
[AAAI 2022] BROS:一种专注于文本和版面信息的预训练语言模型,用于更好地抽取文档关键信息(有源码)
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达

本文简要介绍AAAI 2022录用论文“BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents”的主要工作。
一、研究背景
文档信息抽取是指从文档图片中提取关键信息的过程,主要包括实体抽取和实体连接两个子任务,分别是指从文档中提取出有实际意义的一组单词从而构成实体,和将语义上同属一组的实体连接起来的过程,是机器人过程自动化的基本任务之一。由于它需要理解文档版面中包含的文本信息,这是一个需要计算机视觉和自然语言处理技术结合的任务。早期的研究没有利用版面信息完成任务,而近期的研究对此进行改进时引入的视觉信息带来了额外的计算成本,并且空间特征和文本特征结合的方式仍不够高效[1][2][3]。

二、方法原理简述
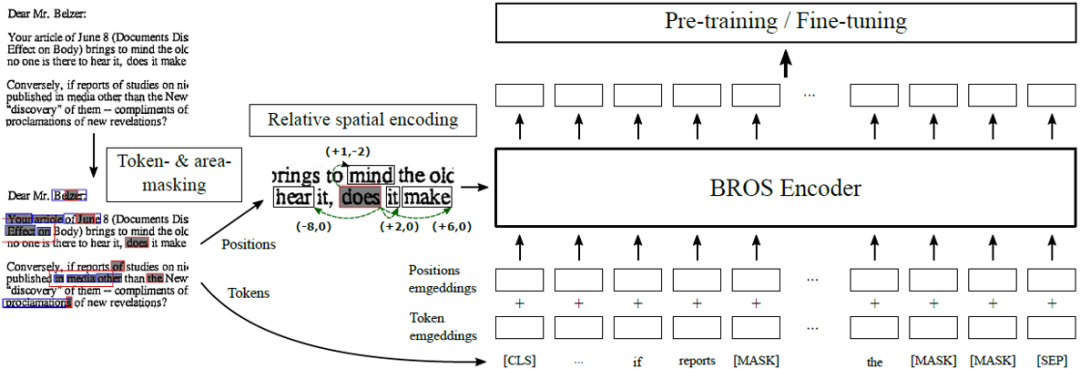
图2 网络整体框架图
图2是这篇文章的整体结构,它的骨干网络BROS Encoder采用了与BERT[4]一致的结构,并用BERT的预训练权重进行初始化。
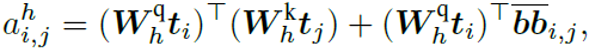
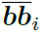 就是与版面信息相关的偏置项,与第i个单词的检测框和第j个单词的检测框的左上角点、右上角点、左下角点和右下角点的相对位置有关,由下面公式计算得到。
就是与版面信息相关的偏置项,与第i个单词的检测框和第j个单词的检测框的左上角点、右上角点、左下角点和右下角点的相对位置有关,由下面公式计算得到。 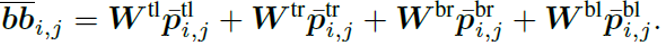
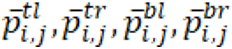 分别代表第i个单词和第j个单词的检测框中上述四个角点坐标的差值经过正弦函数变换后的结果,如下面的公式所示。
分别代表第i个单词和第j个单词的检测框中上述四个角点坐标的差值经过正弦函数变换后的结果,如下面的公式所示。 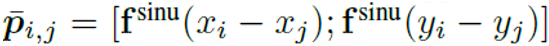
具体来说,Token-masked Language Model与BERT[4]和LayoutLMv2[1]中的一致,即对文档中的单词进行随机掩码,通过上下文信息预测掩码处的单词。如图3所示,其中红色框为选中的token,灰色区域则是单词的掩码。

图3 Token-masked Language Model示意图
Area-masked Language Model则是对文本检测框落入某一区域内的单词进行随机掩码,并预测掩码处的单词,其示意图如图4所示。具体来说,可以分为四步:
(1)随机选择一文本检测框;
(2)以该文本框为中心按某一分布的随机抽样扩大候选区域;
(3)确定与候选区域有较大重叠的文本检测框;
(4)对上述文本检测框内的单词进行掩码。

图4 Area-masked Language Model示意图
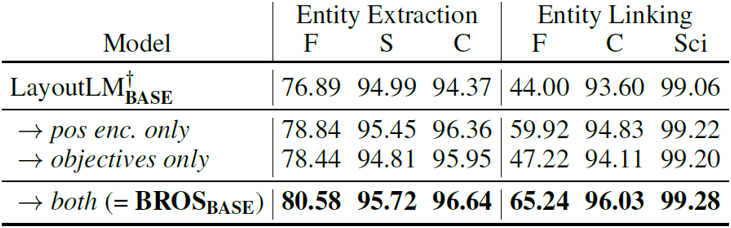
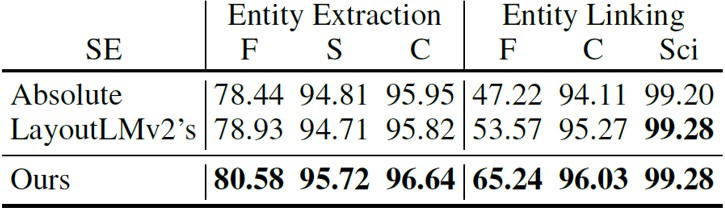
三、主要实验结果
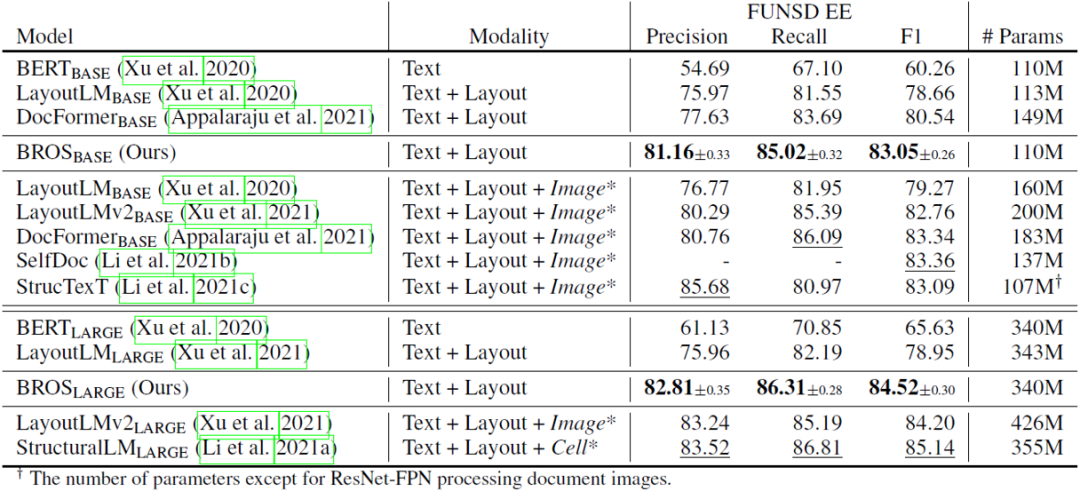
从表1可以看到,在仅使用文本信息和版面信息的情况下,无论是本文BROS的BASE模型还是LARGE模型,在参数量相近或更小的情况下超越了现有模型的表现。虽然其表现不及加入视觉信息的模型,但BROS对比这些模型在参数量上具有一定优势。
表2 不打乱单词顺序时实体抽取和实体连接实验结果
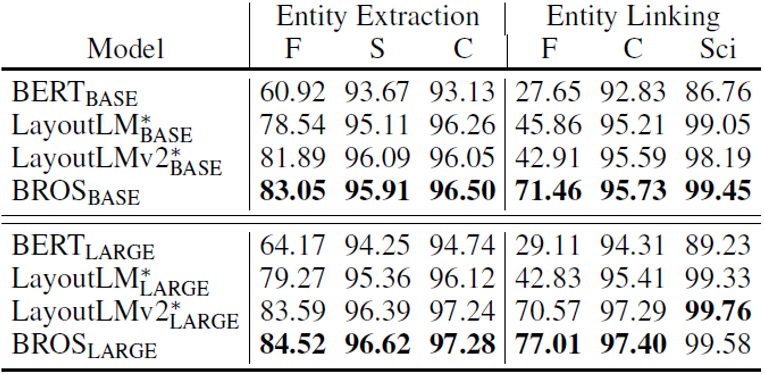
表3 打乱单词顺序时实体抽取和实体连接实验结果
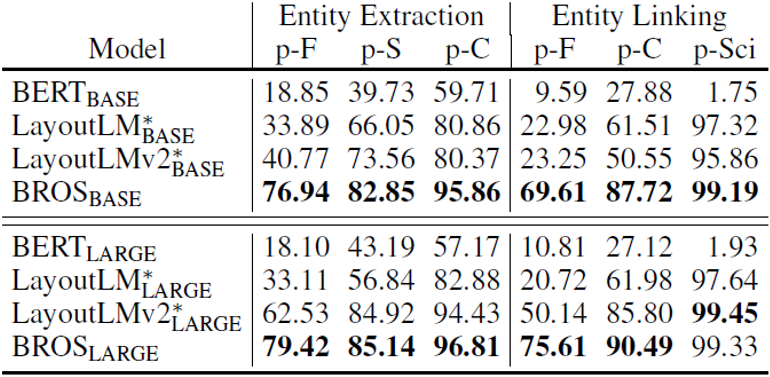
表4 按不同方式重建单词顺序时实体抽取和实体连接实验结果
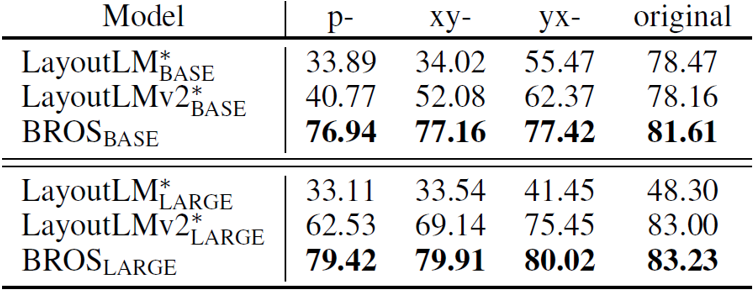
表2、表3、表4中p-F,p-S,p-C和p-Sci分别代表不同数据集,为解决打乱顺序后的关键信息抽取问题,文章引入了SPADE[5]作为解码器。从结果可以看到,BROS对单词的排列顺序不敏感,在各种单词排列方法上相较于其他方法均有更好的表现。
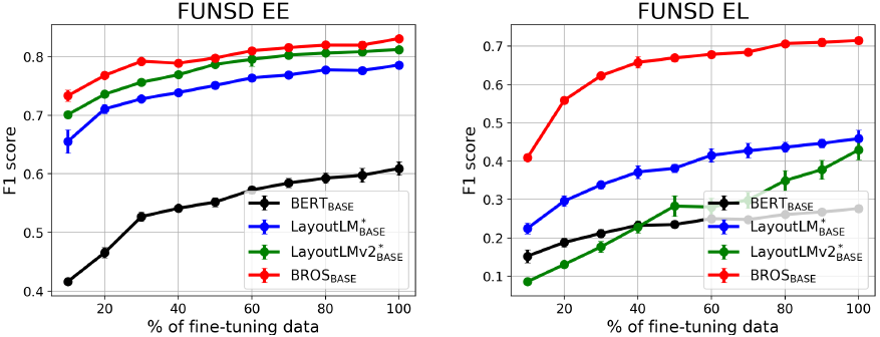
图5 模型表现与微调数据量的关系
表6 模型表现与微调数据量的关系
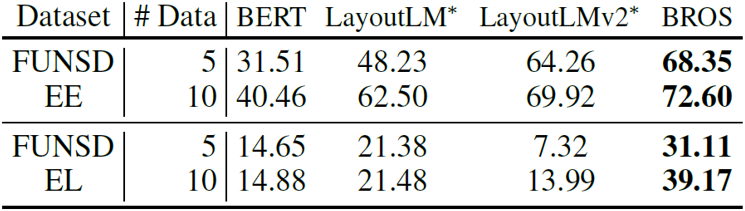
从图5和表6看出来,BROS相较于其他预训练模型,只需要更少的数据进行微调,就能在下游任务中达到更好的效果。
四、结论
五、相关资源
论文地址:https://arxiv.org/pdf/2108.04539v5.pdf
代码地址:https://github.com/clovaai/bros
参考文献
[1] Xu Y, Xu Y, Lv T, et al. LayoutLMv2: Multi-modal Pre-training for Visually-rich Document Understanding[C]//Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021: 2579-2591.
[2] Powalski R, Borchmann Ł, Jurkiewicz D, et al. Going full-tilt boogie on document understanding with text-image-layout transformer[C]//International Conference on Document Analysis and Recognition. Springer, Cham, 2021: 732-747.
[3] Li P, Gu J, Kuen J, et al. Selfdoc: Self-supervised document representation learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 5652-5660.
[4] Kenton J D M W C, Toutanova L K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[C]//Proceedings of NAACL-HLT. 2019: 4171-4186.
[5] Hwang W, Yim J, Park S, et al. Spatial Dependency Parsing for Semi-Structured Document Information Extraction[C]//The Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2021). Association for Computational Linguistics, 2021.
[6] Xu Y, Li M, Cui L, et al. Layoutlm: Pre-training of text and layout for document image understanding[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 1192-1200.
原文作者:Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park
撰稿:廖文辉
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
