
OCR文字识别-基于CTC/Attention/ACE的三大解码算法
什么是OCR文字识别?
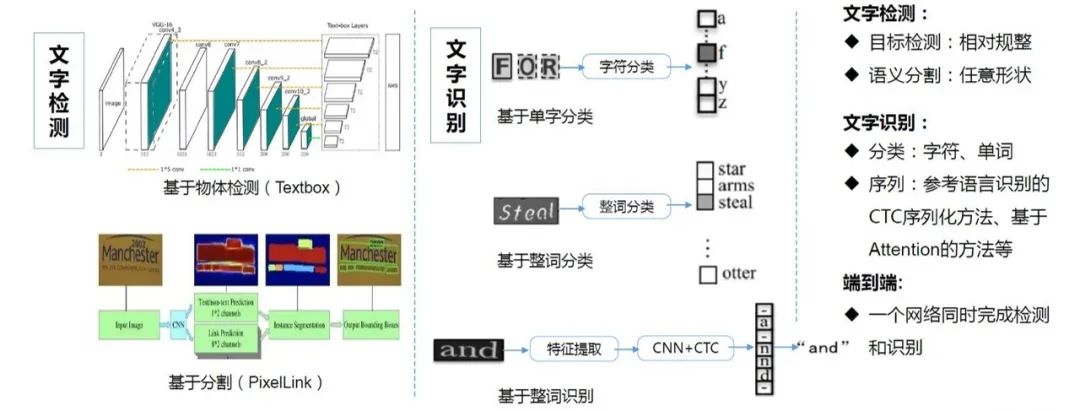
一般来说,文字识别之前需要先对文字进行定位(文字检测主要有基于物体检测和基于分割两种方法),文字识别就是通过输入文字图片,然后解码成文字的方法。本文主要讲文字识别部分,文字识别主要分成三种类型:单字分类、整词分类和整词识别。当能够定位出单字时,可以用图像分类的方法直接对单字进行分类;当需要预测整词数量较少时,可以对整词进行分类;当有大量整词需要预测并且没有单字定位时,就需要用解码序列的方法进行识别了。因此,文字识别中最常用的是文字序列识别,适用场景更为广泛。本文将主要介绍文字序列识别的解码算法。
OCR解码是文字识别中最为核心的问题。本文主要对OCR的序列方法CTC、Attention、ACE进行介绍,微信OCR算法就是参考这三种解码算法的。
不同的解码算法的特征提取器可以共用,后面接上不同的解码算法就可以实现文字识别了,以下用CRNN作为特征提取器。
CRNN
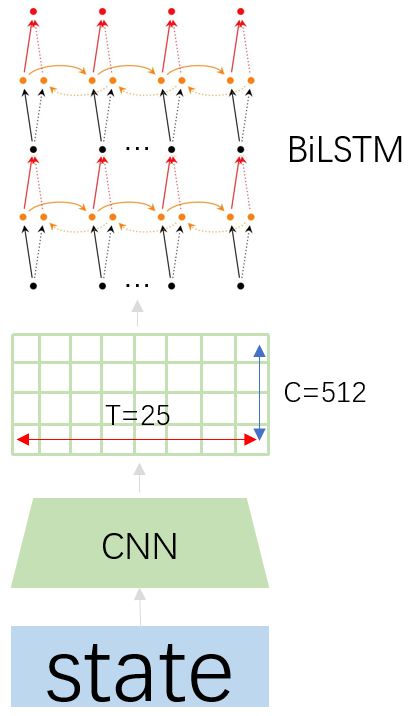
CRNN的特征抽取器由一个CNN和一个BiLSTM组成,其中BiLSTM使用的是stack形深层双向LSTM结构。
CRNN特征提取器流程如下:
1.假设输入图像尺寸为32x100x3(HxWxC),经过CNN转换成1x25x512(HxWxC)。
2.将CNN的输出维度转换为25个1x512的序列,送入深层双向LSTM中,得到CRNN的输出特征,维度转换成为25xn(n是字符集合总数)。
OCR文字识别的难点

OCR文字识别的解码主要难点在于如何进行输入输出的对齐。如上图所示,如果每个1xn预测一个字符,那么可能会出现多个1xn预测同一个字符,这样子得到的最终结果会产生重复字符。所以需要设计针对文字识别的解码算法来解决输入输出的对齐问题。
目前我了解到的主要有三种解码方法,可以解决OCR解码的一对多问题,分别为CTC、Attention和ACE三种。
CTC
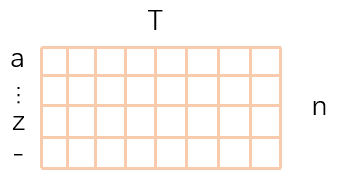
CTC是最为经典的OCR解码算法,假设CRNN特征抽取器的输出维度Txn,其中T=8,n包含blank(记作 - )字符(blank字符是间隔符,意思是前后字符不连续)。对每一列1xn进行softmax得到概率最大的字符,得到的最终序列需要去除连续的重复字符,比如最终得到的序列为-stt-ate,那么去重合并后就得到state序列。
那么state的序列概率就变成了所有去重合并后为state的字符序列概率之和,只要最大化字符序列概率,就可以优化CRNN+CTC的文字识别算法。由于每个字符前后都可以插入blank,所以可以将所有可能状态如下图展开。

为了方便起见,对于所有state序列的合法路径做一些限制,规则如下:
1.转换只能往右下方向,其它方向不允许
2.相同的字符之间起码要有一个空字符
3.非空字符不能被跳过
4.起点必须从前两个字符开始
5.终点必须落在结尾两个字符
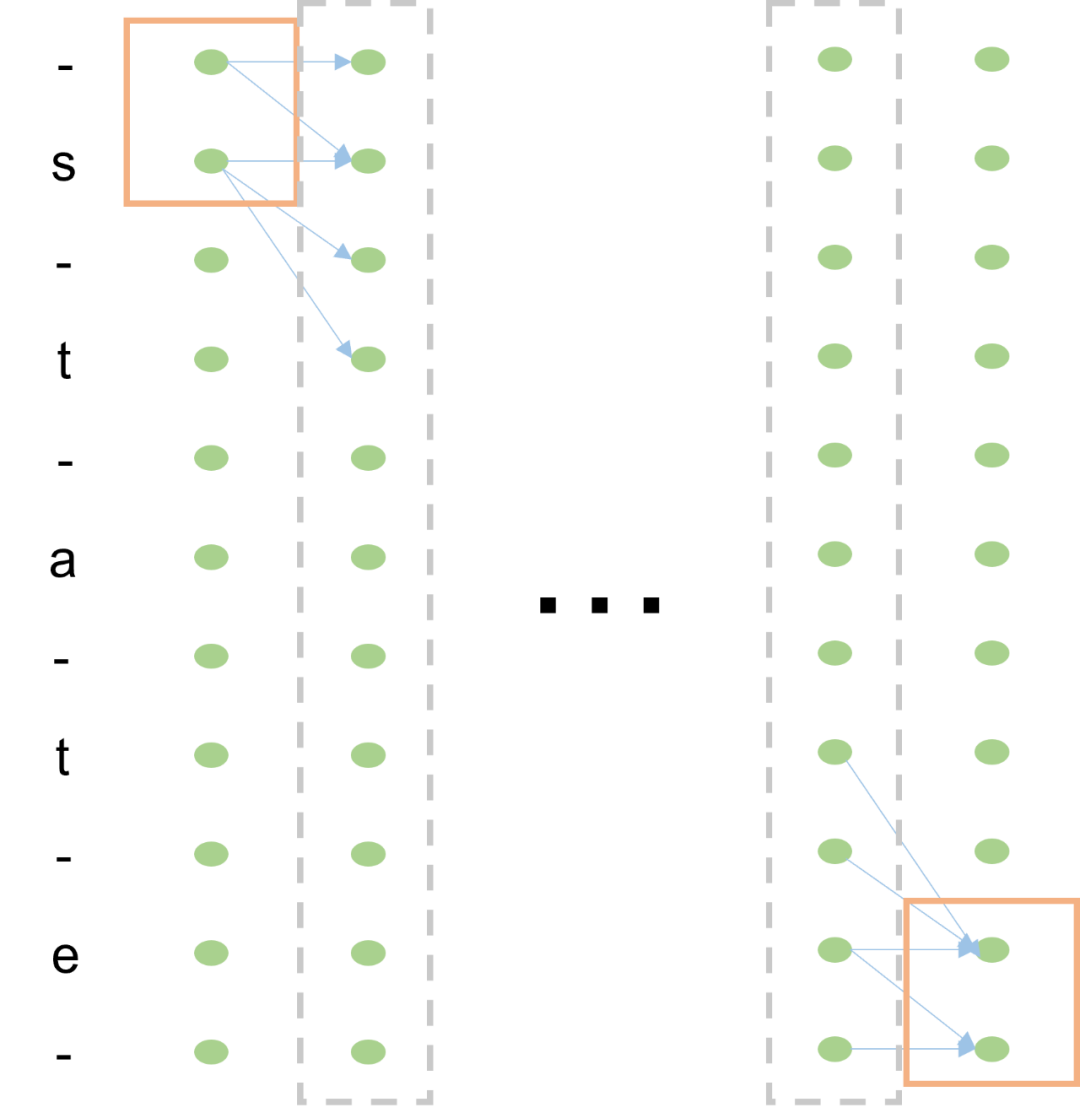
根据上述约束规则,遍历所有"state"序列的合法路径,“state”的所有合法路径如下图所示:

其中绿色框部分为起点和终点,蓝色箭头为"state"序列的合法路径。当然可以通过枚举所有路径,然后求所有路径的概率之和即为"state"序列的概率。但是枚举所有路径计算复杂度太高了,于是CTC引入了HMM的前向-后向算法来减少计算复杂度(可以参考一下我之前的回答,增加隐马尔可夫模型(HMM)的理解)。
以前向算法为例(后向算法可以认为是状态序列的反转,计算方法相同),简单来说,就是利用分治和动态规划的思想,把8个时间点拆分成7个重复单元,然后先计算出第一个重复单元红色虚线框中每个状态的观测概率,并且保存下来当作下一个重复单元的初始状态,循环计算7次就得了最终的观测概率。比起暴力求解观测概率,复杂度大大降低。
Attention
基于Attention的OCR解码算法,把OCR文字识别当成文字翻译任务,即通过Attention Decoder出文字序列。
RNN -> Seq2Seq
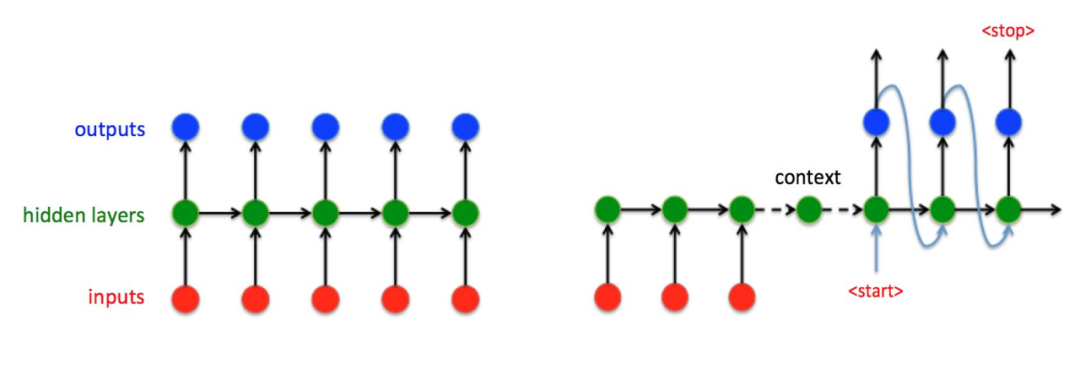
左图是经典的RNN结构,右图是Seq2Seq结构。RNN的输入序列和输出序列必须有相同的时间长度,而机器翻译以及文字识别任务都是输入输出不对齐的,不能直接使用RNN结构进行解码。于是在Seq2Seq结构中,将输入序列进行Encoder编码成一个统一的语义向量Context,然后送入Decoder中一个一个解码出输出序列。在Decoder解码过程中,第一个输入字符为<start>,然后不断将前一个时刻的输出作为下一个时刻的输入,循环解码,直到输出<stop>字符为止。
Seq2Seq -> Attention Decoder
Seq2Seq把所有的输入序列都编码成一个统一的语义向量Context,然后再由Decoder解码。由于context包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个Context可能存不下那么多信息,就会造成精度的下降。除此之外,如果按照上述方式实现,只用到了编码器的最后一个隐藏层状态,信息利用率低下。
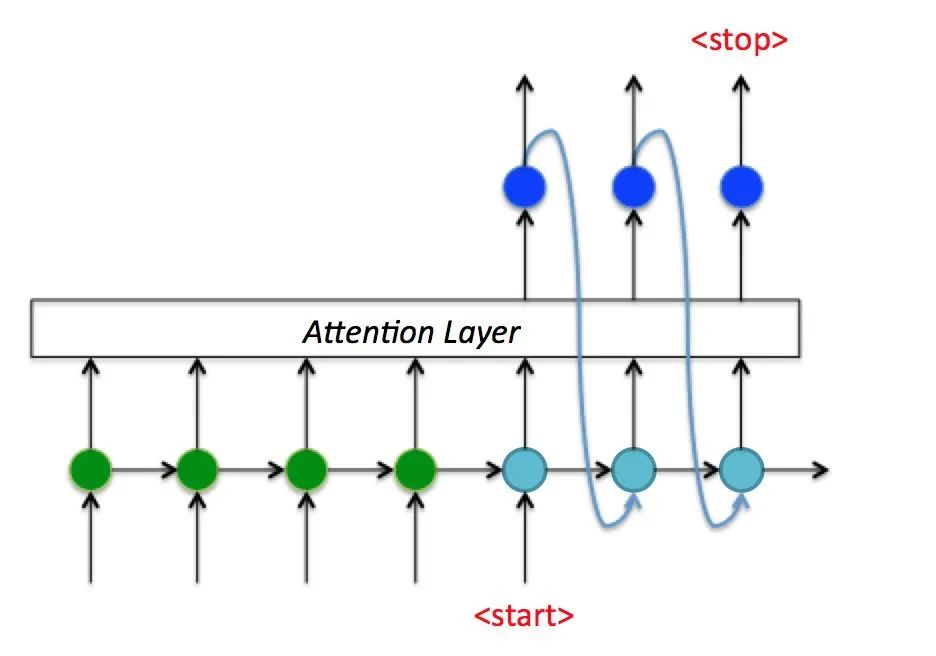
所以如果要改进Seq2Seq结构,最好的切入角度就是:利用Encoder所有隐藏层状态解决Context长度限制问题。于是Attention Decoder在Seq2Seq的基础上,增加了一个Attention Layer,如上图所示。
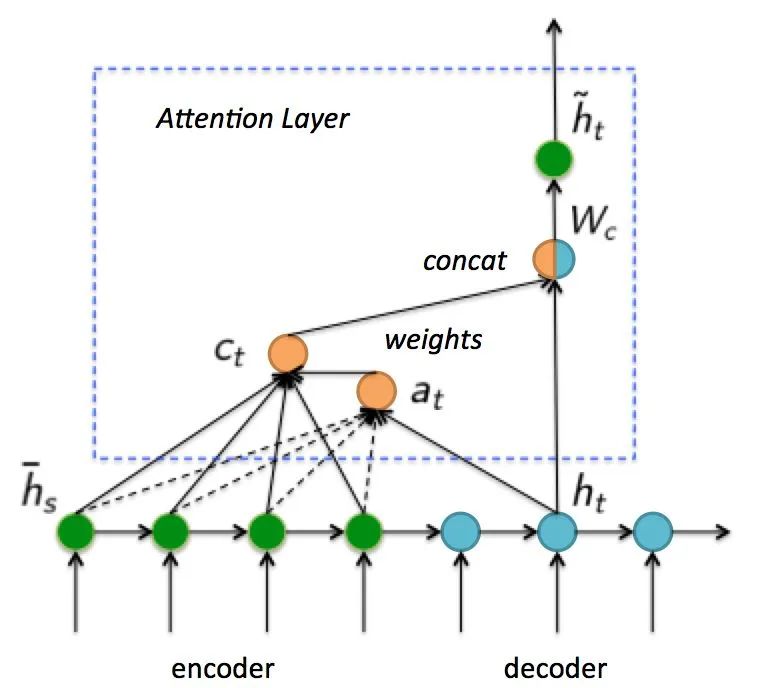
在Decoder时,每个时刻的解码状态跟Encoder的所有隐藏层状态进行cross-attention计算,cross-attention将当前解码的隐藏层状态和encoder的所有隐藏层状态做相关性计算,然后对encoder的所有隐藏层加权求和,最后和当前解码的隐藏层状态concat得到最终的状态。这里的cross-attention计算方式也为后来的Transformer框架打下了基础(详细看我之前写的文章计算机视觉"新"范式: Transformer)。
另外,从形式上看,Attention Decoder很自然的可以替换成最近非常流行的Transformer,事实上,最近也有几篇基于Vision Transformer的文本识别算法。
ACE
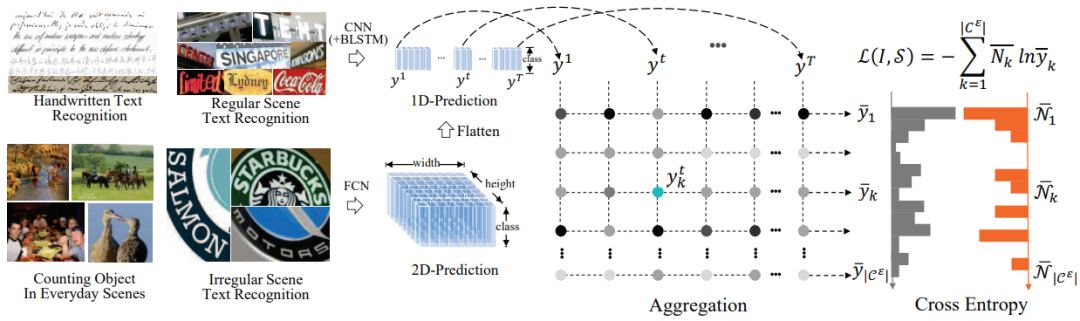
基于ACE的解码方法不同于CTC和Attention,ACE的监督信号实际上是一种弱监督(输入输出没有做形式上的对齐,没有先后顺序信息,倾向于学习表征),并且可以用于多行文字识别。
对于单行文字,假设输出维度为Txn(T是序列长度,n是字符集合总数),那么第k个字符出现的总数为
CTC/Attention/ACE三种解码算法比较
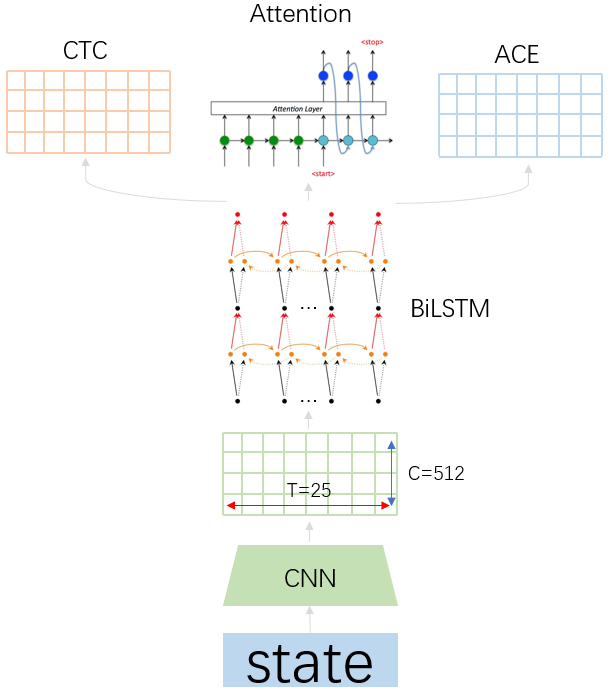
从模型设计上来看,可以采用结合上面3种方法的多任务文本识别模型。在训练时,以CTC为主,Attention Decoder和ACE辅助训练。在预测时,考虑到速度和性能,只采用CTC进行解码预测。多任务可以提高模型的泛化性,同时如果对预测时间要求不高,多结果也可以提供更多的选择和对比。
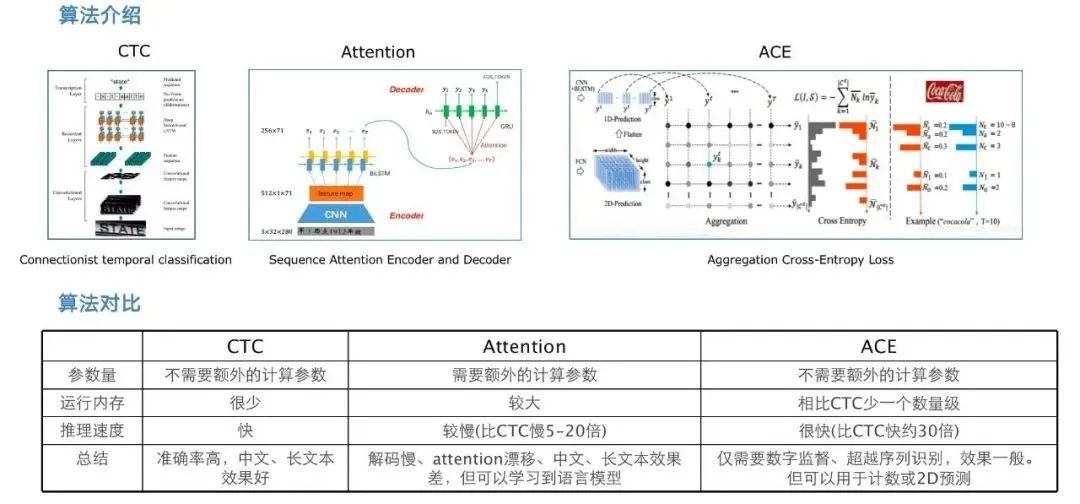
上图来源于微信OCR技术的比较:
1.CTC和ACE方法不需要额外的计算参数,Attention需要额外的计算参数
2.推理内存,ACE < CTC < Attention;推理速度,ACE > CTC > Attention
3.CTC效果更好一些,适合长文本;Attention可以得到语言模型;ACE可以用于计数和2D预测
由于Attention依赖于上一个预测结果,导致只能串行解码,推理速度影响较大,但是可以得到语言模型做pretrain迁移使用;而CTC可以通过引入blank字符做形式上对齐,并且通过HMM前向-后向算法加速;ACE则直接不依赖顺序信息,直接估计整体分布。三者各有利弊,实际使用时,需要结合具体任务按需使用。
Reference
[1] An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
[2] Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks
[3] Robust Scene Text Recognition with Automatic Rectification
[4] Aggregation Cross-Entropy for Sequence Recognition
[5] https://mp.weixin.qq.com/s/6IGXof3KWVnN8z1i2YOqJA
强烈推荐以下三篇blog
https://zhuanlan.zhihu.com/p/43534801
https://zhuanlan.zhihu.com/p/51383402
https://xiaodu.io/ctc-explained/
··· END ···
觉得有用给个在看吧 