
特征提取:传统算法 vs 深度学习
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
概述
特征提取是计算机视觉中的一个重要主题。不论是SLAM、SFM、三维重建等重要应用的底层都是建立在特征点跨图像可靠地提取和匹配之上。特征提取是计算机视觉领域经久不衰的研究热点,总的来说,快速、准确、鲁棒的特征点提取是实现上层任务基本要求。
特征点是图像中梯度变化较为剧烈的像素,比如:角点、边缘等。FAST(Features from Accelerated Segment Test)是一种高速的角点检测算法;而尺度不变特征变换SIFT(Scale-invariant feature transform)仍然可能是最著名的传统局部特征点。也是迄今使用最为广泛的一种特征。特征提取一般包含特征点检测和描述子计算两个过程。描述子是一种度量特征相似度的手段,用来确定不同图像中对应空间同一物体,比如:BRIEF(Binary Robust IndependentElementary Features)描述子。可靠的特征提取应该包含以下特性:
近几年深度学习的兴起使得不少学者试图使用深度网络提取图像特征点,并且取得了阶段性的结果。图1给出了不同特征提取方法的特性。本文中的传统算法以ORB特征为例,深度学习以SuperPoint为例来阐述他们的原理并对比性能。
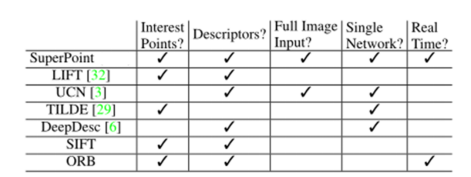
传统算法—ORB特征

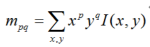
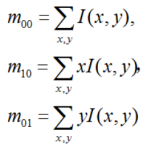
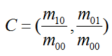
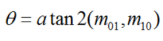

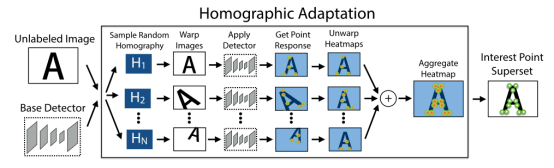
深度学习的方法—SuperPoint
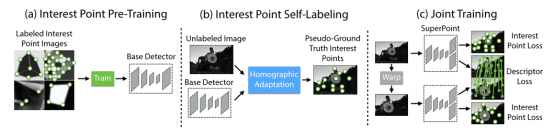
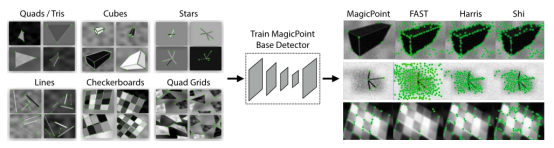
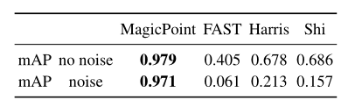


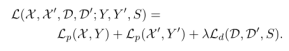

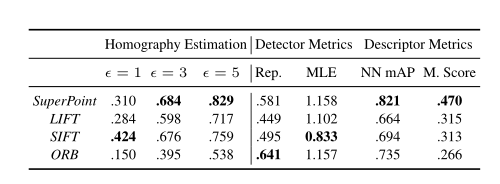
结论
本文仅做学术分享,如有侵权,请联系删文。
—THE END—
评论