
手机拍视频最怕抖,只能靠AI拯救了
视频画面的稳定与否,很大程度上影响着观感的舒适度!如何补偿视频抖动,拯救手抖党,来自台湾大学、谷歌等研究机构的学者,提出了防抖新算法,视频拍摄——稳。


将神经渲染技术应用于视频稳定中,以缓解对流不准确的敏感性问题;
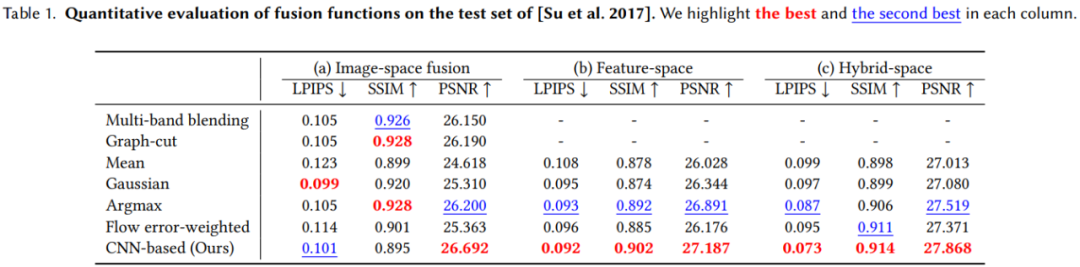
提出了一种混合融合机制,用于在特征和图像级别上组合来自多帧的信息,并通过消融研究系统地验证了各种设计选择;
在两个公共数据集上展示了与代表性视频稳定技术相比较而言,该研究所提出的方法具有良好性能。
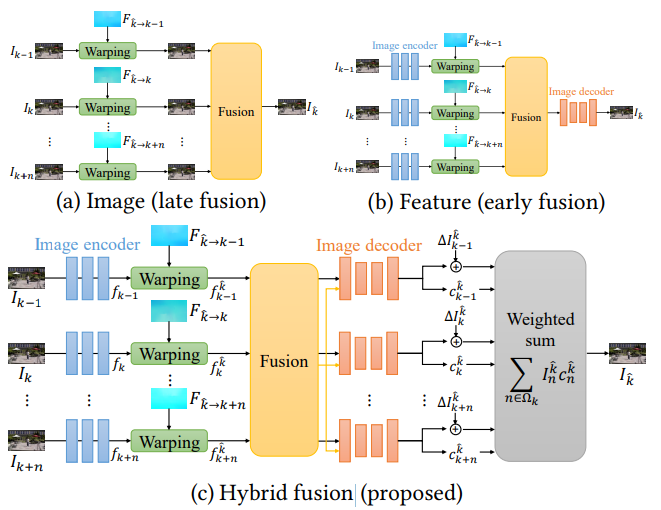
传统的全景图像拼接(或基于图像的渲染)方法通常在图像级别对扭曲(稳定)的图像进行融合。在对齐比较准确时图像级融合效果良好,但在流估计不可靠时可能产生混合伪影;
可以将图像编码为抽象的 CNN 特征,在特征空间中进行融合,并学习到一个解码器,可将融合后的特征转换为输出帧。这种方法对流不准确性具有较好的鲁棒性,但通常会产生过度模糊的图像;
该研究提出的算法结合了这两种策略的优点。首先提取抽象的图像特征(公式(6));然后融合多帧扭曲的特征。对于每一个源帧,将融合后的特征映射和各个扭曲的特征一起解码为输出帧和相关的置信度映射。最后使用公式(8)中生成图像的加权平均值生成最终输出帧。
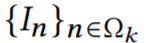 ,使其与目标帧
,使其与目标帧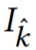 对齐。因为已经有了从目标帧到关键帧的扭曲场
对齐。因为已经有了从目标帧到关键帧的扭曲场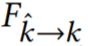 ,以及从关键帧到相邻帧
,以及从关键帧到相邻帧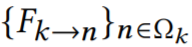 的估计光流,然后可以通过链接流向量来计算从目标帧到相邻帧
的估计光流,然后可以通过链接流向量来计算从目标帧到相邻帧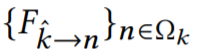 的扭曲场。因此可以使用向后扭曲来扭曲相邻帧 I_n 以对齐目标帧
的扭曲场。因此可以使用向后扭曲来扭曲相邻帧 I_n 以对齐目标帧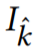 。
。


© THE END
转载请联系 机器之心 公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论