
微信大数据挑战赛方案总结

微信大数据挑战赛是一个非常有意思的比赛,从5月20日一直到8月9日,我从初赛周周星到险些未进复赛,从复赛开始,又占得了一个相对靠前的名次,从躺平到惊起,又从惊起到躺平,是一次“魔幻”的竞赛之旅。今天老肥就来和大家分享本次比赛的方案总结,同时期待决赛大佬们的精彩方案开源。
赛事概要
本次比赛基于脱敏和采样后的数据信息,对于给定的一定数量到访过微信视频号“热门推荐”的用户, 根据这些用户在视频号内的历史14天的行为数据,通过算法在测试集上预测出这些用户在第15天对于不同视频内容的互动行为(包括点赞、点击头像、收藏、转发等)的发生概率。初赛以4个行为预测结果的加权uAUC值进行评分,复赛以7个行为的预测结果的加权uAUC值进行评分。
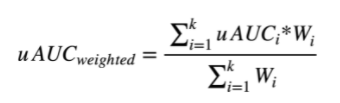
解决方案
复赛的方案采用的是一个相对简单的NN方案,采用的模型为多任务学习模型MMoE, 一共采用了原始特征 + 34维衍生特征,原始特征包括userid、feedid等6个id特征、视频播放时长特征以及4个标签关键词特征,衍生特征包括16维Word2Vec特征、6维视频类别特征、6维用户类别特征、6维视频作者类别特征。
原始特征方面,对于id特征,以0进行空值填充;对于标签以及关键词这种不定长类型的特征,我直接采用了截断的方法,取对应前5个标签或是关键词送入模型,其实这么取的原因主要有两点,一是内存的限制,二是通过初赛的模型训练,我发现单独取每个标签列表的第一位第二位就可以取得较好的效果(可能是靠前的标签比较重要);对于数值特征视频播放时长,我做了取对数的处理方法。
衍生特征方面,我对用户的视频播放序列做了Word2Vec来获取每个用户的embedding,这里有致命缺陷的一点,我没有使用初赛以及复赛的测试集来做Word2Vec(根据比赛群里大佬的消融实验采用测试集的Word2Vec可以比不采用的提升整整1.5个百分点!!)。我还采用了视频的512维embedding向量做Kmeans聚类,指定6个规模不同的K值,给出每个视频的类别特征,视频作者类别则是采用作者发布视频的embedding向量均值做聚类,用户类别则是采用用户所观看的视频的embedding向量均值做聚类。
模型结构方面,其实我也尝试了多种模型,DeepFM、DIN等CTR模型,CGC、PLE等多任务学习模型,还在MMoE模型上进行魔改,比如添加多层attention layer、加入FM等等,最终这些模型的效果较为一般,可能是没有进行细致的参数调整的原因。
模型训练方面,采用前十三天训练、十四天验证的方法做离线验证,采用全量十四天数据来做线上验证,总体而言,线上线下较为一致,提升是同步的。最后我采用多种子平均融合的方法以提升成绩。
本次竞赛云集了很大部分赛圈大佬,哪怕只是看看群聊,也能够有所感悟,提升自身水平。老肥也是非常幸运能坐上通往复赛的末班车,最终在复赛中侥幸取得国一,期待明年能够取得更好的成绩。
以上就是本文的全部内容了,本文的所有代码已经上传,在后台回复「微信」即可。
——END——