
如何用「逻辑回归」构建金融评分卡模型?(下)
评分卡模型的开发
4.3WOE编码
分箱之后我们便得到了一系列的离散变量,下面需要对变量进行编码,将离散变量转化为连续变量。WOE编码是评分卡模型常用的编码方式。
WOE 称为证据权重(weight of evidence),是一种有监督的编码方式,将预测类别的集中度的属性作为编码的数值。对于自变量第 $i$ 箱的WOE值为:
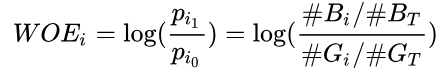

公式中的log函数的底一般取为e,即为ln
从以上公式中我们可以发现,WOE表示的实际上是“当前分箱中坏客户占所有坏客户的比例”和“当前分箱中好客户占所有好客户的比例”的差异。
对以上公式做一个简单变换,可以得到:
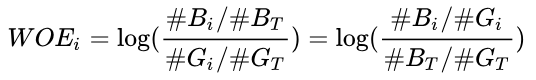
变换以后可以看出,WOE也可以理解为当前分箱中坏客户和好客户的比值,和所有样本中这个比值的差异 (也就是我们随机的坏客户和好客户的比例)。WOE越大,这种差异越大,当前分组里的坏客户的可能性就越大,WOE越小,差异越小,这个分组里的样本响应的可能性就越小。当分箱中坏客户和好客户的比例等于随机坏客户和好客户的比值时,说明这个分箱没有预测能力,即WOE=0。
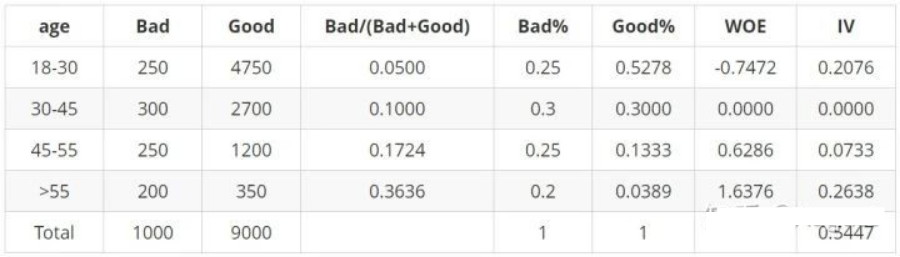
WOE具体计算过程如下表所示:
Q5:我们还有没有学过其他编码方式?这里为什么选择采用WOE编码?
我们还学过one-hot编码。one-hot 编码会将原始变量中的每个状态都做为作为一个新的特征,当原始特征状态较多时,数据经过one-hot编码之后特征数量会成倍的增加,同时新特征也会变得过于稀疏。在进行变量筛选的过程中,也会出现原始特征的一部分状态被筛选出来,另一部分状态未被筛选出来,造成特征的不完整。
而WOE编码不仅可以解决以上这些问题,同时还可以将特征转化为线性。
我们知道,逻辑回归的假设函数为:
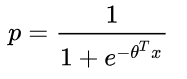
其中p为样本为坏客户的概率,1-p为样本为好客户的概率,整理可得:
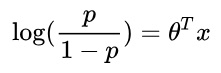
其中
我们再来看来看WOE编码的定义:

实际上WOE编码相当于把分箱后的特征从非线性可分映射到近似线性可分的空间内。如下图所示:
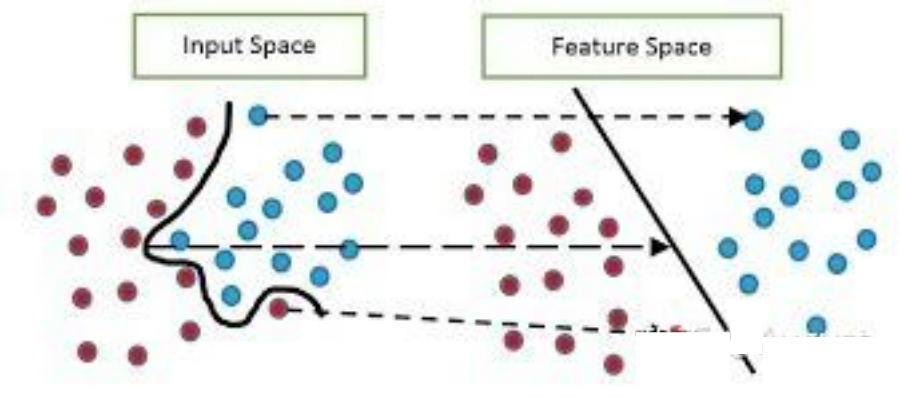
Q6:WOE编码为什么不直接表示为该分箱好坏客户数量之比?
如果直接表示为表示为某个分箱好坏客户数量之比,根绝WOE值无法判断不同分箱的预测能力。同时WOE值在很大程度上受到好坏客户的影响,在严重非均衡的问题中,该比值会非常小,严重影响woe的值。
这里我们举个例子,假设数据中共有5000个好客户和50个坏客户,共有三个分箱,箱1的好客户和坏客户分别有1000个和20个,箱2好客户和坏客户分别有1000个和10个,箱3好客户和坏客户分别有1000个和5个。
显然,箱1和箱3都具有较好的预测能力,而箱2因为坏客户比例和随机预测类似,因此不具有预测能力。
用法1:原公式来计算:
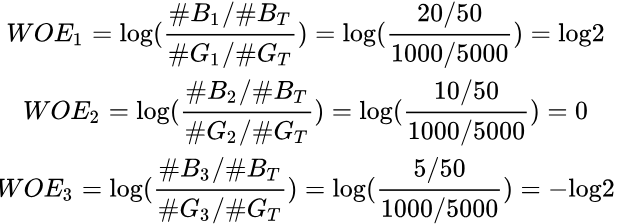
从以上结果我们发现,箱2对应的WOE=0,说明不具有预测能力,而箱1和箱3的WOE分别为log2和-log2,均远离0点,具有预测能力。
用法2:利用分箱中好坏客户数量来计算:
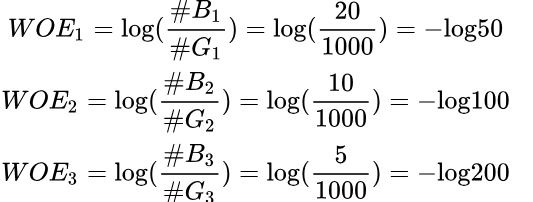
然而从法2得到的结果中只能判断三个分箱的坏客户的比例大小情况,无法判断箱1,箱2和箱3的预测能力。
总结一下WOE编码的优势:
可提升模型的预测效果
将自变量规范到同一尺度上
WOE能反映自变量取值的贡献情况
有利于对变量的每个分箱进行评分
转化为连续变量之后,便于分析变量与变量之间的相关性
与独热向量编码相比,可以保证变量的完整性,同时避免稀疏矩阵和维度灾难
5.变量筛选
之前我们说到过用户的属性有千千万万个维度,而评分卡模型所选用的字段在30个以下,那么怎样挑选这些字段呢?
挑选入模变量需要考虑很多因素,比如:变量的预测能力,变量之间的线性相关性,变量的简单性(容易生成和使用),变量的强壮性(不容易被绕过),变量在业务上的可解释性(被挑战时可以解释的通)等等。其中最主要和最直接的衡量标准是变量的预测能力和变量的线性相关性。本文主要探讨基于变量预测能力的单变量筛选,变量两两相关性分析,变量的多重共线性分析。
(1)单变量筛选
单变量的筛选基于变量预测能力,常用方法:
基于IV值的变量筛选
基于stepwise的变量筛选
基于特征重要度的变量筛选:RF, GBDT…
基于LASSO正则化的变量筛选
1) 基于IV值的变量筛选
IV称为信息价值(information value),是目前评分卡模型中筛选变量最常用的指标之一,自变量的IV值越大,表示自变量的预测能力越强。类似的指标还有信息增益、基尼(gini)系数等。常用判断标准如下:
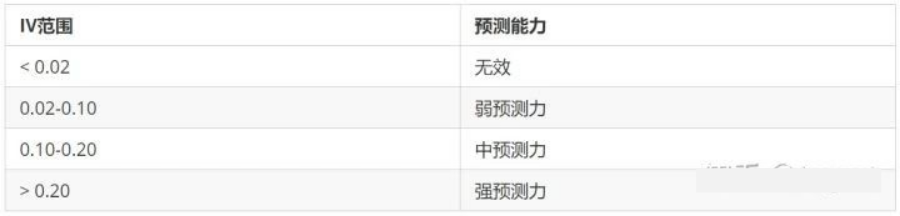
那么怎么计算变量中第i个分箱对应的 IV 值的计算公式为:
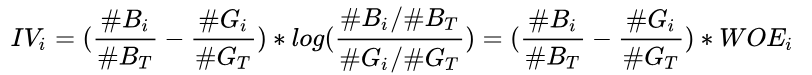
变量对应的IV值为所有分箱对应的 IV 值之和:
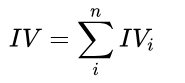
从上式我们可以看出变量的 IV 值实际上式变量各个分箱的加权求和。且和决策树中的交叉熵有异曲同工之妙。以下为交叉熵公式:
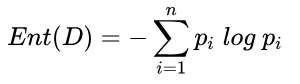
IV值的具体的计算流程如下:
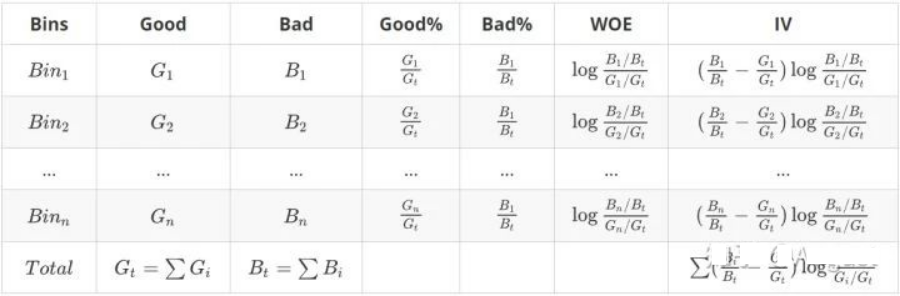
Q7:请补全以下表格
自变量为age,Y表示目标变量,其中bad代表坏客户,good代表好客户。我们希望能用自变量age来预测好坏客户的概率,以此来决定是否放贷。
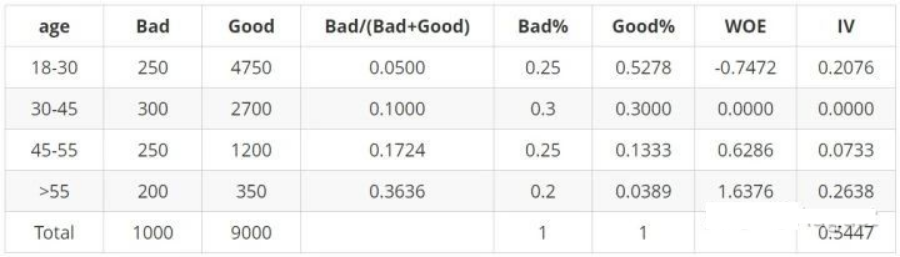
从以上案例中我们可以分析出:
当前分箱中,坏客户占比越大,WOE值越大
当前分箱中WOE的正负,由当前分箱中好坏客户比例,与样本整体好坏客户比例的大小关系决定
当分箱的比例小于整体比例时,WOE为负。例如年龄18-30分箱中:250/4750<1000/9000,该分箱对应的WOE为负值
当分箱的比例大于整体比例时,WOE为正。例如年龄45-55分箱中:250/1200>1000/9000,该分箱对应的WOE为正值
当分箱的比例等于整体比例时,WOE为0。例如年龄30-45分箱中:300/2700=1000/9000,该分箱对应的WOE为0
WOE的取值范围是[-∞,+∞],当分箱中好坏客户比例等于整体好坏客户比例时,WOE为0
对于变量的一个分箱,这个分组的好坏客户比例与整体好坏客户比例相差越大,IV值越大,否则,IV值越小
IV值的取值范围是[0,+∞),当分箱中只包含好客户或坏客户时,IV = +∞,当分箱中好坏客户比例等于整体好坏客户比例时,IV为0
2)基于stepwise的变量筛选
基于基于stepwise的变量筛选方法也是评分卡中变量筛选最常用的方法之一。具体包括三种筛选变量的方式:
前向选择forward:逐步将变量一个一个放入模型,并计算相应的指标,如果指标值符合条件,则保留,然后再放入下一个变量,直到没有符合条件的变量纳入或者所有的变量都可纳入模型
后向选择backward:一开始将所有变量纳入模型,然后挨个移除不符合条件的变量,持续此过程,直到留下所有最优的变量为止
逐步选择stepwise:该算法是向前选择和向后选择的结合,逐步放入最优的变量、移除最差的变量
3)基于特征重要度的变量筛选
基于特征重要度的变量筛选方法是目前机器学习最热门的方法之一,其原理主要是通过随机森林和GBDT等集成模型选取特征的重要度。
①机森林计算特征重要度的步骤:

当改变样本在该特征的值,若袋外数据准确率大幅度下降,则该特征对于样本的预测结果有很大影响,说明特征的重要度比较高。
②GBDT计算特征重要度原理:
特征 j 在单颗树中的重要度的如下:
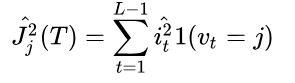
其中,L 为树的叶子节点数量,L-1 为树的非叶子节点数量,Vt是和节点 t 相关联的特征,特征j的全局重要度为特征j在单颗树中的重要度的平均值:
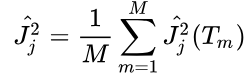
其中,M 是树的数量。
4) 基于LASSO正则化的变量筛选
L1正则化通常称为Lasso正则化,它是在代价函数上增加了一个L1范数:
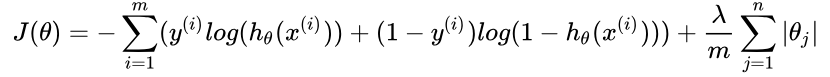
(2)变量相关性分析
1)变量两两相关性分析

两变量间的线性相关性可以利用皮尔森相关系数来衡量。系数的取值为[-1.0,1.0],相关系数越接近0的说明两变量线性相关性越弱,越接近1或-1两变量线性相关性越强。
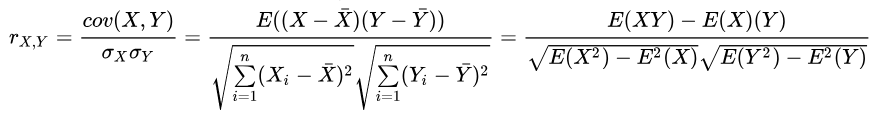
当两变量间的相关系数大于阈值时(一般阈值设为 0.7 或 0.4),剔除IV值较低的变量,或分箱严重不均衡的变量。
2)变量的多重共线性分析

Q8:为什么要进行相关性分析?

即使不进行线性相关性分析也不会影响模型的整体性能,进行相关性分析只是为了让我们的模型更易于解释,保证不同的分箱的得分正确。
总结一下变量筛选的意义:
剔除跟目标变量不太相关的特征
消除由于线性相关的变量,避免特征冗余
减轻后期验证、部署、监控的负担
保证变量的可解释性
6.构建逻辑回归模型
主要包括构建初步的逻辑回归模型,根据p-value进行变量筛选,根据各个变量的系数符号进行筛选,得到最终的逻辑回归模型。
以下为几种常用模型的优势和劣势对比:
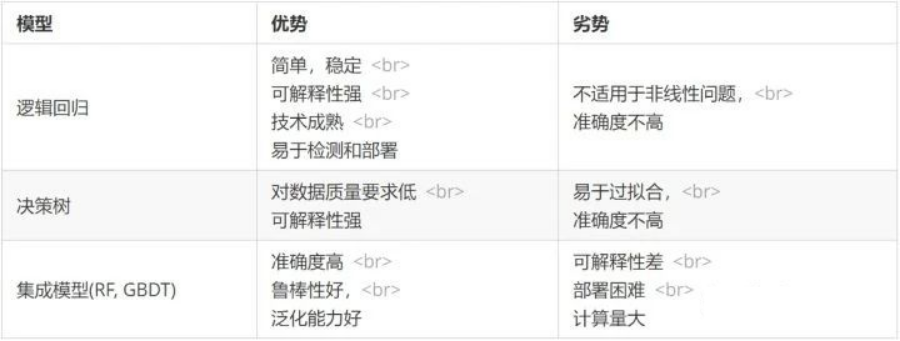
由于逻辑回归模型具有简单,稳定,可解释性强,技术成熟和易于检测和部署等优势,逻辑回归是评分卡模型最经常使用的算法。
(1)根据系数符号进行筛选
检查逻辑回归模型中各个变量的系数,如果所有变量的系数均为正数,模型有效。假如有一些变量的系数出现了负数,说明有一些自变量的线性相关性较强,需要进一步进行变量筛选。通常的做法是:
综合考虑变量的IV值和业务的建议,按照变量的优先级进行降序排列
选择优先级最高的4-5个基本变量
按优先级从高到低逐渐添加变量,当新添加的变量之后,出现系数为负的情况,舍弃该变量
直到添加最后一个变量
Q9:为什么回归模型中各个变量的系数均为正数?
由以上分析我们知道对于分箱的WOE编码,分箱中坏客户占比越大,WOE值越大;也就是说该分箱中客户为坏客户的概率就越大,对应的WOE值越大,即WOE与逻辑回归的预测结果 (坏客户的概率) 成正比。
Q10:为什么说假如有一些变量的系数出现了负数,说明有一些自变量的线性相关性较强?
我们知道,正常情况下,WOE编码后的变量系数一定为正值。由上面为什么进行线性相关性分析的问题可知,由于一些自变量线性相关,导致系数权重会有无数种取法,使得可以为正数,也可以为负数。
(2)根据p-value进行筛选
p-value是假设检验的里面的概念。模型假设某自变量与因变量线性无关,p-value可以理解为该假设成立的可能性 (便于理解,不太准确)。一般,当p-value大于阈值时,表示假设显著,即自变量与因变量线性无关;当p-value小于阈值时,表示假设不显著,即自变量与因变量线性相关。阈值又称为显著性水平,通常取0.05。
因此当某个字段的 p-value 大于0.05时,应该删除此变量。
Q11:先根据系数符号进行筛选,再进行p-value筛选?
变量的线性相关性会影响变量的预测效果,进而影响变量的p-value值。因此应该先根据系数符号进行筛选,再进行p-value筛选。
7.模型评价
(1)混淆矩阵,TPR (Recal),FPR
TPR (或Recall) 为坏客户的查全率,表示被模型抓到的坏客户占总的坏客户的比例,表达式为:
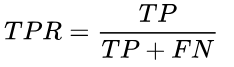
FPR 为好客户误判率,表示好客户中倍模型误误判的比例,表达式为:
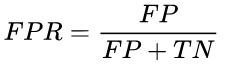
可以把TPR看做模型的收益,FPR看做模型付出的代价。如果一个模型 TPR越大,表示模型能够抓到的坏客户比例越大,即收益越大;FPR越大,表示模型能够将好客户误抓的比例越大,即代价越大。
(2)AUC
AUC 表示模型对任意坏客户的输出结果为大于模型对任意好客户的输出结果的概率。AUC的取值范围在0.5和1之间,AUC 越大,表示模型预测性能越好。
8.小结
最后我们再来回答最初的三个问题作为本文的小结:
(1)用户的属性有千千万万个维度,而评分卡模型所选用的字段在30个以下,那么怎样挑选这些字段呢?
变量预测能力筛选
变量相关性分析(包括两两相关性分析,多重共线性分析)
根据p-value筛选
根据变量的系数符号进行筛选
(2)评分法卡模型采用的是对每个字段的分段进行评分,那么怎样对评分卡进行分段呢?
——变量分箱
(3)怎样对字段的每个分段进行评分呢?这个评分是怎么来的?
WOE编码
将预测概率值转化为评分
利用变量相关性分析和变量的系数符号保证每个分箱评分的合理性
End. 作者:August 来源:知乎专栏 本文为转载分享,如侵权请联系后台删除