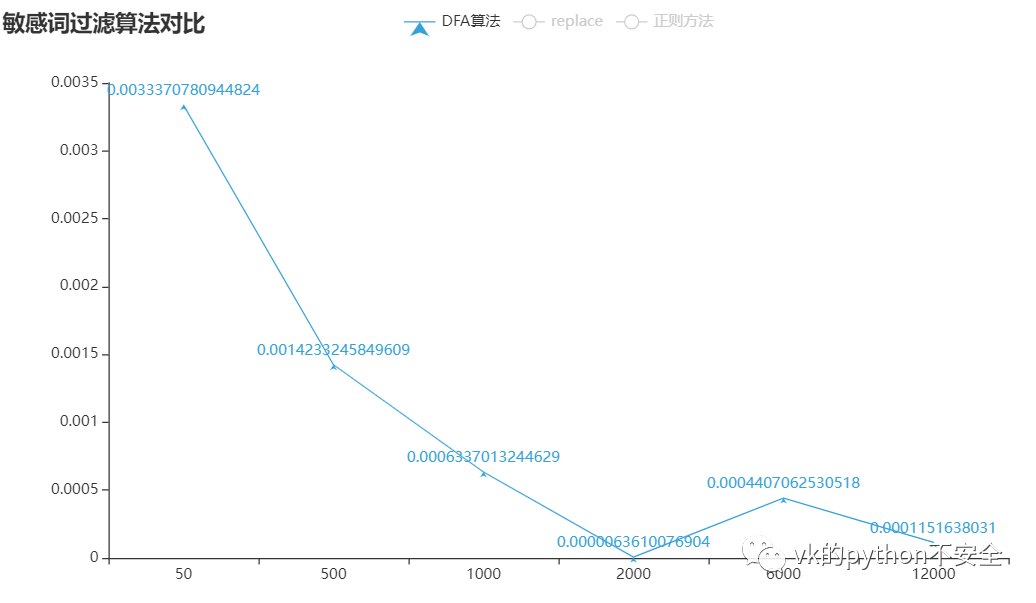
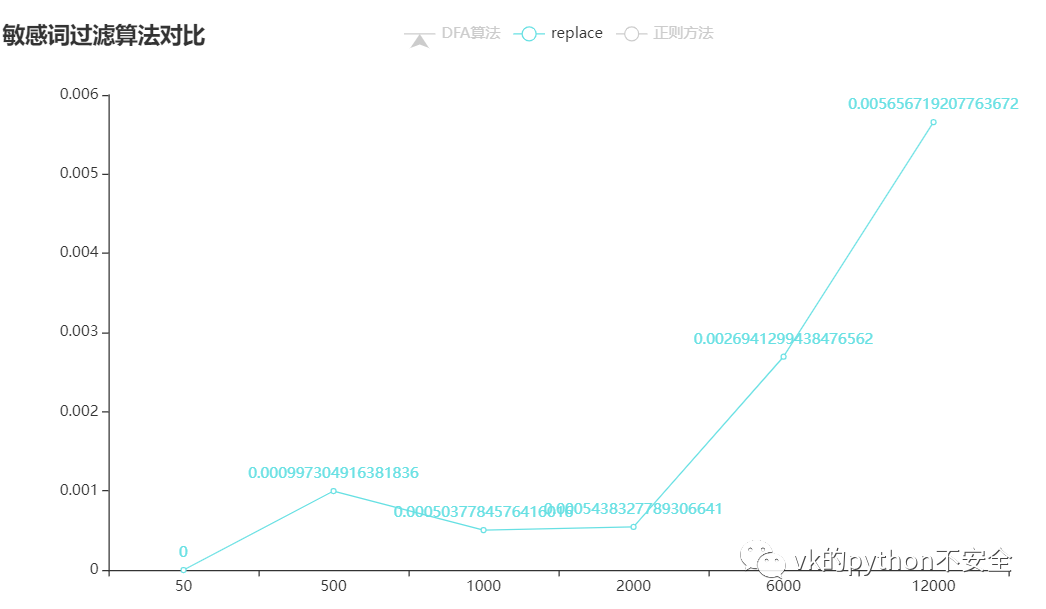
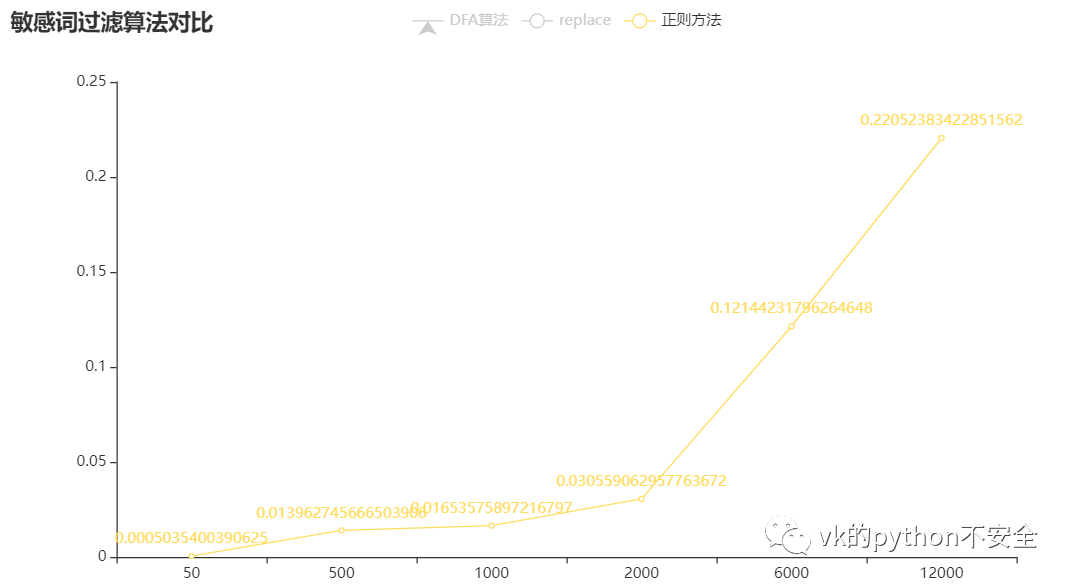
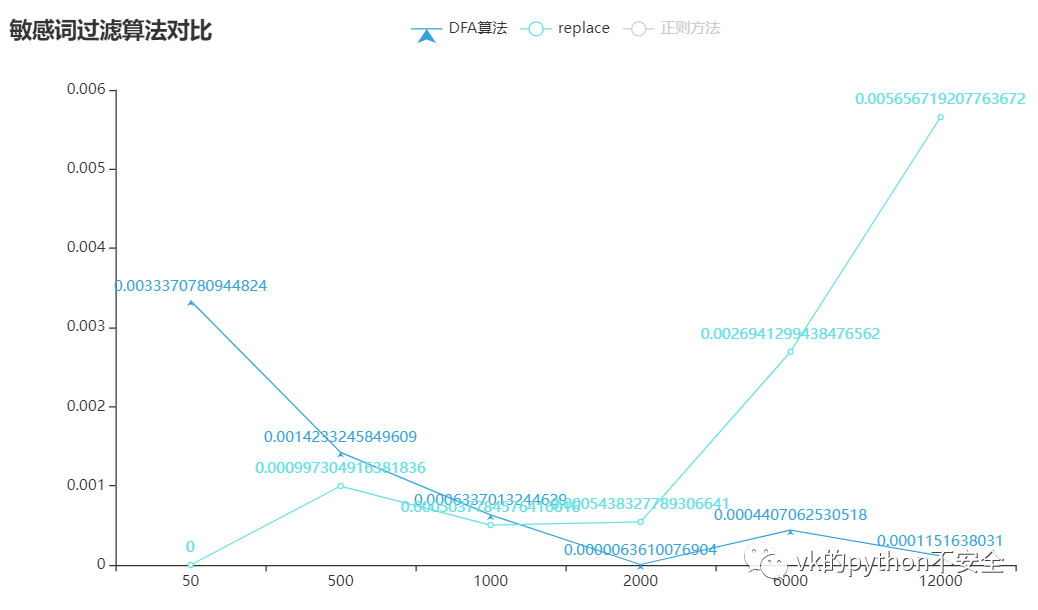
可以看到:正则方法所用的时间是随着词库的扩大而增大,replace是词库少于2000个词的时候表现良好,而DFA算法是大于2000时表现良好
后台控制敏感词名单的增减
DFA算法生成字典那里我们可以做出优化,不用每次运行都生成字典,而是把字典用pickle.dump持久话存储在内存中,用的时候再读,这样就快了很多。
把敏感词库的词所对应的字段在admin中注册就可以后台直接控制词库了,我就不再操作拿IP黑名单字段演示。
类似下图,这样我们就可以在后台管理是否启用特定的敏感词或者增删特定的敏感词了
持久化存储文件更新
当我们增加或删除了敏感词的时候,对应的持久化文件也应该发生改变,可以在model里面重写save和delete方法即可。

不用信号的原因是无需操作别的数据库模型和第三方app,只是重新pickle.dump update了一个新的持久化文件
单词数:349字符数:5138