
使用 MinIO 与 Grafana Mimir 实现指标持久化存储
Grafana Mimir 是 Grafana Labs 开发的一个 AGPLv3 许可的开源软件项目,与对象存储结合使用时,可为 Prometheus 指标提供可扩展的长期存储。Mimir 使用基于微服务的可水平扩展的架构构建。每个微服务被称为一个组件,Mimir 作为由这些组件组成的单个二进制文件运行。大多数组件都是无状态的,不需要在重新启动之间保留任何数据。这里我们结合 MinIO 来使用 Grafana Mimir。
Mimir 特性
当您将 Mimir 和 MinIO 结合起来时,您将生成一个特别适合满足企业云原生可观察性需求的基础架构,其中包括:
性能:MinIO 将可扩展性和高性能相结合,使每个工作负载(无论要求有多高)都触手可及。MinIO 具有惊人的性能,最近的基准测试在 GET 上实现了 325 GiB/s (349 GB/s),在 PUT 上实现了 165 GiB/s (177 GB/s),仅使用 32 个现成 NVMe SSD 节点。
规模:MinIO 没有任何限制,因为它可以通过服务器池水平扩展。每个服务器池都是一组独立的节点,拥有自己的计算、网络和存储资源。在多租户配置中,每个租户都是单个命名空间中的服务器池集群,与其他租户的服务器池完全隔离。通过将 MinIO 指向新的服务器池,可以轻松地将容量添加到现有系统,MinIO 会自动为其做好准备并将其投入使用。
简单性:如果您宁愿使用 Mimir 而不是花几个小时摆弄对象存储,那么您找不到比 MinIO 更简单的解决方案了。MinIO 只服务于对象——这就是我们所做的一切,并且我们执着于成为最好的。其他产品将对象和文件存储相结合,这会产生多个存储层,从而导致 Mimir 的查询响应时间出现延迟,并创建更复杂的架构,从而导致失败的可能性更大。
多云:MinIO 诞生于云端,可以在任何硬件和软件组合上运行。丰富的集成意味着 MinIO 可以透明地插入现有的安全和管理工具及服务,以集中身份管理、加密密钥管理等。MinIO 在裸机或任何版本的 Kubernetes(包括 GKE、EKS、AKS、Red Hat OpenShift、VMware Tanzu)上提供 S3 API 兼容的对象存储,并使用主动-主动复制高效同步数据。
Grafana Mimir 的一些核心优势包括:
易于安装和维护:Grafana Mimir 丰富的文档、教程和部署工具使其能够快速上手。您只需一个二进制文件即可启动并运行 Grafana Mimir,无需任何其他依赖项。部署后,使用 Grafana Mimir 打包的最佳实践仪表板、警报和操作手册可以轻松监控系统的运行状况。
大规模可扩展性:您可以在多台机器上运行 Grafana Mimir 的水平可扩展架构,从而能够比单个 Prometheus 实例处理更多数量级的时间序列。内部测试表明 Grafana Mimir 可处理多达 10 亿个活动时间序列。
指标的全局视图:Grafana Mimir 使您能够运行聚合来自多个 Prometheus 实例的系列的查询,为您提供系统的全局视图。它的查询引擎广泛地并行化查询执行,因此即使是最高基数的查询也能以极快的速度完成。
廉价、耐用的指标存储:Grafana Mimir 使用对象存储进行长期数据存储,使其能够利用这种无处不在、经济高效、高耐用性的技术。它与多种对象存储实现兼容,包括 AWS S3、Google Cloud Storage、Azure Blob Storage、OpenStack Swift 以及任何与 S3 兼容的对象存储。
高可用性:Grafana Mimir 复制传入指标,确保在机器故障时不会丢失数据。其水平可扩展架构还意味着它可以在零停机的情况下重新启动、升级或降级,这意味着指标提取或查询不会中断。
原生多租户:Grafana Mimir 的多租户架构使您能够将数据和查询与独立团队或业务部门隔离,从而使这些组可以共享同一集群。高级限制和服务质量控制可确保容量在租户之间公平共享。
Mimir 可以轻松扩展到 10 亿个指标甚至更多,其查询性能比 Cortex 快 40 倍,TSDB Mimir 就是为了取代 Cortex 而构建的。Cortex 自 2018 年以来一直是 CNCF 项目,广泛用于存储 Prometheus 指标。在创建 Mimir 时,Grafana Labs 通过 AGPLv3 许可、访问控制以及改进的性能、可扩展性和可用性为企业级可观测性奠定了基础。
Grafana Labs 对 Mimir 的目标是:成为最佳可扩展时间序列数据库,无论指标格式如何。企业应该能够在不修改现有代码的情况下使用 Prometheus 指标(以及其他供应商协作的其他指标)。它给自己的定位是成为可观测性中 metrics 后端存储的终极方案,能够兼容各种 metrics 协议,如图:
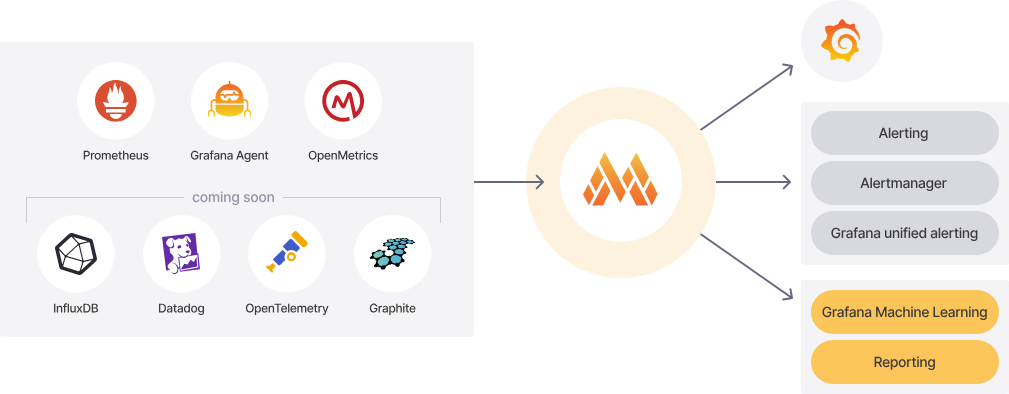
Mimir 架构
整体上 Grafana Mimir 有两种部署模式:
单体模式
微服务模式
部署模式由 -target 参数确定,可以通过 CLI 标志或 YAML 配置来设置该参数。
单体模式
整体模式在单个进程中运行所有必需的组件,并且是默认的操作模式,你可以通过指定 -target=all 来设置。单体模式是部署 Grafana Mimir 的最简单方法,如果您想快速入门或想在开发环境中使用 Grafana Mimir,该模式非常有用。要查看 -target 设置为 all 时运行的组件列表,请使用 ./mimir -modules 查看:
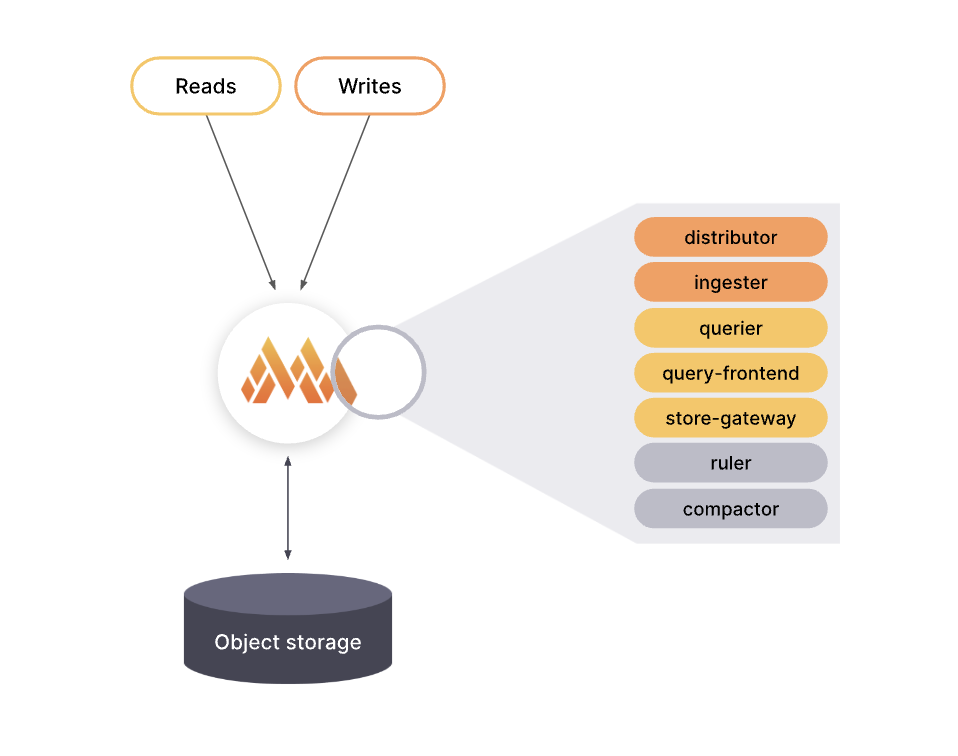
通过使用 -target=all 部署多个 Grafana Mimir 二进制文件,可以水平扩展整体模式。这种方法提供了高可用性和更大的规模,而没有完整的微服务部署的配置复杂性。
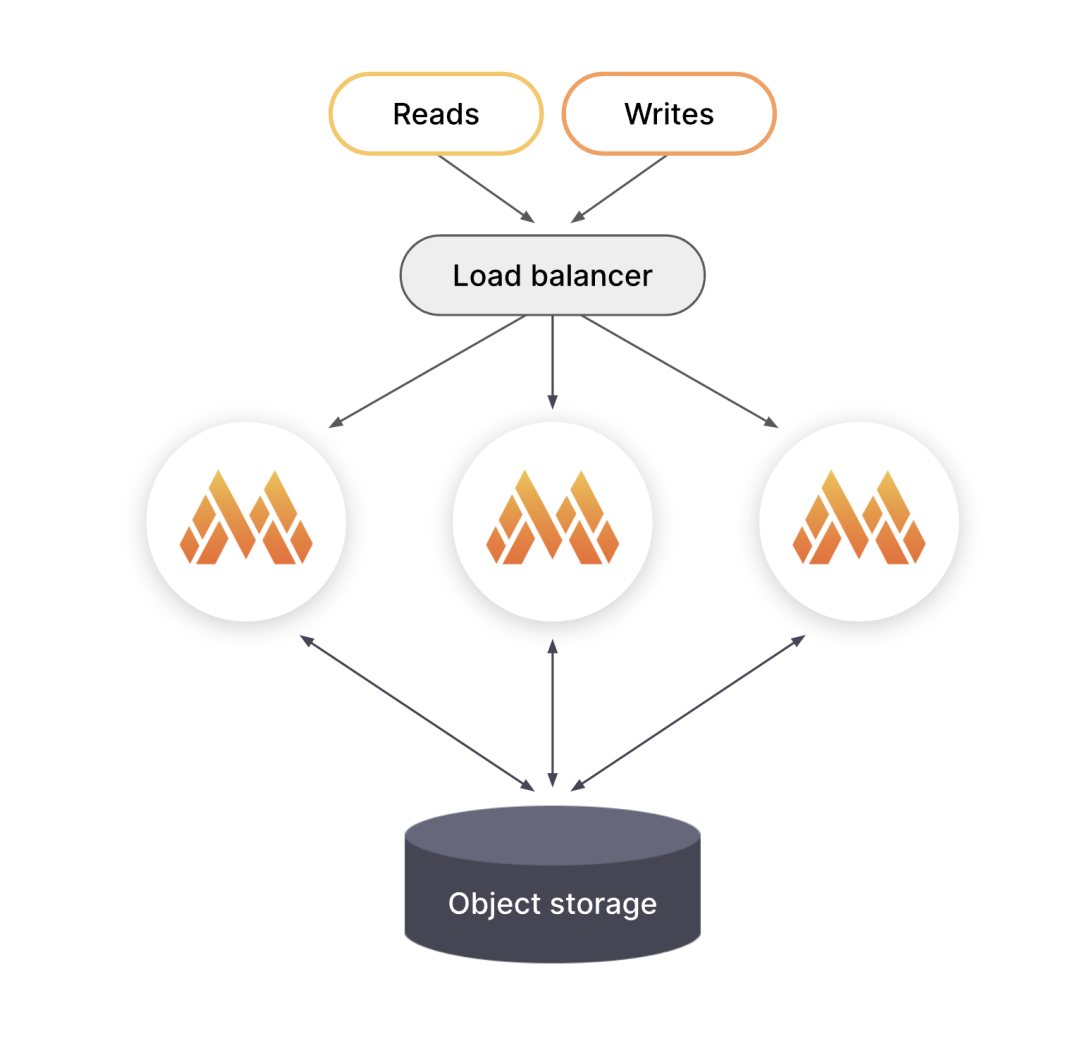
微服务模式
在微服务模式下,组件部署在不同的进程中。扩展是按组件进行的,这使得扩展具有更大的灵活性和更细粒度的故障域。微服务模式是生产部署的首选方法,但也是最复杂的。
在微服务模式下,每个 Grafana Mimir 进程都会被调用,其 -target 参数设置为特定的 Grafana Mimir 组件(例如,-target=ingester 或 -target=distributor)。要获得有效的 Grafana Mimir 实例,您必须部署每个必需的组件。
如果您有兴趣以微服务模式部署 Grafana Mimir,我们建议您使用 Kubernetes 和 mimir 分布式 Helm Chart。
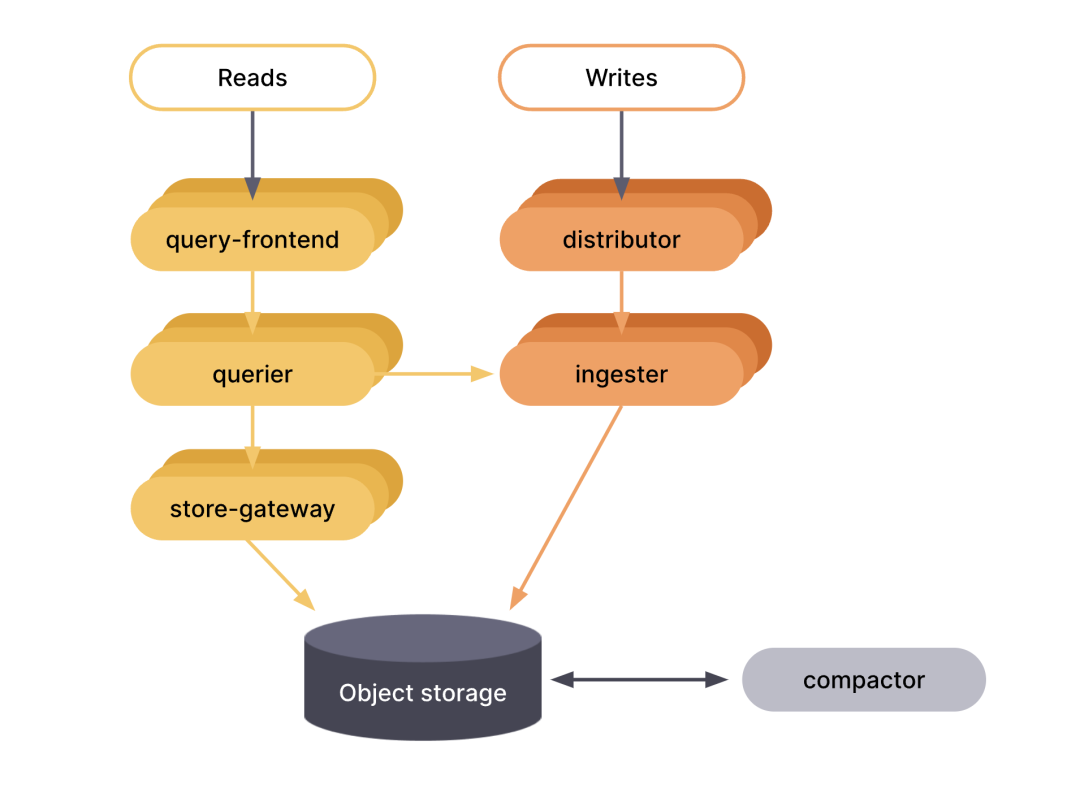
读写分离模式
读写分离部署模式目前还处于实验阶段。
读写分离模式提供了单体和微服务模式的替代方案。在读写分离模式下,组件被分为三个服务,以减轻操作开销,同时仍然允许在读取和写入路径上单独调整规模。这些服务将组件分组如下:
read
query-frontend
querier
backend
store-gateway
compactor
ruler
alertmanager
query-scheduler
overrides-exporter
write
distributor
ingester
与其他模式类似,每个 Grafana Mimir 进程都是通过将其 -target 参数设置为特定服务来调用的:-target=read、-target=write 或 -target=backend。
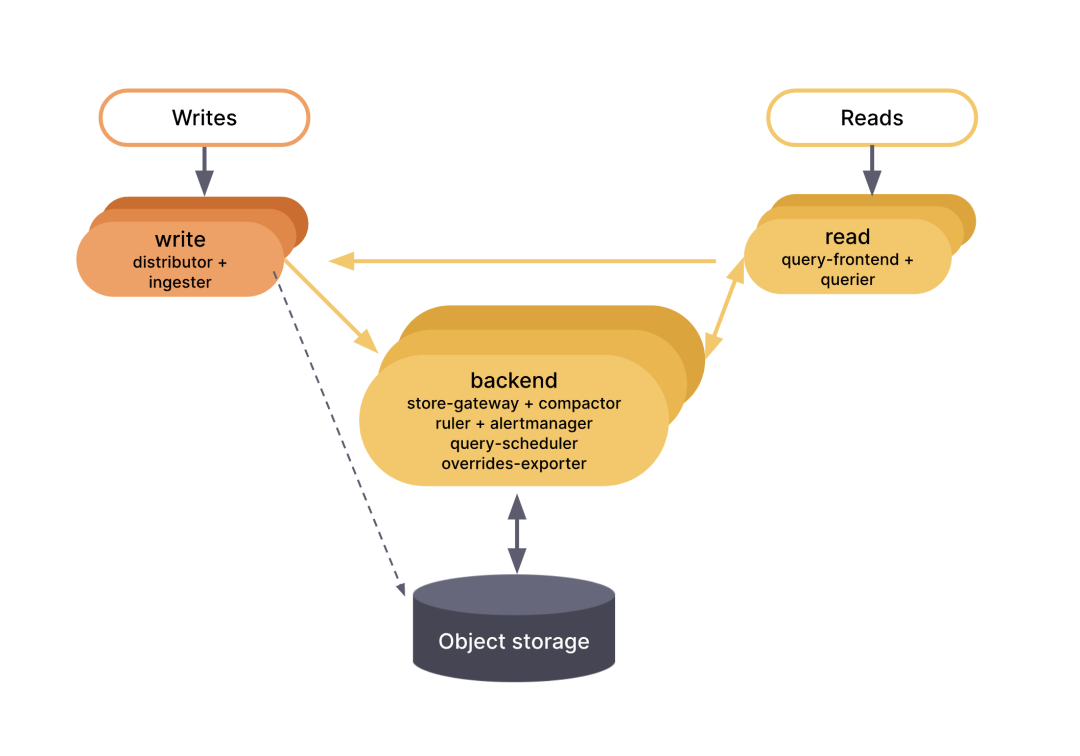
Mimir 组件
上面的不同架构中都提到了 Mimir 的组件,这里我们来看一下 Mimir 的组件。
Compactor(必备)
对数据进行清洗合并,会将ingester上传到 S3 的数据,下载然后重新进行压缩去重,最终再次上传 S3,同时也负责删除。
压缩过程支持高级特性 split-and-merge
Distributor(必备)
相当于整个流量的入口, HTTP 流量会先到达distributor,distributor 持有 ingester 的hash ring,然后通过 gRPC 并行发送给多个 ingester。
Ingester(必备)
必备组件,而且是最核心组件
如果部署,推荐还是一台主机部署一个,不要混布。
接收来自distributer的数据,并不会立刻写入到存储里,而是保存在内存,然后定期的刷新到后端存储。当查询时,会有部分请求来到ingester
Querier(必备)
查询真正的核心组件,支持 cache,可以作为最外层的查询服务,暴露 HTTP
Querier里使用的查询引擎还是PromQL,直接引用的 Prometheus 的源码
Querier将会从ingester和store-gateway分别查数据
Query-frontend(可选)
能加速查询效率(主要是切割成 N 个小范围的 query), 最终将结果做数据聚合,最终结果可以 cache
Query-scheduler(可选)
主要解决query-frontend扩缩问题,简单来说,就是query-frontend维护着任务队列还有数据聚合等操作,不想扩容query-frontend而引起内部 queue 增加。因为每增加query-frontend就会导致querier内部产生新的 worker 去拉取 queue,会导致同时处理查询的数量很大,会超过-querier.max-concurrent
Store-gateway(必备)
Querier、Ruler需要用,主要是加速查询效率,减少查询对象存储的请求数量
注意:生产环境还是需要加一层memcached,效率会提升很多,如果不使用 cache,每次都会下载 chunks
Ruler(可选)
用于评估记录和警报规则中定义的 PromQL 表达式
每个租户都有一组记录和警报规则,并且可以将这些规则分组到命名空间中
Alertmanager(可选)
Mimir Alertmanager 为 Prometheus Alertmanager 添加了多租户支持和水平可扩展性。
Mimir Alertmanager 是一个可选组件,用于接受来自 Mimir ruler 的警报通知。
Alertmanager 对警报通知进行重复数据删除和分组,并将它们路由到通知渠道,例如电子邮件、PagerDuty 或 OpsGenie。
overrides-exporter(可选)
Grafana Mimir 支持在每个租户的基础上应用覆盖。许多替代配置限制可防止单个租户使用过多资源。overrides-exporter组件将限制暴露 Prometheus 指标,以便运维人员可以了解租户与限制的接近程度。
安装 Mimir
为了和大家说明 Mimir 的使用,这里我们将通过 Docker 来使用 Mimir。
首先使用下面命令获取 Mimir 代码:
git clone https://github.com/grafana/mimir.git
导航到教程目录:
cd mimir
cd docs/sources/mimir/get-started/play-with-grafana-mimir/
该目录下面包含一个 docker-compose.yml 文件,我们可以直接使用 docker-compose 来启动 MinIO、Mimir、Prometheus、Grafana 和 NGINX:
docker-compose up
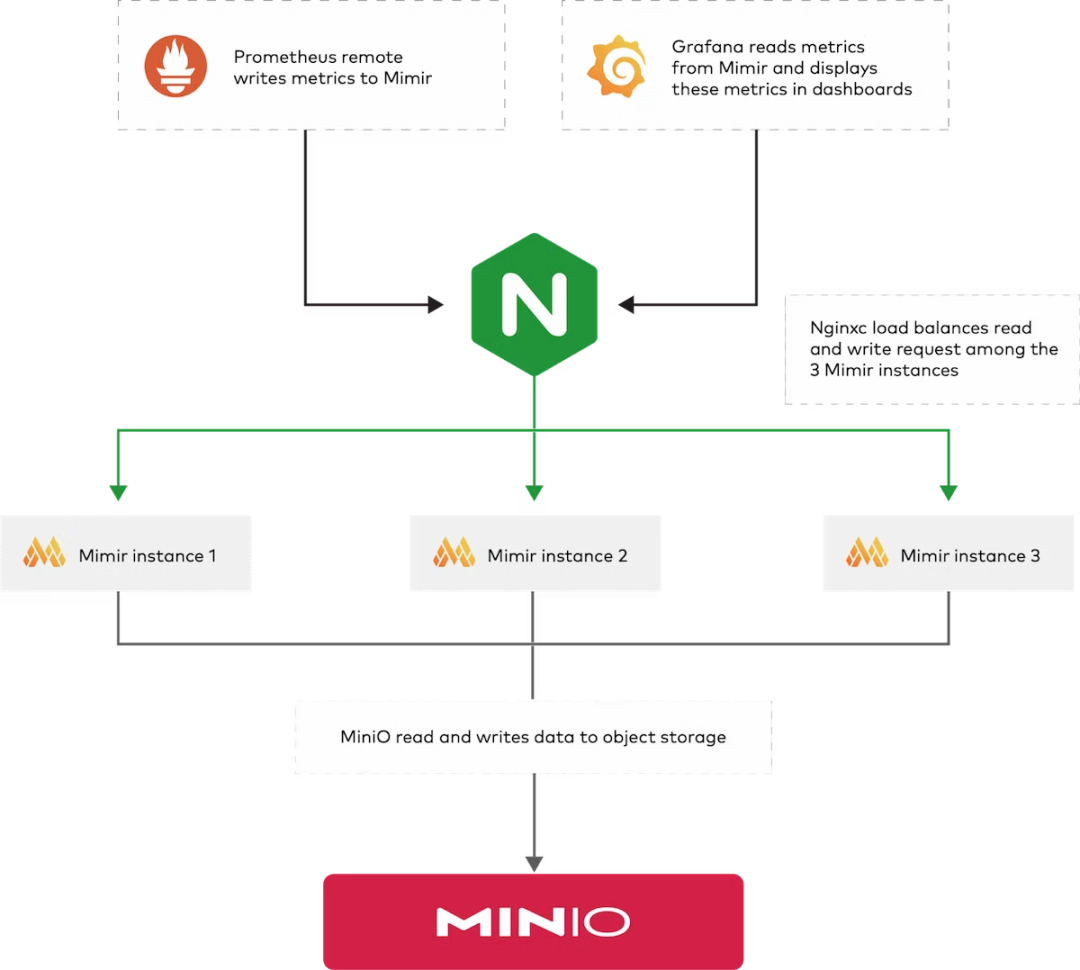
该命令会启动如下几个容器:
Mimir- Mimir 的三个实例以实现高可用性。已启用多租户(租户 ID 为demo)。
Prometheus- 抓取 Mimir 指标,然后将它们写回到 Mimir 以便它们可用
MinIO- 与 S3 兼容的软件定义的块、规则和警报的持久存储
Grafana- 包括用于查询 Mimir 的预安装数据源和用于监控 Mimir 的预安装仪表板
Nginx- 基于 NGINX 的负载均衡器,公开 Mimir 实例
启动后可以使用以下端口访问:
Grafana:http://localhost:9000
Mimir:http://localhost:9009
上面启动的服务整体架构如下所示:
我们这里启动的 Grafana Mimir 配置文件如下所示:
# Do not use this configuration in production.
# It is for demonstration purposes only.
# Run Mimir in single process mode, with all components running in 1 process.
target: all,alertmanager,overrides-exporter
# Configure Mimir to use Minio as object storage backend.
common:
storage:
backend: s3
s3:
endpoint: minio:9000
access_key_id: mimir
secret_access_key: supersecret
insecure: true
bucket_name: mimir
# Blocks storage requires a prefix when using a common object storage bucket.
blocks_storage:
storage_prefix: blocks
tsdb:
dir: /data/ingester
# Use memberlist, a gossip-based protocol, to enable the 3 Mimir replicas to communicate
memberlist:
join_members: [mimir-1, mimir-2, mimir-3]
ruler:
rule_path: /data/ruler
alertmanager_url: http://127.0.0.1:8080/alertmanager
ring:
# Quickly detect unhealthy rulers to speed up the tutorial.
heartbeat_period: 2s
heartbeat_timeout: 10s
alertmanager:
data_dir: /data/alertmanager
fallback_config_file: /etc/alertmanager-fallback-config.yaml
external_url: http://localhost:9009/alertmanager
server:
log_level: warn
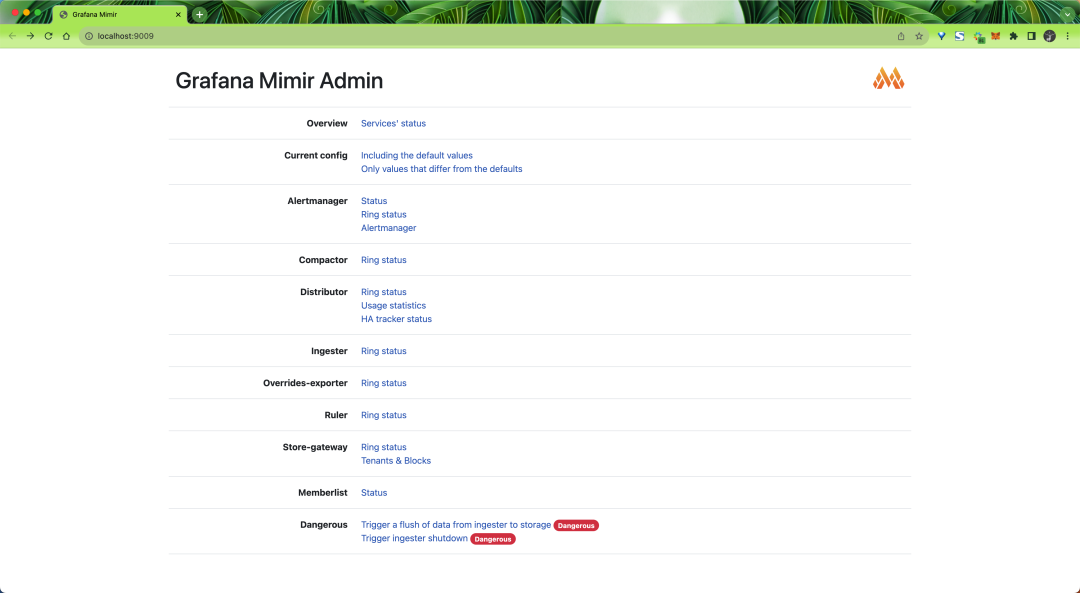
我们可以通过访问 http://localhost:9009 来查看 Mimir 各个组件的状态:
使用 Mimir
要访问 Grafana,请启动浏览器并打开 http://localhost:9000。您将使用 Grafana 查看显示 Mimir 集群状态的仪表板。仪表板向 Mimir 查询它们显示的指标。从左上角的菜单中,单击仪表板,然后单击浏览以查看已为本教程预加载的仪表板。这些仪表板来自 Grafana Mimir mixin,它将 Grafana Labs 的最佳实践仪表板、记录规则和用于监控 Mimir 的警报打包在一起。
启动容器后,指标通常需要 3-5 分钟才能显示在 Grafana 仪表板中。我们还在没有入口网关、查询调度程序或内存缓存的情况下运行 Mimir,因此相关仪表板将为空。
我们可以先浏览仪表板以进行写入、读取、查询和对象存储。例如,对象存储仪表板显示了自从我们启动 Mimir 以来发生的操作。
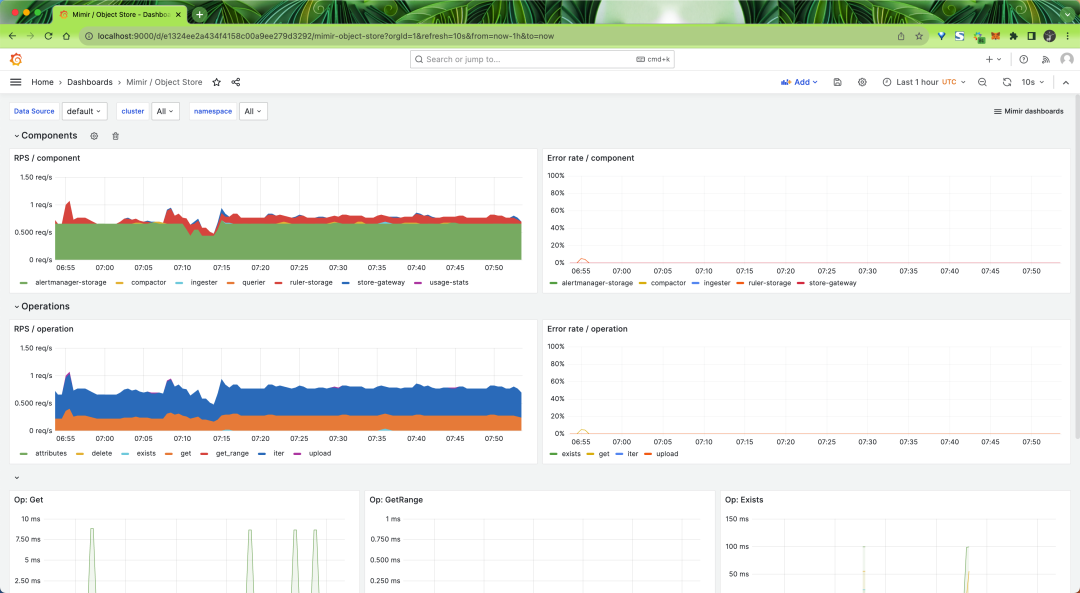
配置记录规则
记录规则是一种预先计算经常需要的或计算成本较高的表达式并将结果保存为一组新的时间序列的机制。按照以下说明我们可以使用 Grafana 在 Mimir 中配置记录规则。
比如 sum:up 记录规则将显示已启动且可进行抓取的 Mimir 实例的数量。创建规则后,即可将其查询并包含在仪表板中。
从左侧工具栏打开报警菜单页,然后点击 Create alert rule 按钮新建报警规则:
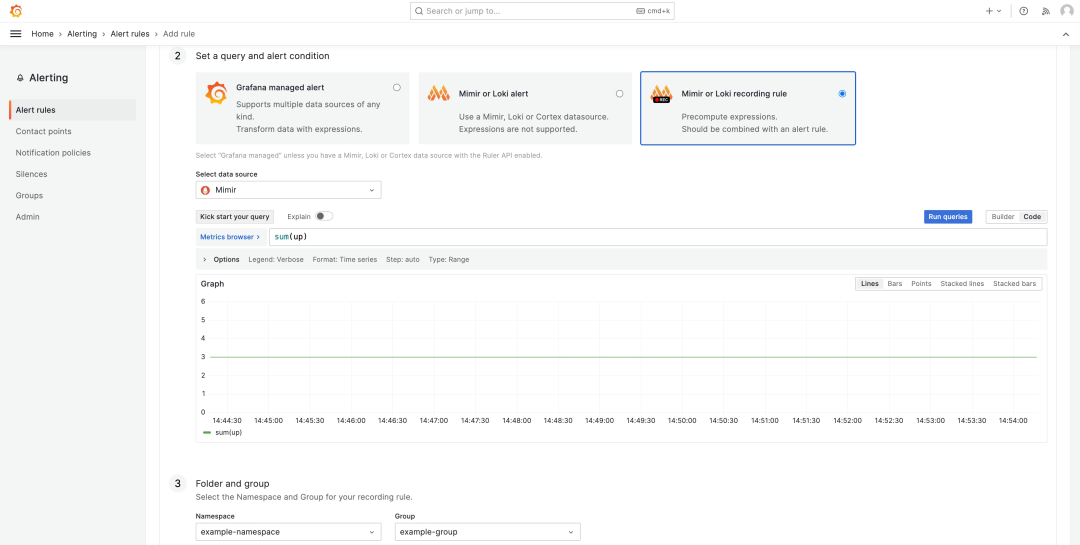
按照以下步骤配置记录规则:
选择 Mimir or Loki recording rule
填写规则名称sum:up
在选择数据源字段中选择Mimir
Namespace:example-namespace
Group:example-group
查询表达式:sum(up)
选择右上角的“保存并退出”。
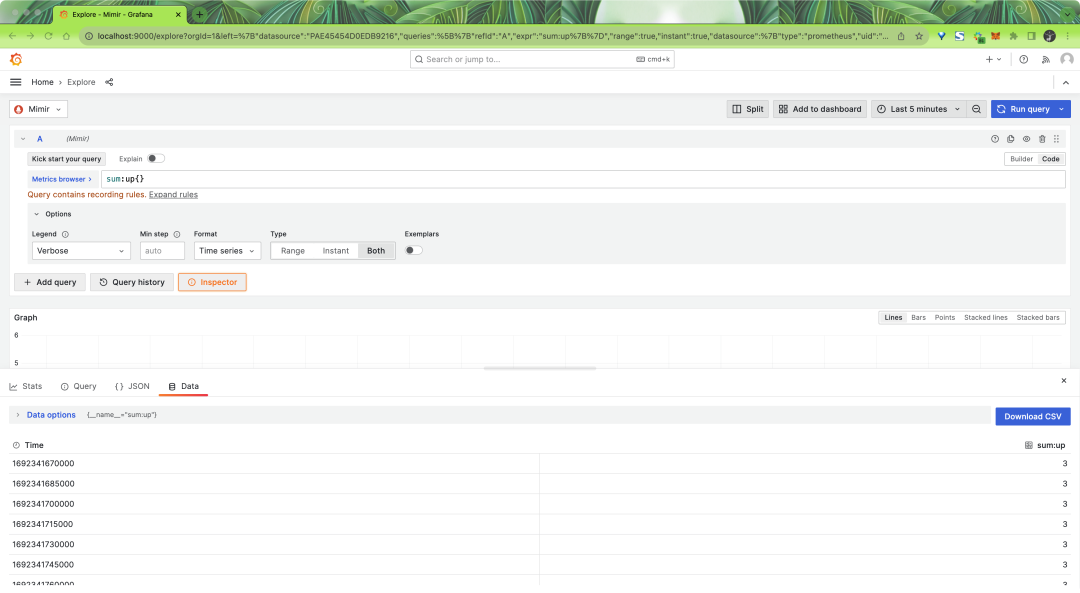
要验证新的记录规则是否正确运行,请从左侧菜单中打开 Explore 页面:
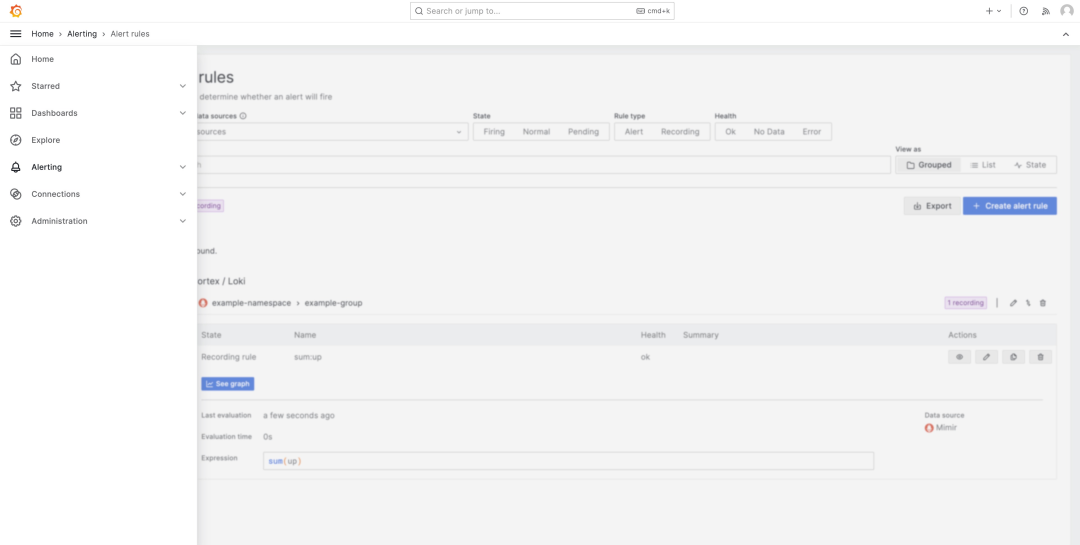
在 Metric 下拉列表中,选择 sum:up ,然后单击右上角的 Run query,然后单击 Inspector 按钮。在下面,单击 Data 可查看时间列表和查询结果。结果应该是3,表明 Mimir 的三个本地实例正在运行。
配置报警规则
基于 Mimir 构建的报警规则遵循与基于 Prometheus 和 Loki 构建的报警规则相同的 PromQL 格式。Grafana 评估表达式,并在必要时使用 Alertmanager 发出警报。
这里我们将创建一个报警,当 Mimir 实例的数量降至三个以下时触发。同样在左侧菜单中,点击 Alerting,然后切换到 Alert rules 页面,然后单击 Create alert rule。
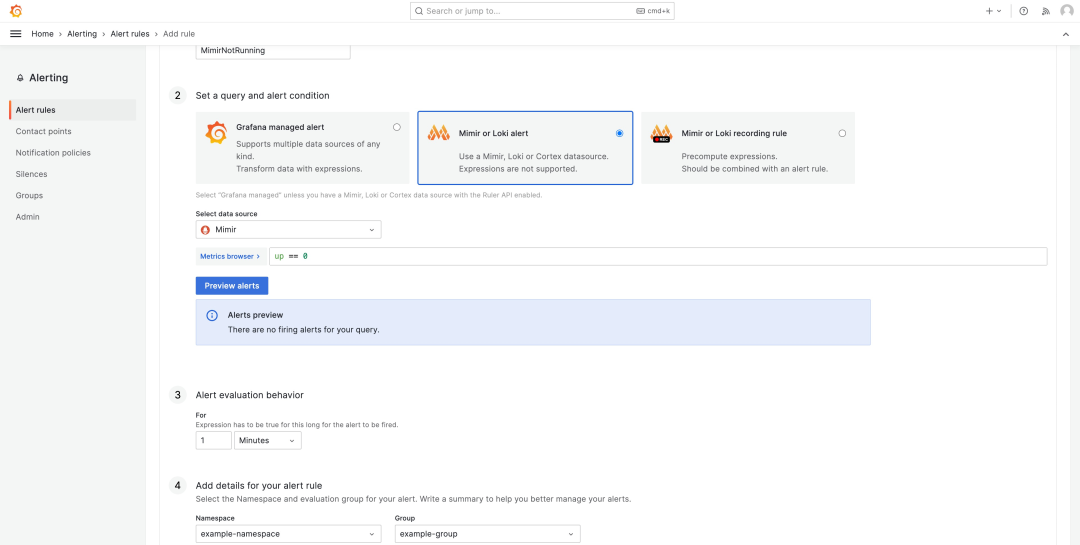
现在我们需要选择 Mimir or Loki alert,然后按照以下步骤配置报警规则:
规则名称:MimirNotRunning
在选择数据源字段中选择 Mimir
Namespace:example-namespace
Group:example-group
查询表达式:up == 0
选择右上角的“保存并退出”。
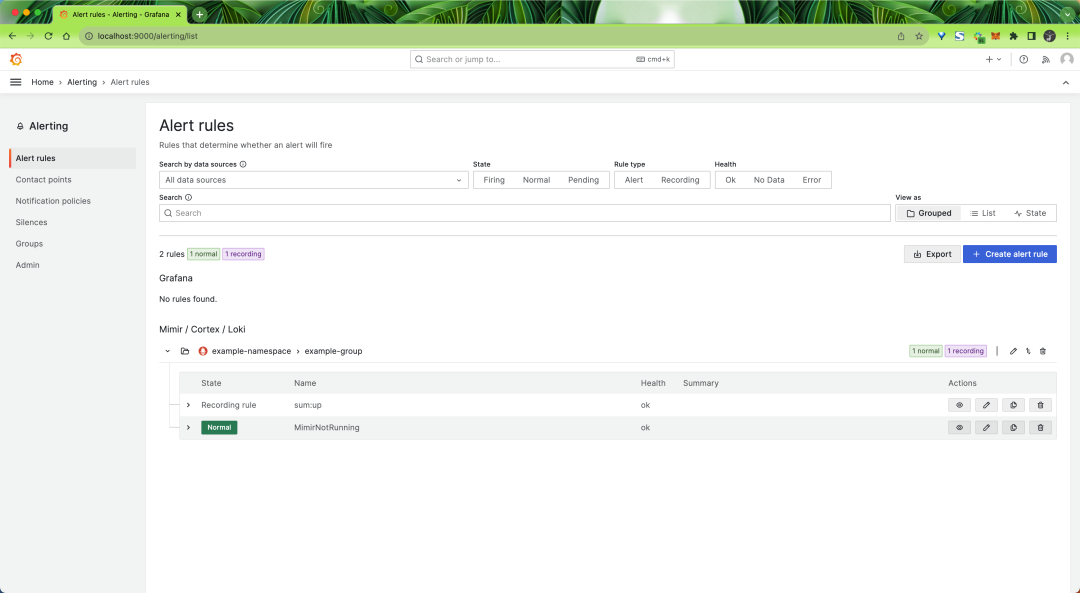
创建完成后我们将看到我们的 Mimir 记录规则和警报规则。请注意,警报旁边显示了一个漂亮、大、舒适的绿色正常状态,因为我们所有的 Mimir 容器仍在运行。
现在我们通过终止三个 Mimir 实例中的一个来模拟错误情况(确保您位于 docs/sources/mimir/get-started/play-with-grafana-mimir/ 目录中):
$ docker-compose kill mimir-3
[+] Running 1/1
⠿ Container play-with-grafana-mimir-mimir-3-1 Killed 0.2s
➜ play-with-grafana-mimir git:(main)
由于我们突然终止 Mimir 实例,Grafana 在查询规则时会短暂显示错误。一旦 Mimir 的内部运行状况检查检测到已终止的实例运行状况不佳,此问题就会自动解决。
大约一分钟后,报警将很快显示黄色 Pending 待处理状态:
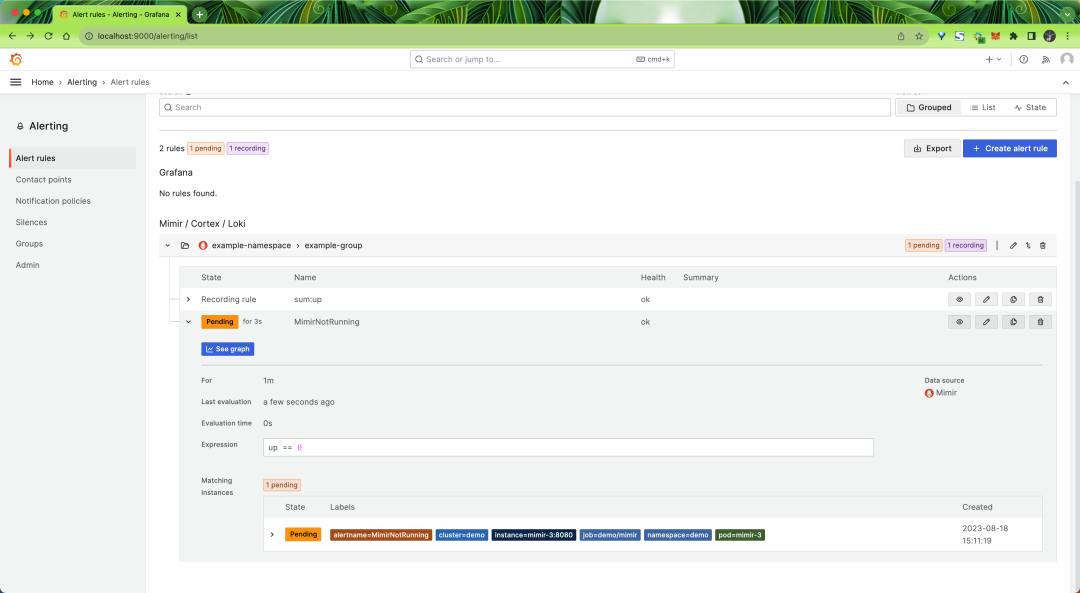
再过一分钟,警报将变为红色 Firing 触发状态:
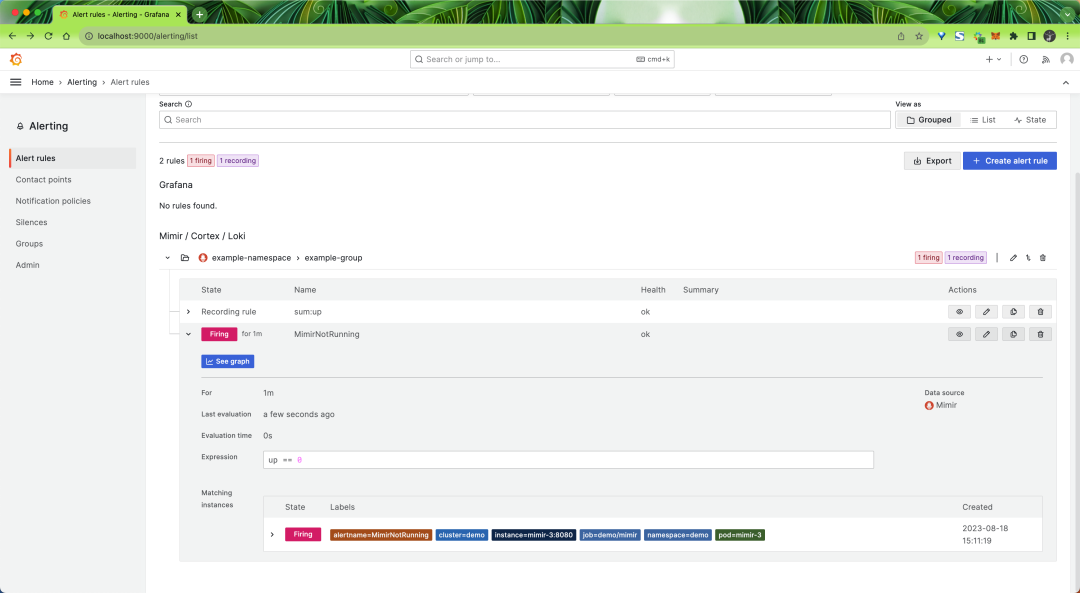
如果我们为 Alertmanager 配置了通知通道,报警就会向适当的机制和联系人发出。
在我们恢复终止的 Mimir 实例之前,请返回 Grafana 中的 Explorer 页面并查询我们的 sum:up 记录规则。我们可以看到,即使 Mimir 实例已关闭,Mimir 仍继续正确记录指标。
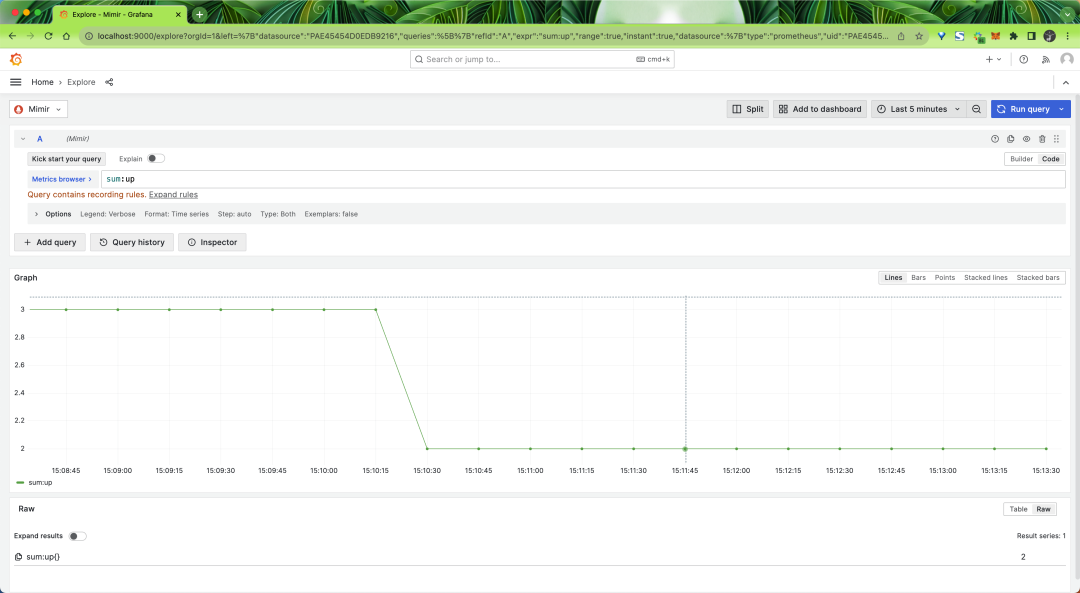
最后,我们恢复 Mimir 实例:
$ docker-compose start mimir-3
[+] Running 1/1
⠿ Container play-with-grafana-mimir-mimir-3-1 Started 0.2s
➜ play-with-grafana-mimir git:(main)
返回报警页面,您会发现我们的报警状态很快会恢复正常。
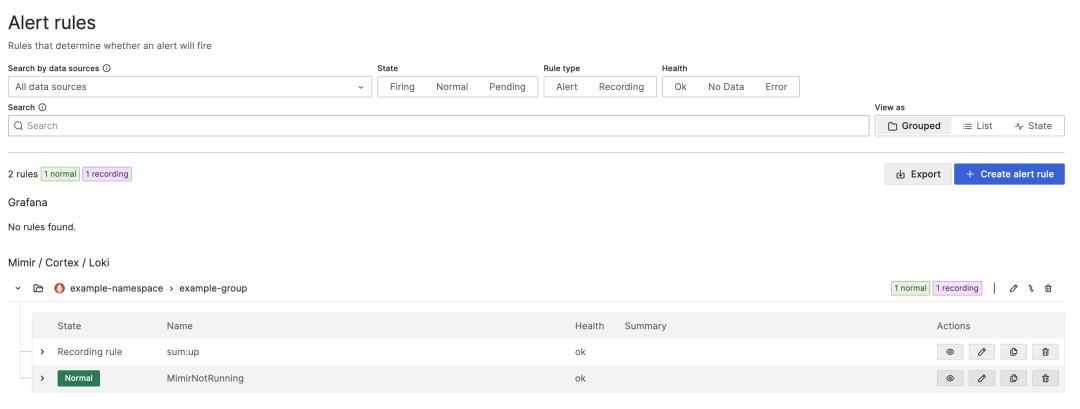
这里我们使用 Mimir 本身的 Prometheus 指标,然后在 Grafana 中查询和可视化它们。我们还配置了记录规则和警报,并验证了满足条件时警报是否按预期触发。您还可以配置 Mimir 和 Grafana 从 MinIO 中抓取 Prometheus 指标,并通过 AlertManager 发出警报。Mimir 将数据存储在对象存储中以实现持久性,从而使其能够利用无处不在、经济高效且高耐用性的 MinIO。