
深度思考|TCP协议存在那些缺陷?
作者:dog250
https://www.zhihu.com/question/47560918/answer/2302296292
TCP如何优化吞吐率,我很直接说优化不了,这让我甩开了很多令人尴尬的麻烦事儿。但我可以聊一聊。
为什么优化不了?因为滑动窗口。
当我这么说时,有人不由分说就怼,说“如果是cwnd limited”呢?我要表达的是,cwnd limited原因有二,如果你的cc算准了,那就是网络原本就是拥塞的,如果你的cc没算准,那是你的cc的问题,换句话说,cwnd决定的是你TCP连接吞吐的下限,却不限制其上限。
为什么因为滑动窗口?因为滑动窗口本质上是一个“停-等”策略。
“停-等”怎么了?因为要等,所以要停,一停就慢了(也叫HoL阻塞)。
队头阻塞(英語:Head-of-line blocking,缩写:HOL blocking)在计算机网络的范畴中是一种性能受限的现象。它的原因是一列的第一个数据包(队头)受阻而导致整列数据包受阻。例如它有可能在缓存式输入的交换机中出现,有可能因为传输顺序错乱而出现,亦有可能在HTTP流水线中有多个请求的情况下出现。
等什么?等buffer被填满。
什么buffer?就是接收窗口。
等接收窗口被填满有什么问题吗?问题就在这里!
那么要取消滑动窗口吗?这个最后再谈。先说本质问题。
问题在于,这块作为滑动窗口的buffer有一个约束,要求其中的字节序列号必须连续。这意味着这个buffer便不再是一块无差别随机访问的内存了,而变成了一个队列。一旦出现一个hole,传输过程就必须停下来等待它被填充,期间窗口的滑动是被阻滞。
当我这么说时,有人不由分说就怼,说“流量控制是对所有有连接协议的基本要求,滑动窗口就是为了流控存在的”。我表达的意思是,首先,当出现hole并在它被补齐前,TCP拥塞状态机完全接管cwnd的计算,cc将不起作用,此时要么你的连接成为rwnd limited,要么带宽估计失真,诓论高吞吐,其次,滑动窗口并非流量控制的唯一方式。
诞生于1970~1980年代的TCP从来就不是为性能而生的。当人们意识到性能问题的时候,随即就出现了依赖out-of-order queue的selective ACK。但于本质问题无补,基因决定了上限。
设计传输协议,肯定要把端到端语义和传输语义分开,不然还要什么分层模型。简单说,传输只关注数据包看不见序列号,端到端只重排字节看不见数据包。这需要在字节流的序列号空间和数据包之间做一次映射。
问题在于,致使TCP没有作出这种设计的根源是什么?
在于它的“流式设计”。下面的链接可以找到故事的一部分:
Transmission Control Protocol (TCP) 1973-1976
分歧在于拆包和组装,为了让分组交换站在电路交换的对面,重新组装由端到端负责,这就不强求TCP流经过相同路由器了,但这个策略未竟全功。
未竟全功,核心原因是TCP协议被设计的时候并没有承载TCP数据的“数据报协议分组”,这是一个先有鸡先有蛋的问题,在1973年~1976年,IP尚未从TCP中分离出来,所以IP无法承载TCP,更别提UDP了。UDP是当IP从TCP中分离出来后,作为IP协议的等价语义在TCP层的补充而被后来添加的。
那么TCP只能自己承载自己,直接在分组交换网传输。
允许乱序是分组交换的基本特征之一,TCP协议也因此将保序逻辑放在了端到端,然而对于传输逻辑,TCP依然更像一条虚电路流,而不像数据报分组。
这是TCP后续停-等buffer,GBN低效的根源。为什么呢?
整个传输逻辑的实体不是TCP数据包,而是没有边界的TCP字节流。换句话说,发送端一次发送1000字节的数据,到了接收端,可能收到2个数据包,一个20字节,另一个980字节,也可能收到1000个数据包,每一个1字节,当然,更大可能是依然是一个1000字节的数据包。无论如何,接收端无法“基于数据包做ACK,只能对字节做ACK”,但主机处理处理依然以数据包为单位。这逆转了人们设计协议时对时间和空间做trade-off时的偏好。
对空间的关注超过了对吞吐的关注。为每一个字节安排一个ACK,将使TCP协议头变得冗长到不可接受,这不仅不能带来吞吐的提升,还会消耗大量的带宽用于ACK本身的管理开销。
摒弃数据包的概念,直接对TCP的字节流对积累ACK可以解决上述问题。积累ACK自然而然就等价于滑动窗口和GBN了。
整个故事是,流式抽象导致了必须基于字节进行ACK,进而积累确认和GBN重传被认为是性价比最高的。这是一个很低效的设计,但管用。
selective ACK是一种向正确方式的回归,但依然没能摆脱“基于字节ACK”的梦魇,SACK看上去很别扭并勉强,因为它不得不委曲于TCP Option中,空间受限而不能求全,本质原因还是最初的那个,如果给SACK安排了不受限制的空间,ACK报文将变得冗长。
我简单画了一个TCP本应该在分组交换网中的正确姿势:
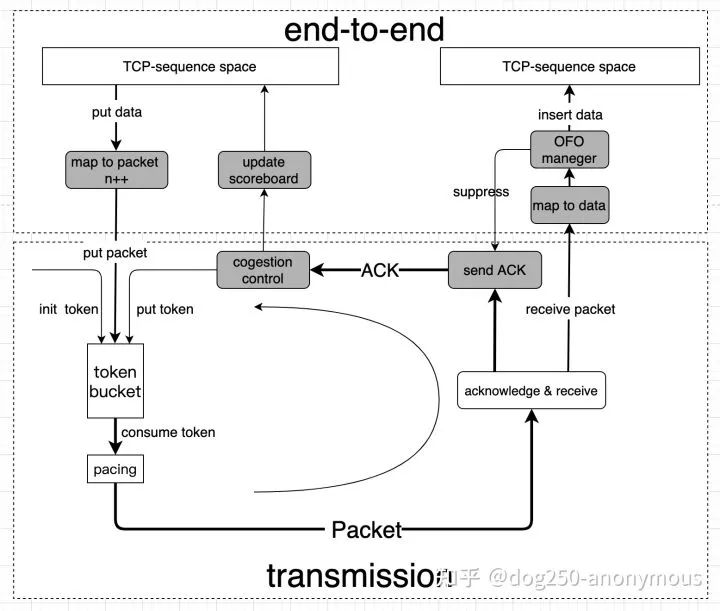
非常清晰的两层结构。接收窗口限制了可用buffer的大小,而buffer只有够不够的问题,如果空间不足,显式发送抑制消息给ACK逻辑即可,ACK将抑制消息反馈到源端。
与buffer的解释类似,网络传输只有带宽满不满,拥塞与否的问题,而这些完全通过congestion control,pacing逻辑等完成,令牌桶里完全序列号的概念。
端到端语义和传输语义分离的好处不胜枚举:
很容易统计重传率指标,需要传输的字节在端到端子层,实际传输的字节在传输子层。
网络传输可以肆意并行,无需关注乱序,重组等问题,以最大化带宽利用率为目标。
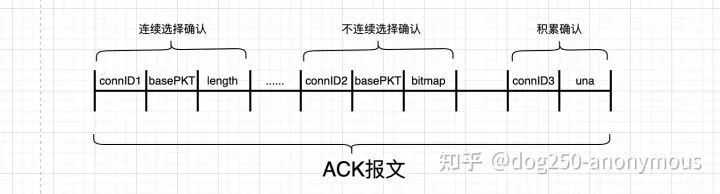
确认数据包而不是确认字节,灵活实现积累ACK或selective ACK,ACK报文可压缩,可编码。
...
简单展示一个ACK报文的样子:
现在看在新的设计下,滑动窗口本身的问题。要不要取消它?滑动窗口要取消,问题在于,首先,如何做流量控制,其次,流量控制如何使用buffer。
第一个问题很容易:
buffer是标量而非矢量,只看大小不看方向,只要尚未超过最大使用限额,就可以收数据。
设置可用buffer最大值以及最大允许的突发,超过限额即发送源抑制。
看第二个问题。如果buffer中数据有hole不连续,应用程序如何收走数据?如果数据一直不被收走,buffer总会没有空闲空间。这不是又回到问题的原点了吗?问题的解决在于使用buffer的方式。
不同于标准TCP一个连接独占buffer的方式:
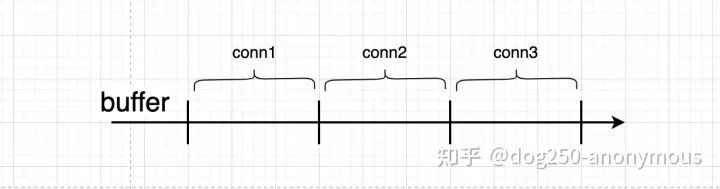
新的设计采用子连接复用的方式让多个连接共享同一个buffer:
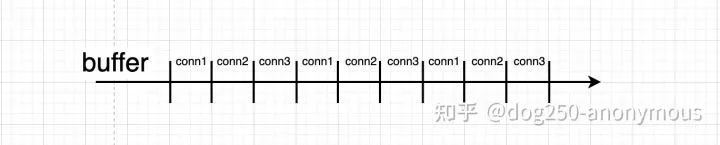
buffer粒度更细,施展空间更大,同一子连接HoL阻塞概率更低。
QUIC大概就是这个意思吧。
...
我不认同NAK的原因还是因为它会引入纷乱的误判。
...
现在,可以把上面的设计部署在IDC网络(互联网数据中心(Internet Data Center), 简称IDC)使用流体渗透原理去对抗incast,也可以部署在MPTCP逻辑通道上。
MultiPath TCP(MPTCP)由互联网工程任务组(IETF)MultiPath TCP工作组研发,其目的是允许传输控制协议Transmission Control Protocol(TCP)连接使用多个路径来最大化信道资源使用。
摩尔定律 在40年中持续改变甚至逆转人们的关注点,30年前,显卡,网卡被称为CPU的外设,如今CPU成了GPU,SmartNIC的外设。同理,TCP刚出来的时候,内存昂贵,带宽昂贵,于是人们挤压空间而不在乎时间,GBN顺势而为,TCP头也就成了那个样子,现在看来各种不够,大并发场景经常遭遇bind占CPU高的问题根源就是端口号只有16bits,TLV不是更好吗?可是那个时代不允许啊。直到空间不再昂贵,人们开始压缩时间,吞吐性能问题就摆在眼前,可是TCP已经是那个样子了,它就是为空间优化而生的,还能怎么办?我总说TCP是一个过时的老协议,言外之意就是说要用新的传输协议了,比如QUIC,或者比QUIC更好的协议。TCP优化?到头了。追求陆地速度就去坐高铁,而不是坐高性能绿皮车。想了想,就写了这篇。时间有限,先这么多...
- END -