
[013] 7种常见数据结构的图画解读

“数据结构在我们做数据过程中会经常遇到的,算法的实现更是依赖。今天给大家分享的这篇文章,对我们工作中最为常用的数据结构进行了结构化解释,同时也有一些图画,更加容易理解,希望可以帮助到大家哦!
Data structures are fundamental constructs that are used to build programs. Each data structure has its own way of organizing data, which may work efficiently in particular use cases. With their own particular structures, data structures offer alternative solutions to data organization, management, storage, access, and modification tasks.
Regardless you are building a machine learning model or a mobile app; you must rely on data structures when working on a project. Therefore, your prospective employer will also want to make sure that you have a good grasp of data structures.
In this post, we will cover seven fundamental data structures that you must know for your next job interview.
1. Arrays
Arrays are the most simple and widely used data structures. They are constructed as a collection of elements in a specific order. Arrays usually have fixed-size, and they hold items of the same data type. You can create an array from the collection of strings, integers, objects, or even arrays. Since arrays are indexed, you can have random access to any array element.
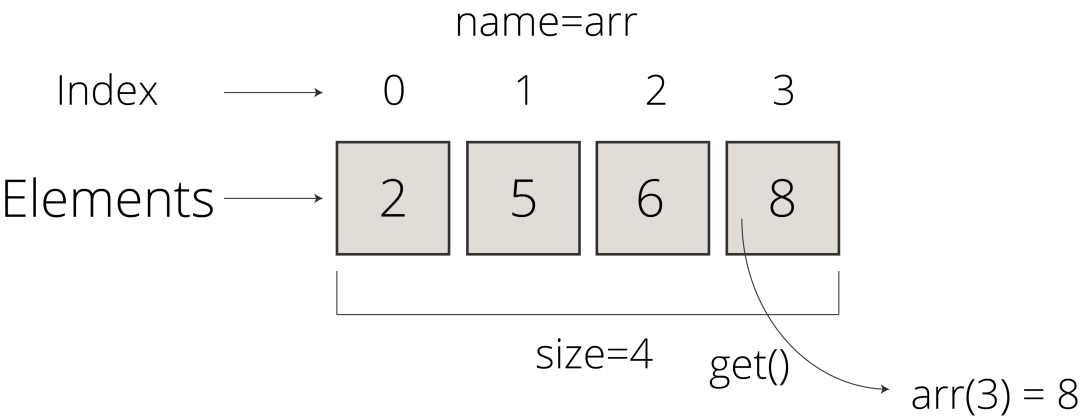
Figure 2. An Example Visualization of Arrays (Figure by Author)
Types of Arrays: The two most common types of arrays you may come across to are
One-dimensional arrays Multi-dimensional arrays
Basic Operations on Arrays: The most common basic operations you can conduct on arrays are insert, get, delete, and size operations.
Insert: Inserting a new element at a given indexGet: Returning an element at a given indexDelete: Deleting an element at a given indexSize: Returning the total number of elements in an array
You can also conduct traverse, search, and update operations on arrays.
Implementation of Arrays:
Arrays are usually used as building blocks of more complex data structures such as arrays,lists,heaps,matrices.In data science, arrays are used for efficient data manipulation operations. We often provide NumPy’s array objects to machine learning models for training.
2. Stacks
Stacks are data structures that work on a LIFO (Last in First Out) basis. In a LIFO based data structure, the data that are placed the last is accessed first. A real-life example of a stack could be a pile of rocks placed in vertical order, as shown in Figure 2.

Figure 3. Photo by Samrat Khadka on Unsplash
Basic Operations on Stacks: The most common basic operations you can conduct on stacks are push, top, pop, isEmpty, and isFull operations.
Push: Inserting a new element to the top;Top: Returning an element at the top without removing it from the stack;Pop: Returning an element at the top after removing it from the stack; andisEmpty: Checking if the stack has any element.isFull: Checking if the stack is full.
Here is a visualization of stack structure:

Figure 4. An Example Visualization of Stacks (Figure by Author)
Commonly asked interview questions regarding stacks
Evaluating postfix expression using a stack (e.g., Reverse Polish notation (RPN), or an abstract syntax tree (AST)); Sorting values in a stack; and Checking balanced parentheses in an expression.
3. Queues
Queues are structurally very similar to stacks. The only difference is that queues are based on the FIFO (First In First Out) method. In a queue, we can either add a new element to the end or remove an element from the front. A real-life example of queues could be a line of people waiting in a grocery, as shown in Figure 4.

Figure 5. Photo by Adrien Delforge on Unsplash
Basic Operations on Queue: The most common basic operations you can conduct on queues are enqueue, dequeue, top, and isEmpty operations.
Enqueue: Inserting a new element to the end of the queue;Dequeue: Removing the element from the front of the queue;Top: Returning the first element of the queue; andisEmpty: Checking if the queue is empty.
Here is a visualization of queue structure:
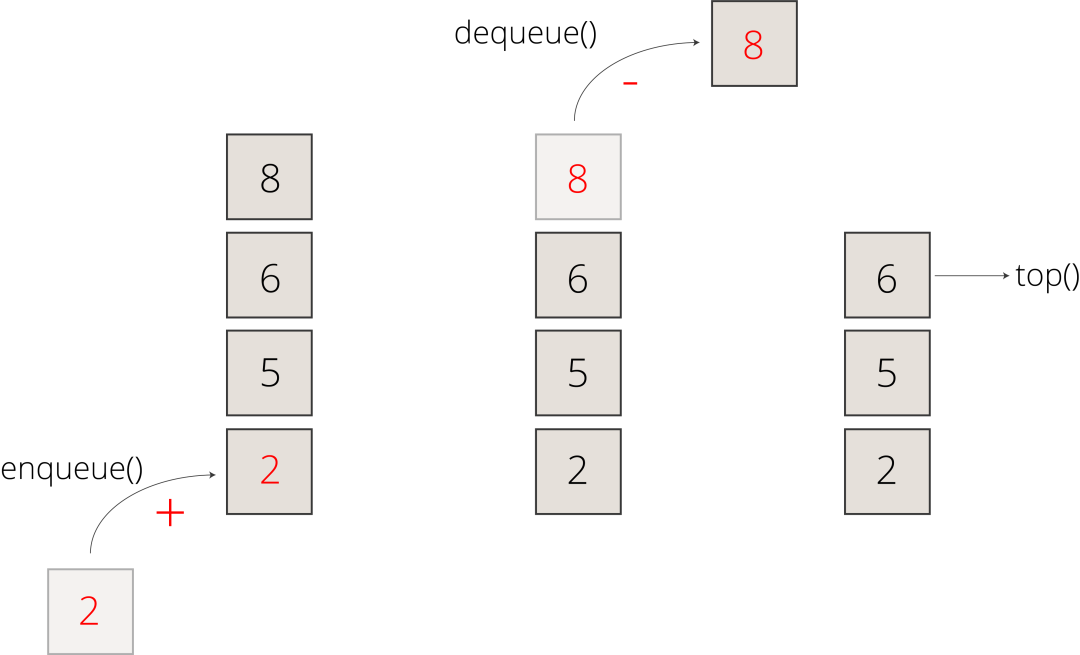
Figure 6. An Example Visualization of Queue (Figure by Author)
Implementation of Queues and Common Interview Questions
Implement a queue using stacks; Retrieve the first n elements of a given queue; and Generate binary numbers from 1 to n.
4. Linked Lists
Linked lists are structured as a linear collection of elements (i.e., node). Each node contains two information:
Data: The value of the elementPointer: The pointer to the next node in the linked list.
Since linked lists are sequential structures, accessing elements randomly is not possible.

Figure 7. Photo by JJ Ying on Unsplash
Types of Linked List: We come across two main types of linked lists,
Singly Linked List: We can only access the next node using the node before it. Doubly Linked List: We can access data both in forward and backward directions.
Here is a visualization of a linked list structure:

Figure 8. An Example Visualization of Single Linked List (Figure by Author)
Basic operations of Linked List: The most common basic operations you can conduct on linked lists are insertAtEnd, insertAtHead, DeleteAtHead, Delete, and isEmpty operations.
InsertAtEnd: Inserting a new element to the end of the linked listInsertAtHead: Inserting a new element to the head of the linked listDeleteAtHead: Removing the first element of the linked listDelete: Removing a given element from the linked listisEmpty: Checking if the linked list is empty.
Commonly asked Linked List interview questions:
Find the middle element of a singly linked list in one pass; Reverse a singly linked list without recursion; and Remove duplicate nodes in an unsorted linked list.
5. Trees
Trees are hierarchical data structures that consist of nodes and edges. Nodes represent values while edges connect them. The relationship between nodes in a tree is a uni or bidirectional one, not a cyclical one. Trees are widely used to build decision trees and ensemble methods.

Figure 9. Photo by Jazmin Quaynor on Unsplash
While tree types like binary trees and binary search trees are the most commonly used variations, the total number of different tree implementations reaches hundreds, where they can be grouped as:
Basic Tree StructuresMulti-Way TreesSpace-Partitioning treesApplication-Specific trees
Figure 10. An Example Visualization of Single Linked List (Figure by Author)
Commonly asked Tree interview questions:
Check if two given binary trees are identical or not; Calculate the height of a binary tree; Construct a full binary tree from a preorder and postorder sequence.
6. Graphs
Graphs consist of a finite set of nodes (i.e., vertices) with a set of unordered or ordered pairs of these vertices that together form a network. These pairs are also referred to as edges (i.e., links, lines, or arrows). An edge may contain weight or cost information to represent how much it cost to move from a to b.

Figure 11. An Example Visualization of Graph (Figure by Author)
Types of Graphs: There are two main types of graphs: (i) directed graphs and (ii) undirected graphs.
Directed Graphs: If all the edges of a graph have direction info like in Figure 8, then we talk about a directed graph;Undirected Graphs: If none of the edges have direction info, then we talk about an undirected graph

Figure 12. Directed Graph vs. Undirected Graph (Figure by Author)
Basic operations of Graphs: The most common basic operations you can conduct on graphs are adjacent, neighbors, add_vertex, remove_vertex, add_edge, remove_edge, and get operations.
adjacent: checks if there is an edge from the vertex a to the vertex b;neighbors: lists all vertices b such that there is an edge from the vertex a to the vertex b;add_vertex: adds the vertex a;remove_vertex: removes the vertex a;add_edge: adds the edge from the vertex a to the vertex b;remove_edge: removes the edge from the vertex a to the vertex b,get: returns the value associated with the vertex a or edges.
Commonly asked Graph interview questions:
Find the path between given vertices in a directed graph; Check if the given Graph is strongly connected or not; and Check if an undirected graph contains a cycle or not.
7. Hash Tables
Hash tables are associative data structures that store data in an array format with a unique index value. In hash tables, accessing random elements are very efficient and fast as long as we know the index value. Besides, data insertion, deletion, and search are also very fast in hash tables regardless of size. Hash tables use a hashing function to generate efficient index values, which gives them a further advantage of efficiency.
Hashing
Hashing is a method to convert key values into a range of indices of an array. The reason for hashing is to reduce the complexity of key pairs and create an efficient indices list.

Figure 13. An Example Visualization of Hash Table (Figure by Author)
The performance of hashing data structure depends on (i) Hash Function, (ii) Size of the Hash Table, and (iii) Collision Handling Method. One of the combined methods used for hashing and collision handling is combining the modulo operator with linear probing so that the complexity can be reduced to a greater extent while ensuring unique index values.
Commonly asked Hashing interview questions:
Find symmetric pairs in an array; Trace the complete path of a journey; Find if an array is a subset of another array; and Check if given arrays are disjoint.