
AIoT领域需要什么样的数据基础架构?【AIoT产业年会演讲分享】

导读
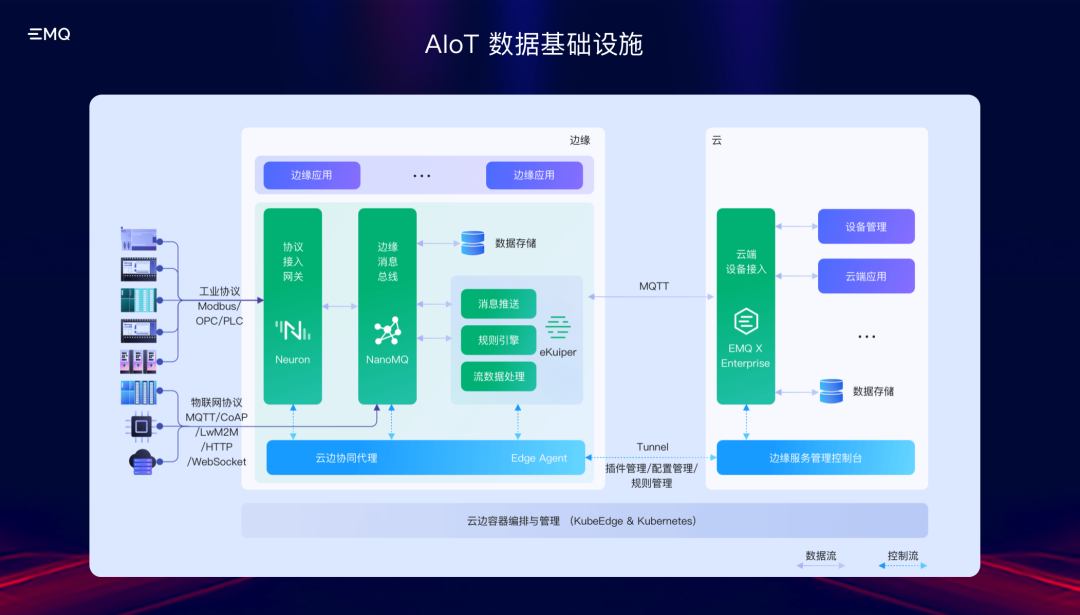
为了保障物联网数据的充分流动和有效利用,除了通信技术本身的连接能力外,还需要打通物联网各层架构之间的壁垒,才能实现数据采集、传输、处理、分析全生命周期的管理,进而让数据真正发挥“物联网时代石油”的价值。EMQ映云科技是一家在物联网数据基础设施领域深耕多年的企业,在2021中国AIoT产业年会上,EMQ映云科技解决方案VP余杰霖为大家带来了题为《EMQ:AIoT的数据基础设施》的精彩演讲。以下是其演讲全文分享:


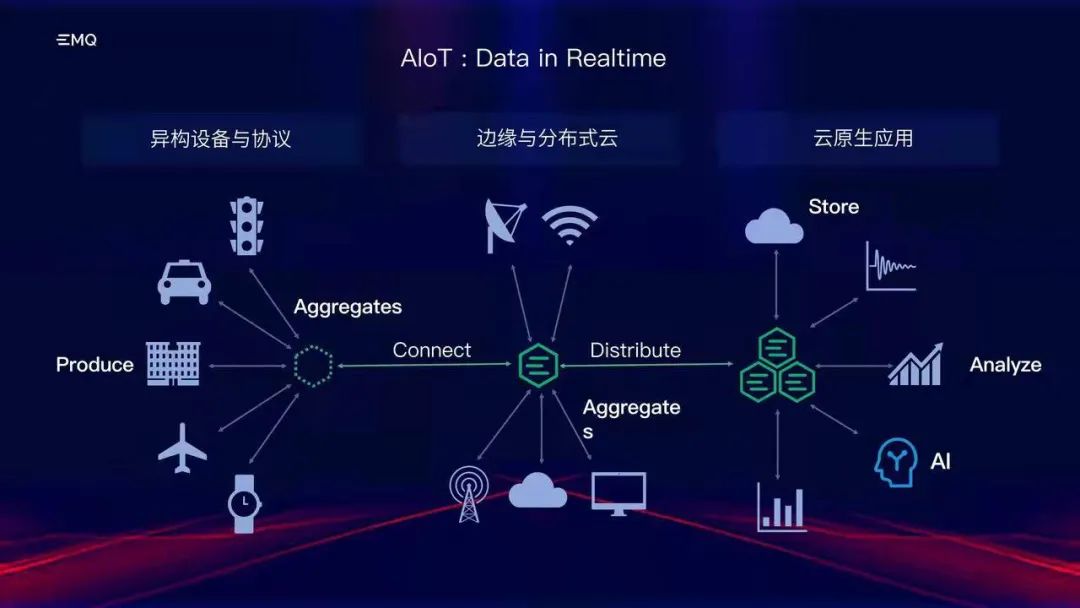


数据生产主体和产生方式
数据类型
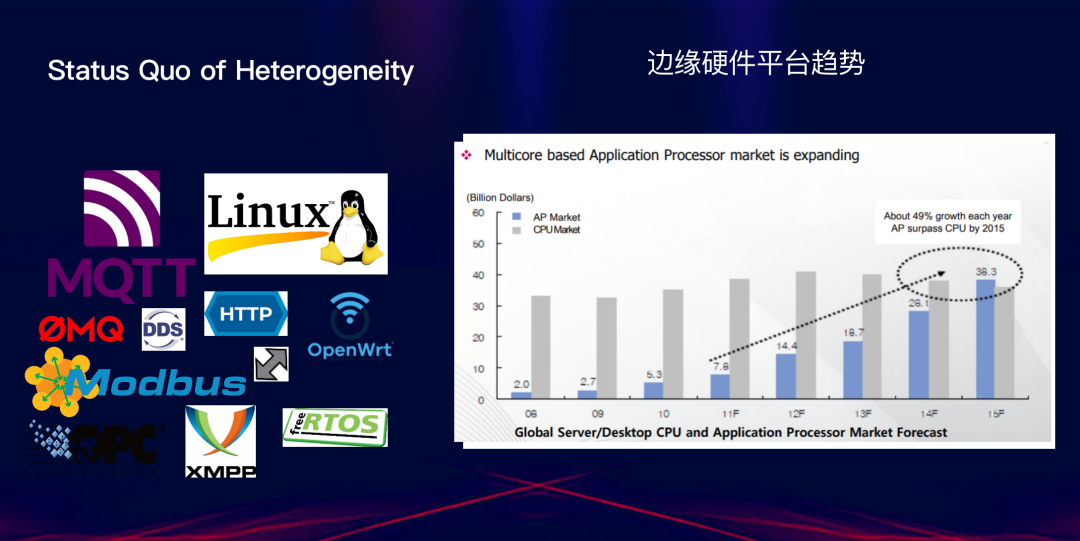
数据体量
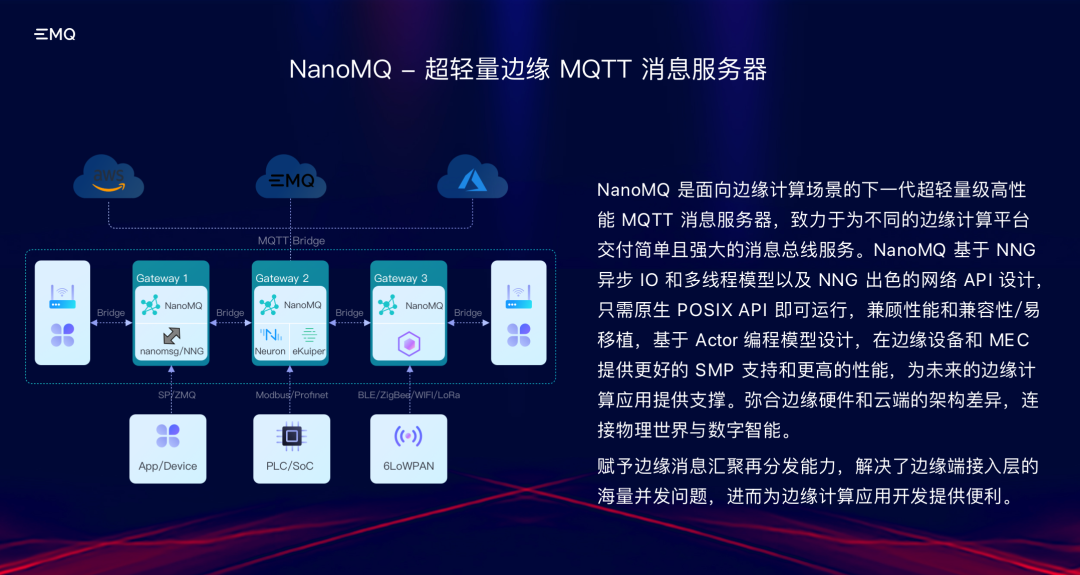
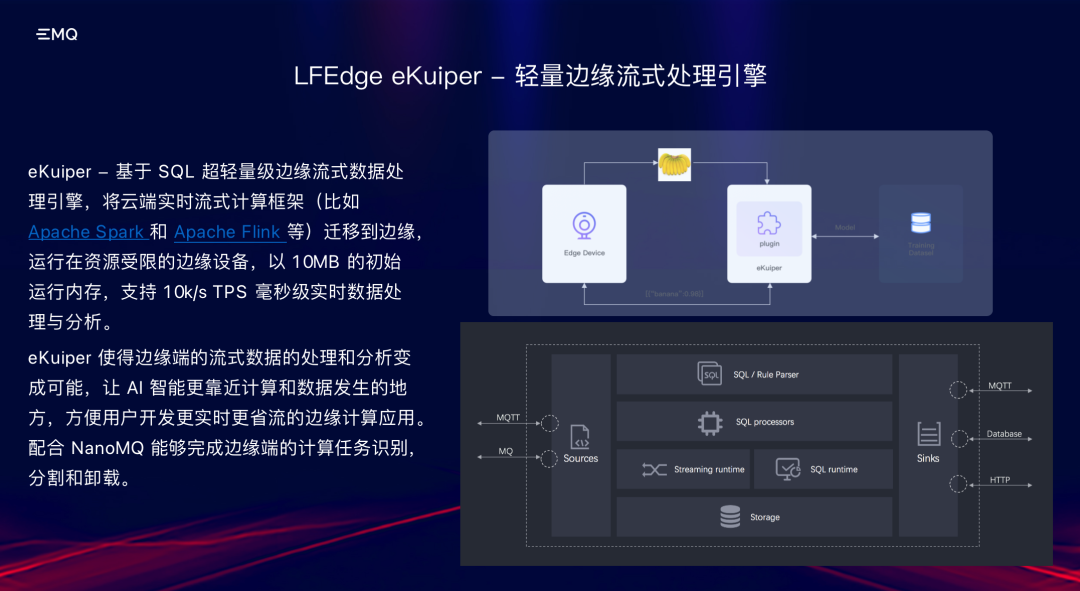
数据处理

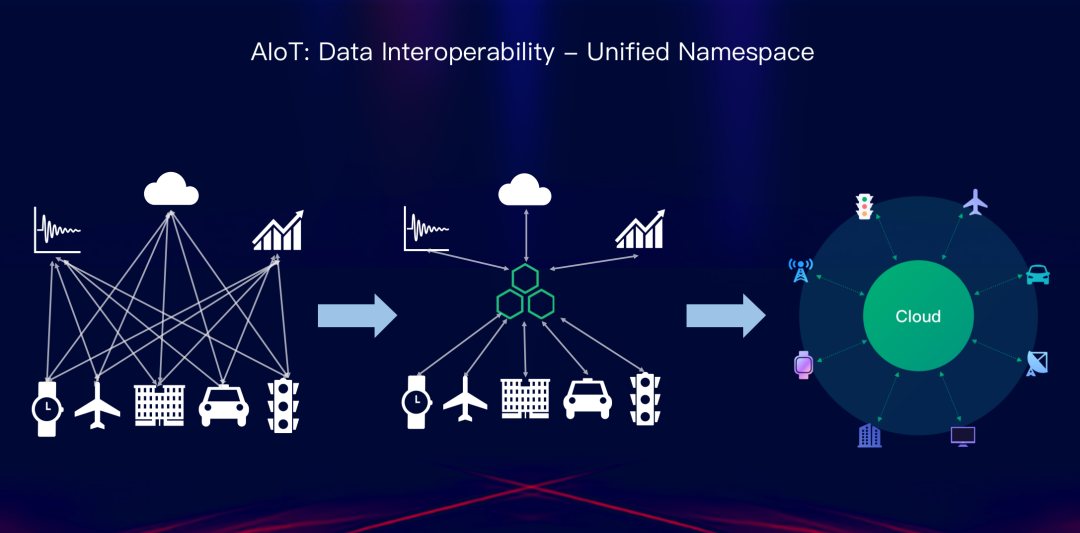
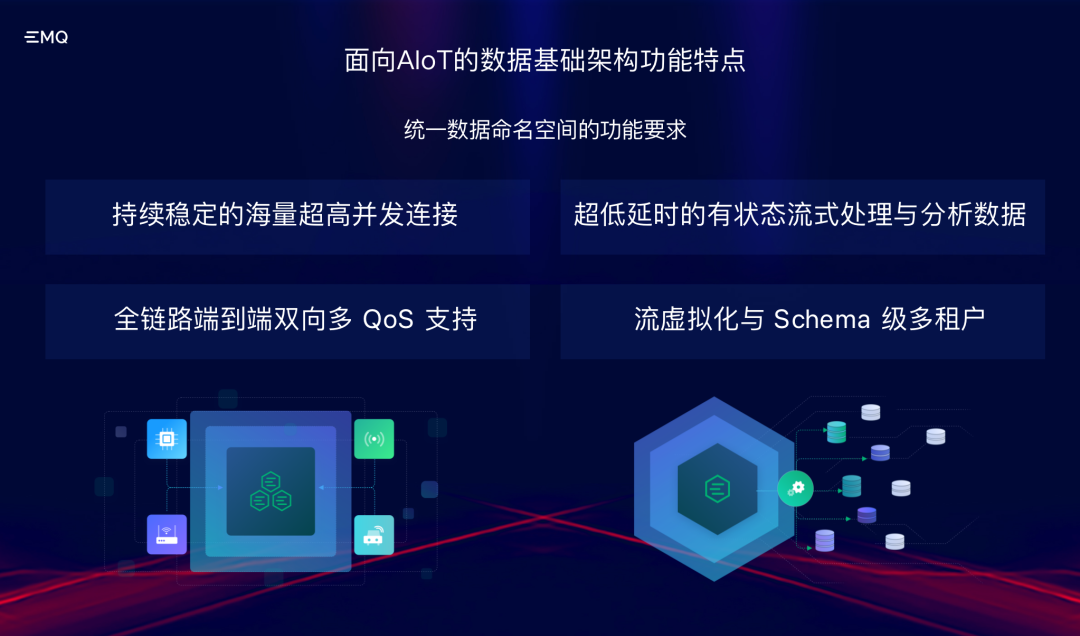
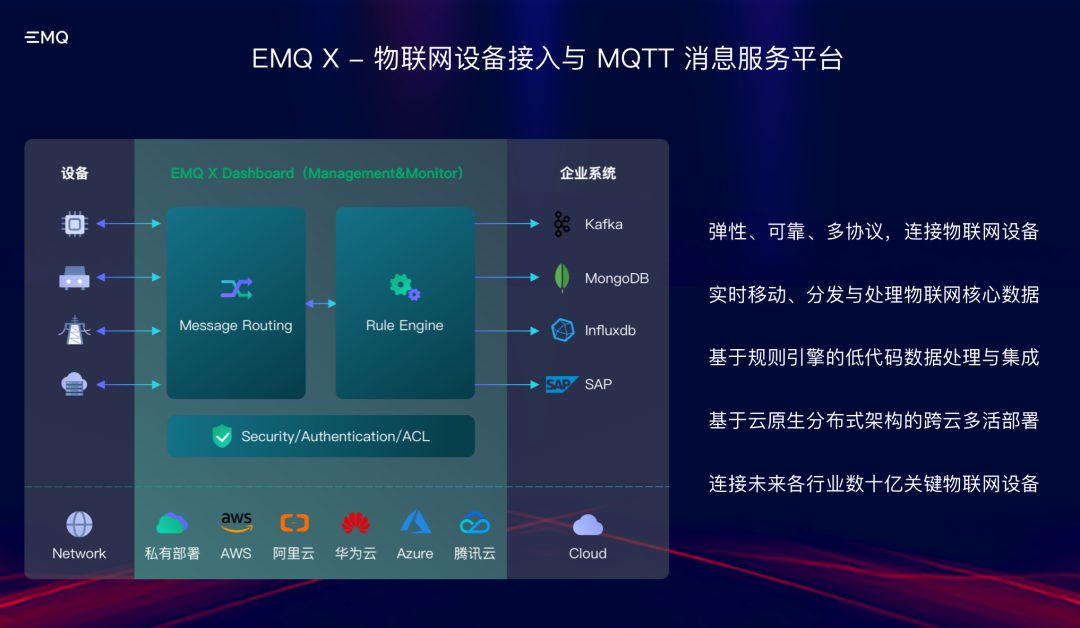




3月31日,深圳
中国万物智联大会——工业物联网专场
诚邀您的参与~
评论