
拯救pandas计划(13)——提取Series字符串中的数字并计算
拯救pandas计划(13)——提取Series字符串中的数字并计算
最近发现周围的很多小伙伴们都不太乐意使用pandas,转而投向其他的数据操作库,身为一个数据工作者,基本上是张口pandas,闭口pandas了,故而写下此系列以让更多的小伙伴们爱上pandas。
系列文章说明:
系列名(系列文章序号)——此次系列文章具体解决的需求
平台:
windows 10 python 3.8 pandas >=1.2.4
/ 数据需求
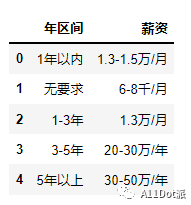
需要对下列有着统一格式的字符串提取其中的数字进行计算。
import pandas as pd
df = pd.DataFrame({
'年区间': ['1年以内', '无要求', '1-3年', ' 3-5年 ', '5年以上'],
'薪资': ['1.3-1.5万/月', '6-8千/月', '1.3万/月', '20-30万/年', ' 30-50万/年 ']
})
df
/ 需求拆解
看标题中说到提取字符串中的数字,可以使用对列进行遍历,一个个进行判断,把数字拿出来,而且在上面说了统一格式的数据,怎么给的数据看起来还不是统一的,是不是在唬人呢。
单个数据来看有点不好判断,在这也不提供这种想法的代码,转念一想,整体看来,正则表达式还挺适合这种格式的字符串数据提取。之前在拯救pandas计划(7)——对含金额标志的字符串列转换为浮点类型数据中也稍有提到正则表达式在pandas里的使用,这次借助本文的例子看下正则表达式如何提取到所需要的数字并进行后续计算。
/ 需求处理
年区间列提取年数
① re
首先观察下数据构成,字符串中有含数字和不含数字的,对于不含数字的用0代替,含数字的中间可能有用-进行隔开,可以考虑 使用以下正则表达式:
import re
re.compile(r'(\d+)?-?(\d+)')
不确定中间的-何时会出现,如果出现也只会出现一次,所以在后面加一个?,前面的数字也难料,同样加上?,用括号表示需要提取括号里的数据,虽然可以对括号添加提取的数据做一个标签,但在这里也不用这么做,能分清就行了。
目前有个想法,对提取的年数进行平均值计算,如果出现0.5就进行四舍五入取整到整年数。将上述的正则表达式运用到下面的这段函数里,由于提取到数字还是字符串格式,需要进行强转成整型。
import re
def year_average(data):
search_year = re.search(r'(\d+)?-?(\d+)', data)
def average(args):
# 平均值计算
x = tuple(args)
length = len(x)
return round(sum(x) / length, 0)
# 如果能提取到数字则计算平均值
if search_year:
return average([int(i) for i in search_year.groups() if i])
# 否则返回 0
else:
return 0
df['平均年数'] = df['年区间'].apply(year_average)
运行后数据显示:
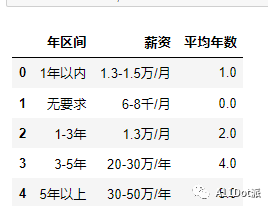
通过apply调用year_average函数,进行正则查找提取并完成后续计算,逻辑上也比较清晰易懂,之前在拯救pandas计划(7)——对含金额标志的字符串列转换为浮点类型数据中有提到过pd.Series类如果为object类型或者string类型,是有个.str方法,可以针对字符串做一些特性操作,在这其中也有提取函数.str.extract,同样可以使用正则表达式。
② .str.extract
df_dash = df['年区间'].str.extract(r'(\d+)?-?(\d+)')
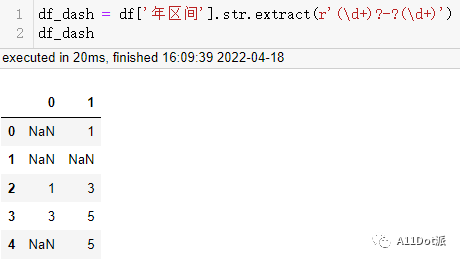
顺利提取出来了,接下的操作和re部分的一样,转换成浮点型数据再计算平均值,可以看到行号为1的行中,两列都为np.nan,所以在计算后还是np.nan,需要对np.nan用0填充,对计算结果进行四舍五入。
df['平均年数2'] = df_dash.astype(float).mean(axis=1).fillna(0).round(0)
df
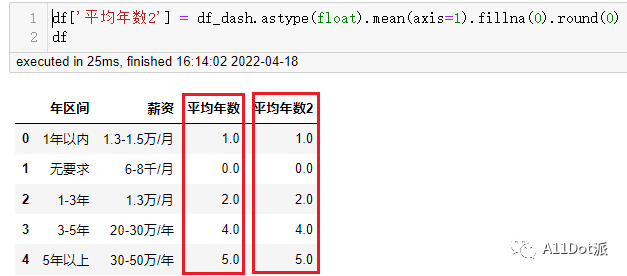
与上一次计算出来的结果是一致的。
(手动水印:原创CSDN宿者朽命,https://blog.csdn.net/weixin_46281427?spm=1011.2124.3001.5343 ,公众号A11Dot派)
提取 薪资列中的数字
在薪资列中,注意到数字之间多了小数点,单单小数点很好解决,为了跟年区间列的提取有一点区别,这里需要将年薪资转换为月薪资,且以数字的形式显示。
起初的想法是数字跟汉字分开提取,既然都需要参与计算,可先替换成数字再整体提取,在万和千之前增加一个分隔符,避免跟前面的混淆,分隔符可以使用在正则表达式里不属于元字符的那一类。
# 先替换成数字,regex=True,用正则方式匹配
df_dash = df['薪资'].replace({'万': '@10000', '千': '@1000', '月': '1', '年': '12'}, regex=True)
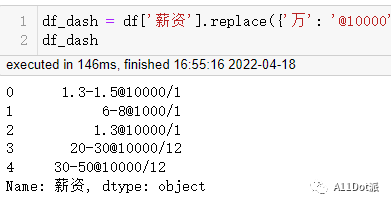
仔细观察一番,正则表达式如下:
re.compile(r'(\d+\.?\d*)?-?(\d+\.?\d*)?@(\d+)/(\d+)')
使用.str.extract提取:
df_dash = df_dash.str.extract(r'(\d+\.?\d*)?-?(\d+\.?\d*)?@(\d+)/(\d+)').astype(float)
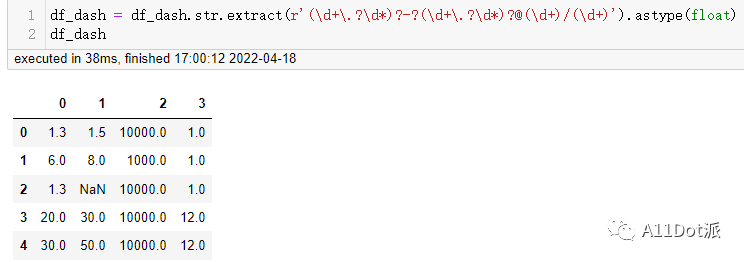
和设想的一样,生成了4列数据,在提取之后使用了astype类型转换方法,类型均为float类型。
转换为月薪资:
df_dash.apply(lambda x: (x[[0, 1]] * x[2]) / x[3], axis=1)
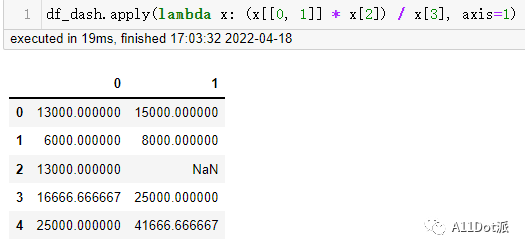
通过上述一系列操作,最终将字符串类型的数据转换为浮点型数字格式,也达到了所想要的结果。
/ 总结
这里主要使用了.str.extract方法结合正则表达式提取相关信息,如需了解更多的使用场景可以查看官方文档,该方法的使用对于正则表达式的掌握程度要求较高,需要理解字符串之间的最小相似类型,编写适当的表达式,完成数据提取。
采桑献春,移云遮阳。
于二零二二年四月十八日作