
前端Base64编码知识,一文打尽
原文: https://juejin.cn/post/6989391487200919566 作者: 云的世界 掘金专栏: 前端基础进阶
大厂技术 高级前端 Node进阶
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群
前言
本文将详细的介绍前端 Base64 编码知识,探索起源,让大家对开发经常用到的 Base64 有个更全面深入的认知。
大纲
Base64在前端的应用 Base64数据编码起源 Base64编码64的含义 Base64编码优缺点 一些计算机和前端基础知识 ASCII码, Unicode , UTF-8 Base64编码和解码 其他的成熟方案
Base64在前端的应用
Base64编码,你一定知道的,先来看看它在前端的一些常见应用:
当然绝部分场景都是基于Data URLs[1]
Canvas图片生成
canvas的 toDataURL[2]可以把canvas的画布内容转base64编码格式包含图片展示的 data URI[3]。
const ctx = canvasEl.getContext("2d");
// ...... other code
const dataUrl = canvasEl.toDataURL();
// data:image/png;base64,iVBORw0KGgoAAAANSUhE.........
你画我猜,新用户加入,要获取当前的最新的绘画界面,也可以通过Base64格式的消息传递。
文件读取
FileReader的 readAsDataURL[4]可以把上传的文件转为base64格式的data URI,比较常见的场景是用户头像的剪裁和上传。
function readAsDataURL() {
const fileEl = document.getElementById("inputFile");
return new Promise((resolve, reject) => {
const fd = new FileReader();
fd.readAsDataURL(fileEl.files[0]);
fd.onload = function () {
resolve(fd.result);
// data:image/png;base64,iVBORw0KGgoAAAA.......
}
fd.onerror = reject;
});
}
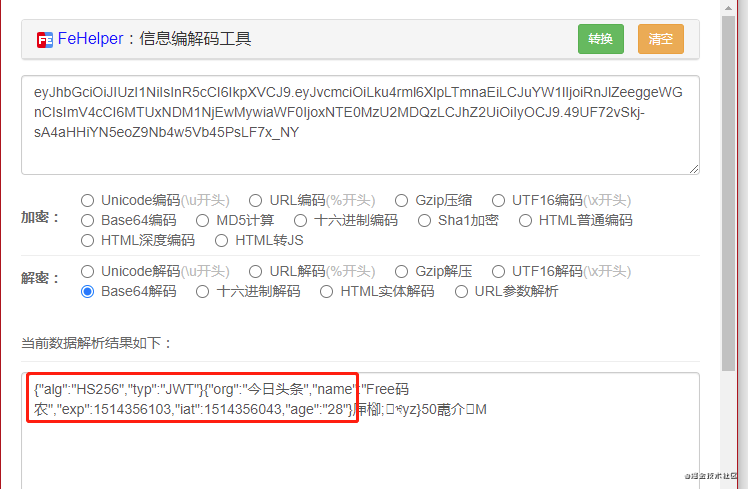
jwt
jwt由header, payload,signature三部分组成,前两个解码后,都是可以明文看见的。拿 国服最强JWT生成Token做登录校验讲解,看完保证你学会![5] 里面的token做测试。
网站图片和小图片
移动端网站图标优化
<link rel="icon" href="data:," />
<link rel="icon" href="data:;base64,=" />
至于怎么获得这个值data:,的:
<canvas height="0" width="0" id="canvas"></canvas>
<script>
const canvasEl = document.getElementById("canvas");
const ctx = canvasEl.getContext("2d");
dataUrl = canvasEl.toDataURL();
console.log(dataUrl); // data:,
</script>
小图片
这个就有很多场景了,比如img标签,背景图等
img标签:
<img src="data:image/png;base64,iVBORw0KGgoAAAA......." />
css背景图:
.bg{
background: url(data:image/png;base64,iVBORw0KGgoAAAA.......)
}
简单的数据加密
当然这不是好方法,但是至少让你不好解读。
const username = document.getElementById("username").vlaue;
const password = document.getElementById("password").vlaue;
const secureKey = "%%S%$%DS)_sdsdj_66";
const sPass = utf8_to_base64(password + secureKey);
doLogin({
username,
password: sPass
})
SourceMap
借用阮大神的一段代码, 注意mappings字段,这实际上就是bas64编码格式的内容,当然你直接去解,是会失败的。
{
version : 3,
file: "out.js",
sourceRoot : "",
sources: ["foo.js", "bar.js"],
names: ["src", "maps", "are", "fun"],
mappings: "AAgBC,SAAQ,CAAEA"
}
具体的实现请看官方的base64-vlq.js[6]文件。
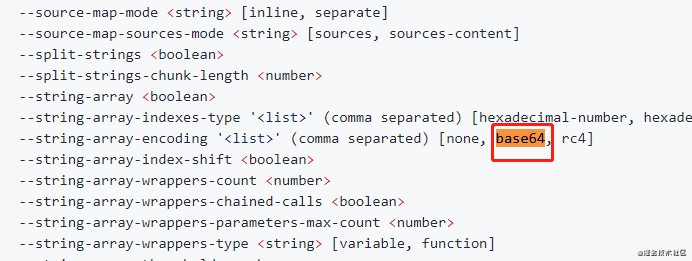
混淆加密代码
著名的代码混淆库, javascript-obfuscator[7],其也是有应用base64几码的,一起看看选项:
webpack-obfuscator[8]也是基于其封装的。
--string-array-indexes-type '<list>' (comma separated) [hexadecimal-number, hexadecimal-numeric-string]
--string-array-encoding '<list>' (comma separated) [none, base64, rc4]
--string-array-index-shift <boolean>
--string-array-wrappers-count <number>
--string-array-wrappers-chained-calls <boolean>
其他
X.509公钥证书, github SSH key, mht文件,邮件附件等等,都有Base64的影子。
Base64数据编码起源
早期邮件传输协议基于 ASCII 文本,对于诸如图片、视频等二进制文件处理并不好。ASCII 主要用于显示现代英文,到目前为止只定义了 128 个字符,包含控制字符和可显示字符。为了解决上述问题,Base64 编码顺势而生。
Base64是编解码,主要的作用不在于安全性,而在于让内容能在各个网关间无错的传输,这才是Base64编码的核心作用。
除了Base64数据编码,其实还有Base32数据编码, Base16数据编码,可以参见 RFC 4648[9]。
Base64编码64的含义
64就是64个字符的意思。
base64对照表, 借用 Base64原理[10]的一张图: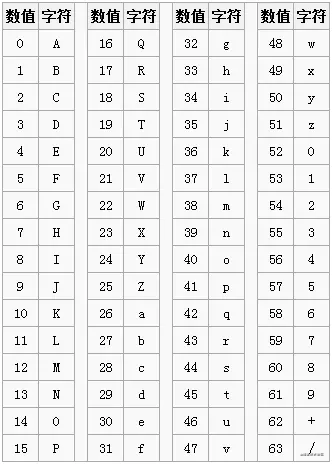
A-Z26a-z260-910+ /2
26 + 26 + 10 + 2 = 64
当然还有一个字符=,这是填充字符,后面会提到,不属于64里面的范畴。
对照表的索引值,注意一下,后面的base64编码和解码会用到。
Base64编码优缺点
优点
可以将二进制数据(比如图片)转化为可打印字符,方便传输数据 对数据进行简单的加密,肉眼是安全的 如果是在html或者css处理图片,可以减少http请求
缺点
内容编码后体积变大, 至少1/3
因为是三字节变成四个字节,当只有一个字节的时候,也至少会变成三个字节。编码和解码需要额外工作量
说完优缺点,回到正题:
我们今天的重点是 uf8编码转Base64编码:
基本流程
char => 码点 => utf-8编码 => base64编码
在之前要解一下编码的知识, 了解编码知识,又要先了解一些计算机的基础知识。
一些计算机和前端基础知识
比特和字节
比特又叫位。在计算机的世界里,信息的表示方式只有 0 和 1, 其可以表示两种状态。
一位二进制可以表示两状态, N位可以表示2^N种状态。
一个字节(Byte)有8位(Bit)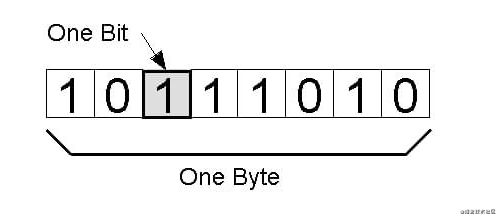
所以一个字节可以表示 2^8 = 256种状态;
获得字符的 Unicode码点
String.prototype.charCodeAt[11] 可以获取字符的码点,获取范围为0 ~ 65535。这个地方注意一下,关系到后面的utf-8字节数。
"a".charCodeAt(0) // 97
"中".charCodeAt(0) // 20013
进制表示
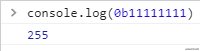
0b开头,可以表示二进制
注意0b10000000= 128 ,0b11000000=92,之后会用到.
0b11111111 // 255
0b10000000 // 128 后面会用到
0b11000000 // 192 后面会用到
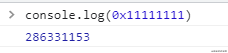
0x开头,可以表示16进制
0x11111111 // 286331153
0o开头可以表示8进制,就不多说了,本来不会涉及。
进制转换
10进制转其他进制
Number.prototype.toString(radix)[12]可以把十进制转为其他进制。
100..toString(2) // 1100100
100..toString(16) // 64, 也等于 ox64
其他进制转为10进制
parseInt(string, radix)[13]可以把其他进制,转为10进制。
parseInt("10000000", 2) // 128
parseInt("10",16) // 16
这里额外提一下一元操作符号+可以把字符串转为数字,后面也会用到,之前提到的0b,0o,0x这里都会生效。
+"1000" // 1000
+"0b10000000" // 128
+"0o10" // 8
+"0x10" // 16
位移操作
本文只涉及右移操作,就只讲右移,右移相当于除以2,如果是整数,简单说是去低位,移动几位去掉几位,其实和10进制除以10是一样的。
64 >> 2 = 16 我们一起看一下过程
0 1 0 0 0 0 0 0 64
-------------------
0 1 0 0 0 0 | 0 0 16
一元 & 操作和 一元|操作
一元&
当两者皆为1的时候,值为1。 本文的作用可用来去高位, 具体看代码。3553 & 36 = 0b110111100001 & 0b111111 = 100001
因为高位缺失,不可能都为1,故均为0, 而低位相当于复制一遍而已。
110111 100001
111111
------------
000000 100001
一元|
当任意一个为1,就输出为1. 本文用来填补0。比如,把3补成8位二进制3 | 256 = 11 | 100000000 = 100000011
100000011.substring(1)是不是就等于8位二进制呢00000011
具备了这些基本知识,我们就开始先了解编码相关的知识。
ASCII码, Unicode , UTF-8
ASCII码
ASCII码第一位始终是0, 那么实际可以表示的状态是 2^7 = 128种状态。
ASCII 主要用于显示现代英文,到目前为止只定义了 128 个字符,包含控制字符和可显示字符。
0~31 之间的ASCII码常用于控制像打印机一样的外围设备 32~127 之间的ASCII码表示的符号,在我们的键盘上都可以被找到
完整的 ASCII码对应表,可以参见 基本ASCII码和扩展ASCII码[14]
接下来是Unicode和UTF-8编码,请先记住这个重要的知识:
Unicode: 字符集 UTF-8: 编码规则
Unicode
Unicode 为世界上所有字符都分配了一个唯一的编号(码点),这个编号范围从 0x000000 到 0x10FFFF (十六进制),有 100 多万,每个字符都有一个唯一的 Unicode 编号,这个编号一般写成 16 进制,在前面加上 U+。例如:掘的 Unicode 是U+6398。
U+0000到U+FFFF
最前面的65536个字符位,它的码点范围是从0一直到216-1。所有最常见的字符都放在这里。
U+010000一直到U+10FFFF
剩下的字符都放着这里,码点范围从U+010000一直到U+10FFFF。
Unicode有平面的概念,这里就不拓展了。
Unicode只规定了每个字符的码点,到底用什么样的字节序表示这个码点,就涉及到编码方法。
UTF-8
UTF-8 是互联网使用最多的一种 Unicode 的实现方式。还有 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示)等实现方式。
UTF-8 是它是一种变长的编码方式, 使用的字节个数从 1 到 4 个不等,最新的应该不止4个, 这个1-4不等,是后面编码和解码的关键。
UTF-8的编码规则:
对于只有一个字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 Unicode 码。此时,对于英语字母UTF-8 编码和 ASCII 码是相同的。对于 n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码,如下表所示:
| Unicode 码点范围(十六进制) | 十进制范围 | UTF-8 编码方式(二进制) | 字节数 |
|---|---|---|---|
0000 0000 ~ 0000 007F | 0 ~ 127 | 0xxxxxxx | 1 |
0000 0080 ~ 0000 07FF | 128 ~ 2047 | 110xxxxx 10xxxxxx | 2 |
0000 0800 ~ 0000 FFFF | 2048 ~ 65535 | 1110xxxx 10xxxxxx 10xxxxxx | 3 |
0001 0000 ~ 0010 FFFF | 65536 ~ 1114111 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 4 |
我们可能没见过字节数为2或者为4的字符, 字节数为2的可以去Unicode对应表[15]这里找,而等于4的可以去这看看Unicode® 13.0 Versioned Charts Index[16]
下面这些码点都处于0000 0080 ~ 0000 07FF, utf-8编码需要2个字节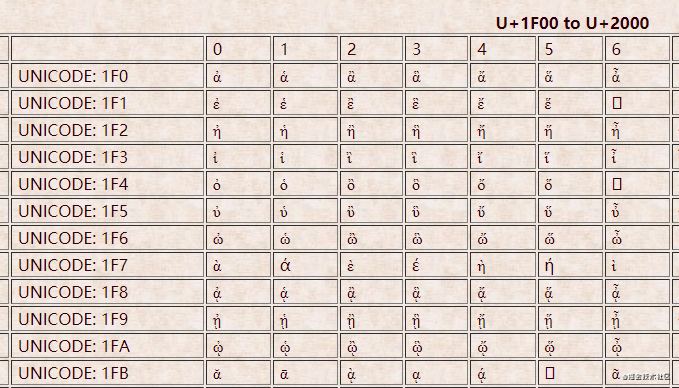
下面这些码点都处于0001 0000 ~ 0010 FFFF, utf-8编码需要4个字节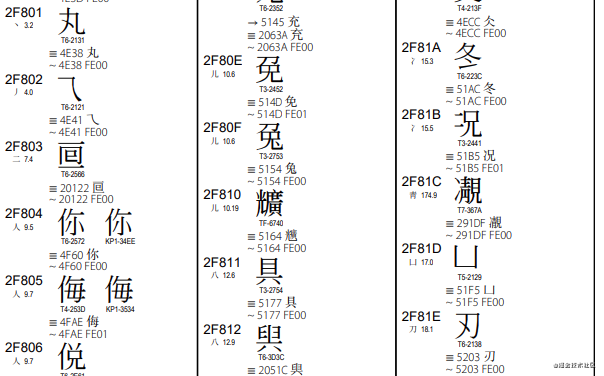
可能这里光说不好理解,我们分别以英文字符a和中文字符掘来讲解一下:
为了验证结果,可以去 Convert UTF8 to Binary Bits - Online UTF8 Tools[17]
英文字符a
先获得其码点, "a".charCodeAt(0)等于97对照表格, 0~127, 需 1个字节97..toString(2)得到编码1100001根据格式 0xxxxxxx进行填充, 最终结果
01100001
中文字符掘
先获得其码点, "掘".charCodeAt(0)等于25496对照表格,2048 ~ 65535 需 3个字节25496..toString(2)得到编码110 001110 011000根绝格式 1110xxxx 10xxxxxx 10xxxxxx进行填充, 最终结果如下
11100110 10001110 10011000
Convert UTF8 to Binary Bits - Online UTF8 Tools[18]执行结果:完全匹配

抽象把字符转为utf8格式二进制的方法
基于上面的表格和转换过程,我们抽象一个方法,这个方法在之后的Base64编码和解码至关重要:
先看看功能,覆盖utf8编码1-3字节范围
console.log(to_binary("A")) // 11100001
console.log(to_binary("س")) // 1101100010110011
console.log(to_binary("掘")) // 111001101000111010011000
方法如下
function to_binary(str) {
const string = str.replace(/\r\n/g, "\n");
let result = "";
let code;
for (var n = 0; n < string.length; n++) {
//获取麻点
code = str.charCodeAt(n);
if (code < 0x007F) { // 1个字节
// 0000 0000 ~ 0000 007F 0 ~ 127 1个字节
// (code | 0b100000000).toString(2).slice(1)
result += (code).toString(2).padStart(8, '0');
} else if ((code > 0x0080) && (code < 0x07FF)) {
// 0000 0080 ~ 0000 07FF 128 ~ 2047 2个字节
// 0x0080 的二进制为 10000000 ,8位,所以大于0x0080的,至少有8位
// 格式 110xxxxx 10xxxxxx
// 高位 110xxxxx
result += ((code >> 6) | 0b11000000).toString(2);
// 低位 10xxxxxx
result += ((code & 0b111111) | 0b10000000).toString(2);
} else if (code > 0x0800 && code < 0xFFFF) {
// 0000 0800 ~ 0000 FFFF 2048 ~ 65535 3个字节
// 0x0800的二进制为 1000 00000000,12位,所以大于0x0800的,至少有12位
// 格式 1110xxxx 10xxxxxx 10xxxxxx
// 最高位 1110xxxx
result += ((code >> 12) | 0b11100000).toString(2);
// 第二位 10xxxxxx
result += (((code >> 6) & 0b111111) | 0b10000000).toString(2);
// 第三位 10xxxxxx
result += ((code & 0b111111) | 0b10000000).toString(2);
} else {
// 0001 0000 ~ 0010 FFFF 65536 ~ 1114111 4个字节
// https://www.unicode.org/charts/PDF/Unicode-13.0/U130-2F800.pdf
throw new TypeError("暂不支持码点大于65535的字符")
}
}
return result;
}
方法中有三个地方稍微难理解一点,我们一起来解读一下:
二字节 (code >> 6) | 0b11000000
其作用是生成高位二进制。
我们以实际的一个栗子来讲解,以س为例,其码点为0x633,在0000 0080 ~ 0000 07FF之间,占两个字节, 在其二进制编码为11 000110011 , 其填充格式如下, 低位要用6位。
110xxxxx 10xxxxxx
为了方便观察,我们把 11 000110011 重新调整一下 11000 110011。
(code >> 6) 等于 00110011 >> 6,右移6位, 直接干掉低6位。为什么是6呢,因为低位需要6位,右移动6位后,剩下的就是用于高位操作的位了。
11000000
11000 | 110011
--------------
11011000
二字节 (code & 0b111111) | 0b10000000
作用,用于生成低位二进制。以س为例,11000 110011, 填充格式
110xxxxx 10xxxxxx
(code & 0b111111)这步的操作是为了干掉6位以上的高位,仅仅保留低6位。一元&符号,两边都是1的时候才会是1,妙啊。
11000 110011
111111
------------------
110011
接着进行 | 0b10000000, 主要是按照格式10xxxxxx进行位数填补, 让其满8位。
11000 110011
111111 (code & 0b111111)
------------------
110011
10 000000 (code & 0b111111) | 0b10000000
-------------------
10 110011
Base64编码和解码
utf-8转Base64编码规则
获取每个字符的Unicode码,转为utf-8编码 三个字节作为一组,一共是24个二进制位
字节数不能被 3 整除,用0字节值在末尾补足按照6个比特位一组分组,前两位补0,凑齐8位 计算每个分组的数值 以第 4步的值作为索引,去ASCII码表找对应的值替换第 2步添加字节数个数的=
比如第2添加了2个字节,后面是2个=
以大掘A为例, 我们通过上面的utf8_to_binary方法得到utf8的编码11100110 10001110 10011000 11000001, 其字节数不能被3整除,后面填补
11100110
10001110
10011000
01000001
--------
00000000
00000000
6位一组分为四组, 高位补0, 用| 分割一下填补的。
00 | 111001 => 57 => 5
00 | 101000 => 40 => o
00 | 111010 => 58 => 6
00 | 011000 => 24 => Y
00 | 110000 => 16 => Q
00 | 010000 => 16 => Q
00 | 000000 => => =
00 | 000000 => => =
结果是:5o6YQQ==, 完美。
utf-8转Base64编码规则代码实现
基于上面的to_binary方法和base64的转换规则,就很简单啦:
先看看执行效果,very good, 和 base64.us[19] 结果完全一致。
console.log(utf8_to_base64("a")); // YQ==
console.log(utf8_to_base64("Ȃ")); // yII=
console.log(utf8_to_base64("中国人")); // 5Lit5Zu95Lq6
console.log(utf8_to_base64("Coding Writing 好文召集令|后端、大前端双赛道投稿,2万元奖池等你挑战!"));
//Q29kaW5nIFdyaXRpbmcg5aW95paH5Y+s6ZuG5Luk772c5ZCO56uv44CB5aSn5YmN56uv5Y+M6LWb6YGT5oqV56i/77yMMuS4h+WFg+WlluaxoOetieS9oOaMkeaImO+8gQ==
完整代码如下:
const BASE64_CHARTS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
function utf8_to_base64(str: string) {
let binaryStr = to_binary(str);
const len = binaryStr.length;
// 需要填补的=的数量
let paddingCharLen = len % 24 !== 0 ? (24 - len % 24) / 8 : 0;
//6个一组
const groups = [];
for (let i = 0; i < binaryStr.length; i += 6) {
let g = binaryStr.slice(i, i + 6);
if (g.length < 6) {
g = g.padEnd(6, "0");
}
groups.push(g);
}
// 求值
let base64Str = groups.reduce((b64str, cur) => {
b64str += BASE64_CHARTS[+`0b${cur}`]
return b64str
}, "");
// 填充=
if (paddingCharLen > 0) {
base64Str += paddingCharLen > 1 ? "==" : "=";
}
return base64Str;
}
至于解码,是其逆过程,留给大家去实现吧。
其他的成熟方案
当然是基于已有的 btoa和atob,
但是 unescape是不被推荐使用的方法
function utf8_to_b64( str ) {
return window.btoa(unescape(encodeURIComponent( str )));
}
function b64_to_utf8( str ) {
return decodeURIComponent(escape(window.atob( str )));
}
// Usage: utf8_to_b64('✓ à la mode'); // "4pyTIMOgIGxhIG1vZGU=" b64_to_utf8('4pyTIMOgIGxhIG1vZGU='); // "✓ à la mode"
MDN的 rewriting `atob()` and `btoa()` using `TypedArray`s and UTF-8[20]
其支持到6字节,但是可读性并不好。
第三方库 base64-js[21] 与 js-base64[22]都是周下载量过百万的库。
虽然有那么多成熟的,但是我们理解和自己实现,才能更明白Base64的编码原理。
额外补充一点
编码关系图
借用[你真的了解 Unicode 和 UTF-8 吗?[23]]一张图:

DOMString[24] 是 utf-16编码
引用
Version-Specific Charts[25]
Unicode13.0.0[26]
Unicode® 13.0 Versioned Charts Index[27]
RFC 4648 | The Base16, Base32, and Base64 Data Encodings[28]
Base64 encoding and decoding[29]
字符编码笔记:ASCII,Unicode 和 UTF-8[30]
Unicode与JavaScript详解[31]
Base64 编码入门教程[32] Base64原理[33]
详解base64原理[34]
一文读懂base64编码[35]
JS 中关于 base64 的一些事[36]
Base64 的原理、实现及应用[37]
图片与Base64换算关系[38]
[你真的了解 Unicode 和 UTF-8 吗?[39]]
Unicode中UTF-8与UTF-16编码详解[40]
Unicode对应表[41]
JavaScript Source Map 详解[42]
我组建了一个氛围特别好的 Node.js 社群,里面有很多 Node.js小伙伴,如果你对Node.js学习感兴趣的话(后续有计划也可以),我们可以一起进行Node.js相关的交流、学习、共建。下方加 考拉 好友回复「Node」即可。

“分享、点赞、在看” 支持一波 