
遇见她,相见恨晚……
前言
遇见她,真的相见恨晚——skywalking。
前几天说要推荐一款运维利器——skywalking,但由于各种原因,立下的flag一直没有兑现,今天周六公司组织了一波活动,但是摸着良心说,真的不咋滴(无组织,无纪律),就感觉累了😵,早知道在家里码字睡觉了,一路舟车劳顿,昏昏欲睡,刚刚才回来,从公司回来的路上,骑了个自行车,吹了一路风,这会才稍微清醒了下,所以赶紧抽时间把资料整理下,把之前的flag先兑现了再说。
今天的内容有点长,但是只要你看完,一定会有所收获 。
。
今天的内容不涉及代码,看完之后只要会用就行了,好了,废话不多说,直接开始。
Skywalking
skywalking是什么
SkyWalking是一款优秀的国产APM工具,包括了分布式追踪、性能指标分析、应用和服务依赖分析等。
APM是什么?APM全称Application Performance Monitor,即应用性能监控(也有翻译成Application Performance Management,应用性能管理的),所有和应用性能相关的指标、管理相关的事情都属于它的范畴
SkyWalking 的核心是数据分析和度量结果的存储平台,通过 HTTP 或gRPC 方式向 SkyWalking Collecter 提交分析和度量数据,SkyWalking Collecter对数据进行分析和聚合,存储到Elasticsearch、H2、MySQL、TiDB 等其一即可,最后我们可以通过 SkyWalking UI 的可视化界面对最终的结果进行查看。Skywalking 支持从多个来源和多种格式收集数据:多种语言的 Skywalking Agent、Zipkin v1/v2 、Istio 勘测、Envoy 度量等数据格式。
简单来说,SkyWalking就是一款监控工具,可以让我们在产品上线以后监测服务的各项性能指标,包括并发数量、相应时长、错误堆栈信息、日志信息等,同时它也支持服务告警,你可以定义一些告警规则,这里我们算是一个小科普,更详细的内容暂时不做介绍,下面是SkyWalking的各个界面的截图:
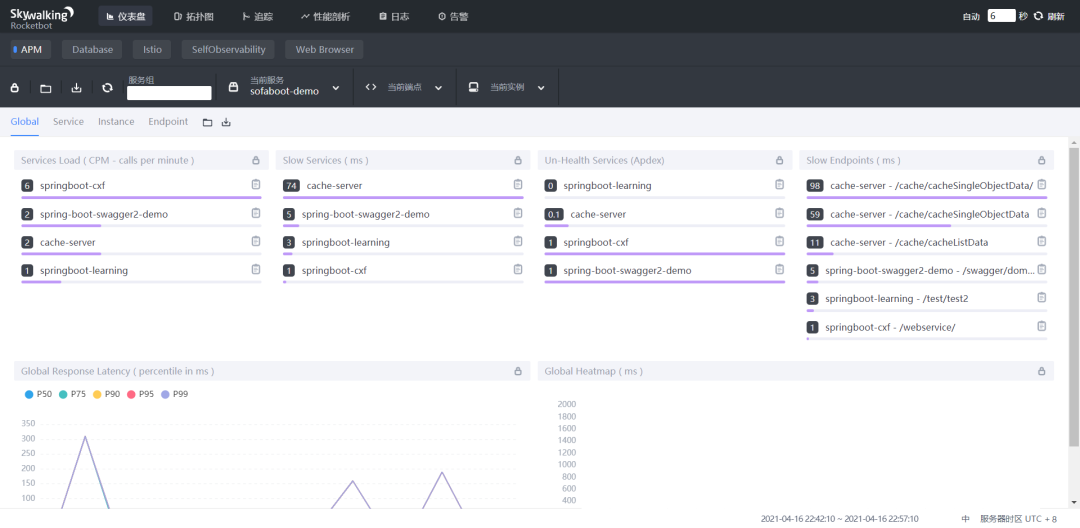
仪表盘
这个是首页的仪表盘
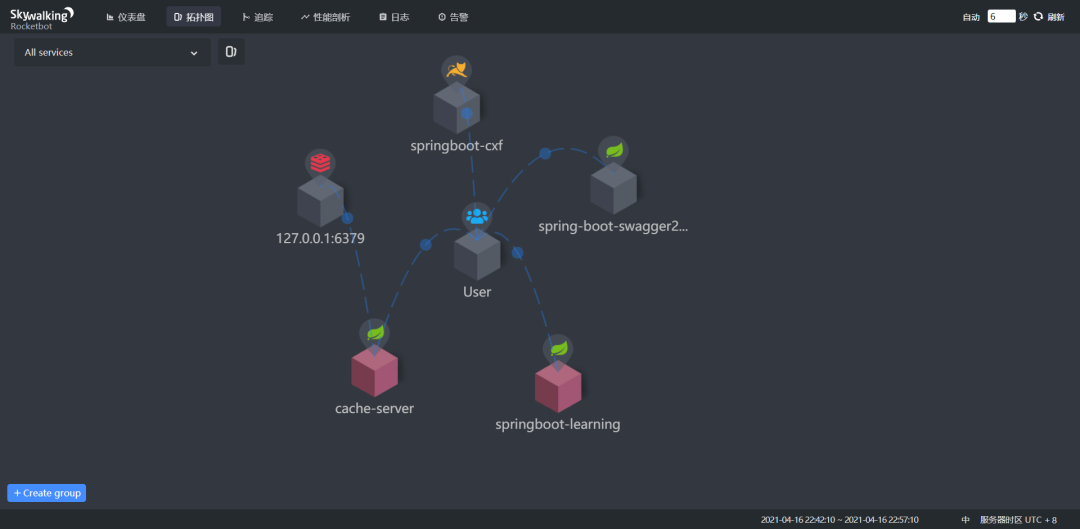
拓扑图
这一个就很神奇,它可以跟踪你的服务调用过程,然后生成你的服务的拓扑图。是不是看着就很高端,另外它还可以很直观地展示系统的架构情况,这里我起了五个服务,其中一个用到了redis,然后它就识别出来了
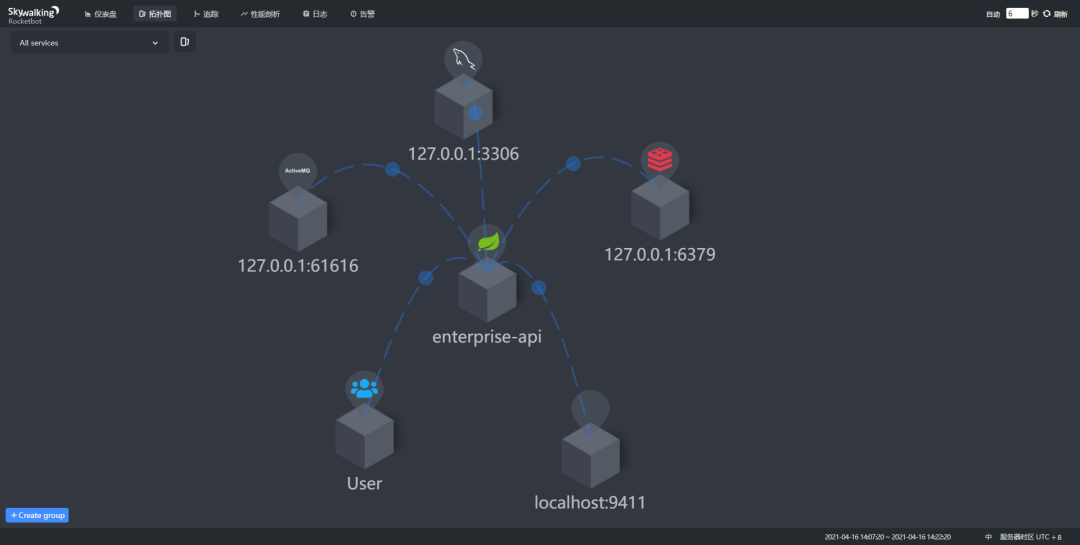
看下下面这个图,这个系统我用到了很多组件,包括mysql、redis、ActiveMq、``Zipkin`,都被它识别并且展示出来了
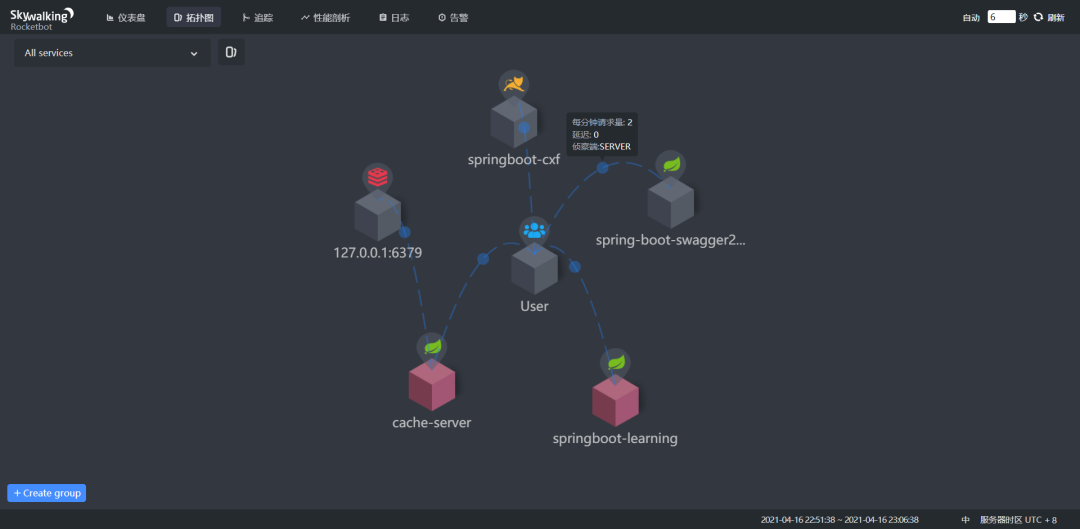
当你把鼠标放到对应的节点上时,它还会显示系统的并发和延迟信息:
追踪
这里就更强大了,当你的系统被调用的时候,它可以跟踪请求的处理过程,统计各个过程的时长,最后让你直观地看到接口的响应情况,找到接口的性能瓶颈。
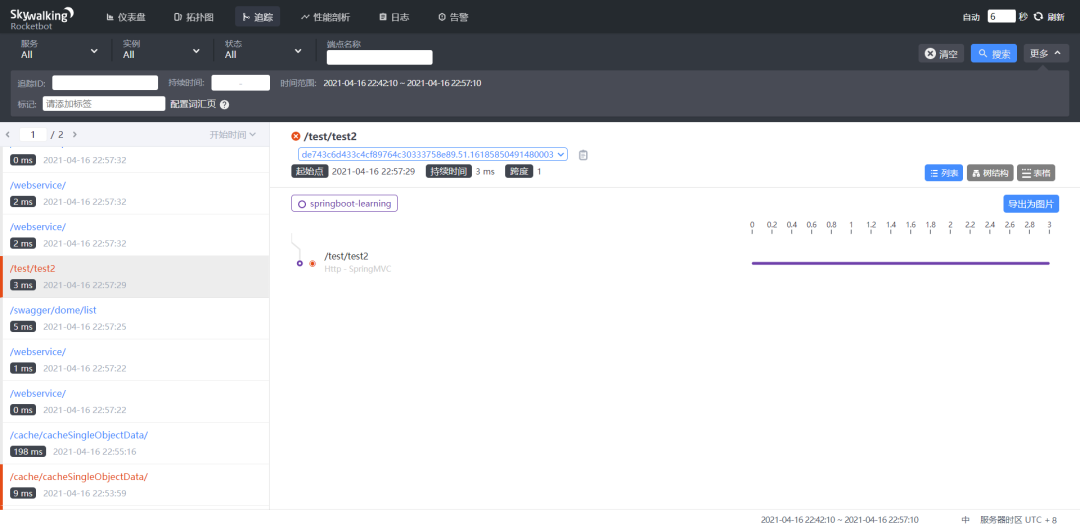
这里是多个节点调用的情况,我这里的cache-server调用了redis
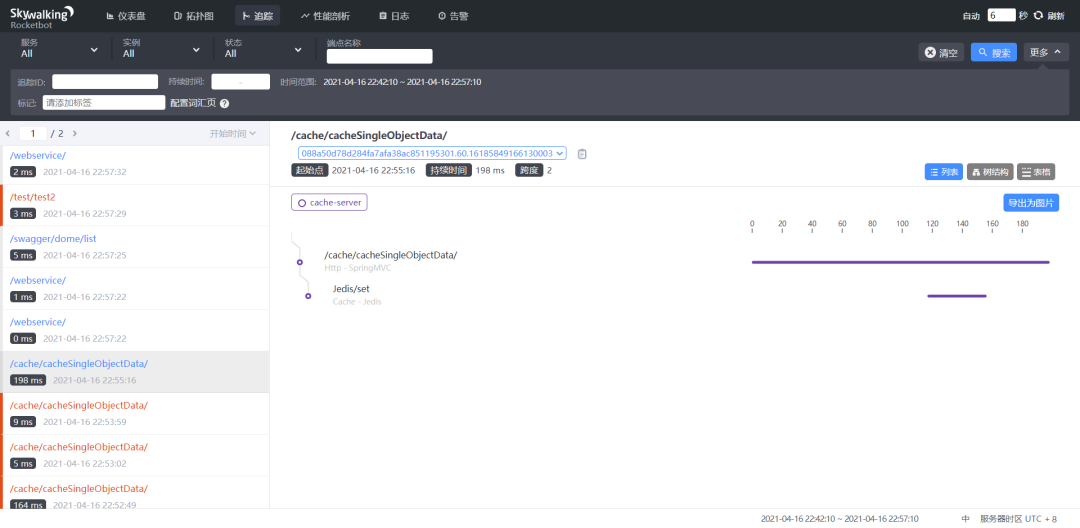
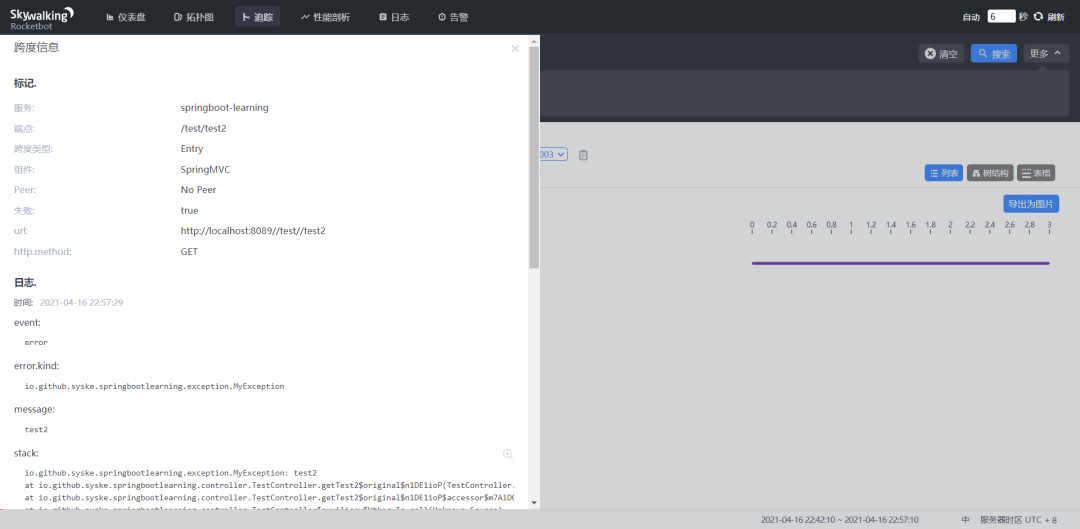
更优秀的是,当你的接口调用过程中报错的时候,它还会保留错误堆栈信息,当你点击对应的错误节点时,就可以很直观的看到:
skywalking安装配置
下载
SkyWalking是Apache基金会下的一个顶级开源项目,直接访问下面的地址,前往官网下载:
https://skywalking.apache.org/
skywalking提供了对多种语言的支持,这里我们选择第一个,我们用的是java,而skywalking本身也是基于java开发的
不知道如何下载的小伙伴可以直接访问下面的地址下载:
https://downloads.apache.org/skywalking/8.5.0/apache-skywalking-apm-8.5.0.tar.gz
安装
skyWalking不需要安装,直接解压下载好的压缩问题,解压之后的文件结构如下:
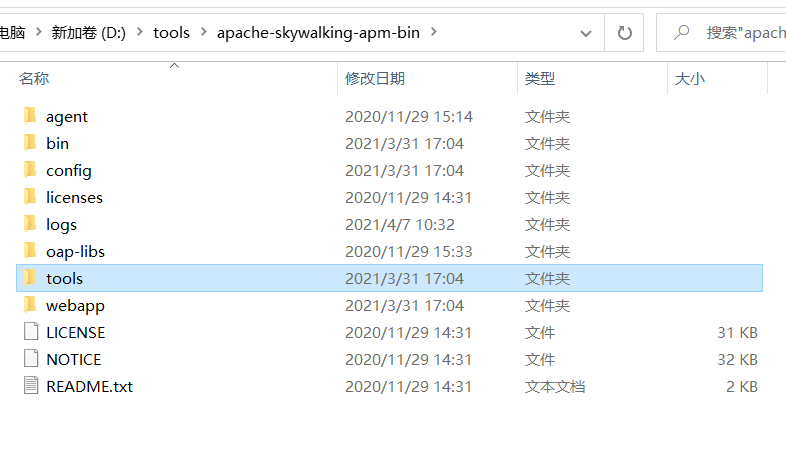
其中,agent就是我们的客户端探针,具体我们后面再解释;bin是运行命令存放的地方,这一个大部分的工具都是一样的;config存放的是配置文件,logs存放日志;其他的我们暂时不需要了解。
配置
进入配置文件夹,打开application.yml文件,这个文件就是skywalking的核心配置文件,配置文件内容比较多,大的配置就下面几项:
数据存储
因为我也刚接触时间不长,所以了解的不是很多,我们这里着重讲一下storage节点:
storge意思是存储,所以这个节点的作用就是配置skywalking的数据存储信息,它支持elasticsearch、h2、mysql、tidb、influxdb,默认存储是h2,这里科普下h2数据库的知识,之前在介绍nacos相关知识的时候,有提到过:
H2 是一个用 Java 开发的嵌入式数据库,它本身只是一个类库,即只有一个 jar 文件,可以直接嵌入到应用项目中。H2 主要有如下三个用途:
第一个用途,也是最常使用的用途就在于可以同应用程序打包在一起发布,这样可以非常方便地存储少量结构化数据。
第二个用途是用于单元测试。启动速度快,而且可以关闭持久化功能,每一个用例执行完随即还原到初始状态。
第三个用途是作为缓存,即当做内存数据库,作为NoSQL的一个补充。当某些场景下数据模型必须为关系型,可以拿它当Memcached使,作为后端MySQL/Oracle的一个缓冲层,缓存一些不经常变化但需要频繁访问的数据,比如字典表、权限表。
es好多小伙伴应该知道,一个企业级数据库,经常用来做分词和搜索,特点就是速度快,像携程就在用;
tidb是一个基于mysql的分布式数据库,当然也是开源的;
influxdb是一个由InfluxData开发的开源时序型数据。我之前也没听说过,它由Go写成,着力于高性能地查询与存储时序型数据。InfluxDB被广泛应用于存储系统的监控数据,IoT行业的实时数据等场景。
一般企业应用中会选择es也就是elasticsearch作为存储数据库,反正我们公司是,其他公司不了解,本地环境下我就用h2。
配置方式
skyWalking的配置方式很有特点,你稍加研究,就会发现他的配置结构是这样的:
配置项:
selecetor: ${SW_配置项:配置项选择1}
配置项选择1:
配置1:配置信息1
配置2:配置信息2
配置项选择2:
配置1:配置信息1
配置2:配置信息2
上面的内容应该可以很好地展示skywalking的配置情况,如果你要修改相关配置,首先修改selector,然后在修改选择项中的配置信息。完整的storage配置信息如下:
storage:
selector: ${SW_STORAGE:h2}
elasticsearch:
nameSpace: ${SW_NAMESPACE:""}
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:localhost:9200}
protocol: ${SW_STORAGE_ES_HTTP_PROTOCOL:"http"}
user: ${SW_ES_USER:""}
password: ${SW_ES_PASSWORD:""}
trustStorePath: ${SW_STORAGE_ES_SSL_JKS_PATH:""}
trustStorePass: ${SW_STORAGE_ES_SSL_JKS_PASS:""}
secretsManagementFile: ${SW_ES_SECRETS_MANAGEMENT_FILE:""} # Secrets management file in the properties format includes the username, password, which are managed by 3rd party tool.
dayStep: ${SW_STORAGE_DAY_STEP:1} # Represent the number of days in the one minute/hour/day index.
indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:1} # Shard number of new indexes
indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:1} # Replicas number of new indexes
# Super data set has been defined in the codes, such as trace segments.The following 3 config would be improve es performance when storage super size data in es.
superDatasetDayStep: ${SW_SUPERDATASET_STORAGE_DAY_STEP:-1} # Represent the number of days in the super size dataset record index, the default value is the same as dayStep when the value is less than 0
superDatasetIndexShardsFactor: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_SHARDS_FACTOR:5} # This factor provides more shards for the super data set, shards number = indexShardsNumber * superDatasetIndexShardsFactor. Also, this factor effects Zipkin and Jaeger traces.
superDatasetIndexReplicasNumber: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_REPLICAS_NUMBER:0} # Represent the replicas number in the super size dataset record index, the default value is 0.
bulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:1000} # Execute the async bulk record data every ${SW_STORAGE_ES_BULK_ACTIONS} requests
syncBulkActions: ${SW_STORAGE_ES_SYNC_BULK_ACTIONS:50000} # Execute the sync bulk metrics data every ${SW_STORAGE_ES_SYNC_BULK_ACTIONS} requests
flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:10} # flush the bulk every 10 seconds whatever the number of requests
concurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:2} # the number of concurrent requests
resultWindowMaxSize: ${SW_STORAGE_ES_QUERY_MAX_WINDOW_SIZE:10000}
metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:5000}
segmentQueryMaxSize: ${SW_STORAGE_ES_QUERY_SEGMENT_SIZE:200}
profileTaskQueryMaxSize: ${SW_STORAGE_ES_QUERY_PROFILE_TASK_SIZE:200}
advanced: ${SW_STORAGE_ES_ADVANCED:""}
elasticsearch7:
nameSpace: ${SW_NAMESPACE:""}
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:localhost:9200}
protocol: ${SW_STORAGE_ES_HTTP_PROTOCOL:"http"}
trustStorePath: ${SW_STORAGE_ES_SSL_JKS_PATH:""}
trustStorePass: ${SW_STORAGE_ES_SSL_JKS_PASS:""}
dayStep: ${SW_STORAGE_DAY_STEP:1} # Represent the number of days in the one minute/hour/day index.
indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:1} # Shard number of new indexes
indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:1} # Replicas number of new indexes
# Super data set has been defined in the codes, such as trace segments.The following 3 config would be improve es performance when storage super size data in es.
superDatasetDayStep: ${SW_SUPERDATASET_STORAGE_DAY_STEP:-1} # Represent the number of days in the super size dataset record index, the default value is the same as dayStep when the value is less than 0
superDatasetIndexShardsFactor: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_SHARDS_FACTOR:5} # This factor provides more shards for the super data set, shards number = indexShardsNumber * superDatasetIndexShardsFactor. Also, this factor effects Zipkin and Jaeger traces.
superDatasetIndexReplicasNumber: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_REPLICAS_NUMBER:0} # Represent the replicas number in the super size dataset record index, the default value is 0.
user: ${SW_ES_USER:""}
password: ${SW_ES_PASSWORD:""}
secretsManagementFile: ${SW_ES_SECRETS_MANAGEMENT_FILE:""} # Secrets management file in the properties format includes the username, password, which are managed by 3rd party tool.
bulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:1000} # Execute the async bulk record data every ${SW_STORAGE_ES_BULK_ACTIONS} requests
syncBulkActions: ${SW_STORAGE_ES_SYNC_BULK_ACTIONS:50000} # Execute the sync bulk metrics data every ${SW_STORAGE_ES_SYNC_BULK_ACTIONS} requests
flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:10} # flush the bulk every 10 seconds whatever the number of requests
concurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:2} # the number of concurrent requests
resultWindowMaxSize: ${SW_STORAGE_ES_QUERY_MAX_WINDOW_SIZE:10000}
metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:5000}
segmentQueryMaxSize: ${SW_STORAGE_ES_QUERY_SEGMENT_SIZE:200}
profileTaskQueryMaxSize: ${SW_STORAGE_ES_QUERY_PROFILE_TASK_SIZE:200}
advanced: ${SW_STORAGE_ES_ADVANCED:""}
h2:
driver: ${SW_STORAGE_H2_DRIVER:org.h2.jdbcx.JdbcDataSource}
url: ${SW_STORAGE_H2_URL:jdbc:h2:mem:skywalking-oap-db}
user: ${SW_STORAGE_H2_USER:sa}
metadataQueryMaxSize: ${SW_STORAGE_H2_QUERY_MAX_SIZE:5000}
maxSizeOfArrayColumn: ${SW_STORAGE_MAX_SIZE_OF_ARRAY_COLUMN:20}
numOfSearchableValuesPerTag: ${SW_STORAGE_NUM_OF_SEARCHABLE_VALUES_PER_TAG:2}
mysql:
properties:
jdbcUrl: ${SW_JDBC_URL:"jdbc:mysql://localhost:3306/swtest"}
dataSource.user: ${SW_DATA_SOURCE_USER:root}
dataSource.password: ${SW_DATA_SOURCE_PASSWORD:root@root}
dataSource.cachePrepStmts: ${SW_DATA_SOURCE_CACHE_PREP_STMTS:true}
dataSource.prepStmtCacheSize: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_SIZE:250}
dataSource.prepStmtCacheSqlLimit: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_LIMIT:2048}
dataSource.useServerPrepStmts: ${SW_DATA_SOURCE_USE_SERVER_PREP_STMTS:true}
metadataQueryMaxSize: ${SW_STORAGE_MYSQL_QUERY_MAX_SIZE:5000}
maxSizeOfArrayColumn: ${SW_STORAGE_MAX_SIZE_OF_ARRAY_COLUMN:20}
numOfSearchableValuesPerTag: ${SW_STORAGE_NUM_OF_SEARCHABLE_VALUES_PER_TAG:2}
tidb:
properties:
jdbcUrl: ${SW_JDBC_URL:"jdbc:mysql://localhost:4000/tidbswtest"}
dataSource.user: ${SW_DATA_SOURCE_USER:root}
dataSource.password: ${SW_DATA_SOURCE_PASSWORD:""}
dataSource.cachePrepStmts: ${SW_DATA_SOURCE_CACHE_PREP_STMTS:true}
dataSource.prepStmtCacheSize: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_SIZE:250}
dataSource.prepStmtCacheSqlLimit: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_LIMIT:2048}
dataSource.useServerPrepStmts: ${SW_DATA_SOURCE_USE_SERVER_PREP_STMTS:true}
dataSource.useAffectedRows: ${SW_DATA_SOURCE_USE_AFFECTED_ROWS:true}
metadataQueryMaxSize: ${SW_STORAGE_MYSQL_QUERY_MAX_SIZE:5000}
maxSizeOfArrayColumn: ${SW_STORAGE_MAX_SIZE_OF_ARRAY_COLUMN:20}
numOfSearchableValuesPerTag: ${SW_STORAGE_NUM_OF_SEARCHABLE_VALUES_PER_TAG:2}
influxdb:
#InfluxDB configuration
url: ${SW_STORAGE_INFLUXDB_URL:http://localhost:8086}
user: ${SW_STORAGE_INFLUXDB_USER:root}
password: ${SW_STORAGE_INFLUXDB_PASSWORD:}
database: ${SW_STORAGE_INFLUXDB_DATABASE:skywalking}
actions: ${SW_STORAGE_INFLUXDB_ACTIONS:1000} # the number of actions to collect
duration: ${SW_STORAGE_INFLUXDB_DURATION:1000} # the time to wait at most (milliseconds)
batchEnabled: ${SW_STORAGE_INFLUXDB_BATCH_ENABLED:true}
fetchTaskLogMaxSize: ${SW_STORAGE_INFLUXDB_FETCH_TASK_LOG_MAX_SIZE:5000} # the max number of fetch task log in a request
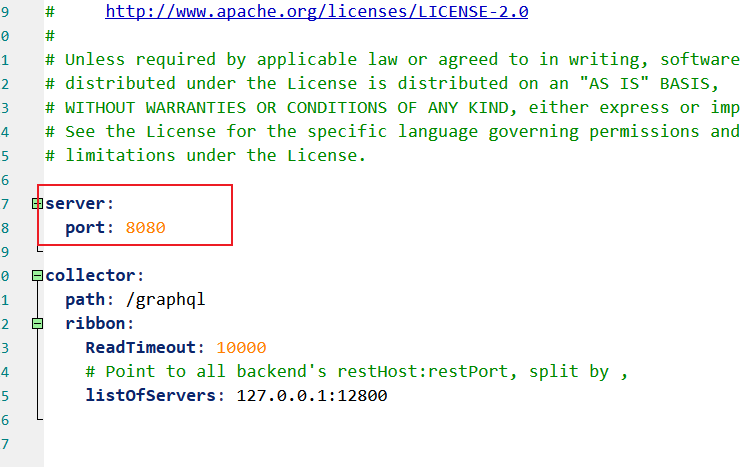
web端端口配置
这里需要注意的一点是SkyWalking默认的访问端口是8080,如果你要修改,需要进入\apache-skywalking-apm-bin\webapp,并修改webapp.yml:
启动
启动也很简单,进入bin目录,运行startup.bat即可:
正常启动成功会弹出两个dos窗口,且窗口不会关闭,如果窗口关闭,可能是配置有问题,或者端口冲突,可以去日志文件夹查看日志信息:

测试
首先我们先访问下web端,看下服务启动是否正常:
http://localhost:8080/
如果你修改了端口,记得把端口修改成你修改过的,如果正常的话,你应该会看到我们最开始展示的首页:
这里因为没有添加任何应用,所以当前服务这里应该显示的是空,这样的显示是正常的,至少说明你的服务启动是OK的。
添加需要监测的服务
这里也是特别的关键,所以各位小伙伴一定要认真仔细。这里你随便添加自己之前写过的java应用,我用的是自己之前写过的springboot项目,方法也很简单:
IDEA
如果你想监测IDEA中的项目,你需要修改项目部署配置中environment的虚拟器启动参数:
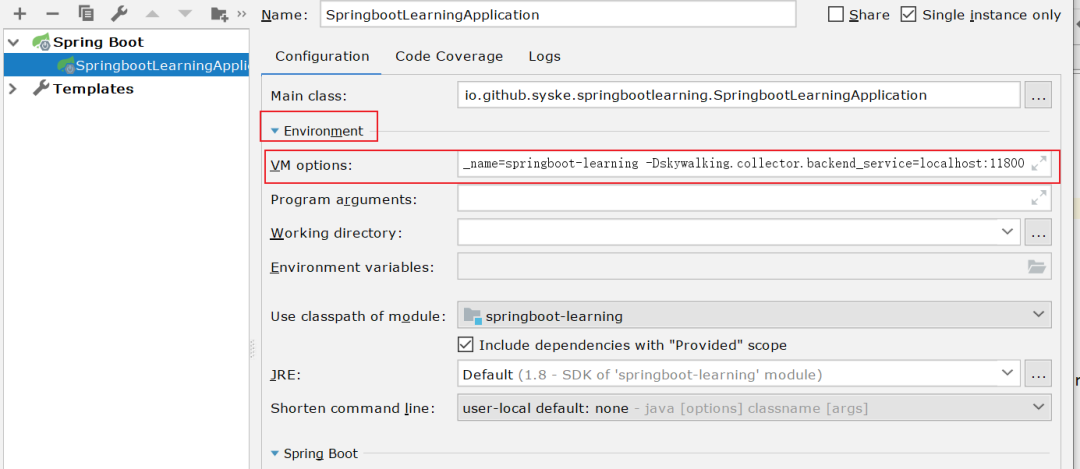
添加如下配置:
-javaagent:D:\tools\apache-skywalking-apm-bin\agent\skywalking-agent.jar -Dskywalking.agent.service_name=enterprise-api -Dskywalking.collector.backend_service=localhost:11800
其中,javaagent配置的就是我们前面说的agent目录下的skywalking-agent.jar,这个参数是jdk1.5以后引入的,是运行方法之前的拦截器,详细知识各位小伙伴自行搜索,我也就大概了解。
利用javaAgent和ASM字节码技术,在JVM加载class二进制文件的时候,利用ASM动态的修改加载的class文件,在监控的方法前后添加计时器功能,用于计算监控方法耗时,同时将方法耗时及内部调用情况放入处理器,处理器利用栈先进后出的特点对方法调用先后顺序做处理,当一个请求处理结束后,将耗时方法轨迹和入参map输出到文件中,然后根据map中相应参数或耗时方法轨迹中的关键代码区分出我们要抓取的耗时业务。最后将相应耗时轨迹文件取下来,转化为xml格式并进行解析,通过浏览器将代码分层结构展示出来,方便耗时分析
Dskywalking.agent.service_name就是配置你的服务在skywalking的名字,如果你省略了这个参数,你的服务在skywalking中的名字就变成了Your_ApplicationName,如果服务多了,你就傻傻分不清到底那个是哪个了。
Dskywalking.collector.backend_service配置的是gRPCPort的端口,这个参数和skywalking核心配置中的gRPCPort保持一致,但如果你的服务不是rpc服务的话,如果没有这个参数应该是不影响的,具体我还没研究。
Tomcat
编辑bin/catalina.bat文件,Linux类似,在脚本最开始添加如下内容:
set CATALINA_OPTS=-javaagent:D:\tools\apache-skywalking-apm-bin\agent\skywalking-agent.jar -Dskywalking.agent.service_name=tomcat-10 -Dskywalking.collector.backend_service=localhost:11800

单点jar文件
如果你的项目是单点的springboot项目,那你只需要在你的启动命令里面增加上面类似的参数即可:
$ java -javaagent:D:\tools\apache-skywalking-apm-bin\agent\skywalking-agent.jar -Dskywalking.agent.service_name=springboot-demo -Dskywalking.collector.backend_service=localhost:11800 -jar springboot-demo.jar
测试
打开你的服务,比如springboot服务,访问你的服务接口,如果没什么问题的话,skywalking会显示相应的访问信息:
如果刷新后没有,稍等下看下。我在本地测试的时候,发现tomcat-10不显示访问信息,但是节点是显示的,不知道是没有部署服务的问题,还是版本的问题,这个问题后面再研究,但是springboo项目妥妥的没问题。具体显示效果参看前面的展示。
补充
如果有小伙伴用的是docker的话,可以通过下面的命令进行安装启动:
docker run -p 8080:8080 -p 10800:10800 -p 11800:11800 -p 12800:12800 -e ES_CLUSTER_NAME=elasticsearch -e ES_ADDRESSES=127.0.0.1:9200 -d apache/skywalking-ui
另外,我本地在使用es7的时候,skywalking不能正常启动,不知道什么原因,这个问题后面再来研究。
结语
遇见她,我的第一个感觉就是相见恨晚,要是我能在上一家公司知道它的存在,那我的工作可以更顺利,工作也会轻松很多,但是我没有,这就是缘分吧。
上一家公司的系统特别老,祖传代码,系统臃肿,管理也特别混乱,特别是当你排查错误的时候,更是让人觉得很恶心 ,所有日志都打印到控制台,然后输入到一个文件里面,排查问题的时候像大海捞针,而且有时候时间久了日志
,所有日志都打印到控制台,然后输入到一个文件里面,排查问题的时候像大海捞针,而且有时候时间久了日志1~2G,本地打开直接死机,服务器终端搜索又不支持中文,有时候你根本不知道如何找问题,心疼还没离职的小伙伴5s😂,但是如果有了skywalking,我不仅可以查看服务运行状况,监测接口调用情况,还可以直接查看错误日志,不香吗 ?
?
如果前同事看见了,可以搞搞看,降低运维难度,提高工作效率,排查错误监测服务,SkyWalking大法真的好