
建设数仓的血泪教训!(建议收藏)
什么才是⼀个好的数据模型设计?

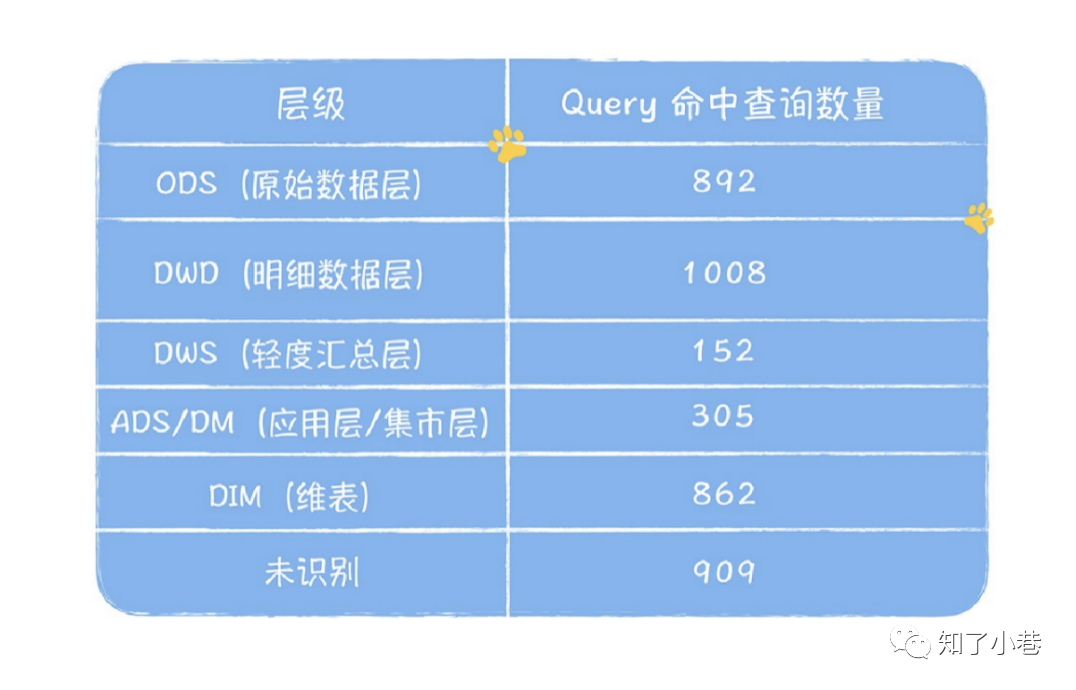

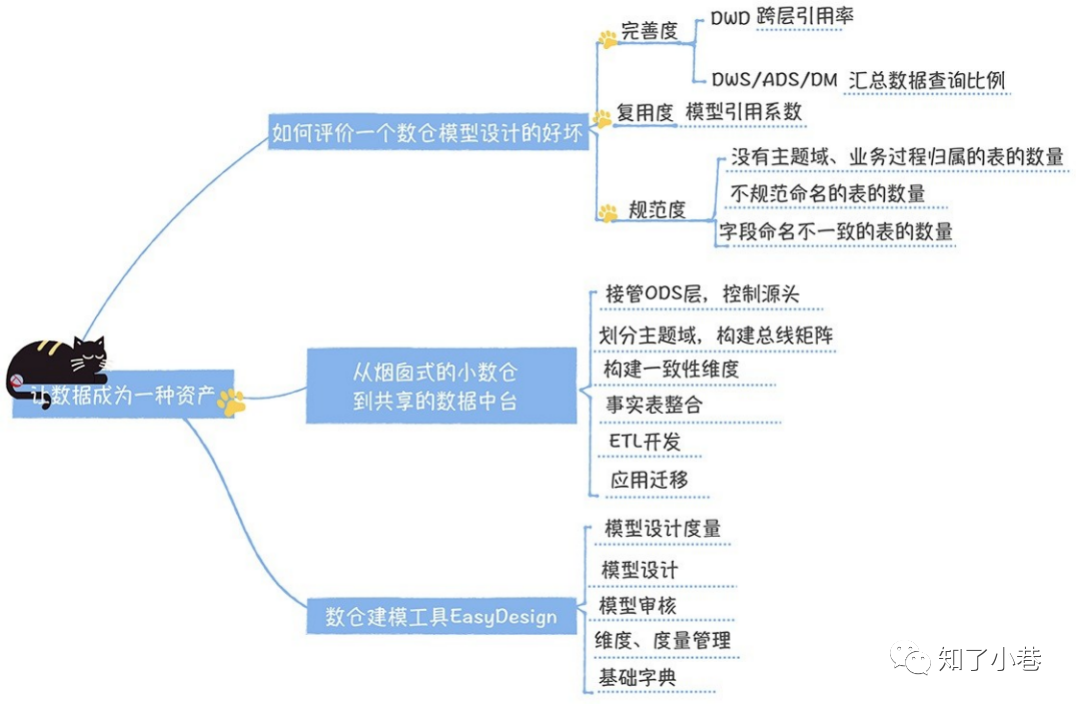
通过上⾯的分析,我们似乎已经找到了⼀个理想的数仓模型设计应该具备的因素,那就是“数据模型可复⽤,完善且规范”。
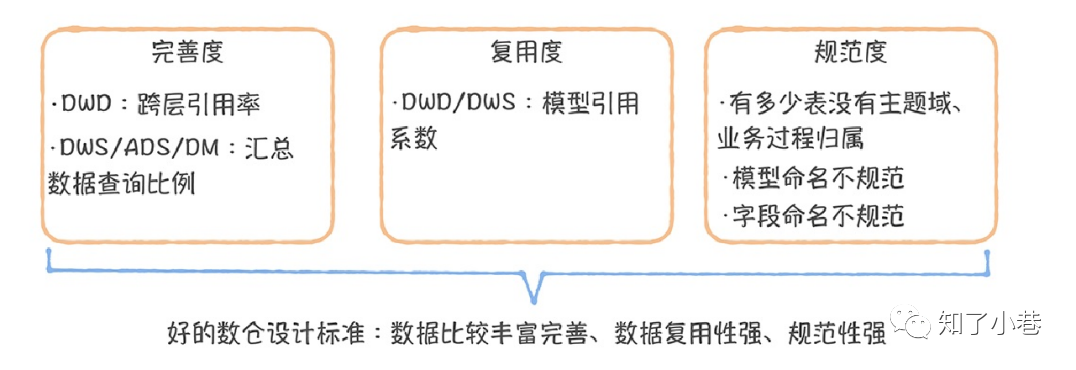
汇总数据查询⽐例:DWS/ADS/DM层的查询占所有查询的⽐例。
如何衡量复⽤度

模型引⽤系数:⼀个模型被读取,直接产出下游模型的平均数量。
如何衡量规范度
经验和建议:
如何从烟囱式的⼩数仓到共享的数据中台
第⼀,接管ODS层,控制源头。
第⼆,划分主题域,构建总线矩阵。


第三,构建⼀致性维度。

第四,事实表整合。

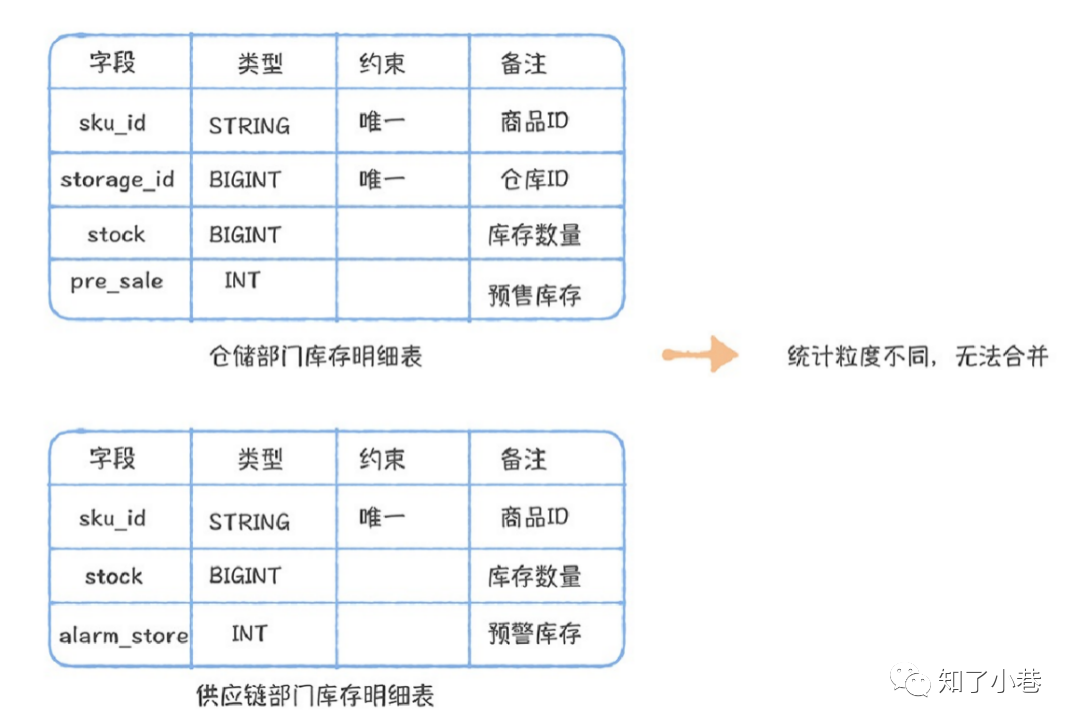
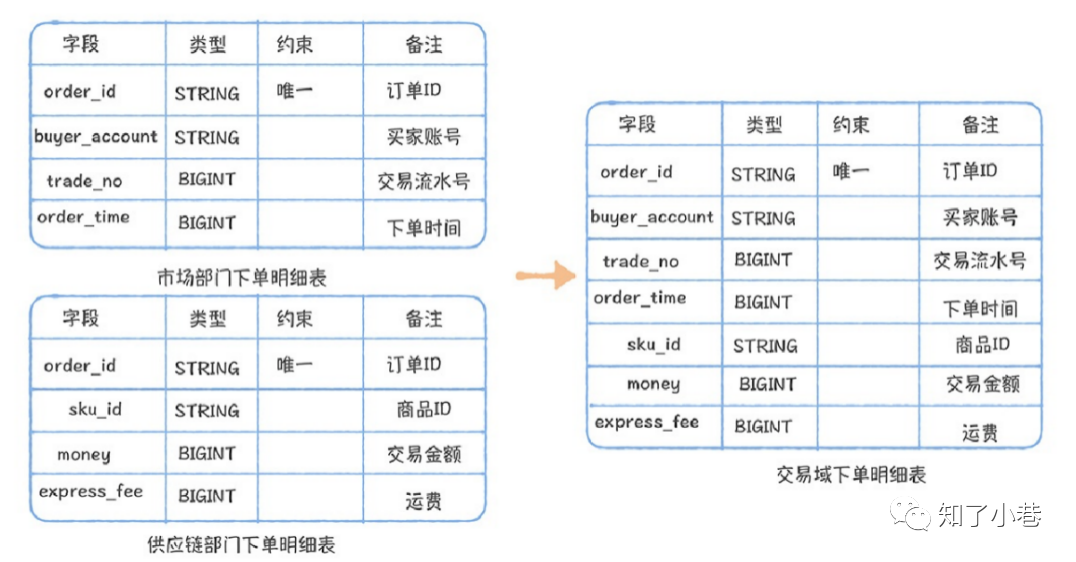
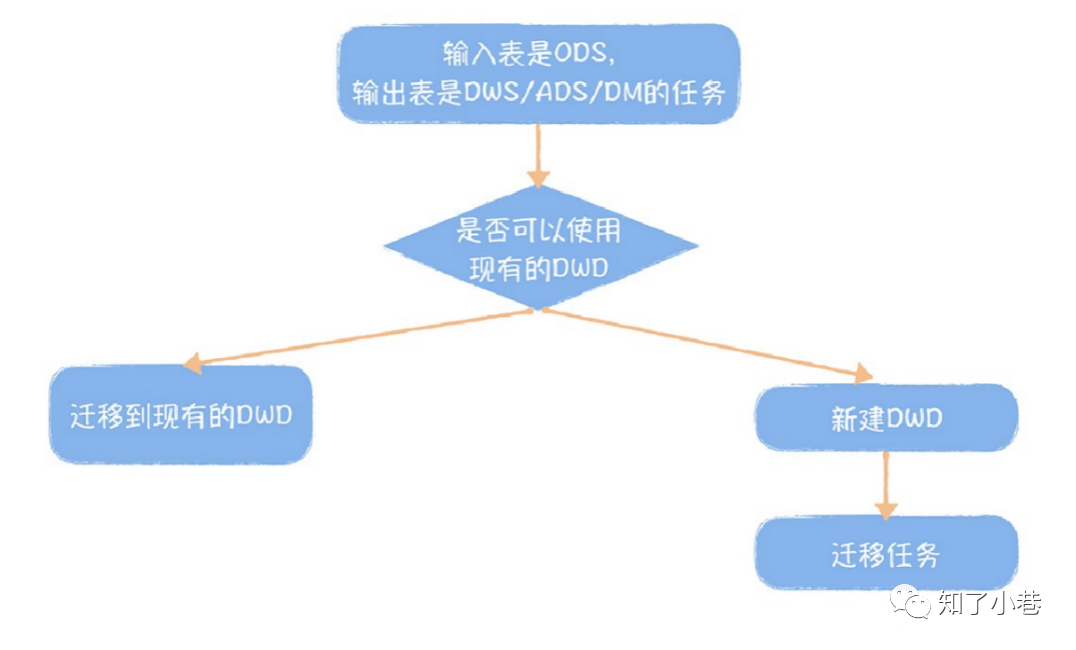
第五,模型开发。
第六,应⽤迁移。
数仓建模⼯具EasyDesign


总结
思考
--end--
扫描下方二维码 添加好友,备注【交流】 可私聊交流,也可进资源丰富学习群
评论