
推荐领域开创性论文,详解阿里巴巴DIN模型
点击上方蓝字,关注并星标,和我一起学技术。
大家好,今天来聊聊推荐领域一篇很重要的paper,它就是阿里巴巴18年发表的Deep Interest Network for Click-Through Rate Prediction,也就是深度兴趣网络模型,简称DIN。
摘要
众所周知,CTR预估在搜索、推荐、广告领域都占据着举足轻重的作用。随着深度模型在推荐领域的兴起,离散特征的Embedding被越来越广泛地使用。用户或者是商品的离散特征会被转化成固定长度的向量,经过一系列转化之后,将这些向量拼接在一起作为MLP的输入,最后训练得到结果。
这样的模型取得了不错的效果,但是也有瓶颈,它最大的瓶颈就在于转化之后得到的向量长度是固定的。它只包含user以及item本身的特征,丢失了用户之前的历史行为,这些行为当中往往隐藏着用户大量的兴趣以及偏好的信息。在本篇paper当中,我们推出了一个新的模型DIN,它可以通过使用local activation unit从用户历史行为信息,从而提升模型的表达能力。
简介
在CPC广告系统当中,CTR的预估非常重要。所谓的CPC指的是cost-per-click,也就是按点击扣费,这也是淘宝等电商平台最常用的广告扣费模式。商家通过竞价排名来购买广告从而获得广告曝光的机会,当用户实际发生点击的时候才会进行扣费。对于广告展示平台来说,为了追求利益最大化,每次应该展示获得的收益期望最大的广告。
这个期望也就是CTR * bid price,这里的bid price也就是商家对于广告的竞价,这个是一个已知的变量。而CTR也就是商品的点击率,这是一个后验的概率,无法提前得到,所以只能通过模型来预测。因此CTR的预测对于广告来说至关重要,它会直接影响广告平台的收入。
截止到论文发表时,主流的CTR预估的模型都是通过将离散特征转化成Embedding的方式来进行的。这样的结果是user的特征转化之后得到的长度是固定的,说白了,一个广泛活跃的用户和一个几乎不活跃的用户转化得到的特征长度是一样的。反而用户的兴趣可能是广泛的,一个人可能既对球鞋也对游戏机感兴趣,如果我们只用用户整体的行为来构建特征,那么往往只能得到单一的兴趣。因此这是模型一个很大的瓶颈,本篇paper就是围绕这一块内容展开的。
从另一个角度来说,我们也没有必要把用户所有的兴趣全部压缩,因为当用户看到一个商品时,他是否会有点击往往是由他兴趣的一个部分驱动的。比如对于一个上周买了游戏机的人来说,他这周点击游戏的概率要明显大于手机。我们希望模型能够学习用户某个历史兴趣以及当前行为之间的联系。DIN模型会根据目标展示的item信息,自动表示出用户兴趣的Embedding。
背景
对于电商网站来说,广告非常重要,由于广告的内容往往就是商品,所以我们可以把广告看成是item。下图简单展示了广告展示的过程。
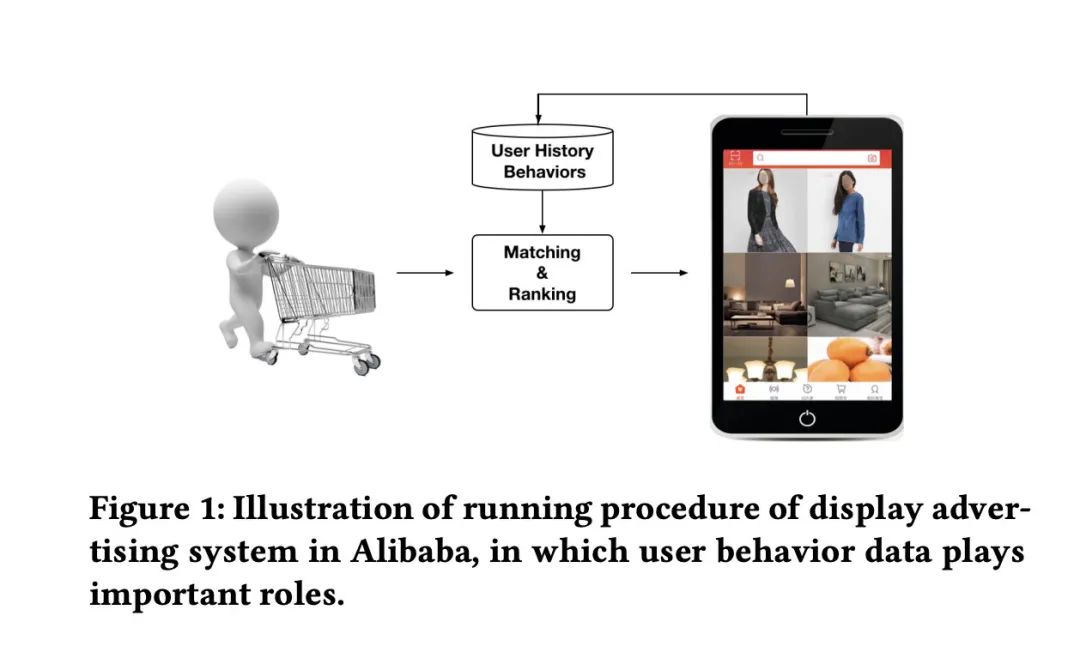
一个是召回过程,根据用户的行为以及相关上下文信息进行商品的召回。第二个是排序的过程,根据用户以及商品的信息预测它的CTR,根据预测出来的CTR从高到低进行排序,挑选出CTR最高的商品进行展示。
每天都有数以百万的用户在平台留下大量的信息,值得注意的是,拥有丰富历史行为的用户往往也有这丰富的兴趣。比如一位年轻的妈妈,最近浏览过毛大衣,T恤,耳环,手包和儿童外套,这些行为数据背后能够反映她的兴趣。这样当她再次来到平台的时候,系统就会根据她的兴趣推荐符合她兴趣的商品,比如新款的手包。关于用户兴趣的识别以及表达是本文的重点,我们将会在之后的内容详细阐述。
DIN网络
特征表示
在CTR预估的场景当中categorical形式的特征往往都会被转化成多组Embedding向量,比如性别是一组,每周周几是一组,商品的类别也是一组。比如[weekday=Friday, gender=Female, visited_cate_ids={Bag,Book}, ad_cate_id=Book]这样一组特征在编码之后的结果可能是[4, 19, 21],然后再通过这些索引找到对应位置的Embedding向量。
我们把第i个特征转化得到的向量写成,这里的表示的是i所在的特征组的维度,也可以理解成Embedding的长度。表示这个Embedding第j个元素,它是一个0到1的浮点数,,如果k=1就是one-hot特征,如果k > 1则说明是multihot特征。这样的话一条样本就可以表示成:。因为我们通常所有的Embedding都拥有一样的维度,所以它们的上标都写成T。
这样我们可以把[weekday=Friday, gender=Female, visited_cate_ids={Bag,Book}, ad_cate_id=Book]这组特征表示为:

其中weekday、gender、ad_cate_id是one-hot特征,visited_cate_ids是multihot特征。
论文当中还提供了常用的一些特征的维度表:

基本模型
这里的基本模型主要介绍的是主流的推荐领域的模型,也就是Embedding&MLP结构的模型。在这篇论文当中将它称为基本模型。
我们可以参考下图:
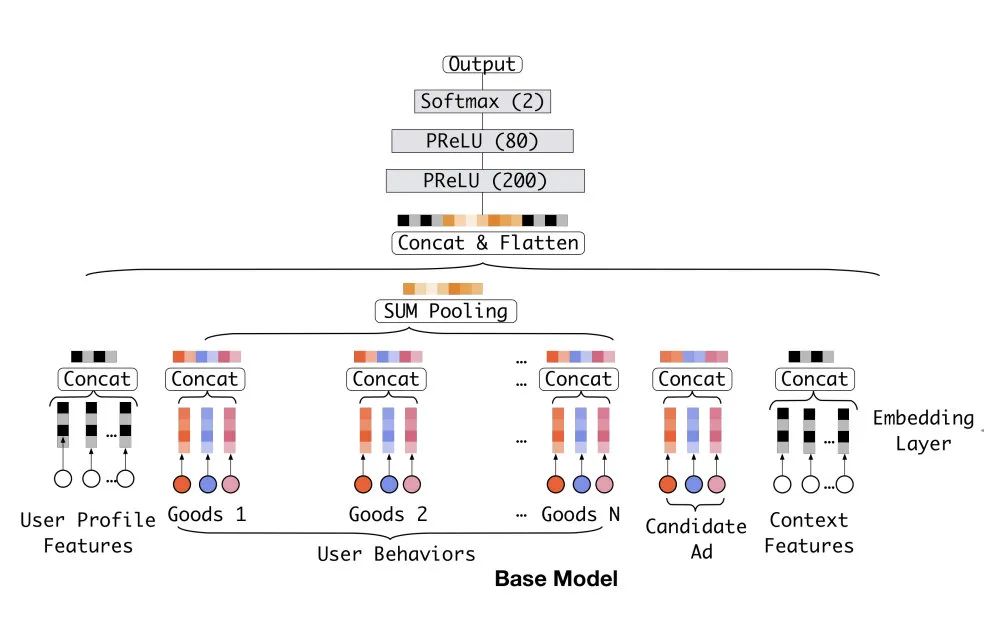
Embedding层
模型的输入一般都是高纬度的01向量,Embedding层的用处就是将这些categorical的向量转化成低维度的Embedding向量。这个很好理解, 比如我们特征所有的维度是M,Embedding的长度是D,那么模型会生成一个M x D的二维向量。假设有一个特征的index是21,那么在做Embedding的时候就会从这个M x D的二维向量当中取出它的第21行作为这个特征的Embedding,这个操作被称为lookup。
multihot和onehot的操作类似,同样是生成索引查找对应的Embedding。只不过onehot只会查找一个,而multihot往往会查找多个。
pooling层和concat层
pooling层同样在深度学习模型当中广泛使用,它的主要作用是对tensor进行压缩。比如我们现在有10个长度为20的向量,我们可以把这些向量类加在一起,也可以计算它每一位的均值。一般来说常用的pooling操作也就只有这两个,sumpooling和avgpooling。它的公式可以简单写成:
concat层也很好理解,我们经过模型处理得到的tensor往往不止一个,比如连续性特征组成的tensor,onehot组成的tensor,用户特征组成的tensor等等。对于这些tensor我们不可能都pooling到一起,否则会丢失信息,所以这个时候一个比较好的方法就是把这些tensor拼接在一起,最后将拼接之后的结果作为MLP的输入。
MLP和Loss
MLP和Loss这两个很好理解,MLP就是多层感知机,也就是最普通的DNN。
而Loss一般用交叉熵,公式可以写成:
DIN结构
最后终于到了本文的重头戏,也就是DIN结构。
DIN模型主体依然借用的基本模型,只不过其中加入了DIN结构,也就是下图红框当中标记出来的部分。
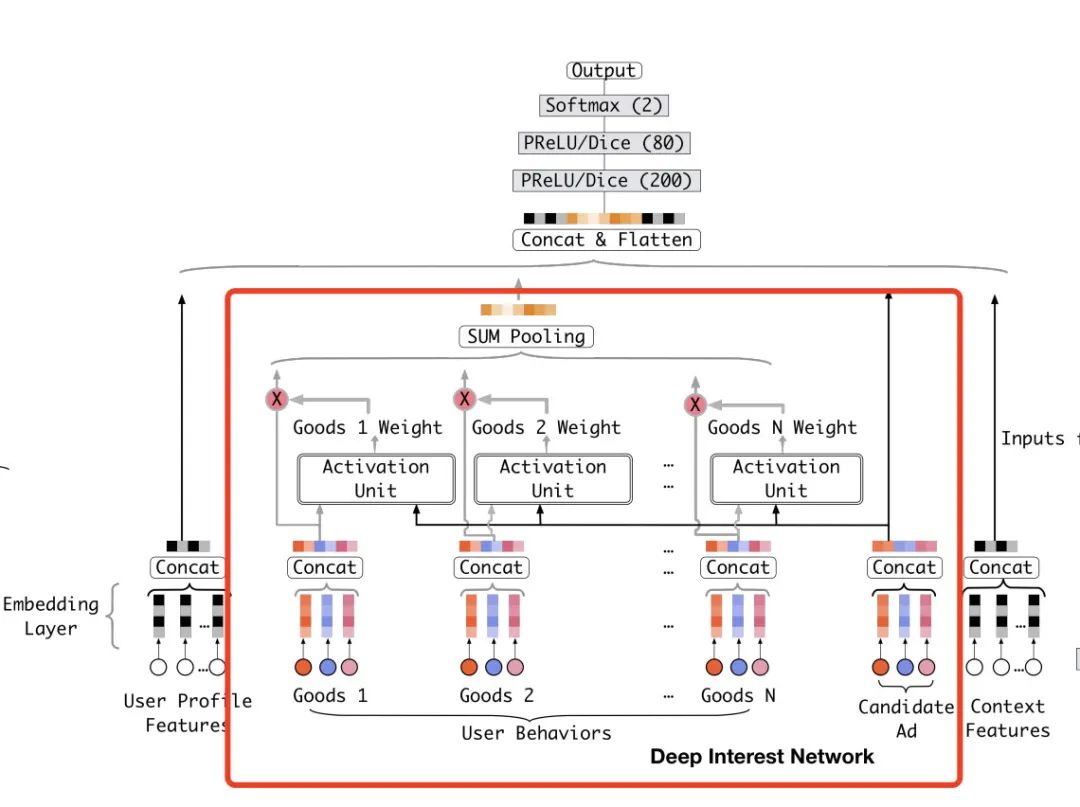
这里的User Behaviors表示的用户历史的行为,可以理解成用户有过行为交互过的商品集,当中的每一个Good表示一个商品。对于每一个商品我们会选择它的几个特征做Embedding,图中画的是3个,实际我们实现的时候可以进行调节。然后我们把这几个Embedding拼接到一起作为整个商品的Embedding。
之后每一个商品的Embedding会和当前候选商品的Embedding一起进入Activation Unit当中去计算得到权重,表示这个商品与当前候选的相似度或者是关联度。这个Activation Unit的部分论文当中也给与了详细的展示,如下图:
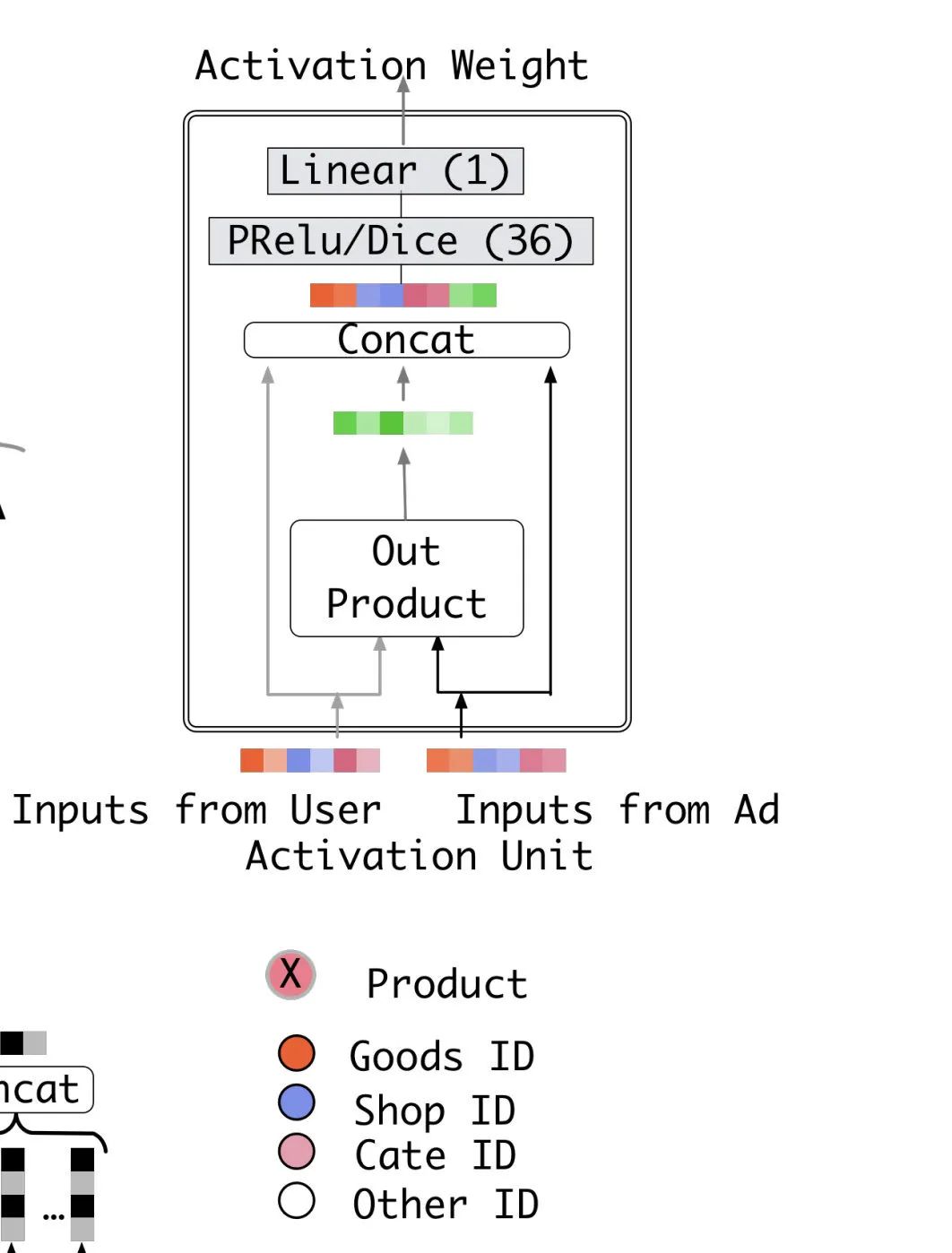
用户历史行为有过交互的商品与候选商品的本质是一样的,都是商品,所以它们转化成Embedding之后的维度相同。然后我们将它们的Embedding进行out product运算,再将这个out product的结果与输入的两个item Embedding concat到一起作为一个MLP的输入,MLP的输出结果为一个单一的权重。
为了保证这个权重的值不会太大,我们在进行sum pooling之前往往还会进行softmax操作,保证加权的和为1。
最后我们看下模型实验的结果,原论文当中选择了亚马逊以及阿里自己的数据集作为验证的标准。
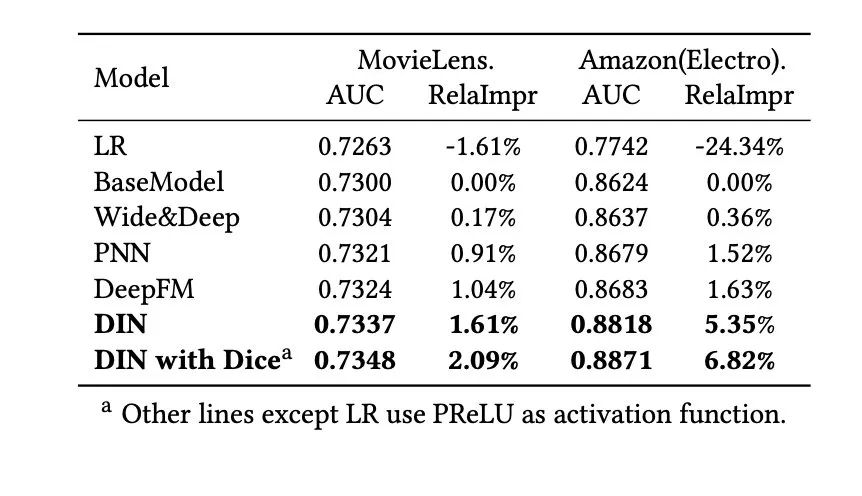
我们可以看到在这两个数据集当中,DIN模型的效果都是最好的。
总结
到这里整个DIN模型的原理和模型细节就算是讲解完了,原paper当中还有一些其他的技术细节,比如大规模参数进行正则运算的方法等等,这些内容相对不太重要,因此就不过多赘述了,感兴趣的同学可以去阅读一下原文详细了解一下。
DIN模型和之前介绍的FM家族等模型相比是一个飞跃,因为它开创性地引入了用户历史行为的序列,获得了更多的信息,并且良好地表达了这些信息,因此产生了非常好的效果。也就是说它效果好不仅是模型的结构改进带来的,也是因为引入了更多的特征和更多的信息,这也印证了那句话,数据决定了效果的上限,而模型只能是逼近这个上限。
好了,今天的文章就到这里,感谢大家的阅读,如果喜欢本文的话,不要忘了三连。