
以微信为例,聊聊在内容推荐上AI的一些应用实践
Hello~ 这是公号的第25篇原创文章,感谢阅读
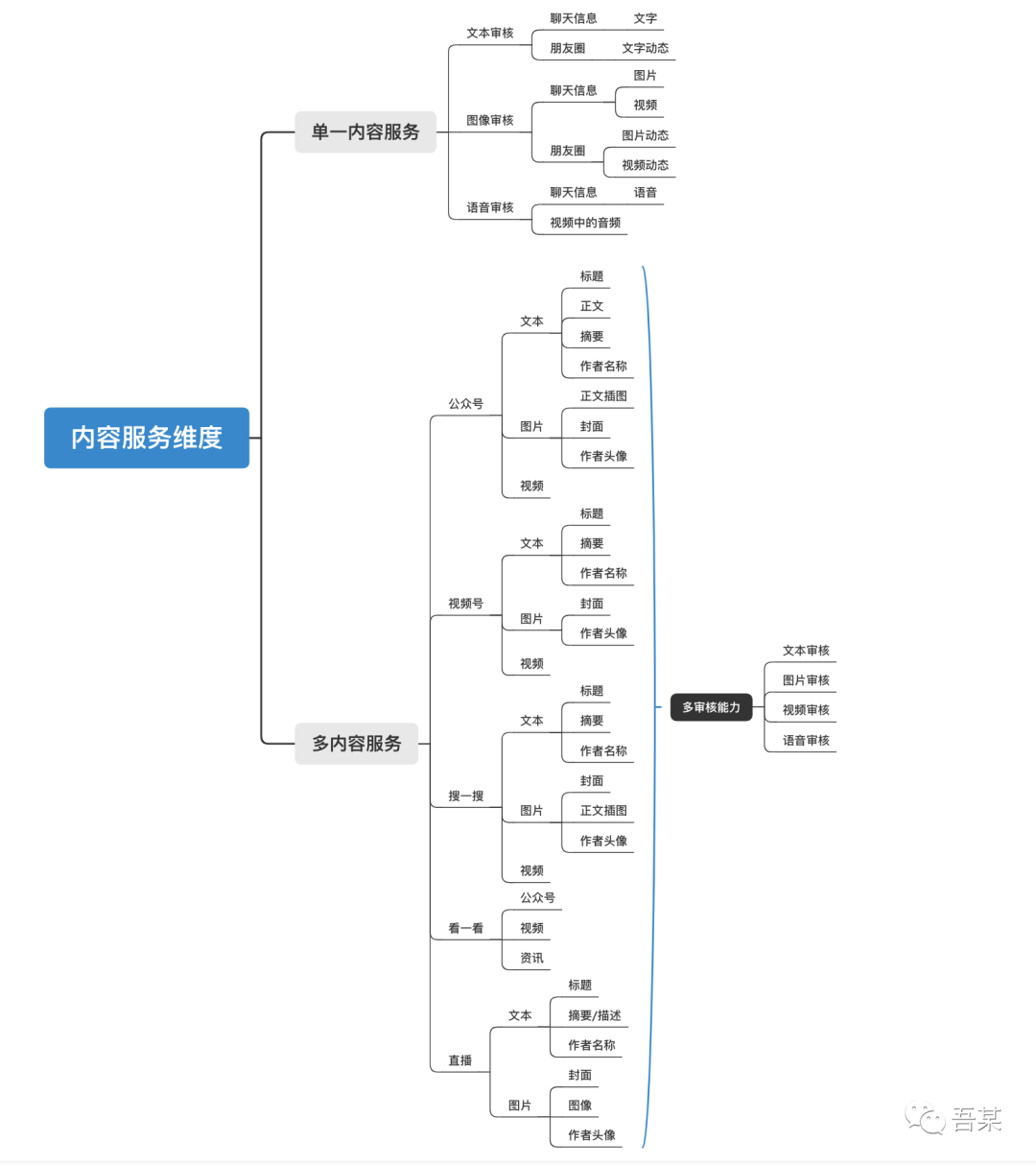
内容推荐一直是流量分发中十分常见的应用方向,如头条的资讯、抖音的短视频、网易云音乐等等。而微信也从去年开始逐渐推出更多内容产品服务,包括视频号、直播、看一看等等。对于微信而言既是机会也是挑战。机会意味微信已经开始探索出属于自己的内容成长方向,挑战则是在如何在庞大的流量上,管好内容的质量输出、推荐服务体验。
而本文也将基于微信当前的内容产品服务,聊一聊微信将在多个场景服务上,都可能会进行哪些AI能力实践。
(值得说明一下的是,本文无意从技术角度探究AI原理,更多从应用场景出发了解当前的实践情况)
1
那么到底什么是内容推荐?
在当下娱乐高度消费的社会,每个人几乎每天都在接触不同的内容产品服务。尤其是现在推荐算法越发成熟,对用户和内容的理解越发深刻。诸如头条的资讯、抖音的短视频或网易云音乐等等,但这些都是只是用户能接触最表层的“事物”,要想提供这样的服务,背后有着一套成熟的体系。所以在这里也先简单科普下,什么叫内容推荐服务。

以上就是一套典型的内容推荐服务体系,具体可以划分3部分:基础服务>内容识别+用户画像>推荐引擎
基础服务
所谓基础服务,即搭建整个系统服务所需的一些基础能力。基于内容、用户及推荐引擎环节,这样的基础服务需要涉及内容源、工程、数据等方面的能力支撑。
内容源:主要包含内容的引入存储、处理管理,把众多非结构化的数据,或者不同形态格式的内容数据,以统一结构化的形式管理,便于为后续内容识别提供统一的方案。 工程:对于这样的能力,需要工程端给予性能优、高可用的研发能力支撑,对服务的计算效能、算法模型的推理服务等都需要较强的支撑 数据:在整套服务中,数据是不可或缺的,对于内容的数据、用户的数据等等,都构筑了以“用户”维度的画像特征,本质上推荐服务把合适的内容分发给合适的用户,那么从数据维度识别用户,就必不可少。而关键的数据就包含用户信息数据(头像、昵称、身份信息等)、行为数据(如当前位置、操作偏好等等)
NLP:Natural Language Processing,即自然语言处理,通俗来讲就是研究计算机如何理解人类语言并能进行相关的意图思考。而时下文本识别、关键词抽取等能力输出,主要就是立足于这一技术 CV:Computer Vision,即计算机视觉,任何关于图片、视频等形式,都主要应用这一技术能力 ASR:Automatic Speech Recognition,即自动语言识别技术,是一种将人的语音转换为文本的技术,例如把视频中的音频转译为文本,从而通过文本识别方式进行处理。而这一技术难度主要在于环境干扰程度、语言种类及词汇表丰富性等等

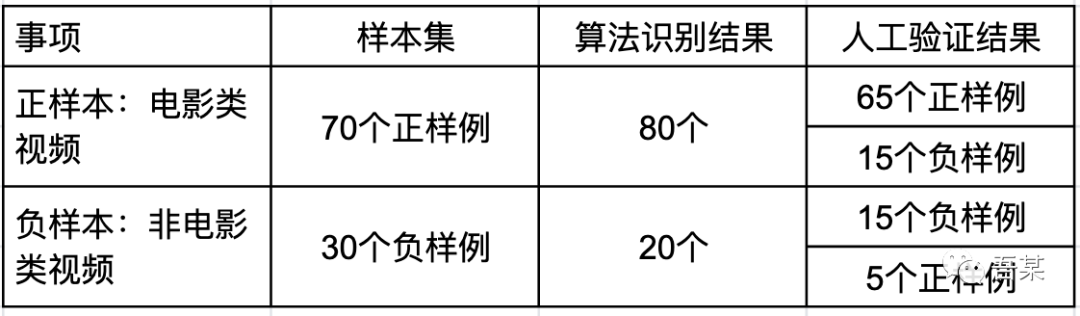
假设算法识别100个视频中为电影类视频有80个,其中65个是正确的电影类内容(正样例),剩余20个非电影类视频中15个正确的非电影类内容(负样例),则为:(65+15)/100*100%=80.00%
假设算法识别100个视频中为电影类视频有80个,其中在数据验证中发现80个里面有65个是正确的,则为:65/80*100%=81.25%
假设算法识别100个视频中为电影类视频有80个,其中在数据验证中发现80个里面有65个是正确的,而100个视频中真正为电影类的70个,则为:65/70*100%=92.85%
假设算法识别100个视频中为电影类视频有80个,即认为剩下20个为非电影类,而在数据验证下发现20个中有5个实际是正确的(即算法未识别到),则为:5/70*100%=7.14%
假设算法识别100个视频中为电影类视频有80个,其中在数据验证中发现80个里面有15个实际是错误的,而100个视频中实际为非电影类的有30个,则为:15/30*100%=50.00%

平台外:国家层面是否涉恐、涉政、黄赌毒等,行业层面是否侵犯版权(原创声明)、是否冒认等 平台内:基于平台的产品服务和特性,进行平台产品的使用规范,如禁止辱骂、广告、低俗、灌水等


图中左侧的2张图,是典型的文本检测审核案例,从这里可以看出这是不同文本做出了是否正常及问题点的安全检测; 图中右侧的2张图,尤其是“已停止访问该网页”图,这是大家常见微信的一种的异常处理方式,显然这是一个垃圾广告营销性质的推文而被封禁。而最后一张图则是正常的一篇推文,对标题、视频中的文本、水印等其实也会进行相关检测,完成安全审核。


清晰度:有时候视频或者图片的清晰度,会影响用户感官感受。清晰度的识别也是当前内容分发中常见的应用场景。而这一能力主要能够识别当前图片或图像是正常或是模糊等鉴别,那么这里就依赖多个技术集合,如人脸检测(人物主体是否清晰)、分辨率识别(图片截帧识别分辨率或像素)、OCR等等 音频质量:如果是视频内容或者是音乐内容,那么就需要注意当前分发的音频是否出现卡顿、无声或噪音等等,如果能从AI上进行这样的支撑,则能在分发时就规避这些低质量内容。 声画不同步:实际这也是存在的场景之一,即视频在播放过程中,音频会出现延迟或提早,与视频当前播放内容出现不一致。其实这样也会影响体验效果。
OCR检测:因为是视频,需要通过OCR来识别其中的文本,如弹幕、水印等,来收集数据 关键词抽取:通过OCR识别的文本,视频本身的标题等,进行一系列的“关键词”抽取,可以识别出诸如“电影”、“海报"、“爱乐之城”、“高司令”等关键词。但是这些关键词都是独立个体数据,没有关系,那么接下来就需要知识图谱及NER来进行进一步的“联结” 知识图谱:结合NER实体识别以及上述的关键词,基于知识图谱关系来梳理出“电影-爱乐之城-男主角高司令”等这一系列有序的数据。 内容分类:实质为分类标签,即对内容打标进行各级分类,从以上的数据可以看出它是属于电影类(一级分类)-欧美电影(二级分类)这样的关系。分类的全面性及细粒度体验当前平台的分类标签能力。如果平台足够储备这样的分类数据,结合以上的数据,就可以快速识别该内容是一致的,可以进行推荐池基于推荐规则进行分发。
假设作为消费型用户,我喜欢体育及科比球星,那么是否推荐都给我推荐科比的视频? 假设作为内容生产型用户,大家都创作了科比的视频,你一个我一个都这样推荐给用户,看着对内容生产者有利益,但对于普通用户而言是否就有帮助? 假设作为内容生产型用户,我手上有几个视频号自媒体矩阵(以及都有较高的粉丝量),但是这几个账号里面有些作品内容是几乎重复的。那么作为平台方,该如何规避这些不同账号但旗下内容重复的分发? 假设有一个地域性的新闻视频,所报道的内容是跟深圳本地强相关的,但是在没有做分类及位置信息的前提下,怎么最大化地把这个内容合适推荐给本地信息流里面去?

纯内容重复:即内容完全或接近一致。这种可能存在同一账户下多条内容重合,或不同账户下同一条相似内容重合。从上图中的左侧1、2可以看出,这是同一时段内(23点34-35分间),同一条相似内容在不同的账户下发生重复现象。明显微信在这方面其实还没做到精细化的管理,但是AI能力上,其实是可以进行“重复”判断及置信度的反馈,获取这样的算法标签时,在内容推荐分发上就可以一定程度上规避这样的情况。即假设用户已在头一条成功曝光和观看内容,则在相似的下一条基于已有重复标签,在去重时间窗口内(如3个月内)进行过滤分发。 主题性重复:即在内容推荐过程中,主题分类或话题性十分相似。譬如前面提到科比视频,如果在视频推荐中前10条中7条都是科比的(尽管具体内容不同),但是基于偏好不能直接分发给用户,因为这样看似迎合了用户喜好,但实际反而造成用户观赏疲劳,相似性内容太多缺乏好奇性和新鲜性,最终影响对平台的感官感受。这里的支撑,依赖于主题分类的规则制定。


「往期回顾」
评论