
目标检测经典工作:RetinaNet和它背后的Focal Loss
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

RetinaNet 是通过对单目标检测模型 (如 YOLO 和 SSD) 进行两次改进而形成的:
1.Feature Pyramid Networks for Object Detection (https://arxiv.org/abs/1612.03144)
2.Focal Loss for Dense Object Detection (https://arxiv.org/abs/1708.02002)
RetinaNet只是原来FPN网络与FCN网络的组合应用,因此在目标网络检测框架上它并无特别亮眼创新。文章中最大的创新来自于Focal loss的提出及在单阶段目标检测网络RetinaNet(实质为Resnet + FPN + FCN)的成功应用。Focal loss是一种改进了的交叉熵(cross-entropy, CE)loss,它通过在原有的CE loss上乘了个使易检测目标对模型训练贡献削弱的指数式,从而使得Focal loss成功地解决了在目标检测时,正负样本区域极不平衡而目标检测loss易被大批量负样本所左右的问题。此问题是单阶段目标检测框架(如SSD/Yolo系列)与双阶段目标检测框架(如Faster-RCNN/R-FCN等)accuracy gap的最大原因。
在Focal loss提出之前,已有的目标检测网络都是通过像Boot strapping/Hard example mining等方法来解决此问题的。作者通过后续实验成功表明Focal loss可在单阶段目标检测网络中成功使用,并最终能以更快的速率实现与双阶段目标检测网络近似或更优的效果。
类别不平衡(class imbalance)是目标检测模型训练的一大难点(推荐这篇综述文章Imbalance Problems in Object Detection: A Review),其中最严重的是正负样本不平衡,因为一张图像的物体一般较少,而目前大部分的目标检测模型在FCN上每个位置密集抽样,无论是基于anchor的方法还是anchor free方法都如此。
对于Faster R-CNN这种two stage模型,第一阶段的RPN可以过滤掉很大一部分负样本,最终第二阶段的检测模块只需要处理少量的候选框,而且检测模块还采用正负样本固定比例抽样(比如1:3)或者OHEM方法(online hard example mining)来进一步解决正负样本不平衡问题。
对于one stage方法来说,detection部分要直接处理大量的候选位置,其中负样本要占据绝大部分,SSD的策略是采用hard mining,从大量的负样本中选出loss最大的topk的负样本以保证正负样本比例为1:3。其实RPN本质上也是one stage检测模型,RPN训练时所采取的策略也是抽样,从一张图像中抽取固定数量N(RPN采用的是256)的样本,正负样本分开来随机抽样N/2,如果正样本不足,那就用负样本填充。
Focal Loss为了同时调节正、负样本与难易样本,提出了如下所示的损失函数。
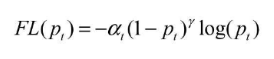
其中  用于控制正负样本的权重,当其取比较小的值来降低负样本(多的那类样本)的权重;
用于控制正负样本的权重,当其取比较小的值来降低负样本(多的那类样本)的权重;  用于控制难易样本的权重,目的是通过减少易分样本的权重,从而使得模型在训练的时候更加专注难分样本的学习。文中通过批量实验统计得到当
用于控制难易样本的权重,目的是通过减少易分样本的权重,从而使得模型在训练的时候更加专注难分样本的学习。文中通过批量实验统计得到当  时效果最好。
时效果最好。
可以看出,对于Focal loss损失函数,有如下3个属性:
与平衡交叉熵类似,引入了αt权重,为了改善正负样本的不均衡,可以提升一些精度。
- 是为了调节难易样本的权重。当一个边框被误分类时,pt较小,则接近于1,其损失几乎不受影响;当pt接近于1时,表明其分类预测较好,是简单样本,接近于0,因此其损失被调低了。
γ是一个调制因子,γ越大,简单样本损失的贡献会越低。
为了验证Focal Loss的效果,何凯明等人还提出了一个一阶物体检测结构RetinaNet,其结构如下图所示。
RetinaNet的框架整体是ResNet+FPN+FCN,它使用ResNet作为backbone来提取图像特征,然后从中抽取5层特征层来构建特征金字塔网络(FPN: feature pyramid network),最后接两个独立的全卷积网络(FCN: full convolution network)分别得到物体的类别信息和位置框信息。

对于RetinaNet的网络结构,有以下5个细节:
(1)在Backbone部分,RetinaNet利用ResNet与FPN构建了一个多尺度特征的特征金字塔。
(2)RetinaNet使用了类似于Anchor的预选框,在每一个金字塔层,使用了9个大小不同的预选框。
(3)分类子网络:分类子网络为每一个预选框预测其类别,因此其输出特征大小为KA×W×H, A默认为9, K代表类别数。中间使用全卷积网络与ReLU激活函数,最后利用Sigmoid函数输出预测值。
(4)回归子网络:回归子网络与分类子网络平行,预测每一个预选框的偏移量,最终输出特征大小为4A×W×W。与当前主流工作不同的是,两个子网络没有权重的共享。
(5)Focal Loss:与OHEM等方法不同,Focal Loss在训练时作用到所有的预选框上。对于两个超参数,通常来讲,当γ增大时,α应当适当减小。实验中γ取2、α取0.25时效果最好。
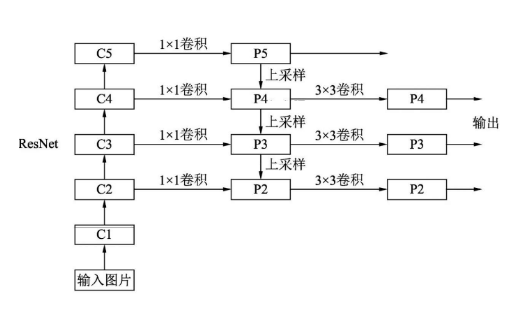
将深层信息上采样,与浅层信息逐元素地相加,从而构建了尺寸不同的特征金字塔结构,性能优越,现已成为目标检测算法的一个标准组件。FPN的结构如下所示。
△ 特征金字塔FPN结构
自下而上:最左侧为普通的卷积网络,默认使用ResNet结构,用作提取语义信息。C1代表了ResNet的前几个卷积与池化层,而C2至C5分别为不同的ResNet卷积组,这些卷积组包含了多个Bottleneck结构,组内的特征图大小相同,组间大小递减。
自上而下:首先对C5进行1×1卷积降低通道数得到P5,然后依次进行上采样得到P4、P3和P2,目的是得到与C4、C3与C2长宽相同的特征,以方便下一步进行逐元素相加。这里采用2倍最邻近上采样,即直接对临近元素进行复制,而非线性插值。
横向连接(Lateral Connection):目的是为了将上采样后的高语义特征与浅层的定位细节特征进行融合。高语义特征经过上采样后,其长宽与对应的浅层特征相同,而通道数固定为256,因此需要对底层特征C2至C4进行11卷积使得其通道数变为256,然后两者进行逐元素相加得到P4、P3与P2。由于C1的特征图尺寸较大且语义信息不足,因此没有把C1放到横向连接中。
卷积融合:在得到相加后的特征后,利用3×3卷积对生成的P2至P4再进行融合,目的是消除上采样过程带来的重叠效应,以生成最终的特征图。
原始的ResNet共有4个stage,其得到的特征分别记为,相较于输入图像,它们的stride分别为。
FPN的构建从开始,首先采用一个1x1卷积得到channel为C(FPN中取256,FPN中所有level的channel都是一样的)的新特征,然后就可以自上而下生成不同level的新特征,分别记为,与ResNet的特征是一一对应的,另外对直接采用一个stride=2的下采样得到一个新特征(基于stride=2的1x1 maxpooling实现),这样最后FPN实际上得到了5个不同level的特征,其stride分别为,特征维度均为C。
Faster R-CNN是采用这样的FPN结构,但是RetinaNet却有稍许变动,第一点是只用ResNet的,这样通过FPN得到的特征是,相当于去掉了,的stride是4,特征很大,去掉它可以减少计算量,后面会讲到RetinaNet的anchor量和detection head都是比RPN更heavy的,这很有必要。另外新增两个特征和,在上加一个stride=2的3x3卷积得到,是在后面加ReLU和一个stride=2的3x3卷积得到。
这样RetinaNet的backbone得到特征也是5个level,分别为,其stride分别为。一点题外话就是FCOS的backbone也是取,也算是借鉴了RetinaNet。而YOLOV3的backbone是基于DarkNet-53的FPN,其特征共提取了3个层次,stride分别是。
同时结合上述提到的Focal Loss机制和单阶段模型的设计,使得RetinaNet在检测精度和前向速度上都达到了一个很高的水准,如下图所示。采用ResNeXt-101-FPN作为backbone,最终能在COCO test-dev数据集上达到40.8 mAP值。
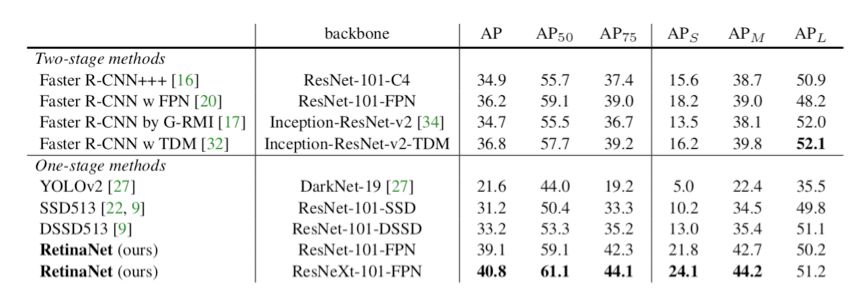
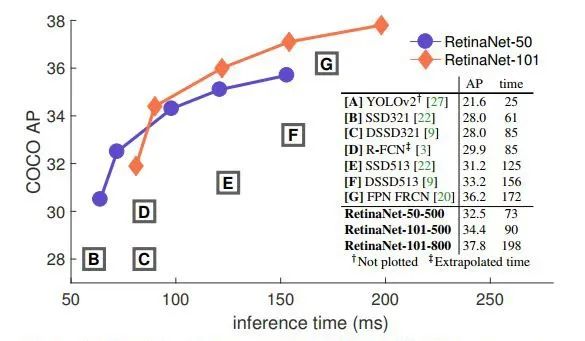
最后总结一下RetinaNet与其它同类模型的对比:
相比RPN,前面已经说过RetinaNet可以看成RPN的多分类升级版,backbone和FPN设置基本一样,只不过RPN采用简单的sampling方法训练,而RetinaNet采用FL;
相比SSD,SSD也是利用多尺度特征,不过RetinaNet是FPN,SSD的anchor与Faster R-CNN类似,不过anchor的size和ratio有稍许差异,另外就是SSD是OHEM 1:3训练,而且采用softmax loss;
相比YOLOV3,YOLOv3的backbone是基于DarkNet-53的类FPN结构,level只有3个,不过整体与RetinaNet的backbone接近;YOLOV3的anchor是基于k-means生成,而且匹配策略是基于center和IoU的策略,训练loss是普通的sigmoid。
对比之后,其实发现基于anchor的one stage检测模型差异并没有多大。
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~