
Pod 拓扑分布约束使用及调度原理
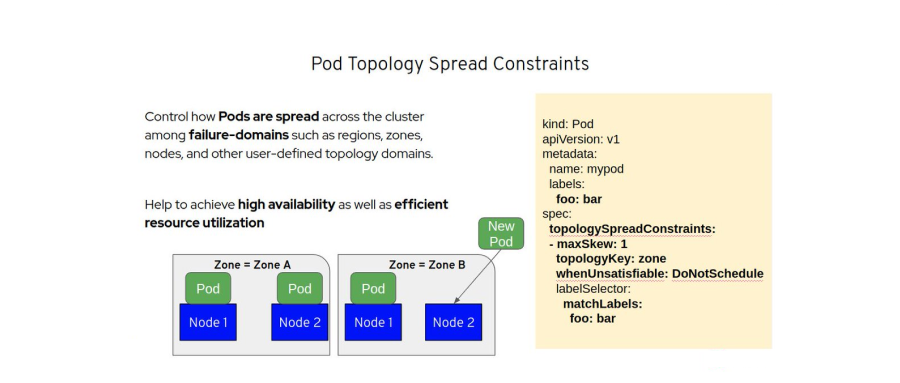
在 k8s 集群调度中,“亲和性”相关的概念本质上都是控制 Pod 如何被调度 - 堆叠或是打散。目前 k8s 提供了 podAffinity 以及 podAntiAffinity 两个特性对 Pod 在不同拓扑域的分布进行了一些控制,podAffinity 可以将无数个 Pod 调度到特定的某一个拓扑域,这是堆叠的体现;podAntiAffinity 则可以控制一个拓扑域只存在一个 Pod,这是打散的体现。但这两种情况都太极端了,在不少场景下都无法达到理想的效果,例如为了实现容灾和高可用,将业务 Pod 尽可能均匀的分布在不同可用区就很难实现。
PodTopologySpread 特性的提出正是为了对 Pod 的调度分布提供更精细的控制,以提高服务可用性以及资源利用率,PodTopologySpread 由 EvenPodsSpread 特性门所控制,在 v1.16 版本第一次发布,并在 v1.18 版本进入 beta 阶段默认启用。再了解这个插件是如何实现之前,我们首先需要搞清楚这个特性是如何使用的。
使用规范
在 Pod 的 Spec 规范中新增了一个 topologySpreadConstraints 字段:
spec:
topologySpreadConstraints:
- maxSkew: <integer>
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
由于这个新增的字段是在 Pod spec 层面添加,因此更高层级的控制 (Deployment、DaemonSet、StatefulSet) 也能使用 PodTopologySpread 功能。
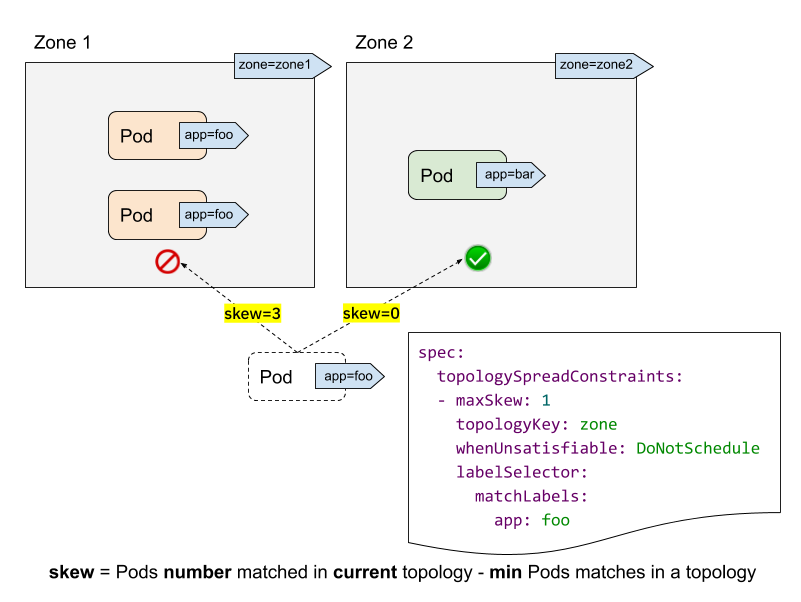
让我们结合上图来理解 topologySpreadConstraints 中各个字段的含义和作用:
labelSelector: 用来查找匹配的 Pod,我们能够计算出每个拓扑域中匹配该 label selector 的 Pod 数量,在上图中,假如 label selector 是 app:foo,那么 zone1 的匹配个数为 2, zone2 的匹配个数为 0。topologyKey: 是 Node label 的 key,如果两个 Node 的 label 同时具有该 key 并且 label 值相同,就说它们在同一个拓扑域。在上图中,指定 topologyKey 为 zone, 具有 zone=zone1标签的 Node 被分在一个拓扑域,具有zone=zone2标签的 Node 被分在另一个拓扑域。maxSkew: 描述了 Pod 在不同拓扑域中不均匀分布的最大程度,maxSkew 的取值必须大于 0。每个拓扑域都有一个 skew,计算的公式是: skew[i] = 拓扑域[i]中匹配的 Pod 个数 - min{其他拓扑域中匹配的 Pod 个数}。在上图中,我们新建一个带有app=foo标签的 Pod:如果该 Pod 被调度到 zone1,那么 zone1 中 Node 的 skew 值变为 3,zone2 中 Node 的 skew 值变为 0 (zone1 有 3 个匹配的 Pod,zone2 有 0 个匹配的 Pod ) 如果该 Pod 被调度到 zone2,那么 zone1 中 Node 的 skew 值变为 1,zone2 中 Node 的 skew 值变为 0 (zone2 有 1 个匹配的 Pod,拥有全局最小匹配 Pod 数的拓扑域正是 zone2 自己 ) whenUnsatisfiable: 描述了如果 Pod 不满足分布约束条件该采取何种策略: DoNotSchedule (默认) 告诉调度器不要调度该 Pod,因此也可以叫作硬策略; ScheduleAnyway 告诉调度器根据每个 Node 的 skew 值打分排序后仍然调度,因此也可以叫作软策略。
下面我们用两个实际的示例来进一步说明。
单个 TopologySpreadConstraint
假设你拥有一个 4 节点集群,其中标记为 foo:bar 的 3 个 Pod 分别位于 node1、node2 和 node3 中:
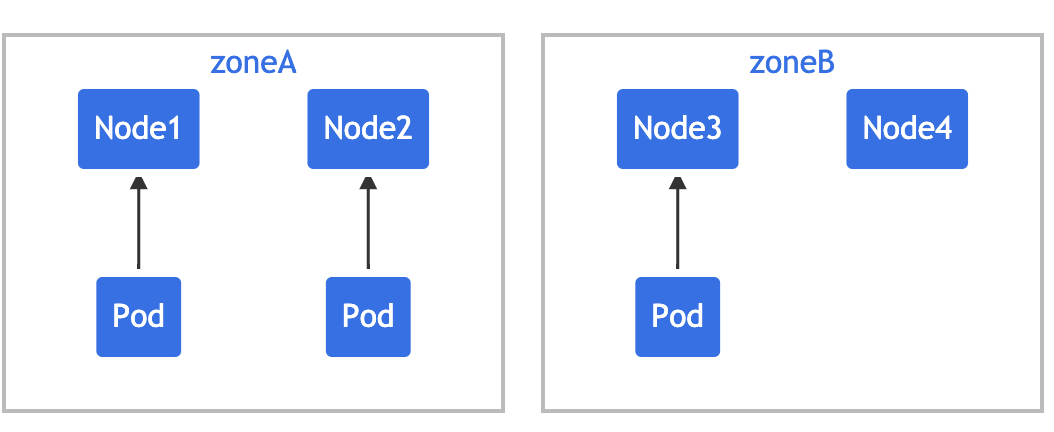
如果希望新来的 Pod 均匀分布在现有的可用区域,则可以按如下设置其约束:
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: k8s.gcr.io/pause:3.1
topologyKey: zone 意味着均匀分布将只应用于存在标签键值对为 zone:<any value> 的节点。 whenUnsatisfiable: DoNotSchedule 告诉调度器如果新的 Pod 不满足约束,则不可调度。如果调度器将新的 Pod 放入 "zoneA",Pods 分布将变为 [3, 1],因此实际的偏差为 2(3 - 1),这违反了 maxSkew: 1 的约定。此示例中,新 Pod 只能放置在 "zoneB" 上:

或者
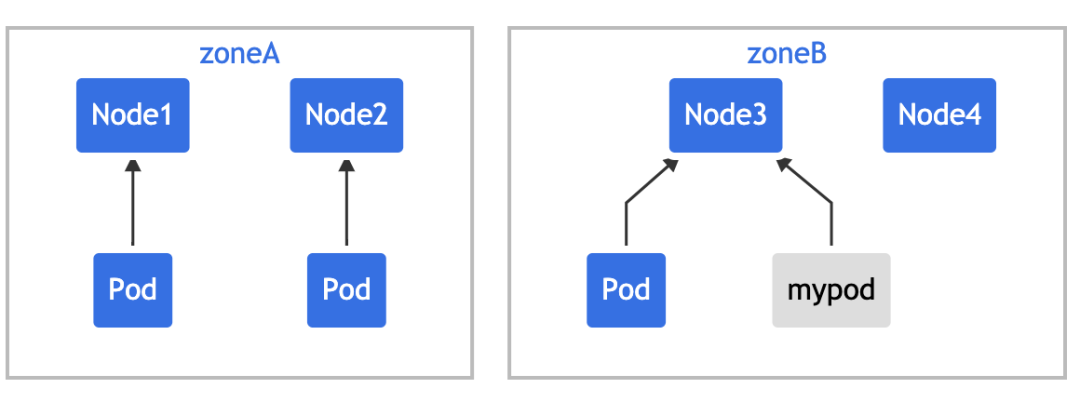
你可以调整 Pod 约束以满足各种要求:
将 maxSkew更改为更大的值,比如 "2",这样新的 Pod 也可以放在 "zoneA" 上。将 topologyKey更改为 "node",以便将 Pod 均匀分布在节点上而不是区域中。在上面的例子中,如果maxSkew保持为 "1",那么传入的 Pod 只能放在 "node4" 上。将 whenUnsatisfiable: DoNotSchedule更改为whenUnsatisfiable: ScheduleAnyway, 以确保新的 Pod 可以被调度。
多个 TopologySpreadConstraint
上面是单个 Pod 拓扑分布约束的情况,下面的例子建立在前面例子的基础上来对多个 Pod 拓扑分布约束进行说明。假设你拥有一个 4 节点集群,其中 3 个标记为 foo:bar 的 Pod 分别位于 node1、node2 和 node3 上:
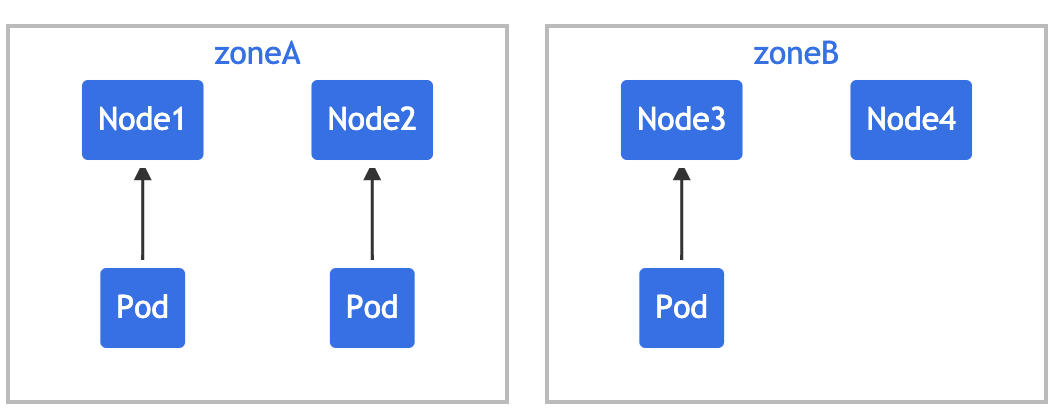
可以使用 2 个 TopologySpreadConstraint 来控制 Pod 在 区域和节点两个维度上的分布:
# two-constraints.yaml
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
- maxSkew: 1
topologyKey: node
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: k8s.gcr.io/pause:3.1
在这种情况下,为了匹配第一个约束,新的 Pod 只能放置在 "zoneB" 中;而在第二个约束中, 新的 Pod 只能放置在 "node4" 上,最后两个约束的结果加在一起,唯一可行的选择是放置 在 "node4" 上。
多个约束之间可能存在冲突,假设有一个跨越 2 个区域的 3 节点集群:
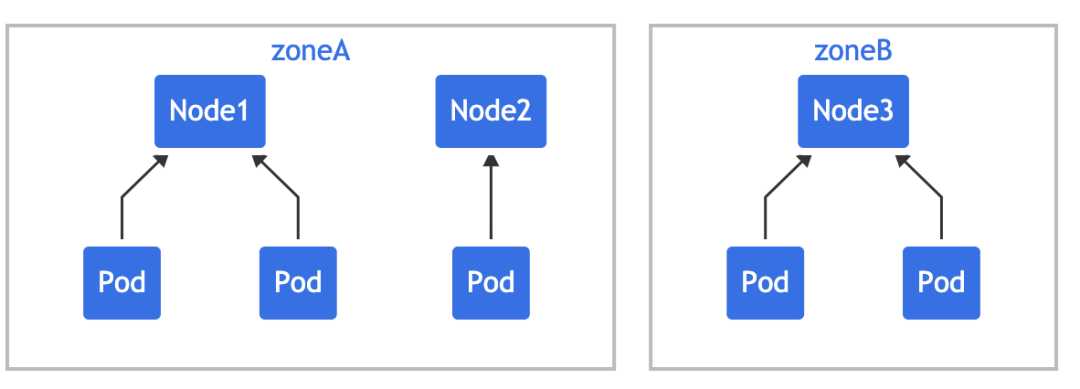
如果对集群应用 two-constraints.yaml,会发现 "mypod" 处于 Pending 状态,这是因为为了满足第一个约束,"mypod" 只能放在 "zoneB" 中,而第二个约束要求 "mypod" 只能放在 "node2" 上,Pod 调度无法满足这两种约束,所以就冲突了。
为了克服这种情况,你可以增加 maxSkew 或修改其中一个约束,让其使用 whenUnsatisfiable: ScheduleAnyway。
集群默认约束
除了为单个 Pod 设置拓扑分布约束,也可以为集群设置默认的拓扑分布约束,默认拓扑分布约束在且仅在以下条件满足 时才会应用到 Pod 上:
Pod 没有在其 .spec.topologySpreadConstraints设置任何约束;Pod 隶属于某个服务、副本控制器、ReplicaSet 或 StatefulSet。
你可以在 调度方案(Schedulingg Profile)中将默认约束作为 PodTopologySpread 插件参数的一部分来进行设置。约束的设置采用和前面 Pod 中的规范一致,只是 labelSelector 必须为空。配置的示例可能看起来像下面这个样子:
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
profiles:
- pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
defaultingType: List
预选
前面了解了如何使用 Pod 拓扑分布约束,接下来我们就可以来看下调度器中对应插件是如何实现的了。
PreFilter
首先也是去查看这个插件的 PreFilter 函数的实现:
// pkg/scheduler/framework/plugins/podtopologyspread/filtering.go
// 在 prefilter 扩展点调用
func (pl *PodTopologySpread) PreFilter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod) *framework.Status {
s, err := pl.calPreFilterState(pod)
if err != nil {
return framework.NewStatus(framework.Error, err.Error())
}
cycleState.Write(preFilterStateKey, s)
return nil
}
这里最核心的就是 calPreFilterState 函数,该函数用来计算描述如何在拓扑域上传递 Pod 的 preFilterState 状态数据,在了解该函数如何实现之前,我们需要先弄明白 preFilterState 的定义:
// pkg/scheduler/framework/plugins/podtopologyspread/common.go
type topologyPair struct {
key string
value string
}
// 拓扑分布约束定义
type topologySpreadConstraint struct {
MaxSkew int32
TopologyKey string
Selector labels.Selector
}
// pkg/scheduler/framework/plugins/podtopologyspread/filtering.go
const preFilterStateKey = "PreFilter" + Name
// preFilterState 在 PreFilter 处进行计算,在 Filter 中使用。
// 它结合了 TpKeyToCriticalPaths 和 TpPairToMatchNum 来表示。
// (1) 最少的 Pod 在每个分布约束上匹配的关键路径。
// (2) 在每个分布约束上匹配的 Pod 数量。
// 一个 nil preFilterState 表示没有设置(在 PreFilter 阶段);
// 一个空的 preFilterState 对象是一个合法的状态,在 PreFilter 阶段进行设置。
type preFilterState struct {
// demo: {{
// MaxSkew: 1,
// TopologyKey: "zone",
// Selector: ......,
// }}
Constraints []topologySpreadConstraint
// 这里记录2条关键路径,而不是所有的关键路径。
// criticalPaths[0].MatchNum 总是保持最小的匹配数。
// criticalPaths[1].MatchNum 总是大于或等于criticalPaths[0].MatchNum,但不能保证是第2个最小匹配数。
// demo: {
// "zone": {{"zone3", 0}, {"zone2", 2}},
// "node": {{"node-b", 1}, {"node-a", 2}},
// }
TpKeyToCriticalPaths map[string]*criticalPaths
// TpPairToMatchNum 以 topologyPair 为 key,匹配的 Pods 数量为 value 值
// demo: {key: "zone", value: "zone1"}: pointer.Int32Ptr(3),
// {key: "zone", value: "zone2"}: pointer.Int32Ptr(2),
// {key: "zone", value: "zone3"}: pointer.Int32Ptr(0),
// {key: "node", value: "node-a"}: pointer.Int32Ptr(2),
// {key: "node", value: "node-b"}: pointer.Int32Ptr(1),
TpPairToMatchNum map[topologyPair]*int32
}
type criticalPaths [2]struct {
// TopologyValue 拓扑Key对应的拓扑值
TopologyValue string
// MatchNum 匹配的 Pod 数量
MatchNum int32
}
preFilterState 中定义了3个属性,在 PreFilter 处进行计算,在 Filter 中使用:
Constraints 用来保存定义的所有拓扑分布约束信息 TpKeyToCriticalPaths 是一个 map,以定义的拓扑 Key 为 Key,值是一个 criticalPaths指针,criticalPaths的定义不太好理解,是一个两个长度的结构体数组,结构体里面保存的是定义的拓扑对应的 Value 值以及该拓扑下匹配的 Pod 数量,而且需要注意的是这个数组的第一个元素中匹配数量是最小的(其实这里定义一个结构体就可以,只是为了保证获取到的是最小的匹配数量,就定义了两个,第二个是用来临时比较用的,真正有用的是第一个结构体)TpPairToMatchNum 同样是一个 map,对应的 Key 是 topologyPair,这个类型其实就是一个拓扑对,Values 值就是这个拓扑对下匹配的 Pod 数
这里可能不是很好理解,我们用测试代码中的一段测试用例来进行说明可能更好理解:
// pkg/scheduler/framework/plugins/podtopologyspread/filtering_test.go
{
name: "normal case with two spreadConstraints",
pod: st.MakePod().Name("p").Label("foo", "").
SpreadConstraint(1, "zone", v1.DoNotSchedule, fooSelector).
SpreadConstraint(1, "node", v1.DoNotSchedule, fooSelector).
Obj(),
nodes: []*v1.Node{
st.MakeNode().Name("node-a").Label("zone", "zone1").Label("node", "node-a").Obj(),
st.MakeNode().Name("node-b").Label("zone", "zone1").Label("node", "node-b").Obj(),
st.MakeNode().Name("node-x").Label("zone", "zone2").Label("node", "node-x").Obj(),
st.MakeNode().Name("node-y").Label("zone", "zone2").Label("node", "node-y").Obj(),
},
existingPods: []*v1.Pod{
st.MakePod().Name("p-a1").Node("node-a").Label("foo", "").Obj(),
st.MakePod().Name("p-a2").Node("node-a").Label("foo", "").Obj(),
st.MakePod().Name("p-b1").Node("node-b").Label("foo", "").Obj(),
st.MakePod().Name("p-y1").Node("node-y").Label("foo", "").Obj(),
st.MakePod().Name("p-y2").Node("node-y").Label("foo", "").Obj(),
st.MakePod().Name("p-y3").Node("node-y").Label("foo", "").Obj(),
st.MakePod().Name("p-y4").Node("node-y").Label("foo", "").Obj(),
},
want: &preFilterState{
Constraints: []topologySpreadConstraint{
{
MaxSkew: 1,
TopologyKey: "zone",
Selector: mustConvertLabelSelectorAsSelector(t, fooSelector),
},
{
MaxSkew: 1,
TopologyKey: "node",
Selector: mustConvertLabelSelectorAsSelector(t, fooSelector),
},
},
TpKeyToCriticalPaths: map[string]*criticalPaths{
"zone": {{"zone1", 3}, {"zone2", 4}},
"node": {{"node-x", 0}, {"node-b", 1}},
},
TpPairToMatchNum: map[topologyPair]*int32{
{key: "zone", value: "zone1"}: pointer.Int32Ptr(3),
{key: "zone", value: "zone2"}: pointer.Int32Ptr(4),
{key: "node", value: "node-a"}: pointer.Int32Ptr(2),
{key: "node", value: "node-b"}: pointer.Int32Ptr(1),
{key: "node", value: "node-x"}: pointer.Int32Ptr(0),
{key: "node", value: "node-y"}: pointer.Int32Ptr(4),
},
},
}
理解了 preFilterState 的定义,接下来我们就可以来分析 calPreFilterState 函数的实现了:
// pkg/scheduler/framework/plugins/podtopologyspread/filtering.go
func (pl *PodTopologySpread) calPreFilterState(pod *v1.Pod) (*preFilterState, error) {
// 获取所有节点信息
allNodes, err := pl.sharedLister.NodeInfos().List()
if err != nil {
return nil, fmt.Errorf("listing NodeInfos: %v", err)
}
var constraints []topologySpreadConstraint
if len(pod.Spec.TopologySpreadConstraints) > 0 {
// 如果 Pod 中配置了 TopologySpreadConstraints,转换成这里的 topologySpreadConstraint 对象
constraints, err = filterTopologySpreadConstraints(pod.Spec.TopologySpreadConstraints, v1.DoNotSchedule)
if err != nil {
return nil, fmt.Errorf("obtaining pod's hard topology spread constraints: %v", err)
}
} else {
// 获取默认配置的拓扑分布约束
constraints, err = pl.defaultConstraints(pod, v1.DoNotSchedule)
if err != nil {
return nil, fmt.Errorf("setting default hard topology spread constraints: %v", err)
}
}
// 没有约束,直接返回
if len(constraints) == 0 {
return &preFilterState{}, nil
}
// 初始化 preFilterState 状态
s := preFilterState{
Constraints: constraints,
TpKeyToCriticalPaths: make(map[string]*criticalPaths, len(constraints)),
TpPairToMatchNum: make(map[topologyPair]*int32, sizeHeuristic(len(allNodes), constraints)),
}
for _, n := range allNodes {
node := n.Node()
if node == nil {
klog.Error("node not found")
continue
}
// 如果定义了 NodeAffinity 或者 NodeSelector,则应该分布到这些过滤器的节点
if !helper.PodMatchesNodeSelectorAndAffinityTerms(pod, node) {
continue
}
// 保证现在的节点的标签包含 Constraints 中的所有 topologyKeys
if !nodeLabelsMatchSpreadConstraints(node.Labels, constraints) {
continue
}
// 根据约束初始化拓扑对
for _, c := range constraints {
pair := topologyPair{key: c.TopologyKey, value: node.Labels[c.TopologyKey]}
s.TpPairToMatchNum[pair] = new(int32)
}
}
processNode := func(i int) {
nodeInfo := allNodes[i]
node := nodeInfo.Node()
// 计算每一个拓扑对下匹配的 Pod 总数
for _, constraint := range constraints {
pair := topologyPair{key: constraint.TopologyKey, value: node.Labels[constraint.TopologyKey]}
tpCount := s.TpPairToMatchNum[pair]
if tpCount == nil {
continue
}
// 计算约束的拓扑域中匹配的 Pod 数
count := countPodsMatchSelector(nodeInfo.Pods, constraint.Selector, pod.Namespace)
atomic.AddInt32(tpCount, int32(count))
}
}
parallelize.Until(context.Background(), len(allNodes), processNode)
// 计算每个拓扑的最小匹配度(保证第一个Path下是最小的值)
for i := 0; i < len(constraints); i++ {
key := constraints[i].TopologyKey
s.TpKeyToCriticalPaths[key] = newCriticalPaths()
}
for pair, num := range s.TpPairToMatchNum {
s.TpKeyToCriticalPaths[pair.key].update(pair.value, *num)
}
return &s, nil
}
// update 函数就是来保证 criticalPaths 中的第一个元素是最小的 Pod 匹配数
func (p *criticalPaths) update(tpVal string, num int32) {
// first verify if `tpVal` exists or not
i := -1
if tpVal == p[0].TopologyValue {
i = 0
} else if tpVal == p[1].TopologyValue {
i = 1
}
if i >= 0 {
// `tpVal` exists
p[i].MatchNum = num
if p[0].MatchNum > p[1].MatchNum {
// swap paths[0] and paths[1]
p[0], p[1] = p[1], p[0]
}
} else {
// `tpVal` doesn't exist
if num < p[0].MatchNum {
// update paths[1] with paths[0]
p[1] = p[0]
// update paths[0]
p[0].TopologyValue, p[0].MatchNum = tpVal, num
} else if num < p[1].MatchNum {
// update paths[1]
p[1].TopologyValue, p[1].MatchNum = tpVal, num
}
}
}
首先判断 Pod 中是否定义了 TopologySpreadConstraint ,如果定义了就获取转换成 preFilterState 中的 Constraints,如果没有定义需要查看是否为调度器配置了默认的拓扑分布约束,如果都没有这就直接返回了。
然后循环所有的节点,先根据 NodeAffinity 或者 NodeSelector 进行过滤,然后根据约束中定义的 topologyKeys 过滤节点。
接着计算每个节点下的拓扑对匹配的 Pod 数量,存入 TpPairToMatchNum 中,最后就是要把所有约束中匹配的 Pod 数量最小(或稍大)的放入 TpKeyToCriticalPaths 中保存起来。整个 preFilterState 保存下来传递到后续的插件中使用,比如在 filter 扩展点中同样也注册了这个插件,所以我们可以来查看下在 filter 中是如何实现的。
Filter
在 preFilter 阶段将 Pod 拓扑分布约束的相关信息存入到了 CycleState 中,下面在 filter 阶段中就可以来直接使用这些数据了:
// pkg/scheduler/framework/plugins/podtopologyspread/filtering.go
func (pl *PodTopologySpread) Filter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
node := nodeInfo.Node()
if node == nil {
return framework.NewStatus(framework.Error, "node not found")
}
// 获取 preFilsterState
s, err := getPreFilterState(cycleState)
if err != nil {
return framework.NewStatus(framework.Error, err.Error())
}
// 如果没有拓扑匹配的数量或者没有约束,则直接返回
if len(s.TpPairToMatchNum) == 0 || len(s.Constraints) == 0 {
return nil
}
podLabelSet := labels.Set(pod.Labels)
// 循环Pod设置的约束
for _, c := range s.Constraints {
tpKey := c.TopologyKey // 拓扑Key
// 检查当前节点是否有的对应拓扑Key
tpVal, ok := node.Labels[c.TopologyKey]
if !ok {
klog.V(5).Infof("node '%s' doesn't have required label '%s'", node.Name, tpKey)
return framework.NewStatus(framework.UnschedulableAndUnresolvable, ErrReasonNodeLabelNotMatch)
}
// 如果拓扑约束的selector匹配pod本身标签,则selfMatchNum=1
selfMatchNum := int32(0)
if c.Selector.Matches(podLabelSet) {
selfMatchNum = 1
}
// zone=zoneA zone=zoneB
// p p p p p
// 一个拓扑域
pair := topologyPair{key: tpKey, value: tpVal}
// 获取指定拓扑key的路径匹配数量
// [{zoneB 2}]
paths, ok := s.TpKeyToCriticalPaths[tpKey]
if !ok {
klog.Errorf("internal error: get paths from key %q of %#v", tpKey, s.TpKeyToCriticalPaths)
continue
}
// 获取最小匹配数量
minMatchNum := paths[0].MatchNum
matchNum := int32(0)
// 获取当前节点所在的拓扑域匹配的Pod数量
if tpCount := s.TpPairToMatchNum[pair]; tpCount != nil {
matchNum = *tpCount
}
// 如果匹配的Pod数量 + 1或者0 - 最小的匹配数量 > MaxSkew
// 则证明不满足约束条件
skew := matchNum + selfMatchNum - minMatchNum
if skew > c.MaxSkew {
klog.V(5).Infof("node '%s' failed spreadConstraint[%s]: MatchNum(%d) + selfMatchNum(%d) - minMatchNum(%d) > maxSkew(%d)", node.Name, tpKey, matchNum, selfMatchNum, minMatchNum, c.MaxSkew)
return framework.NewStatus(framework.Unschedulable, ErrReasonConstraintsNotMatch)
}
}
return nil
}
首先通过 CycleState 获取 preFilterState ,如果没有配置约束或者拓扑对匹配数量为0就直接返回了。
然后循环定义的拓扑约束,先检查当前节点是否有对应的 TopologyKey,没有就返回错误,然后判断拓扑对的分布程度是否大于 MaxSkew,判断方式为拓扑中匹配的 Pod 数量 + 1/0(如果 Pod 本身也匹配则为1) - 最小的 Pod 匹配数量 > MaxSkew ,这个也是前面我们在关于 Pod 拓扑分布约束中的 maxSkew 的含义描述的意思**。**
优选
PodTopologySpread 除了在预选阶段会用到,在打分阶段其实也会用到,在默认的插件注册函数中可以看到:
func getDefaultConfig() *schedulerapi.Plugins {
return &schedulerapi.Plugins{
......
PreFilter: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: podtopologyspread.Name},
......
},
},
Filter: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: podtopologyspread.Name},
......
},
},
......
PreScore: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: podtopologyspread.Name},
......
},
},
Score: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
// Weight is doubled because:
// - This is a score coming from user preference.
// - It makes its signal comparable to NodeResourcesLeastAllocated.
{Name: podtopologyspread.Name, Weight: 2},
......
},
},
......
}
}
PreScore 与 Score
同样首先需要调用 PreScore 函数进行打分前的一些准备,把打分的数据存储起来:
// pkg/scheduler/framework/plugins/podtopologyspread/scoring.go
// preScoreState 在 PreScore 时计算,在 Score 时使用。
type preScoreState struct {
// 定义的约束
Constraints []topologySpreadConstraint
// IgnoredNodes 是一组 miss 掉 Constraints[*].topologyKey 的节点名称
IgnoredNodes sets.String
// TopologyPairToPodCounts 以 topologyPair 为键,以匹配的 Pod 数量为值
TopologyPairToPodCounts map[topologyPair]*int64
// TopologyNormalizingWeight 是我们给每个拓扑的计数的权重
// 这使得较小的拓扑的 Pod 数不会被较大的稀释
TopologyNormalizingWeight []float64
}
// initPreScoreState 迭代 "filteredNodes" 来过滤掉没有设置 topologyKey 的节点,并进行初始化:
// 1) s.TopologyPairToPodCounts: 以符合条件的拓扑对和节点名称为键
// 2) s.IgnoredNodes: 不应得分的节点集合
// 3) s.TopologyNormalizingWeight: 根据拓扑结构中的数值数量给予每个约束的权重
func (pl *PodTopologySpread) initPreScoreState(s *preScoreState, pod *v1.Pod, filteredNodes []*v1.Node) error {
var err error
// 将 Pod 或者默认定义的约束转换到 Constraints 中
if len(pod.Spec.TopologySpreadConstraints) > 0 {
s.Constraints, err = filterTopologySpreadConstraints(pod.Spec.TopologySpreadConstraints, v1.ScheduleAnyway)
if err != nil {
return fmt.Errorf("obtaining pod's soft topology spread constraints: %v", err)
}
} else {
s.Constraints, err = pl.defaultConstraints(pod, v1.ScheduleAnyway)
if err != nil {
return fmt.Errorf("setting default soft topology spread constraints: %v", err)
}
}
if len(s.Constraints) == 0 {
return nil
}
topoSize := make([]int, len(s.Constraints))
// 循环过滤节点得到的所有节点
for _, node := range filteredNodes {
if !nodeLabelsMatchSpreadConstraints(node.Labels, s.Constraints) {
// 后面打分时,没有全部所需 topologyKeys 的节点会被忽略
s.IgnoredNodes.Insert(node.Name)
continue
}
// 循环约束条件
for i, constraint := range s.Constraints {
if constraint.TopologyKey == v1.LabelHostname {
continue
}
// 拓扑对 初始化
pair := topologyPair{key: constraint.TopologyKey, value: node.Labels[constraint.TopologyKey]}
if s.TopologyPairToPodCounts[pair] == nil {
s.TopologyPairToPodCounts[pair] = new(int64)
topoSize[i]++ // 拓扑对数量+1
}
}
}
s.TopologyNormalizingWeight = make([]float64, len(s.Constraints))
for i, c := range s.Constraints {
sz := topoSize[i] // 拓扑约束数量
if c.TopologyKey == v1.LabelHostname {
// 如果 TopologyKey 是 Hostname 标签
sz = len(filteredNodes) - len(s.IgnoredNodes)
}
// 计算拓扑约束的权重
s.TopologyNormalizingWeight[i] = topologyNormalizingWeight(sz)
}
return nil
}
// topologyNormalizingWeight 根据拓扑存在的值的数量,计算拓扑的权重。
// 由于<size>至少为1(所有通过 Filters 的节点都在同一个拓扑结构中)
// 而k8s支持5k个节点,所以结果在区间<1.09,8.52>。
//
// 注意:当没有节点具有所需的拓扑结构时,<size> 也可以为0
// 然而在这种情况下,我们并不关心拓扑结构的权重
// 因为我们对所有节点都返回0分。
func topologyNormalizingWeight(size int) float64 {
return math.Log(float64(size + 2))
}
// PreScore 构建写入 CycleState 用于后面的 Score 和 NormalizeScore 使用
func (pl *PodTopologySpread) PreScore(
ctx context.Context,
cycleState *framework.CycleState,
pod *v1.Pod,
filteredNodes []*v1.Node,
) *framework.Status {
// 获取所有节点
allNodes, err := pl.sharedLister.NodeInfos().List()
if err != nil {
return framework.NewStatus(framework.Error, fmt.Sprintf("error when getting all nodes: %v", err))
}
// 过滤后的节点或者当前没有节点,表示没有节点用于打分
if len(filteredNodes) == 0 || len(allNodes) == 0 {
return nil
}
// 初始化 preScoreState 状态
state := &preScoreState{
IgnoredNodes: sets.NewString(),
TopologyPairToPodCounts: make(map[topologyPair]*int64),
}
err = pl.initPreScoreState(state, pod, filteredNodes)
if err != nil {
return framework.NewStatus(framework.Error, fmt.Sprintf("error when calculating preScoreState: %v", err))
}
// 如果传入的 pod 没有软拓扑传播约束,则返回
if len(state.Constraints) == 0 {
cycleState.Write(preScoreStateKey, state)
return nil
}
processAllNode := func(i int) {
nodeInfo := allNodes[i]
node := nodeInfo.Node()
if node == nil {
return
}
// (1) `node`应满足传入 pod 的 NodeSelector/NodeAffinity
// (2) 所有的 topologyKeys 都需要存在于`node`中。
if !pluginhelper.PodMatchesNodeSelectorAndAffinityTerms(pod, node) ||
!nodeLabelsMatchSpreadConstraints(node.Labels, state.Constraints) {
return
}
for _, c := range state.Constraints {
// 拓扑对
pair := topologyPair{key: c.TopologyKey, value: node.Labels[c.TopologyKey]}
// 如果当前拓扑对没有与任何候选节点相关联,则继续避免不必要的计算
// 每个节点的计数也被跳过,因为它们是在 Score 期间进行的
tpCount := state.TopologyPairToPodCounts[pair]
if tpCount == nil {
continue
}
// 计算节点上匹配的所有 Pod 数量
count := countPodsMatchSelector(nodeInfo.Pods, c.Selector, pod.Namespace)
atomic.AddInt64(tpCount, int64(count))
}
}
parallelize.Until(ctx, len(allNodes), processAllNode)
cycleState.Write(preScoreStateKey, state)
return nil
}
上面的处理逻辑整体比较简单,最重要的是计算每个拓扑约束的权重,这样才方便后面打分的时候计算分数,存入到 CycleState 后就可以了来查看具体的 Score 函数的实现了:
// pkg/scheduler/framework/plugins/podtopologyspread/scoring.go
// 在 Score 扩展点调用
func (pl *PodTopologySpread) Score(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod, nodeName string) (int64, *framework.Status) {
nodeInfo, err := pl.sharedLister.NodeInfos().Get(nodeName)
if err != nil || nodeInfo.Node() == nil {
return 0, framework.NewStatus(framework.Error, fmt.Sprintf("getting node %q from Snapshot: %v, node is nil: %v", nodeName, err, nodeInfo.Node() == nil))
}
node := nodeInfo.Node()
s, err := getPreScoreState(cycleState)
if err != nil {
return 0, framework.NewStatus(framework.Error, err.Error())
}
// 如果该节点不合格,则返回
if s.IgnoredNodes.Has(node.Name) {
return 0, nil
}
// 每出现一个 <pair>,当前节点就会得到一个 <matchSum> 的分数。
// 而我们将<matchSum>相加,作为这个节点的分数返回。
var score float64
for i, c := range s.Constraints {
if tpVal, ok := node.Labels[c.TopologyKey]; ok {
var cnt int64
if c.TopologyKey == v1.LabelHostname {
// 如果 TopologyKey 是 Hostname 则 cnt 为节点上匹配约束的 selector 的 Pod 数量
cnt = int64(countPodsMatchSelector(nodeInfo.Pods, c.Selector, pod.Namespace))
} else {
// 拓扑对下匹配的 Pod 数量
pair := topologyPair{key: c.TopologyKey, value: tpVal}
cnt = *s.TopologyPairToPodCounts[pair]
}
// 计算当前节点所得分数
score += scoreForCount(cnt, c.MaxSkew, s.TopologyNormalizingWeight[i])
}
}
return int64(score), nil
}
// scoreForCount 根据拓扑域中匹配的豆荚数量、约束的maxSkew和拓扑权重计算得分。
// `maxSkew-1`加到分数中,这样拓扑域之间的差异就会被淡化,控制分数对偏斜的容忍度。
func scoreForCount(cnt int64, maxSkew int32, tpWeight float64) float64 {
return float64(cnt)*tpWeight + float64(maxSkew-1)
}
在 Score 阶段就是为当前的节点去计算一个分数,这个分数就是通过拓扑对下匹配的 Pod 数量和对应权重的结果得到的一个分数,另外在计算分数的时候还加上了 maxSkew-1,这样可以淡化拓扑域之间的差异。
NormalizeScore
当所有节点的分数计算完成后,还需要调用 NormalizeScore 扩展插件:
// pkg/scheduler/framework/plugins/podtopologyspread/scoring.go
// NormalizeScore 在对所有节点打分过后调用
func (pl *PodTopologySpread) NormalizeScore(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod, scores framework.NodeScoreList) *framework.Status {
s, err := getPreScoreState(cycleState)
if err != nil {
return framework.NewStatus(framework.Error, err.Error())
}
if s == nil {
return nil
}
// 计算 <minScore> and <maxScore>
var minScore int64 = math.MaxInt64
var maxScore int64
for _, score := range scores {
if s.IgnoredNodes.Has(score.Name) {
continue
}
if score.Score < minScore {
minScore = score.Score
}
if score.Score > maxScore {
maxScore = score.Score
}
}
// 循环 scores({node score}集合)
for i := range scores {
nodeInfo, err := pl.sharedLister.NodeInfos().Get(scores[i].Name)
if err != nil {
return framework.NewStatus(framework.Error, err.Error())
}
node := nodeInfo.Node()
// 节点被忽略了,分数记为0
if s.IgnoredNodes.Has(node.Name) {
scores[i].Score = 0
continue
}
// 如果 maxScore 为0,指定当前节点的分数为 MaxNodeScore
if maxScore == 0 {
scores[i].Score = framework.MaxNodeScore
continue
}
// 计算当前节点分数
s := scores[i].Score
scores[i].Score = framework.MaxNodeScore * (maxScore + minScore - s) / maxScore
}
return nil
}
NormalizeScore 扩展是在 Score 扩展执行完成后,为每个 ScorePlugin 并行运行 NormalizeScore 方法,然后并为每个 ScorePlugin 应用评分默认权重,然后总结所有插件调用过后的分数,最后选择一个分数最高的节点。
到这里我们就完成了对 PodTopologySpread 的实现分析,我们利用该特性可以实现对 Pod 更加细粒度的控制,我们可以把 Pod 分布到不同的拓扑域,从而实现高可用性,这也有助于工作负载的滚动更新和平稳地扩展副本。
不过如果对 Deployment 进行缩容操作可能会导致 Pod 的分布不均衡,此外具有污点的节点上的 Pods 也会被统计到。
K8S 进阶训练营

 点击屏末 | 阅读原文 | 即刻学习
点击屏末 | 阅读原文 | 即刻学习