
用Python爬取B站、腾讯视频、芒果TV和爱奇艺视频弹幕
点击上方“数据管道”,选择“置顶星标”公众号
干货福利,第一时间送达


海量的弹幕数据不仅可以绘制此类词云图,还可以调用百度AI进行情感分析。那么,我们该如何获取弹幕数据呢?本文运用Python爬取B站视频、腾讯视频、芒果TV和爱奇艺视频等弹幕,让你轻松获取主流视频网站弹幕数据。
一、B站视频弹幕
1.网页分析
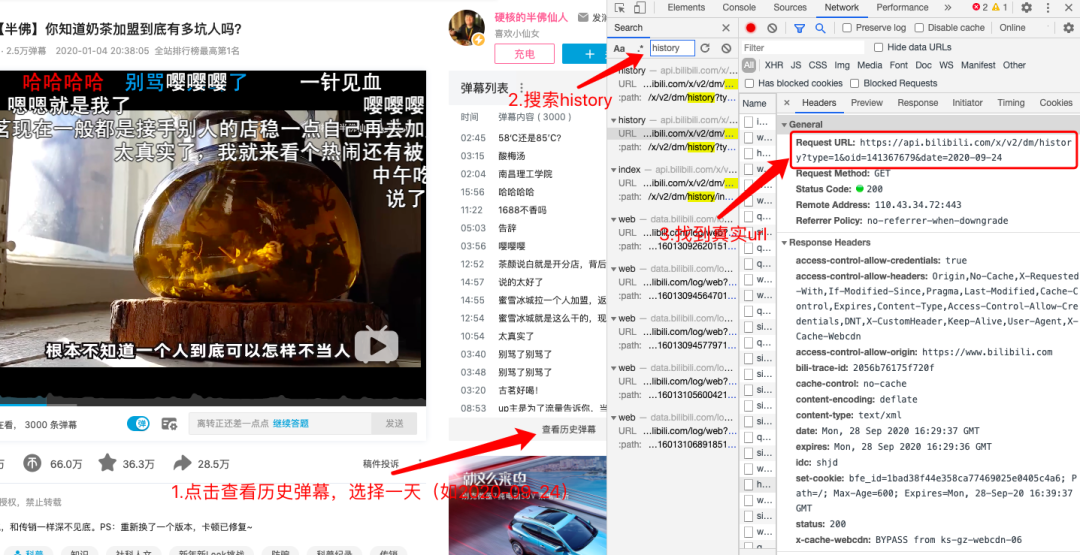
本文以爬取up主硬核的半佛仙人发布的《你知道奶茶加盟到底有多坑人吗?》视频弹幕为例,首先通过以下步骤找到存放弹幕的真实url。
import requests #请求网页数据
from bs4 import BeautifulSoup #美味汤解析数据
import pandas as pd
import time
from tqdm import trange #获取爬取速度
def get_bilibili_url(start, end):
url_list = []
date_list = [i for i in pd.date_range(start, end).strftime('%Y-%m-%d')]
for date in date_list:
url = f"https://api.bilibili.com/x/v2/dm/history?type=1&oid=141367679&date={date}"
url_list.append(url)
return url_list
def get_bilibili_danmu(url_list):
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36",
"cookie": "你自己的" #Headers中copy即可
}
file = open("bilibili_danmu.txt", 'w')
for i in trange(len(url_list)):
url = url_list[i]
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text)
data = soup.find_all("d")
danmu = [data[i].text for i in range(len(data))]
for items in danmu:
file.write(items)
file.write("\n")
time.sleep(3)
file.close()
if __name__ == "__main__":
start = '9/24/2020' #设置爬取弹幕的起始日
end = '9/26/2020' #设置爬取弹幕的终止日
url_list = get_bilibili_url(start, end)
get_bilibili_danmu(url_list)
print("弹幕爬取完成")
二、腾讯视频弹幕
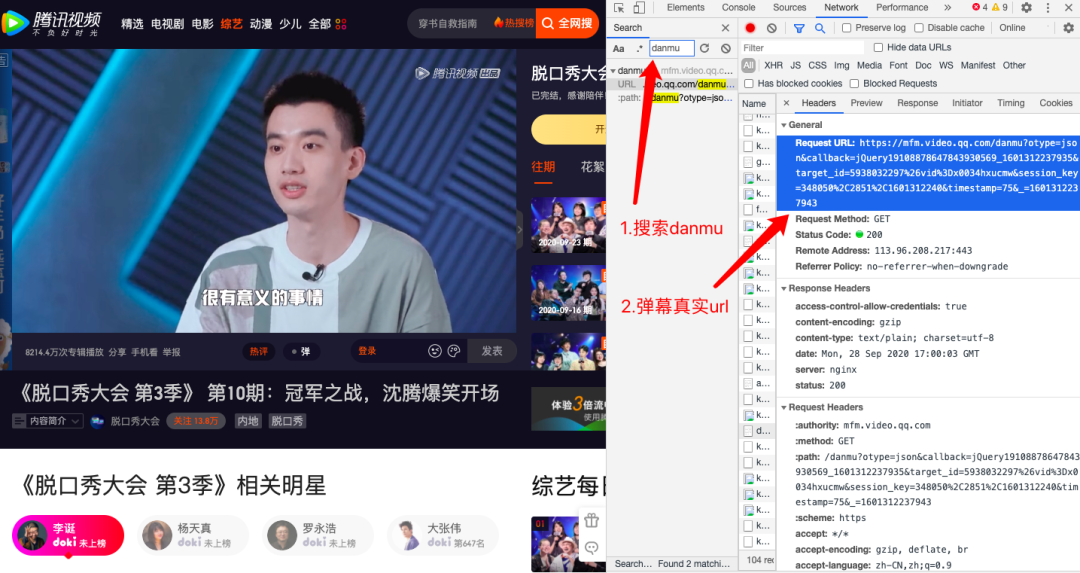
1.网页分析
import requests
import json
import time
import pandas as pd
df = pd.DataFrame()
for page in range(15, 12399, 30):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
url = 'https://mfm.video.qq.com/danmu?otype=json×tamp={}&target_id=5938032297%26vid%3Dx0034hxucmw&count=80'.format(page)
print("正在提取第" + str(page) + "页")
html = requests.get(url,headers = headers)
bs = json.loads(html.text,strict = False) #strict参数解决部分内容json格式解析报错
time.sleep(1)
#遍历获取目标字段
for i in bs['comments']:
content = i['content'] #弹幕
upcount = i['upcount'] #点赞数
user_degree =i['uservip_degree'] #会员等级
timepoint = i['timepoint'] #发布时间
comment_id = i['commentid'] #弹幕id
cache = pd.DataFrame({'弹幕':[content],'会员等级':[user_degree],
'发布时间':[timepoint],'弹幕点赞':[upcount],'弹幕id':[comment_id]})
df = pd.concat([df,cache])
df.to_csv('tengxun_danmu.csv',encoding = 'utf-8')
print(df.shape)
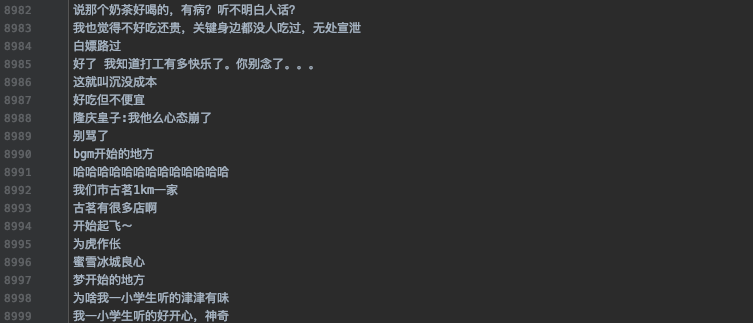
3.数据预览

import requests
import json
import pandas as pd
def get_mangguo_danmu(num1, num2, page):
try:
url = 'https://bullet-ws.hitv.com/bullet/2020/09/29/{}/{}/{}.json'
print("正在爬取第" + str(page) + "页")
danmuurl = url.format(num1, num2, page)
res = requests.get(danmuurl)
res.encoding = 'utf-8'
#print(res.text)
data = json.loads(res.text)
except:
print("无法连接")
details = []
for i in range(len(data['data']['items'])): # 弹幕数据在json文件'data'的'items'中
result = {}
result['stype'] = num2 # 通过stype可识别期数
result['id'] = data['data']['items'][i]['id'] # 获取id
try: # 尝试获取uname
result['uname'] = data['data']['items'][i]['uname']
except:
result['uname'] = ''
result['content'] = data['data']['items'][i]['content'] # 获取弹幕内容
result['time'] = data['data']['items'][i]['time'] # 获取弹幕发布时间
try: # 尝试获取弹幕点赞数
result['v2_up_count'] = data['data']['items'][i]['v2_up_count']
except:
result['v2_up_count'] = ''
details.append(result)
return details
#输入关键信息
def count_danmu():
danmu_total = []
num1 = input('第一个数字')
num2 = input('第二个数字')
page = int(input('输入总时长'))
for i in range(page):
danmu_total.extend(get_mangguo_danmu(num1, num2, i))
return danmu_total
def main():
df = pd.DataFrame(count_danmu())
df.to_csv('mangguo_danmu.csv')
if __name__ == '__main__':
main()
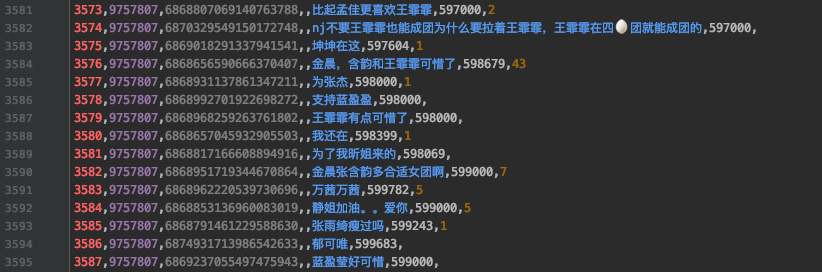
3.数据预览
四、爱奇艺弹幕
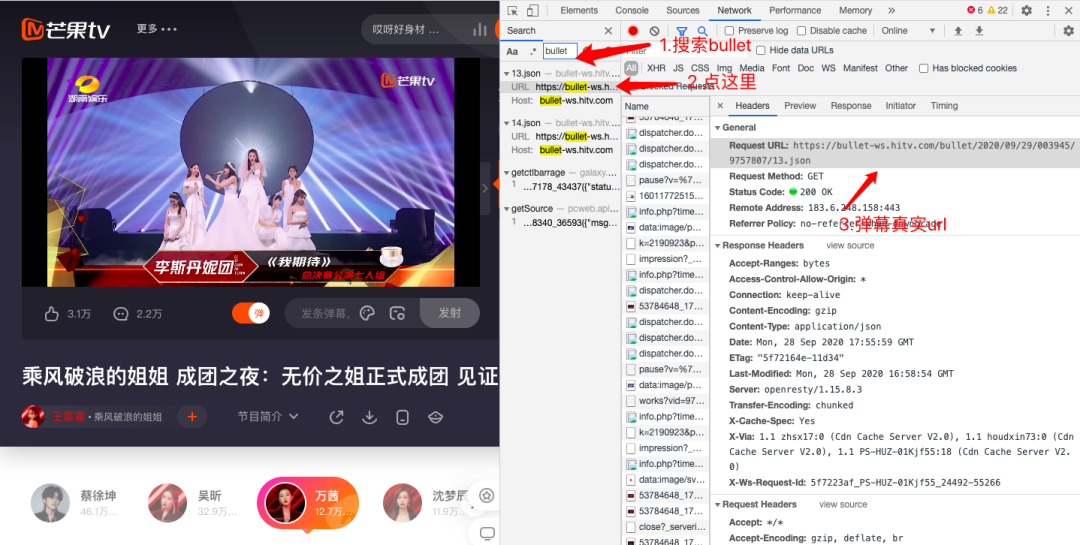
1.网页分析
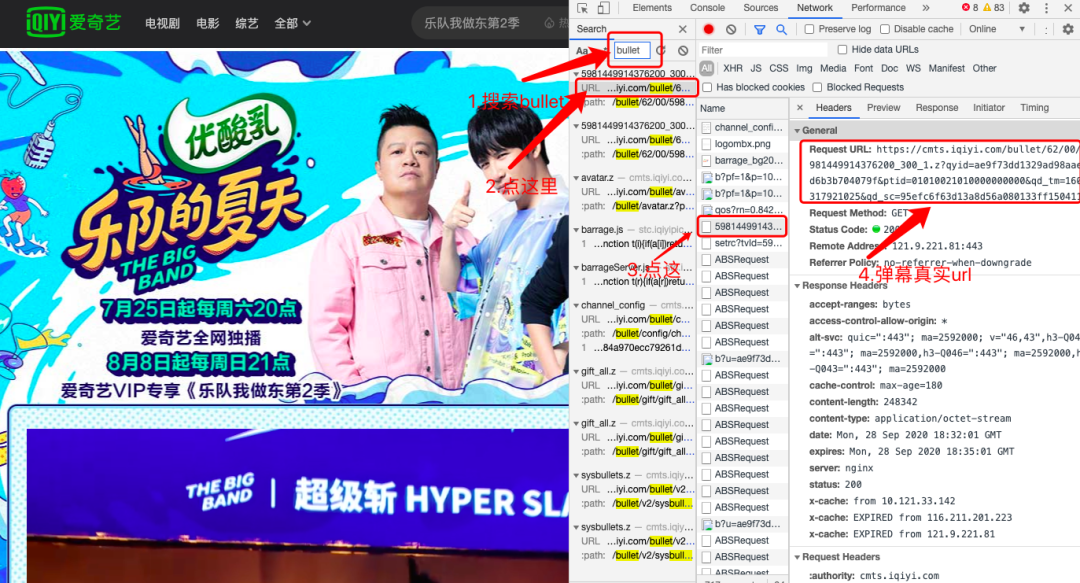
本文以爬取《乐队的夏天第2季》第13期上视频弹幕为例,首先通过以下步骤找到存放弹幕的真实url。
import zlib
import requests
# 1.爬取xml文件
def download_xml(url):
bulletold = requests.get(url).content # 二进制内容
return zipdecode(bulletold)
def zipdecode(bulletold):
'对zip压缩的二进制内容解码成文本'
decode = zlib.decompress(bytearray(bulletold), 15 + 32).decode('utf-8')
return decode
for x in range(1,12):
# x是从1到12,12怎么来的,这一集总共57分钟,爱奇艺每5分钟会加载新的弹幕,57除以5向上取整
url = 'https://cmts.iqiyi.com/bullet/62/00/5981449914376200_300_' + str(x) + '.z'
xml = download_xml(url)
# 把编码好的文件分别写入17个xml文件中(类似于txt文件),方便后边取数据
with open('./aiqiyi/iqiyi' + str(x) + '.xml', 'a+', encoding='utf-8') as f:
f.write(xml)
# 2.读取xml文件中的弹幕数据数据
from xml.dom.minidom import parse
import xml.dom.minidom
def xml_parse(file_name):
DOMTree = xml.dom.minidom.parse(file_name)
collection = DOMTree.documentElement
# 在集合中获取所有entry数据
entrys = collection.getElementsByTagName("entry")
print(entrys)
result = []
for entry in entrys:
content = entry.getElementsByTagName('content')[0]
print(content.childNodes[0].data)
i = content.childNodes[0].data
result.append(i)
return result
with open("aiyiqi_danmu.txt", mode="w", encoding="utf-8") as f:
for x in range(1,12):
l = xml_parse("./aiqiyi/iqiyi" + str(x) + ".xml")
for line in l:
f.write(line)
f.write("\n"
3.数据预览

评论