
神经网络与高斯过程会碰撞出怎样的火花?
【导读】大家好,我是泳鱼。一个乐于探索和分享AI知识的码农!
神经网络是目前最强大的函数近似器,而高斯过程是另一种非常强大的近似方法。结合高斯过程与神经网络模型(Neural Network Gaussian Process),这种模型能获得神经网络训练上的高效性,与高斯过程在推断时的灵活性。阅读本文具体了解下吧~
原文标题 神经网络高斯过程
©作者 宋珣 | 南京大学 | 数据挖掘
本文中,我们先梳理出单隐层神经网络与高斯过程(GP)的关系,再将概念拓展到多隐层神经网络,然后讨论如何用 GP 来完成传统神经网络的任务,即学习和预测。
1 单隐层神经网络与NNGP
在如下图所示的全连接神经网络中:

函数的输出可以写为:
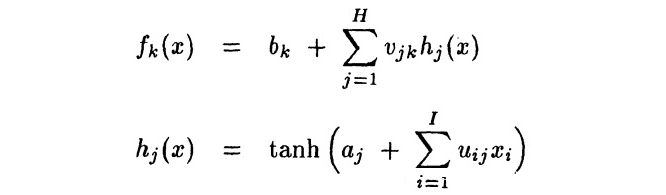
我们令网络的的所有参数服从高斯分布:
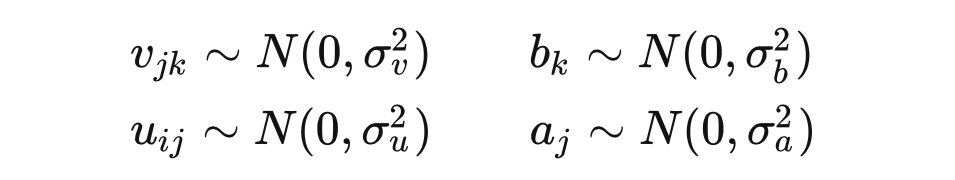
现在我们研究在某个输入
下第
个输出单元的值,即
。
因为
,对于任意的
,第
个隐藏单元的输出的期望值是 0:
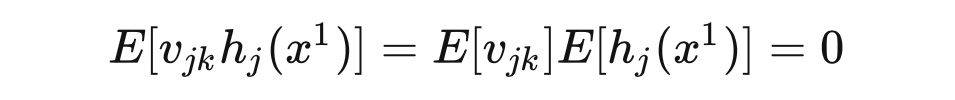
第
个隐藏单元的输出的方差为:

注意对于所有的
,
的值都是一样的(因为它只决于
,
和
),所以我们令
。
由于所有隐层输出
独立同分布,由中心极限定理可知,当
趋于无穷时,
服从高斯分布,方差为
。综上,当
趋于无穷时,我们得到
的先验分布为:
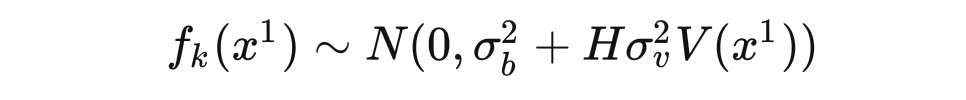
为了限制
的方差不会趋于无穷,对于某个固定的
,我们令
,可得
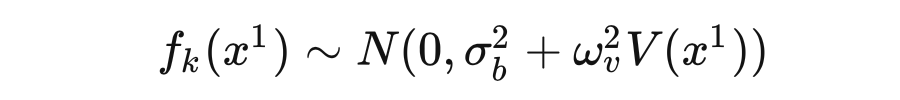
现在对于一组输入
,我们考虑其对应输出 的联合概率分布。根据定义, 应当服从均值为 0 的多元高斯分布,其中任意两个输出
和
之间的协方差定义为:

其中 ,该值对于所有的
都相等。
此时我们说 组成一个高斯过程,高斯过程的定义为:
定义:高斯过程是是一组变量的集合,这组变量的任意子集都服从多元高斯分布。[2]
其实,与其说高斯过程描述了这几个变量,不如说它描述的是一个函数的分布:
对于任意数量的输入,其对应的函数输出的联合概率分布都是多元高斯分布。
[1] 中的作者做了以下的实验来为验证这种高斯分布:
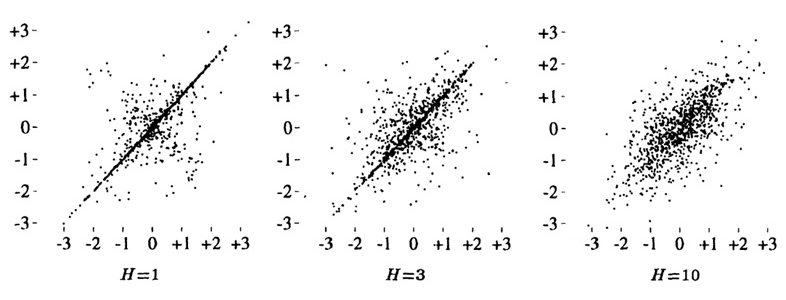
参数设置为:。在上面的三张图中,分别设置隐藏层宽度
为 1,3 和 10。
每个点代表对网络参数的一次采样(即每个点都是一个单独的神经网络),横轴和纵轴分别代表输入为
和
时的函数输出。
可以看到,随着
逐渐变大,两个输出呈现出二元高斯分布(并且有明显的相关性)。
现在我们来直觉上理解一下这个结论的作用。

我们以上面
的情况为例。还是那两个输入,一个
,一个
。现在我们假设
的标签
已知:
,那么
的标签
该是多少呢?
在没有
的标签时,我们并不知道图中的哪些点(代表的神经网络)可以拟合
和
之间的关系。而当得知
后,我们至少可以把选择范围缩小在上图的红色方框内,因为只有那里面的模型对
的预测符合我们的观测值。此时一种可行的做法是综合考虑方框内所有模型对
的预测,然后给出最终输出(比如取它们的均值)。
在这个例子中,(
)相当于训练样本,而
是测试集。
2 多隐层神经网络与NNGP
我们已经知道单隐层神经网络的每一维输出可以看作是一个高斯过程(GP),其实这个结论可以推广到多隐层全连接神经网络 [3]。
对于输入
,将第
层的第
个单元的输出记为
,神经网络的计算可以表示为:
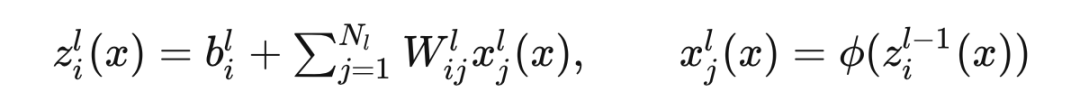
其中
为激活函数。
对输入
,其输出 是一个高斯过程(原理同单隐层类似):

其中
被称为 kernel,它的递归式为:

可以看到整个递归式中唯一非线性的部分就是激活函数
。这使得我们不能得到一个完全的解析式。幸运的是对于一些特定的激活函数,是可以有等价的解析式表达的。比如对于常用的 ReLU 函数,递归式就可以表示为如下的解析形式:
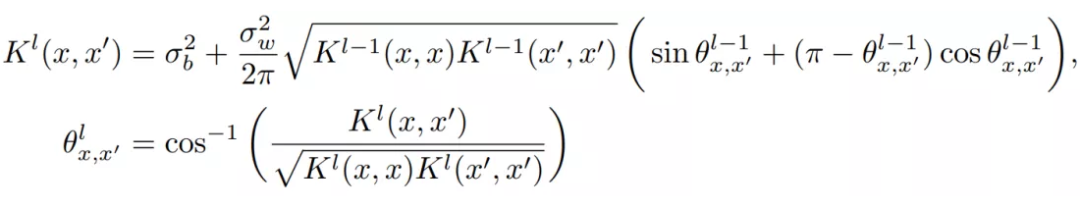
3 用NNGP做预测
在讲 NNGP 的预测方法前,我们需要先铺垫一个基础知识:多元高斯分布的条件概率分布。
考虑一个服从高斯分布的向量
,我们把它分成一上一下两部分:
和
。则我们有:
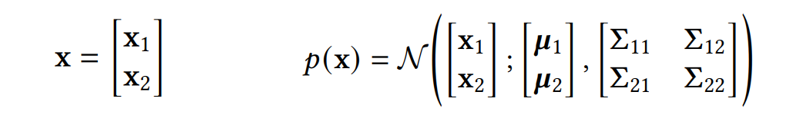
在已知
的情况下,
的分布可以表示为:

其中:
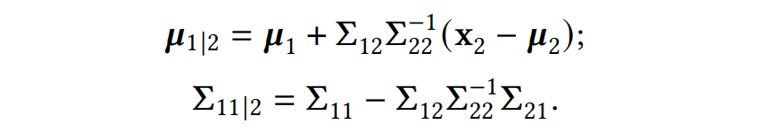
注意
是已知
时
的分布。区别于
的先验分布
,
是一种后验分布,它利用了
的观测值以及
与
之间的协方差
,在一定程度上消除了对原有
的不确定度。
现在我们就知道如何用 NNGP 做预测了:
记得我们前两节的结论是:对于全连接层神经网络,当网络参数服从高斯分布,且隐层宽度足够大时,其每一维度的输出都是一个高斯过程。
和常规 learning 问题一样,我们的数据集有两部分:训练集和测试集。
训练集的每个样本包括一个输入值和一个观测值:
而测试集只有输入样本
我们将它们记为向量的形式:
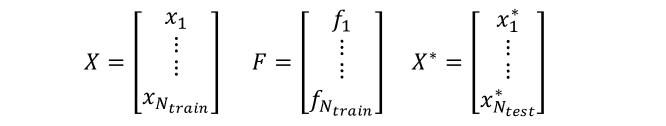
我们感兴趣的未知量为
,根据我们的结论,
和
的联合高斯概率分布为:
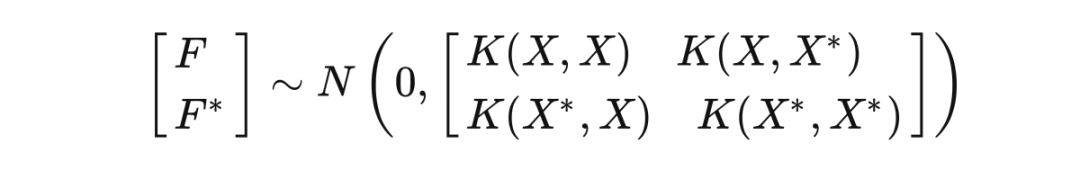
现在已知
,则
的后验分布为:

4 总结
传统神经网络与神经网络高斯过程(NNGP)最大的区别在于,后者没有显式的训练的过程(即通过 BP 调整参数),而是只借助了神经网络的结构信息(包括网络参数的分布,激活函数)来生成一个 kernel,即协方差矩阵。
我们甚至都不需要真的生成一个神经网络就可以得到 kernel:
假设我们用到是 ReLU 激活函数,那么从:

开始,到递归式:
都不需要涉及神经网络的具体参数。
除此之外,还可以直接指定一个 empirical 的协方差矩阵,比如平方指数(squared exponential)误差:

和
的距离越远,协方差越小,反之则越大。这是符合直觉的,因为对于一个连续、平滑的函数,相隔较近的点总会有更强的相关性——这也是 empirical 的协方差函数所依赖的共识。

参考文献
[1] Neal R M. Bayesian learning for neural networks[M]. Springer Science & Business Media, 2012.
[2] Williams C K I, Rasmussen C E. Gaussian processes for machine learning[M]. Cambridge, MA: MIT press, 2006.
[3] Lee J, Bahri Y, Novak R, et al. Deep neural networks as gaussian processes[J]. arXiv preprint arXiv:1711.00165, 2017.
[4] Roman Garnett. BAYESIAN OPTIMIZATION.
扩展阅读:AI领域文章精选!
评论